论文阅读《High-frequency Stereo Matching Network》
论文地址:https://openaccess.thecvf.com/content/CVPR2023/papers/Zhao_High-Frequency_Stereo_Matching_Network_CVPR_2023_paper.pdf
源码地址: https://github.com/David-Zhao-1997/High-frequency-Stereo-Matching-Network
概述
在立体匹配研究领域,当前的方法在估计视差图的细微特征方面表现不足,尤其是在对象的边缘性能方面。此外,弱纹理区域的混淆匹配和细小物体的错误匹配也是模型性能表现不佳的重要因素。在迭代式的方法中,现有的基于GRU的结构存在一定局限性,用于生成视差图更新的信息与GRU的隐藏状态信息耦合在一起,使得在隐藏状态中保持细微的细节变得困难。
为了解决该问题,本文提出了 DLNR (Stereo Matching Network with Decouple LSTM and Normalization Refinement),该方法可以在迭代过程中保留更多的细节信息。同时,为了进一步提取高频的细节信息,本文提出了一个视差归一化细化模块,将视差值归一化为图像宽度上的视差比例,有效地减轻了模型跨域性能下降的问题。此外,为了克服传统resNet的特征提取瓶颈,本文引入了一个多尺度多层级的特征提取骨干网络,通过通道级自注意力机制来增强模型的特征提取能力。实验结果表明,本文在多个数据集上达到了最先进的水平。
模型架构
Channel-Attention Transformer extractor
受到 Restormer 的启发,作者设计了一个多阶段、多尺度的通道注意力transformer特征提取结构用于提取像素长程依赖特征与高频细节特征,如图3所示:
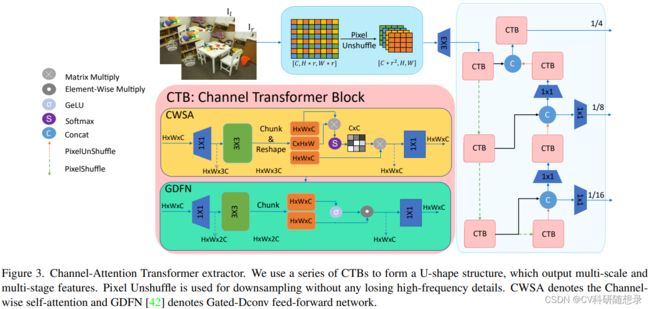
高频细节特征获取
文中采用 Pixel Unshuffle 来替代池化操作对图像进行下采样至原始大小的1/4,并扩展通道数,同时不丢失任何高频信息。原始图像的形状是 [ C , H ∗ r , W ∗ r ] [C, H * r, W * r] [C,H∗r,W∗r],经过Pixel Unshuffle后reshape为 [ C ∗ r 2 , H , W ] [C * r^2, H, W] [C∗r2,H,W]。这样可以在降低图像分辨率的同时,保留图像中的高频细节信息。
通道注意力机制
文中提出了CWSA模块(来源于Restromer中的MDTA)用于通道注意力,以减少原始通道注意力带来的计算量激增问题。
多尺度解耦LSTM正则化
在每次迭代中,迭代单元结合特征提取器从多尺度和多阶段信息 F l F_l Fl、 F m F_m Fm 和 F h F_h Fh,以及上一次迭代产生的隐藏状态 h i − 1 h_{i-1} hi−1、 C i − 1 C_{i-1} Ci−1 和先前的视差图 D i − 1 D_{i-1} Di−1,预测视差图的残差图 Δ D i \Delta D_i ΔDi。
多尺度结构
为了解决立体匹配中弱纹理区域的匹配难题,文中使用多尺度的迭代模块来充分利用1/4,1/8和1/16分辨率下的视图信息。每个子模块都与其余相邻的分辨率进行交互,低分辨率可以获得更大的感受野用于处理弱纹理区域的混淆匹配。高分辨率尺度可以提供更多的高频细节信息,为物体的边缘和角落提供更多细节。
解耦机制
传统的GRU结构的隐藏层特征 h h h 用于预测视差残差图,同时用于GRU模块之间的状态转移,导致模型无法保留更多的细节信息。为此,文中引入一个新的隐藏特征 C C C,如图4所示。

隐藏状态 h h h 用于通过视差头生成更新矩阵,而新引入的隐藏状态 C C C 仅用于在迭代之间传递信息。该设计将更新矩阵和隐藏状态解耦,可以在迭代过程中保留更多有效的语义信息。
视差归一化细化
为了缓解模型在地分辨率下细化导致的高频细节信息丢失问题,文中引入一个视差细化模块,如图5所示:

1/4尺度的视差图经过可学习的上采样模块上采样到原分辨率,继而将右视图根据视差图warp到左视图,用于计算误差图:
D f r = l e a r n e d U p s a m p l e ( D l r , u p M a s k ) I l ′ = w a r p ( I r , d i s p ) E l = I l ′ − I l (1) \begin{aligned} D^{fr}& =learnedUpsample(D^{lr},upMask) \\ I_{l}^{'}& =warp(I_r,disp) \\ E_{l}& =I_{l}^{'}-I_{l} \end{aligned}\tag{1} DfrIl′El=learnedUpsample(Dlr,upMask)=warp(Ir,disp)=Il′−Il(1)
上采样后的视差图被缩放到0到1之间,且 D f r D^{fr} Dfr 的最小值通常为0。文中使用图像的宽度来作为最大视差值将所有像素点的视差值归一化:
D N o r m f r = D f r − m i n ( D f r ) w i d t h ( I l ) (2) D_{Norm}^{fr}=\frac{D^{fr}-min(D^{fr})}{width(I_l)}\tag{2} DNormfr=width(Il)Dfr−min(Dfr)(2)
将归一化视差图 D N o r m f r D_{Norm}^{fr} DNormfr,误差图 E l E_{l} El 与左视图 I l I_l Il 送入视差细化模块中得到正则化后的视差图 D f r ′ D^{fr'} Dfr′:
I e r r = C o n v 3 × 3 ( [ E l , I l ] ) D f r ′ = h o u r g l a s s ( [ I e r r , C o n v 3 × 3 ( D N o r m f r ) ] ) (3) \begin{aligned}I_{err}&=Conv_{3\times3}([E_l,I_l])\\D^{fr'}&=hourglass([I_{err},Conv_{3\times3}(D_{Norm}^{fr})])\end{aligned}\tag{3} IerrDfr′=Conv3×3([El,Il])=hourglass([Ierr,Conv3×3(DNormfr)])(3)
最后根据归一化视差图计算原始视差图:
D r e f i n e d = D f r ′ × w i d t h ( I l ) + m i n ( D f r ′ ) (4) D_{refined}=D^{fr^{\prime}}\times width(I_l)+min(D^{fr^{\prime}})\tag{4} Drefined=Dfr′×width(Il)+min(Dfr′)(4)
损失函数
L = ∑ i = 1 n − 1 γ n − i L 1 + L r e f i n e , w h e r e γ = 0.9. L 1 = ∣ ∣ d g t − d i ∣ ∣ 1 L r e f i n e = ∣ ∣ d g t − d r e f i n e d ∣ ∣ 1 (5) \begin{aligned} \text{L}& =\sum_{i=1}^{n-1}\gamma^{n-i}L_1+L_{refine},where\gamma=0.9. \\ L_{1}& =\left|\left|d_{gt}-d_i\right|\right|_1 \\ L_{refine}& =\left|\left|d_{gt}-d_{refined}\right|\right|_1 \end{aligned}\tag{5} LL1Lrefine=i=1∑n−1γn−iL1+Lrefine,whereγ=0.9.=∣∣dgt−di∣∣1=∣∣dgt−drefined∣∣1(5)
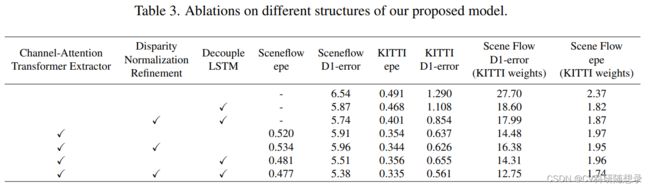
实验结果