一位Java小白的学习随录-初识JVM
JVM
1.什么是JVM?
JVM(Java Virtual Machine,Java虚拟机)
- Java程序的跨平台特性主要是指字节码文件可以在任何具有Java虚拟机的计算机或者电子设备上运行,Java虚拟机中的Java解释器负责将字节码文件解释成为特定的机器码进行运行。因此在运行时,Java源程序需要通过编译器编译成为.class文件。
- jvm虚拟机类似vmware等,只不过虚拟的机器在实际中不存在,只是软件环境。
目前jvm使用的是hotspot虚拟机(hotspot最初是一家小公司开发,后被sun收购)。
jvm执行class文件,除了java可以生产class外,jruby、groovy等语言也可以生成class让jvm执行。
内部以补码表示数据,因为这样做加法可以直接用补码相加,非常方便。
正数的补码是本身,负数的补码是按位取反加1。
2.JVM启动流程

其中windows的jvm.cfg在

jvm.dll在

linux同理(可以用find / -name jvm.cfg来查找)
3.JVM的结构
(从前辈那儿盗的图)
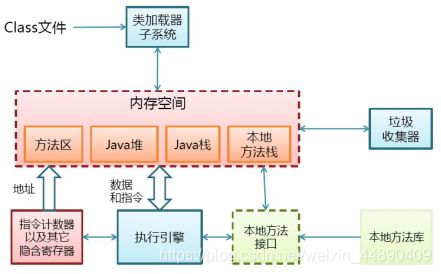
分为方法区、堆、栈等,此外在jvm外还可以直接在操作系统上分配内存,称为直接内存。jmm是java内存模型(java memory model)
-PC计数器(程序计数器、PC寄存器)
当前线程的执行的行号指示器。
每个线程拥有一个PC寄存器
在线程创建时创建
指向下一条指令的地址
执行本地方法(Native)时,它的值为undefined
jvm中唯一一个不会产生OutOfMemoryError的区域。
-方法区
保存装载的类信息,通常也叫做永久区(Perm)
方法区是jvm的一个规范,是一个逻辑区,不同的虚拟机的实现是不同的,JDK1.8之前,Hotspot是把方法区放在了"堆"的永久代中,JDK1.8之后永久代被移除了,于是方法区被放在了与堆不相关的本地内存中一个叫做"元空间(Metaspace)"中。
因此jdk8中的-XX:MaxPermSize已经失效了,取而代之的是-XX:MaxMetaspaceSize参数。
1、存放类、方法、接口等描述信息
2、常量池:数据在编译期被确定,编译到了class文件,分为:
字面量:文本字符串、声明为final的常量值等;
符号引用:类和接口的完全限定名(Fully Qualified Name)、字段的名称和描述符(Descriptor)、方法的名称和描述符
3、运行时常量池:
方法区的一部分,所有线程共享。虚拟机加载Class后把常量池中的数据放入到运行时常量池。运行时常量池可以在程序运行的时候动态增加,比如String.intern()方法,会将程序中的字符串放入运行时常量池。
JDK6时,String等常量信息置于方法区
JDK7时,已经移动到了堆

-堆
存放对象,所有线程共享。堆是分代的,分为年轻代、老年代等
堆分为:年轻代、老年代、永久代(也叫方法区,存放加载的类信息、常量、静态变量、即时编译器编译后的代码等数据,jdk1.8以前方法区在堆里面,1.8以后是单独的,在元空间)。
年轻代也叫新生代,分为1个eden区和2个survivor区(s0和s1),新生代存放新创建的对象,满了以后,会触发Scavenge GC,回收非存活对象,同时将存活对象放入survivor区,survivor区的from和to会在gc时从from移动到to,当to满的时候,就把对象移动到老年代,同时from和to互换。因此只有多次Scavenge GC都存活的对象,才会放入老年代。Scavenge GC不会触发老年代和永久代的垃圾回收。老年代满了以后,会触发full gc,会清除老年代和永久代的非存活对象。
survivor区的两个总有一个是空的,from和to的大小是相等的,因此统计大小的时候只算其中一个的。
新生代GC也叫Young GC或者Minor GC,老年代GC叫Full GC
当Eden区满时,还存活的对象将被复制到Survivor区(两个中的一个),当这个Survivor区满时,此区的存活对象将被复制到另外一个Survivor区,当这个Survivor区也满了的时候,从第一个Survivor区复制过来的并且此时还存活的对象,将被复制“年老区(Tenured)”。需要注意,Survivor的两个区是对称的,没先后关系,所以同一个区中可能同时存在从Eden复制过来 对象,和从前一个Survivor复制过来的对象,而复制到年老区的只有从第一个Survivor去过来的对象。而且,Survivor区总有一个是空的。同时,根据程序需要,Survivor区是可以配置为多个的(多于两个),这样可以增加对象在年轻代中的存在时间,减少被放到年老代的可能。
一般情况下,当新对象生成,并且在Eden申请空间失败时,就会触发Scavenge GC,对Eden区域进行GC,清除非存活对象,并且把尚且存活的对象移动到Survivor区。然后整理Survivor的两个区。这种方式的GC是对年轻代的Eden区进行,不会影响到年老代。因为大部分对象都是从Eden区开始的,同时Eden区不会分配的很大,所以Eden区的GC会频繁进行。因而,一般在这里需要使用速度快、效率高的算法,使Eden区能尽快空闲出来。
full gc对整个堆进行整理,包括Young、Tenured和Perm。Full GC因为需要对整个对进行回收,所以比Scavenge GC要慢,因此应该尽可能减少Full GC的次数。在对JVM调优的过程中,很大一部分工作就是对于FullGC的调节。
有如下原因可能导致Full GC:
· 年老代(Tenured)被写满
· 持久代(Perm)被写满
· System.gc()被显示调用
·上一次GC之后Heap的各域分配策略动态变化
垃圾回收优先回收年轻代对象,年轻代多次未被回收的对象进入老年代。永久代很少回收.

- 栈
每个线程创建的时候创建一个栈,线程每次调用方法时分配一个栈帧,然后压入线程栈中。栈帧由局部变量表、操作数栈、帧数据区(例如常量池指针等)组成。
java没有数据寄存器,所有参数传递都靠”操作数栈”,有返回值的方法返回时,会把返回值放到调用者方法的操作数栈中。
这里要注意,java的参数传递只有一种:“值传递”
下面引用一位前辈的文章,方便理解和记忆:
(1):“在Java里面参数传递都是按值传递”这句话的意思是:按值传递是传递的值的拷贝,按引用传递其实传递的是引用的地址值,所以统称按值传递。
(2):在Java里面只有基本类型和按照下面这种定义方式的String是按值传递,其它的都是按引用传递。就是直接使用双引号定义字符串方式:String str = “Java私塾”;
————————————————
版权声明:本文为CSDN博主「散仙一个」的原创文章,遵循CC 4.0 by-sa版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/p4885056000/article/details/79105922
线程的栈空间通常很小,只有几百k,因为每个线程单独占用一个栈空间,几百k乘以线程数,就是总的占用空间,因此,栈空间越小,服务器所能运行的线程数越多,而栈空间决定了函数调用的深度,在有递归调用等情况下,栈空间不能太小。
局部变量表:包含方法参数和局部变量
如:

这里右边是局部变量表的槽位,1个槽位32位,long占64位,所以占用了2个槽位(1和2),其他类型如引用类型都占32位
第二个方法runInstance是非静态的,所以第一个槽位存放了this的引用
一个线程的栈如果满了会溢出,导致java.lang.StackOverflowError异常。
增大调用深度,可以通过配置-Xss的栈空间参数或者调用减少方法的参数和局部变量(减少方法消耗的栈空间)等方式。
栈的操作示例
先将a、b入栈,然后出栈计算,将结果入栈,最后返回时将结果出栈。

栈上分配(逃逸分析)
1.7以上的jvm内部会自动分析方法内创建的对象会不会被方法外引用(如返回对象引用、将对象引用赋值给全局变量等),如果不会,则会尝试将对象创建到栈上,而不是堆上,提高访问效率。分析的过程叫做“逃逸分析”
如:
public class OnStackTest {
public static void alloc(){
byte[] b=new byte[2];
b[0]=1;
}
public static void main(String[] args) {
long b=System.currentTimeMillis();
for(int i=0;i<100000000;i++){
alloc();
}
long e=System.currentTimeMillis();
System.out.println(e-b);
}
}
如果运行时加参数
-XX:+DoEscapeAnalysis -XX:+PrintGC
则:

其中+DoEscapeAnalysis表示需要进行逃逸分析,+PrintGC表示打印gc日志,此时会在栈上分配new byte[2],只执行了4毫秒,没有GC操作。

如果用参数-XX:-DoEscapeAnalysis -XX:+PrintGC表示不进行逃逸分析,new byte[2]将在堆上分配,打印如下:

进行了多次GC,用时701毫秒
逃逸分析优势:
消除同步,线程同步的代价是相当高的,同步的后果是降低并发性和性能。逃逸分析可以判断出某个对象是否始终只被一个线程访问,如果只被一个线程访问,那么对该对象的同步操作就可以转化成没有同步保护的操作,这样就能大大提高并发程度和性能。也叫“锁省略”。
栈上分配:避免堆上分配的开销,性能得到很大提升。
劣势:
栈上分配受限于栈的空间大小,一般自我迭代类的需求以及大的对象空间需求操作,将导致栈的内存溢出;故只适用于一定范围之内的内存范围请求,大对象或者逃逸对象无法在栈上分配。
对象创建时在栈上保存引用,堆上创建对象。
线程工作内存和主内存
每一个线程都有自己独立的工作内存,所有的线程有共享的主内存,对象的成员变量等就放在主内存中,线程操作主内存时,先从主内存把变量复制一份到自己的工作内存中,线程执行完后再把更新后的变量写回主内存。
读取时:线程load,主内存read
回写时:线程store,主内存write
因为线程执行过程中使用的都是从主内存中复制的变量,因此线程在执行过程中,如果其他线程改变了主内存的变量值,当前线程是不知道的,如果变量加了volatile关键字修饰,则每次操作都会立即同步到主内存。
如:
public class VolatileStopThread extends Thread {
private volatile boolean stop = false;
public void stopMe() {
stop = true;
}
public void run() {
int i = 0;
while (!stop) {
i++;
}
System.out.println("Stop thread");
}
public static void main(String args[]) throws InterruptedException {
VolatileStopThread t = new VolatileStopThread();
t.start();
Thread.sleep(1000);
t.stopMe();
Thread.sleep(1000);
}
}
一个线程不断地 i++,另一个线程通过stop标记控制它停止,如果没有volatile关键字,则无法控制其停止,因为它只会读取工作内存的stop标记,它并不知道另一个线程已经修改了主内存的stop标记值。
也可以用synchronized,synchronized方法执行完时,会回写主内存。不过同步开销较大。
volatile不能代替synchronized,因为它只能保证每次操作从主内存读写,而不能保证线程安全性。
如:
public class Counter {
public volatile static int count = 0;
public static void inc() {
//这里延迟1毫秒,让结果明显些
try {
Thread.sleep(1);
} catch (InterruptedException e){
}
count ++;
}
public static void main (String[] args) {
//同时启动1000个线程,进行i++运算,看看实际结果
for(int i = 0; i < 1000; i++){
new Thread(new Runnable(){
@Override
public void run() {
Counter.inc();
}
}).start();
}
//这里每次运算的值都可能不同,也有可能等于1000
System.out.println("运行结果:Counter.count=" + Counter.count);
}
}
运行结果如下:

count++本身线程不安全,有可能两个线程并发同时读取到同样的count值,然后+1,回写两次同样的值。
结论:
1.volatile解决了线程间共享变量的可见性问题
2.使用volatile会增加性能开销
3.volatile并不能解决线程同步问题
4.解决i++或者++i这样的线程同步问题需要使用synchronized或者AtomicXX系列的包装类,同时也会增加性能开销