java正则表达式,从入门到熟练使用
笔记来自b站视频:java300集
正则表达式及java操作复制文本
正则表达式是操作文本的时候非常常用的技术,对于处理复杂文本很有帮助,学习的时候可以把正则表达式看成一门独立的语言(简单处理文本的小语言)
正则表达式的基本知识:
- 基本语法,高级语法
- 练习
- editplus,notpad++,ultraedit,eclipse中使用正则
- JAVA复杂文本操作(不光java可以使用,各种语言都可以使用)
简介
为什么需要正则表达式?
因为文本的复杂处理。
正则表达式的优势和用途?
一种强大而灵活的文本处理工具
大部分编程语言、数据库、文本编辑器、开发环境都支持正则表达式。
正则表达式定义∶
正如他的名字一样是描述了一个规则,通过这个规则可以匹配一类字符串。
学习正则表达式很大程度上就是学习正则表达式的语法规则。
开发中使用正则表达式的流程︰
1.分析所要匹配的数据,写出测试用的典型数据
2.在工具软件中进行匹配测试
3.在程序中调用通过测试的正则表达式(程序可能不支持某些正则语法,先测试一下)
工具软件
RegexBuddy
表达式库
软件这里有很多已经写好了的正则,可以直接拿来用
语法
普通字符
字母、数字、汉字、下划线、以及没有特殊定义的标点符号,都是"普通字符"。
表达式中的普通字符,在匹配一个字符串的时候,匹配与之相同的一个字符。
简单的转义字符 
标准字符集合
能够与’多种字符’匹配的表达式
注意区分大小写,大写是相反的意思
自定义字符集合
它是用中括号[]匹配方式,能够匹配中括号中的任意一个字符(中括号里面是或的关系)
正则表达式的特殊符号,被包含到中括号中,则失去特殊意义,除了^和-之外。
标准字符集合,除小数点外,如果被包含于中括号,自定义字符集合将包含该集合。比如∶
[\d.\-+] 由于小数点在中括号中失去特殊意思,仅表示该本身;
-在中括号里有特殊含义,如果想表示减号,加\
将匹配︰数字、小数点、+、-

注意:^在中括号里面是取反的意思,在外面是字符串开头的意思
自定义字符集合特殊用法-量词
量词(Quantifier):修饰匹配次数的特殊符号
匹配次数中的贪婪模式(匹配字符越多越好,默认!)
匹配次数中的非贪婪模式(匹配字符越少越好,修饰匹配次数的特殊符号后再加上一个"?"号)
(?充当量词时表示0-1次,而量词后面加?表示开启非贪婪模式)
\d\d{6} 不是表示匹配12个数字,而是表示匹配7个数字,修饰的是前一个
(\d\d){6} 加括号才表示匹配12个数字
字符边界
本组标记匹配的不是字符而是位置,符合某种条件的位置
\b匹配这样一个位置:前面的字符和后面的字符不全是\w
字符边界匹配时是零宽的,匹配的是位置

匹配模式
IGNORECASE忽略大小写模式
匹配时忽略大小写。
默认情况下,正则表达式是要区分大小写的。
SINGLELINE单行模式
整个文本看作一个字符串,只有一个开头,一个结尾。
使小数点"."可以匹配包含换行符( \n )在内的任意字符。
MULTILINE多行模式
按行匹配,每行都是一个字符串,都有开头和结尾。
在指定了MULTILINE之后,如果需要仅匹配字符串开始和结束位置,可以使用\A和\Z
选择符和分组
| 表达式 | 作用 |
|---|---|
| | 分支结构 | 左右两边表达式之间"或"关系,匹配左边或者右边 |
| ( ) 捕获组 | 1. 在被修饰匹配次数的时候,括号中的表达式可以作为整体被修饰 2. 取匹配结果的时候,括号中的表达式匹配到的内容可以被单独得到 3. 每一对括号会分配一个编号,使用 ( ) 的捕获根据左括号的顺序从 1开始自动编号。捕获元素编号为 0 的第一个捕获是由整个正则表达式模式匹配的文本 |
| (?:Expression)非捕获组 | 一些表达式中,不得不使用 ( ),但又不需要保存 ( ) 中子表达式匹配内容,这时可以用非捕获组来抵消使用 ( ) 带来的副作用 |
反向引用
反向引用(\nnn)
每一对()会分配一个编号,使用()的捕获根据左括号的顺序从1开始自动编号。
通过反向引用,可以对分组已捕获的字符串进行引用。
([a-z]{2})\1 这里请注意:是把匹配到的字符重复一次,而不是重复一次表达式

用捕获组时,会把刚匹配到的字符存进内存里,以便于反复存取。所以在做大文本处理时,有些地方我们只想使用()的组织功能,又没有必要存进内存的,可以使用非捕获组。
预搜索(零宽断言)
只进行子表达式的匹配,匹配内容不计入最终的匹配结果,是零宽度
这个位置应该符合某个条件
判断当前位置的前/后字符,是否符合指定的条件,但不匹配前/后的字符**.是对位置的匹配**
正则表达式匹配过程中,如果子表达式匹配到的是字符内容,而非位置,并被保存到最终的匹配结果中,那么就认为这个子表达式是占有字符的;如果子表达式匹配的仅仅是位置,或者匹配的内容并不保存到最终的匹配结果中,那么就认为这个子表达式是零宽度的。占有字符还是零宽度,是针对匹配的内容是否保存到最终的匹配结果中而言的。


强调一点,零宽断言匹配到的是位置,不计入匹配结果
练习
电话号码验证
(1)电话号码由数字和"-“构成
(2)电话号码为7到8位
(3)如果电话号码中包含有区号,那么区号为三位或四位,首位是0
(4)区号用”-"和其他部分隔开
(5)移动电话号码为11位
(6)11位移动电话号码的第一位和第二位为"13 ",“15”,“18”
电子邮箱验证
1.用户名∶字母、数字、中划线、下划线组成。
2.@
3.网址:字母、数字组成。
4.小数点∶.
5.组织域名︰2-4位字母组成。
不区分大小写

这个图不一定是对的,匹配空白行我匹配不出来
其他妙用
各种环境下都可以使用正则
请注意,在开发环境中使用正则,某些语法有可能不支持
开发环境和文本编辑器中使用正则
eclipse
Notepad++
Editplus
UltraEdit
eclipse
Search-File-Regular expression

Notepad++
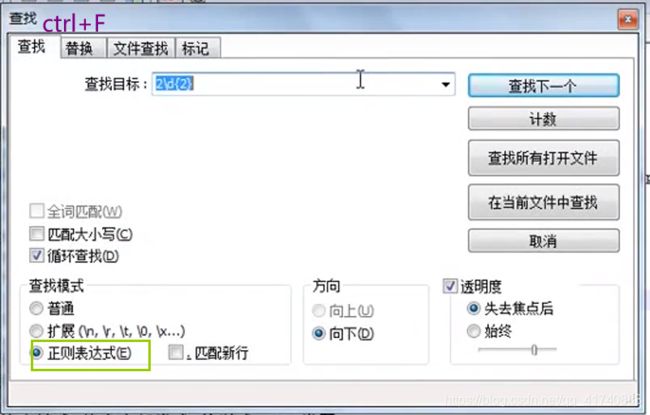
数据库中也可以使用正则
Mysql5.5以上
Oracle10g以上
SELECT prod_name FROM products WHERE prod_name REGEXP ‘.000’
.匹配任意字符
java中使用正则表达式(重点)
相关类位于:java.util.regex包下面
类Pattern :
正则表达式的编译表示形式。
Pattern p = Pattern.compile(r,int); //建立正则表达式,并启用相应模式
类Matcher :
通过解释Pattern对character sequence 执行匹配操作的引擎
Matcher m = p.matcher(str); //匹配str字符串
正则表达式用法非常简单,首先把正则表达式表示成java里的一个对象,然后把正则表达式和测试字符串用Matcher对象关联起来,然后再调用Matcher对象相关的方法进行查找。
字符串寻找
@org.junit.Test
public void RegexExpression1(){
//把正则表达式表示成java的对象
Pattern p =Pattern.compile("\\w+");
//创建Matcher对象,正则表达式对象和测试字符串用该Matcher对象关联起来
Matcher m =p.matcher("qwerasdf");
//尝试将整个字符序列与该模式匹配
boolean yesOrNo = m.matches();
System.out.println(yesOrNo); //true
}
@org.junit.Test
public void RegexExpression2() {
Pattern p = Pattern.compile("\\w+");
Matcher m = p.matcher("qwer##asdf");
//该方法扫描输入的序列,查找与该模式匹的下一个子序列
boolean yesOrNo = m.find();
System.out.println(m.group()); //qwer
boolean yesOrNo2 = m.find();
System.out.println(m.group()); //asdf
}
也可以改成循环的方式
@org.junit.Test
public void RegexExpression3() {
Pattern p = Pattern.compile("\\w+");
Matcher m = p.matcher("qwer##asdf");
while (m.find()){
//该方法扫描输入的序列,查找与该模式匹的下一个子序列
System.out.println(m.group());
//group(),group(0)匹配整个表达式的子字符串,意思是一样的
System.out.println(m.group(0));
}
}
@org.junit.Test
/**
* 测试正则表达式中的分组处理
*/
public void RegexExpression4() {
Pattern p = Pattern.compile("(([a-z]+)([0-9]+))");
//Pattern p = Pattern.compile("([a-z]+)([0-9]+)");
Matcher m = p.matcher("aaa111**bbb222***ccc333");
while (m.find()){
//该方法扫描输入的序列,查找与该模式匹的下一个子序列
System.out.println(m.group());
System.out.println(m.group(1));
System.out.println(m.group(2));
System.out.println(m.group(3));
//分组以左括号为主,最左边的(是第一组,如果角标不存在会报数组下标越界异常
}
}
运行结果:
aaa111
aaa111
aaa
111
bbb222
bbb222
bbb
222
ccc333
ccc333
ccc
333
字符串替换
@org.junit.Test
public void RegexExpression5() {
Pattern p = Pattern.compile("[0-9]");
Matcher m = p.matcher("aaa111**bbb222***ccc333");
//字符串替换
String newStr = m.replaceAll("+");
System.out.println(newStr); //aaa+++**bbb+++***ccc+++
}
字符串分割
@org.junit.Test
public void RegexExpression6() {
String str = "a88b998c0000";
String[] arrs = str.split("\\d+");
System.out.println(Arrays.toString(arrs)); //[a, b, c]
}
手写网络爬虫(重点)
目标:把某网页的源码爬下来,比如把图片都下载下来
这个笔记暂时不做了,从入门到入狱你懂得,有兴趣的玩玩即可,别走火入魔了。
笔记来自b站视频:java300集
下篇详细解释split用法https://blog.csdn.net/qq_41740883/article/details/111696866