计算机网络:应用层(下篇)
文章目录
- 前言
- 一 、电子邮件(Email)
-
- 1.邮件服务器
- 2.SMTP[RFC 2821]
- 3.邮件报文格式
- 4.邮件访问协议
- 二、DNS(域名系统)
-
- 1.DNS的历史
- 2.DNS总体思路和目标
-
- (1)问题1:DNS名字空间
- (2)问题2:解析问题-名字服务器
- (3)问题3:维护问题-新增一个域
- 三、P2P应用
-
- 1. 纯P2P架构
- 2.文件分发
-
- P2P文件共享
-
- 非结构化P2P
- 结构化:DHT
- 三、CDN(Content Distribution Network)
-
- 1.多媒体:视频
- 2.多媒体流化服务
- 3.CDN(内容分发网络)
- 总结
前言
SMTP、DNS、P2P应用、CDN视频流化服务。
一 、电子邮件(Email)
- 3个主要组成部分:
- 用户代理
- 邮件服务器
- 简单邮件传输协议:SMTP
- 用户代理
- 又名“邮件阅读器”
- 撰写、编辑和阅读邮件
- 如Outlook、Foxmail
- 输出和输入邮件保存在服务器上
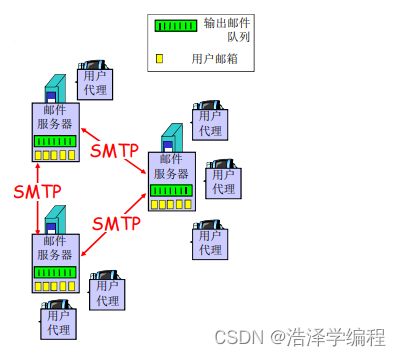
1.邮件服务器
- 邮件服务器
- 邮箱中管理和维护发送给用户的邮件
- 输出报文队列保持待发送邮件报文
- 邮件服务器之间的SMTP协议:发送email报文
- 客户:发送方邮件服务器
- 服务器:接收端邮件服务器
2.SMTP[RFC 2821]
- 使用TCP在客户端和服务器之间传送报文,端口号为25
- 直接传输:从发送方服务器到接收方服务器
- 传输的3个阶段
- 握手
- 传输报文
- 关闭
- 命令/响应交互
- 命令:ASCII文本
- 响应:状态码和状态信息
- 报文必须为7位ASCII码
例子:
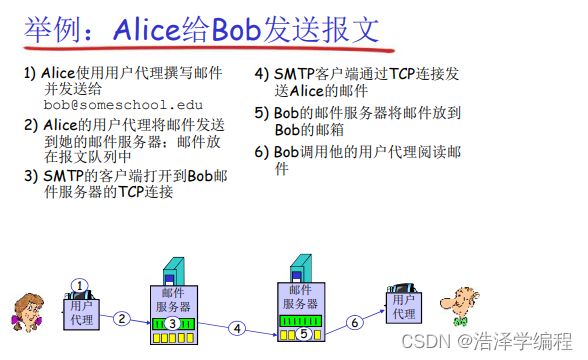
简单SMTP交互:

总结:
- SMTP使用持久连接
- SMTP要求报文(首部和主体)为7位ASCII编码
- SMTP服务器使用CRLF.CRLF决定报文的尾部
HTTP比较:
- HTTP:拉(pull)
- SMTP:推( push)
- 二者都是ASCII形式的命令/响应交互、状态码
- HTTP:每个对象封装在各自的响应报文中
- SMTP:多个对象包含在一个报文中
3.邮件报文格式
- SMTP:交换email报文的协议 RFC 822:文本报文的标准:
- 首部行:如,
- To:
- From:
- Subject:与SMTP命令不同!
- 主体
- 报文,只能是ASCII码字符
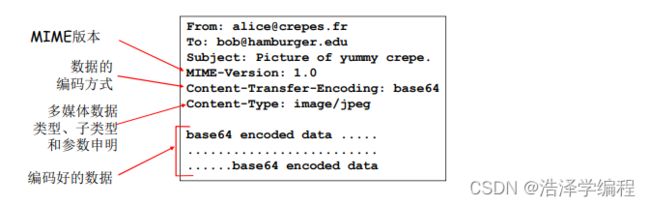
报文格式:多媒体扩展
- MIME:多媒体邮件扩展(multimedia mail extension) ,RFC 2045,2056
- 在报文首部用额外的行申明MIME内容类型
- 它扩展了电子邮件标准,使其能够支持:非ASCII字符文本、非文本格式附件(二进位制、声音、图片等)等。
4.邮件访问协议
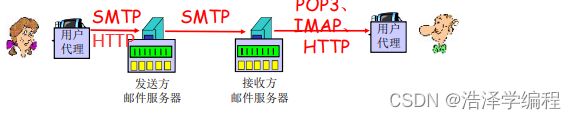
- SMTP:传送到接收方的邮件服务器
- 邮件访问协议:从服务器访问邮件
- POP:邮局访问协议(Post Office Protocol)[RFC 1939]
- 用户身份确认(代理<–>服务器)并下载
- IMAP: Internet邮件访问协议(Internet Mail Access Protocol[RFC 1730]
- 更多特性(更复杂)
- 在服务器上处理存储的报文
- HTTP: Hotmail , yahoo! Mail等
- 方便
- POP:邮局访问协议(Post Office Protocol)[RFC 1939]
POP3协议
- 用户确认阶段客户端命令:
- user:申明用户名
- pass:口令
- 服务器响应
- +OK
- -ERR
- 事物处理阶段,客户端:
- list:报文号列表
- retr:根据报文号检索报文
- dele:删除
- quit

- “下载并删除”模式
- 如果改变客户机,Bob不能阅读邮件
- “下载并保留”:不同客户机上为报文的拷贝
- POP3在会话中是无状态的
IMAP
- IMAP服务器将每个报文与一个文件夹联系起来
- 允许用户用目录来组织报文
- 允许用户读取报文组件
- IMAP在会话过程中保留用户状态:
- 目录名、报文ID与目录名之间映射
- Bob用户不能使用SMTP得到报文,因为取报文是一个拉操作,而SMTP是一个推协议。
- Bob从邮件服务器取回邮件有两种常用方式:一种是使用基于web的电子邮件或智能手机上的客户端,则用户代理将使用HTTP接口和SMTP接口(与Alice的邮件服务器通信);另一种讲就是使用IMAP协议,这通常用于微软的outLook等。HTTP和IMAP都支持BOb管理自己邮件服务器中的文件夹,包括将邮件移动到他创建的文件夹中,删除邮件,标记为重要邮件。
二、DNS(域名系统)
DNS的必要性
- IP地址标识主机、路由器
- 但IP地址不好记忆,不便人类使用(没有意义)
- 人类一般倾向于使用一些有意义的字符串来标识Internet上的设备
- 例如: [email protected]所在的邮件服务器、www.ustc.edu.cn所在的web服务器
- 存在着“字符串”一IP地址的转换的必要性
- 人类用户提供要访问机器的“字符串”名称
- 由DNS负责转换成为二进制的网络地址
DNS系统需要解决的问题
- 问题1:如何命名设备
- 用有意义的字符串:好记,便于人类用使用
- 解决一个平面命名的重名问题:层次化命名
- 问题2:如何完成名字到IP地址的转换
- 分布式的数据库维护和响应名字查询
- 问题3:如何维护:增加或者删除一个域,需要在域名系统中做哪些工作
1.DNS的历史
- ARPANET的名字解析解决方案
- 主机名:没有层次的一个字符串(一个平面)
- 存在着一个(集中)维护站:维护着一张主机名-IP地址的映射文件: Hosts.txt
- 每台主机定时从维护站取文件
- ARPANET解决方案的问题
- 网络中主机数量很大时
- 没有层次的主机名称很难分配
- 文件的管理、发布、查找都很麻烦
- 网络中主机数量很大时
2.DNS总体思路和目标
- DNS的主要思路
- 分层的、基于域的命名机制
- 若干分布式的数据库完成名字到IP地址的转换
- 运行在UDP之上端口号为53的应用服务
- 核心的Internet功能,但以应用层协议实现
- 在网络边缘处理复杂性
- DNS主要目的:
- 实现主机名-IP地址的转换(name/IP translate)
- 其它目的
- 主机别名到规范名字的转换: Host aliasing
- 邮件服务器别名到邮件服务器的正规名字的转换:Mail serveraliasing
- 负载均衡: Load Distribution
负载均衡(load distribution):DNS也用于在冗余的服务器(如冗余的Web服务器等)之间进行负载分配。繁忙的站点(如cnn. com)被冗余分布在多台服务器上,每台服务器均运行在不同的端系统上,每个都有着不同的P地址。由于这些冗余的Web服务器,一个P地址集合因此与同一个规范主机名相联系。DNS数据库中存储着这些IP地址集合。当客户对映射到某地址集合的名字发出一个 DNS请求时,该服务器用IP地址的整个集合进行响应,但在每个回答中循环这些地址次序。因为客户通常总是向IP地址排在最前面的服务器发送HTTP请求报文,所以DNS就在所有这些冗余的Web服务器之间循环分配了负载。DNS的循环同样可以用于邮件服务器,因此,多个邮件服务器可以具有相同的别名。一些内容分发公
(1)问题1:DNS名字空间
- DNS域名结构
- 一个层面命名设备会有很多重名
- NDS采用层次树状结构的命名方法
- Internet根被划为几百个顶级域(top lever domains)
- 通用的(generic)
.com; .edu ; .gov ; .int ; .mil ; .net ;.org.firm ; .hsop : .web ; .arts ;.rec ; - 国家的(countries)
.cn ; .us ;.nl ; .jp
- 通用的(generic)
- 每个(子)域下面可划分为若干子域(subdomains)
- 树叶是主机
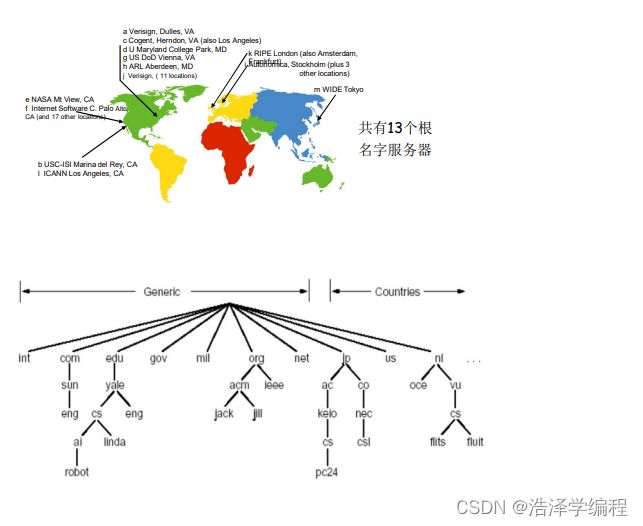
- 域名(Domain Name)
- 从本域往上,直到树根
- 中间使用“.”间隔不同的级别
- 例如: ustc.edu.cn
auto.ustc.edu.cn
www.auto.ustc.edu.cn - 域的域名:可以用于表示一个域
- 主机的域名:一个域上的一个主机
- 域名的管理
- 一个域管理其下的子域
.jp被划分为ac.jp co.jp
.cn被划分为edu.cn com.cn - 创建一个新的域,必须征得它所属域的同意
- 一个域管理其下的子域
- 域与物理网络无关
- 域遵从组织界限,而不是物理网络
- 一个域的主机可以不在一个网络
- 一个网络的主机不一定在一个域
- 域的划分是逻辑的,而不是物理的
- 域遵从组织界限,而不是物理网络
(2)问题2:解析问题-名字服务器
- 单一名字服务器的问题(一个DNS服务器存在的问题)
- 可靠性问题:单点故障(如果该DNS服务器崩溃,整个因特网随之瘫痪!)
- 扩展性问题:通信容量(单个服务器不得不处理所有的DNS查询(用于为上亿台主机产生的所有HTTP请求报文和电子用邮件报文服务))
- 维护问题:远距离的集中式数据库(单个 DNS服务器将不得不为所有的因特网主机保留记录。这不仅将使这个中央数据库非常庞大,而且它还不得不为解决每个新添加的主机而频繁更新。)
- 区域(zone)
- 区域的划分有区域管理者自己决定
- 将DNS名字空间划分为互不相交的区域,每个区域都是树的一部分
- 名字服务器:
- 每个区域都有一个名字服务器:维护着它所管辖区域的权威信息(authoritative record)
- 名字服务器允许被放置在区域之外,以保障可靠性
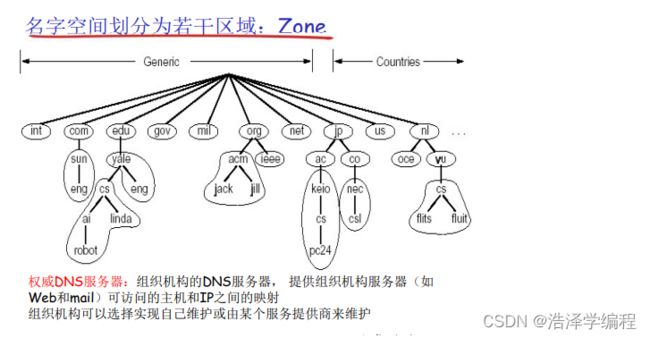
TLD服务器
- 顶级域(TLD)服务器:负责顶级域名(如com, org, net,edu和gov)和所有国家级的顶级域名(如cn, uk,fr , ca,jp )
- Network solutions公司维护com TLD服务器
- Educause公司维护edu TLD服务器
区域名字服务器维护:
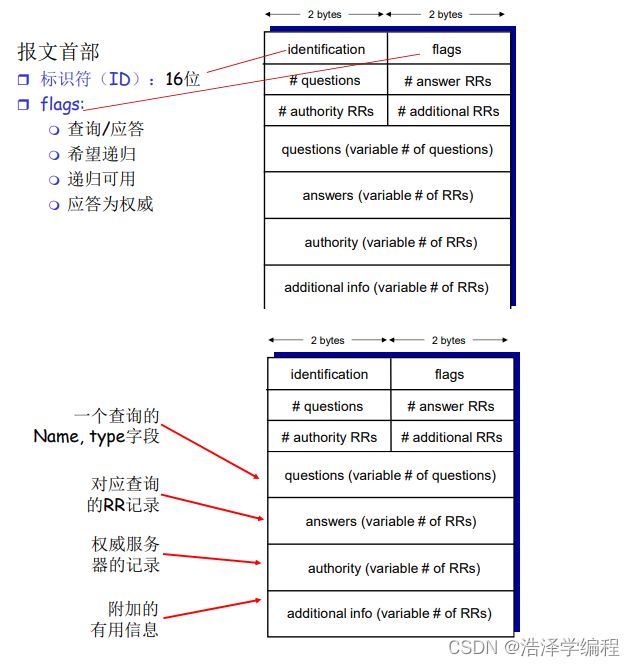
- 资源记录(resource records)
- 作用:维护域名-IP地址(其它)的映射关系
- 位置:Name Server的分布式数据库中
- 资源记录(RR)是一个包含了四个字段的4元组:(Name,Value,Type,TTL)
- Domain_name:域名
- TTL: time to live ,是该记录的生存时间,它决定了资源记录应当从缓存中删除的时间。
- Class类别:对于Internet,值为IN
- Value值:可以是数字,ip地址,域名或ASCII串
- Type类别:资源记录的类型,见下面
DNS记录:

DNS大致工作过程
- 应用调用解析器(resolver)
- 解析器作为客户向Name Server发出查询报文(封装在UDP段中)
- Name Server返回响应报文(name/ip)
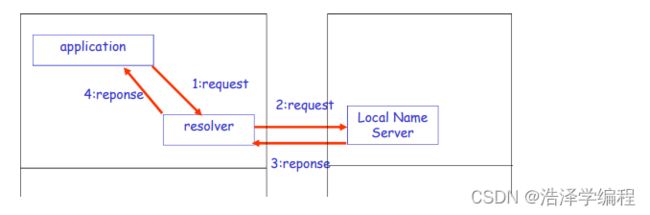
本地名字服务器
- 并不严格属于层次结构
- 每个ISP(居民区的ISP、公司、大学)都有一个本地DNS服务器
- 也称为“默认名字服务器”
- 当一个主机发起一个DNS查询时,查询被送到其本地DNS服务器
- 起着代理的作用,将查询转发到层次结构中
名字服务器
- 名字解析过程
- 目标名字在Local Name Server中
- 情况1:查询的名字在该区域内部
- 情况2:缓存(cashing)
- 目标名字在Local Name Server中
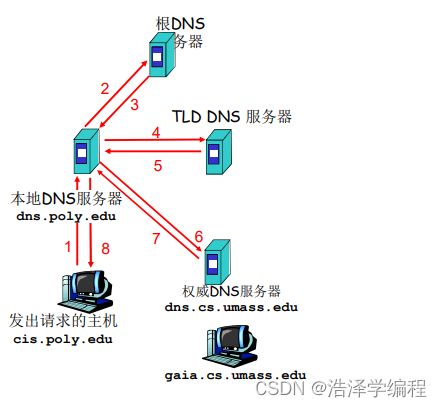
当与本地名字服务器不能解析名字时,联系根名字服务器顺着根-TLD一直找到权威名字服务器

查找权威名字服务器有两种查询方式
递归查询:
- 顺着根服务器到子服务器找
- 递归查询:名字解析负担都放在当前联络的名字服务器上
- 问题:根服务器的负担太重
- 解决:迭代查询(iteratedqueries)

迭代查询:
- 主机cis.poly.edu想知道主机 gaia.cs.umass.edu的IP地址
- 根(及各级域名)服务器返回的不是查询结果,而是根的下一层名字服务器的地址,然后本地服务器去这个名字服务器找,这个个名字服务器不知道也返回一个线索(它的下一层名字服务器的地址),然后本地服务请器再去告知的服务器…
- 直到找到权威服务器,最后由权威名字服务器给出解析结果
- 当前联络的服务器给出可以联系的服务器的名字
- “我不知道这个名字,但可以向这个服务器请求”
- 找到后还会缓存地址,方便一定失效时期内再次访问
DNS协议、报文
提高性能:缓存
- 一旦名字服务器学到了一个映射,就将该映射缓存起来
- 根服务器通常都在本地服务器中缓存着
- 使得根服务器不用经常被访问
- 目的:提高效率
- 可能存在的问题:如果情况变化,缓存结果和权威资源记录不一致
- 解决方案:TTL(默认2天)
(3)问题3:维护问题-新增一个域
- 在上级域的名字服务器中增加两条记录,指向这个新增的子域的域名和域名服务器的地址
- 在新增子域的名字服务器上运行名字服务器,负责本域的名字解析:名字->IP地址
例子:在com域中建立一个“Network Utopia”
- 到注册登记机构注册域名networkutopia.com
- 需要向该机构提供权威DNS服务器(基本的、和辅助的)的名字和IP地址
- 登记机构在com TLD服务器中插入两条RR记录:
(networkutopia.com,dns1.networkutopia.com,NS):域名和该域名的权威服务器域名
(dns1.networkutopia.com,212.212.212.1,A):主机,ip地址
- 在networkutopia.com的权威服务器中确保有
- 用于Web服务器的www.networkuptopia.com的类型为A的记录
- 用于邮件服务器mail.networkutopia.com的类型为MX的记录
攻击DNS
- DDoS攻击
- 对根服务器进行流量轰炸攻击:发送大量ping
- 没有成功
- 原因1:根目录服务器配置了流量过滤器,防火墙
- 原因2: Local DNS服务器缓存了TLD服务器的IP地址,因此无需查询根服务器
- 向TLD服务器流量轰炸攻击:发送大量查询
- 可能更危险
- 效果一般,大部分DNS缓存了TLD
- 对根服务器进行流量轰炸攻击:发送大量ping
- 重定向攻击
- 中间人攻击
- 截获查询,伪造回答,从而攻击某个(DNS回答指定的IP)站点
- DNS中毒
- 发送伪造的应答给DNS服务器,希望它能够缓存这个虚假的结果
- 技术上较困难:分布式截获和伪造
- 中间人攻击
- 利用DNS基础设施进行DDoS
- 伪造某个IP进行查询,攻击这个目标IP
- 查询放大,响应报文比查询报文大
- 效果有限
- 总的来说,DNS比较健壮
三、P2P应用
1. 纯P2P架构
- 没有(或极少)一直运行的服务器
- 任意端系统都可以直接通信
- 利用peer的服务能力
- Peer节点间歇上网,每次IP地址都有可能变化
例子:
- 文件分发(BitTorrent)
- 流媒体(KanKan)
- VoIP (Skype)
2.文件分发
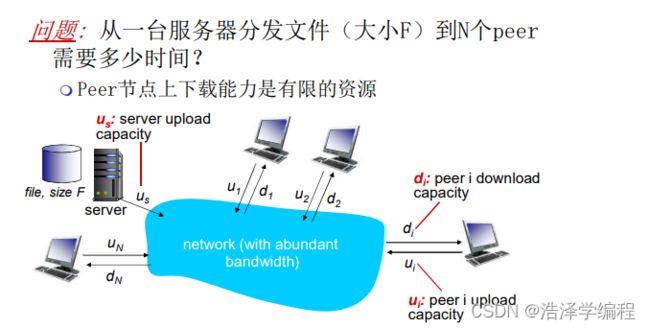
C/S模式
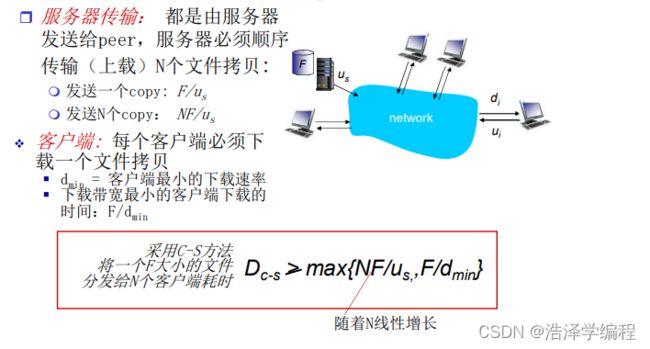
P2P模式
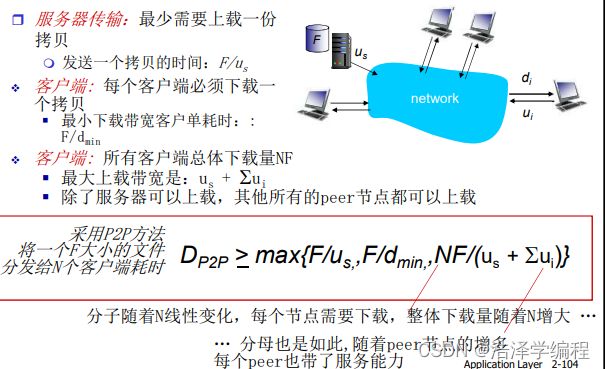
比较

P2P文件共享
- 例子
- Alice在其笔记本电脑上运行P2P客户端程序
- 间歇性地连接到Internet,每次从其ISP得到新的IP地址
- 请求“双截棍.MP3”应用程序显示其他有“双截棍.MP3”拷贝的对等方
- Alice选择其中一个对等方,如Bob.
- 文件从Bob’sPC传送到Alice的笔记本上: HTTP
- 当Alice下载时,其他用户也可以从Alice处下载
- Alice的对等方既是一个Web客户端,也是一个瞬时Web服务器
- 所有的对等方都是服务器 = 可扩展性好!
- 两大问题:
- 如何定位所需资源
- 如何处理对等方的加入与离开
- 可能的方案
- 集中
- 分散
- 半分散
非结构化P2P
P2P:集中式目录
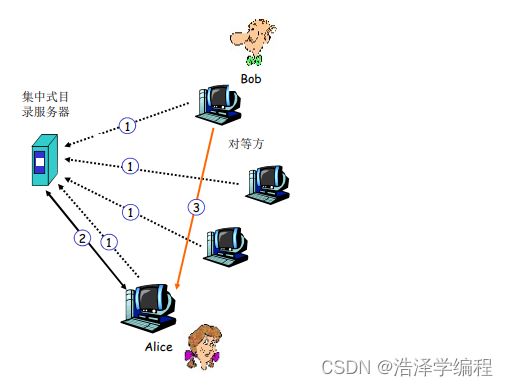
最初的“Napster”设计
- 1)当对等方连接时,它告知中心服务器:
- IP地址
- 内容
- 2)Alice查询“双截棍.MP3”
- 3)Alice从Bob处请求文件
- 文件传输是分散的,而定位内容则是高度集中的
存在的问题:
- 单点故障
- 性能瓶颈
- 侵犯版权
P2P:完全分布式
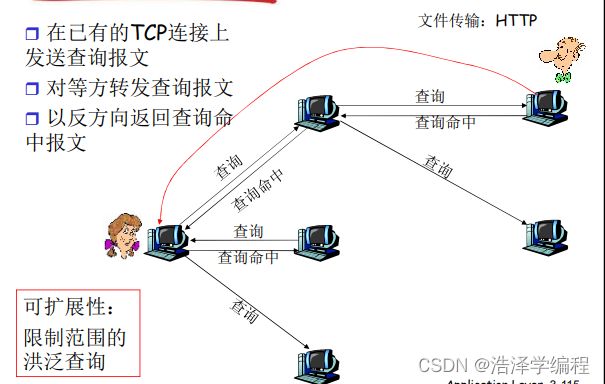
Gnutella:协议:
- 在已有的TCP连接上发送查询报文
- 对等方转发查询报文以反方向返回查询命中报文
- 以反方向返回查询命中报文

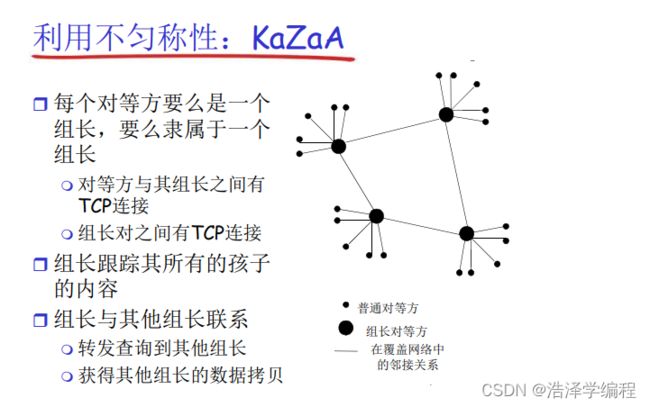
P2P:混合体


P2P文件分发:BitTorrent
- BitTorrent是一种用于文件分发的流行P2P协议
- 文件被分为一个个块256KB
- 网络中的这些peers发送接收文件块,相互服务
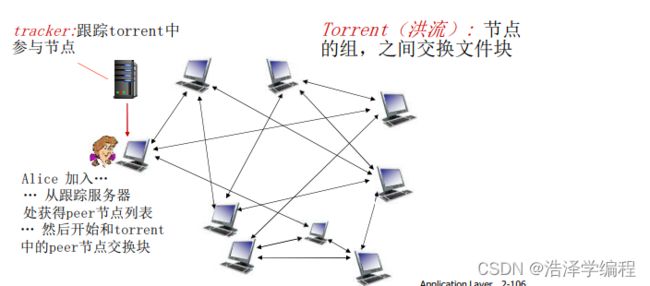
- Peer加入torrent(洪流) :
- 一开始没有块,但是将会通过其他节点处累积文件块
- 向跟踪服务器注册,获得peer节点列表,和部分peer节点构成邻居关系(“连接”)
- 当peer下载时,该peer可以同时向其他节点提供上载服务
- Peer可能会变换用于交换块的peer节点
- 扰动churn: peer节点可能会上线或者下线
- 一旦一个peer拥有整个文件,它会(自私的)离开或者保留(利他主义)在torrent中
BitTorrent:请求,发送文件块
- 请求块:
- 在任何给定时间,不同peer节点拥有一个文件块的子集
- 周期性的,Alice节点向邻居询问他们拥有哪些块的信息
- 获得四个文件块
- Alice再向peer节点请求它希望的块,稀缺的块,在这期间,其他peer可以向他请求块(先随机获取四块,是因为如果获取稀缺块,等待时间过长,而且此时获取时还可以向其他peer发送块,再获取稀缺块是因为稀缺块少,防止持有稀缺块的peer下线,获取后,稀缺块又多了peer,能更好的提供服务)
- 再获取其他块
- 有一个文件全部的peer,他就是种子,啥都没有,就是吸血鬼了。
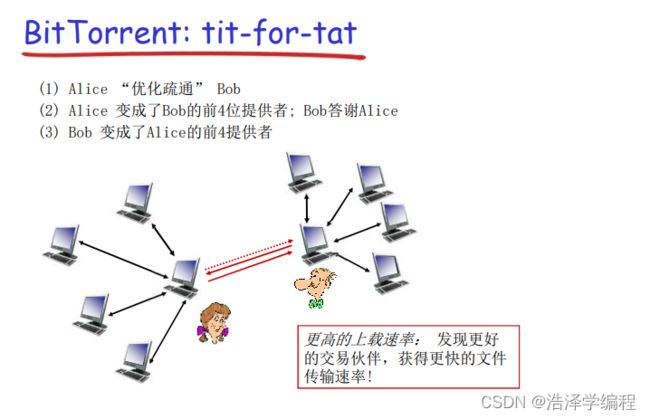
- 发送块:一报还一报tit-for-tat
- Alice向4个peer发送块,这些块以后就会向它自己提供最大带宽的服务
- 其他peer被Alice阻塞(将不会从Alice处获得服务)
- 每10秒重新评估一次:前4位
- 每个30秒:随机选择其他peer节点,向这个节点发送块
- ‘优化疏通”这个节点、
- 新选择的节点可以加入这个top4
- Alice向4个peer发送块,这些块以后就会向它自己提供最大带宽的服务
结构化:DHT

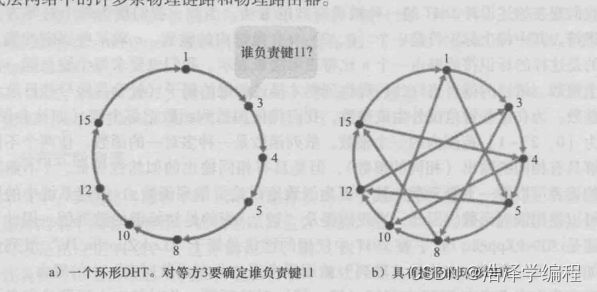
- 按照ID号大小围成一圈,当前对等方的IP地址,标识符等信息,其紧挨着后面的一个对等方知道(8知道5)
- 假设使用该环形覆盖网络,初始对等方(对等方3)生成一个报文,问“谁负责键11?”并绕环顺时针发送该报文。无论何时某对等方接收到该报文,因为它知道其后继和前任的标识符,它能够确定是否由它负责(即最邻近)查询中的键。如果某对等方不负责该键,它只需将该报文发送给它的后继。因此,例如当对等方4接收到询问键11的报文,它确定自己不负责该键(因为其后继更邻近该键),故它只需将该报文传递给对等方5。这个过程直到该报文到达对等方12才终止,对等方12确定自己是最邻近键11的对等方。此时,对等方12能够向查询的对等方即对等方3回送一个报文,指出自己负责键11。
- 为减少每个对等方必须管理的覆盖信息的数量,环形 DHT 提供了一种非常精确有效的解决方案。特别是,每个对等方只需要知道两个对等方,即它的直接后继和直接前任。但该解决方案也引入了一个新问题。尽管每个对等方仅知道两个邻居对等方,但为了找到负责的键(在最差的情况下),DHT中的所有N个结点将必须绕环转发该报文;平均发送N/2条报文。
- 细化方案:设置一个捷径的DHT(上图b)
- 以环形覆盖网络为基础,但增加“捷径”,使每个对等方不仅联系它的直接后继和直接前任,而且联系分布在环上的数量相对少的捷径对等方。使用捷径来加速查询报文的路由选择。具体来说,当某对等方接收到一条查询一个键的报文时,它向最接近该键的邻居(后继邻居或捷径邻居之一)转发该报文。所以,当对等方4接收到请求键11的报文,它确定(在它的邻居中)对该键最邻近的对等方是它的捷径邻居10,并且直接向对等方10转发该报文。显然,捷径能够大大减少用于处理查询的报文数量。
三、CDN(Content Distribution Network)
1.多媒体:视频
- 视频:固定速度显示的图像序列
- e.g. 24images/sec
- 网络视频特点:
- 高码率:>10x于音频,高的网络宽需求
- 可以被压缩
- 90%以上的网络流量是视频
- 数字化图像:像素的阵列。
- 每个像素被若干bits表示
- 编码:使用图像内和图像间的冗余来降低编码的比特数
- 空间冗余(图像内):发送视频的某一帧图片时(其背景是紫色)不发送N个相同的颜色(全部是紫色)值,仅发送2个值:颜色(紫色)和重复个数(N)
- 时间冗余(相邻的图像间):不发生第i+1帧的全部编码,而仅仅发送和帧i差别的地方。
- CBR:(constant bitrate):以固定速率编码
- VBR:(variable bitrate):视频编码速率随时间的变化而变化
例子:- MPEG 1 (CD-ROM)1.5
- Mbps
- MPEG2 (DVD)3-6 Mbps
- MPEG4 (often used inlnternet,< 1 Mbps)
2.多媒体流化服务
- DASH: Dynamic,Adaptive Streaming over HTTP
- 服务器:
- 将视频文件分割成多个块
- 每个块独立存储,编码于不同码率(8-10种)
- 告示文件(manifest file) :提供不同块的URL
- 客户端:
- 先获取告示文件
- 周期性地测量服务器到客户端的带宽
- 查询告示文件,在一个时刻请求一个块,HTTP头部指定字节范围
- 如果带宽足够,选择最大码率的视频块
- 会话中的不同时刻,可以切换请求不同的编码块(取决于当时的可用带宽)
- “智能”客户端:客户端自适应决定
- 什么时候去请求块(不至于缓存挨饿,或者溢出)
- 请求什么编码速率的视频块(当带宽够用时,请求高质量的视频块)
- 哪里去请求块(可以向离自己近的服务器发送URL,或者向高可用带宽的服务器请求)
3.CDN(内容分发网络)
- 挑战:服务器如何通过网络向上百万用户同时流化视频内容(上百万视频内容)?
- 选择1:单个的、大的超级服务中心“mega-server”
- 服务器到客户端路径上跳数较多,瓶颈链路的带宽小导致停顿
- “二八规律”决定了网络同时充斥着同一个视频的多个拷贝,效率低(付费高、带宽浪费、效果差)
- 单点故障点,性能瓶颈
- 周边网络的拥塞
评述:相当简单,但是这个方法不可扩展
- 选项2:通过CDN,全网部署缓存节点,存储服务内容,就近为用户提供服务,提高用户体验
- enter deep:将CDN服务器深入到许多接入网(部署到local ISP附近)
- 更接近用户,数量多,离用户近,管理困难
- 如Akamai,部署了1700个位置
- bring home:部署在少数(10个左右)关键位置,如将服务器簇安装于POP(高层ISP面向客户网络的接入点
)附近(离若干first ISP POP较近)- 采用租用线路将服务器簇连接起来
- Limelight
- enter deep:将CDN服务器深入到许多接入网(部署到local ISP附近)
- CDN:在CDN节点中存储内容的多个拷贝
- e.g. Netflix stores copies of MadMen
- 用户从CDN中请求内容
- 重定向到最近的拷贝,请求内容
- 如果网络路径拥塞,可能选择不同的拷贝
总结
以上就是应用层SMTP、DNS、CDN等讲解。