C++标准库 STL -- STL 体系结构基础介绍
STL 体系结构基础介绍
文章内容为侯捷老师的《C++标准库与泛型编程》的学习笔记
文章目录
- STL 体系结构基础介绍
-
- 代码示例
- 容器分类
- vector
-
- 关于vector 的动态扩充
- deque
- 红黑树
-
- multiset
- multimap
- hashTable
-
- unordered_multiset
- allocator
组成:
- 容器(constainers)
- 算法(algorithm)
- 迭代器(iterators)
- 仿函数(functors)
- 适配器(adapters)
- 分配器(allocators)
容器就是数据结构,容器中放入数据,要占用内存,但是在使用容器的时候,我们只关心如何存取数据,而内存的分配工作,是由分配器(Allocator)在背后帮我们完成的。容器中有了数据后,我们需要对数据进行操作,一些操作需要使用到算法中的操作,数据在容器中,操作数据的动作是在另外一个class 中。这个和OO (面向对象) 是不同的,这种称为GP——泛型编程。
那么如果要使用算法中的方法对容器中的数据进行操作,那么就涉及到如何获取到容器中的数据。所以算法和容器之间的桥梁就是迭代器(Iterator), 迭代器相当于一种泛化的指针。
仿函数: 实现对象之间的一些操作:比如定义对象之间的加减操作。(后面应该会详细介绍)
适配器: 实现转换功能,例如,将容器做一些转换,迭代器做一些转换(后面应该会详细讲)

代码示例
一个将六大部件一起使用的代码示例

容器要放东西,东西要占用内存。所以容器非常好的是帮我们把内存的问题全部解决掉。你看不到内存这件事情。你只要把东西一点一点的放进入,或者把它取出来就可以,不需要考虑内存的问题。所以它的背后要有另外一个部件去支持它,那就是分配器。
需要对容器内的数据进行操作,这部分操作放置在算法中。
迭代器处于容器和算法之间,起到桥梁的作用,它是一种泛化的指针。
容器的范围是一种 前闭后开。[ )
Container<T> c;
Container<T>::interator ite = c.begin();
for(; ite != c.end(); == ite)
容器分类
序列式容器和关联式容器(key-value组合)。

连续内存空间的容器
- Array :固定元素数量的容器
- Vector: 两倍扩充的容器
- Deque: 可以进行两端插入的容器
非连续内存空间的容器
- List: 双向链表,不是连续内存空间的容器。
- Forward-list: 单项链表,
hash-table 就是一个vector+list
其中vector中的每一个元素都相当于一个篮子,而篮子中可以存放数据,这些数据是链表的方式存放的。
元素和元素之间是什么样的关系, 是连续的关系,还是通过指针将它们串联起来。串联起来后是一个链表,还是一棵树,是一个红黑树还是一个二叉树。还是一个HashTable
vector
vector 是表示可以改变大小的数组的序列容器。
就像数组一样,vector 使用连续空间的存储位置,它们的元素可以使用元素的常规指针来进行偏移访问,而且和数组一样高效。但是和数组不同,它们的大小可以动态地改变,它们的存储由容器自动处理。
针对vector的各种常见操作的复杂度如下:
- 随机访问— 常数(O1)
- 在尾部增删元素—常数(O1)
- 增删元素—目标位置到vector尾部之间的线性距离 O(n)

举个例子,Class Foo; vector, v 中已插入100万个元素,如果要在头部再插入一个元素,那么,就会发生100万次的析构函数和100万次的拷贝构造或move构造函数。所以在容器Vector 开头插入一个元素是非常低效的。
一个容器大小固定后就不能再扩充,再扩充就有可能扩充到其它人的地方去了。vector 的扩充也是重新找一份内存空间,在将vector 原先的数据拷贝过去。
关于vector 的动态扩充
在MinGW编译器下,vector 是2倍的。而在MSVC 下却是1.5倍的成长。
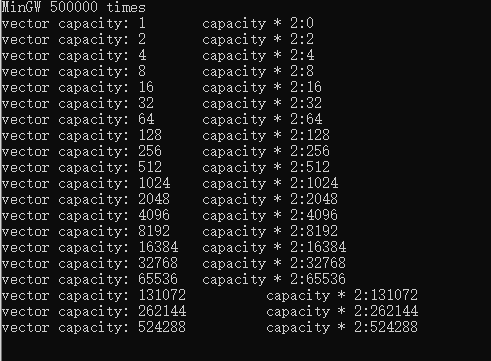

动态改变大小的方式是,重新从系统内存空间找一份两倍于当前容器大小的内存空间。然后将原先内存空间的数据拷贝到新的内存空间中,并且还会释放原先内存空间的数据。这就无法避免的产生析构函数和拷贝构造函数或移动构造函数。
deque

deque 是一个双向开口可进可出的一个容器。
deque 是分段连续。假如deque, 有三段buff,在查找数据时,当一个buff 遍历完后,会去到下一个buff遍历。
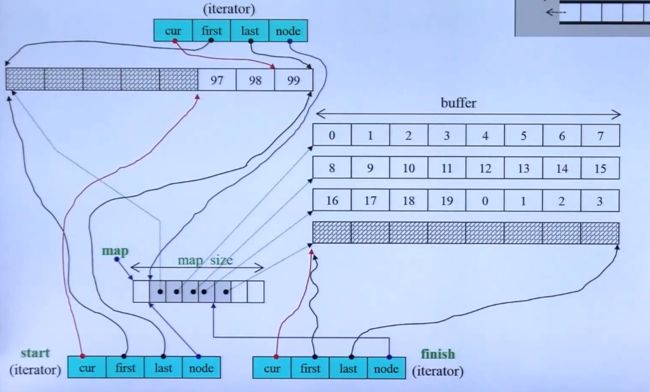
上图一个个的方块就是一个个的buff,当buff 用完后就会申请新的buff。
stack 和 queue 的底层实现都有一个deque。(具体实现见P2)
红黑树
红黑树是平衡二分搜寻树中常被使用的一种。平衡二分搜寻树的特征:排列规则有利于 Search 和 insert,并保持适度平衡——无任何节点过深。
rb_tree 提供两种 insertion操作:insert_unique 和 insert_equal。前者表示节点的key 一定是在整个tree 中独一无二,否则安插失败。后者表示节点的key 可重复。独一无二的key 对应的就是 set 和 map,可以重复的key 对应的就是 multiSet 和 multiMap。

multiset
multiset<string> set;
c.insert(string(buf));
创建一个 multiset 以及 向容器中添加数据。
multimap
multimap<long , string> map;
要在map 中添加一个数据,使用
map.insert(pair<long, string>(1, "1"));
pair 的作用是将 long 和 string 打包成一个整体放入map 中。
要将key 和 value 打包成为一个 pair 放入map 中。
hashTable

容器有多个篮子(bucket)组成,每个篮子下挂着一串数据(是单项链表或双向链表,取决于编译器的实现方式)。
unordered_multiset
unordered_multiset<string> c;
c.insert(string(buf));
//插入 1000000 元素后
cout << " unordered_multiset.size() " << c.size() << endl;//1000000
cout << " unordered_multiset.bucket_count() " << c.bucket_count() << endl;//1048576
出现了篮子的数量大于 元素的数量,因为某些篮子上没有挂载元素。有些篮子上则会挂载1个或多个的元素。
可以通过 c.bucket_size(i) 来查看指定篮子中的元素个数。
篮子的数量都比元素的数量多,如果一个篮子中的元素过长,会影响全局的查找。查找是按照循序查找的方式。如果篮子元素的数量大于等于篮子的数量,则这个篮子的元素会被打散,重新挂在不同的篮子下面。
allocator
分配器是一个类,提供两个函数用于内存申请和释放。
allocator<int> alloc1;
int * p = alloc1.allocate(1);
//int * std::allocator::allocate(size_ count);
// _Ty * allocate( const size_t _Count)
alloc1.deallocate(p, 1);
//void std::allocator::deallocate(int* _ptr, size_t Count);
//void deallocate(_Ty * const _Ptr, const size_t _Count) ===》 底层调用的是 ::operator delete(_Ptr, _Bytes);