《UNISURF: Unifying Neural Implicit Surfaces and Radiance Fields for Multi-View Reconstruction》文章解读
参考文献:
@inproceedings{Oechsle2021ICCV, author = {Michael Oechsle and Songyou Peng and Andreas Geiger}, title = {UNISURF: Unifying Neural Implicit Surfaces and Radiance Fields for Multi-View Reconstruction}, booktitle = {International Conference on Computer Vision (ICCV)}, year = {2021} }
代码:GitHub - autonomousvision/unisurf: [ICCV'21] UNISURF: Unifying Neural Implicit Surfaces and Radiance Fields for Multi-View Reconstruction
摘要
神经隐式三维表示已经成为从多视点图像重建表面和综合新视点的强大范例。遗憾的是,DVR 或 IDR 等现有方法需要精确的逐像素对象掩码作为监督。与此同时,神经辐射场也为新视图合成带来了革命性的变化。然而,NeRF 估算的体积密度并不能实现精确的表面重建。我们的主要见解是,隐式曲面模型和辐射场可以用统一的方式进行表述,从而可以使用相同的模型进行曲面和体积渲染。这种统一的视角使新颖的、更有效的采样程序和能够在没有输入掩模的情况下重建准确的表面。我们在 DTU、BlendedMVS 和合成室内数据集上比较了我们的方法。实验表明在重建质量方面优于 NeRF,同时在不需要掩膜的情况下与 IDR 的性能相当。
1. 文献主要内容
1.1 研究背景及重要解决的问题
背景
从一组图像中捕捉3D场景的几何形状和外观是计算机视觉的基础问题之一。为了实现这一目标,基于坐标的神经模型在过去的几年中已经成为几何和外观三维重建的强大工具。许多最近的方法采用神经网络参数化的连续隐式函数作为几何或外观的三维表示。这些神经三维表示在几何重建和从多视图图像中进行的新视图合成方面显示出了令人印象深刻的性能。除了三维表示的选择(如占用场、无符号或有符号距离场)外,神经隐式多视图重建的一个关键因素是渲染技术。
问题1:
在现有的工作中,表面渲染技术在三维重建中表现出了令人印象深刻的性能。然而,它们需要逐像素的对象掩码作为输入和适当的网络初始化,因为表面渲染技术只提供曲面与射线相交的局部梯度信息。直观地说,优化局部梯度可以看作是对初始神经表面进行迭代变形的过程,而初始神经表面通常被初始化为一个球体。为了收敛到一个有效的表面,需要额外的约束条件,如掩模的监督,如图2所示。由于它们依赖于掩模,表面渲染方法仅限于对象级的重建,而不能扩展到更大的场景。

问题2:
像NeRF 这样的体积渲染方法在新视图合成和更大的场景中显示出了令人印象深刻的结果。然而,作为底层体积密度的水平集提取的表面通常是不平滑的,并且由于辐射场表示的灵活性而包含伪影,在存在模糊性的情况下不能充分约束 3D 几何形状,见图 3。

为解决上述两个问题,作者提出了 UNISURF(Unified Neural Implicit Surface and Radiance Fields),一个针对隐式曲面和辐射场统一框架,其目标是从一组RGB图像中重建固体(即不透明)对象。该框架结合了表面渲染和体积渲染的优点,使其能够在不需要掩模的情况下从多视图图像中重建精确的几何形状。通过恢复隐式曲面,我们可以在优化过程中逐步缩小体积渲染的采样区域。从大的采样区域开始,可以捕获粗几何图形并解决早期迭代中的歧义。在后期阶段,我们绘制更接近表面的样本,以提高重建精度。
1.2 原理(或者方法,或者模型)描述
1.2.1 原理
隐式表面模型。Occupancy Networks 将曲面表示为二值占用分类器的决策边界,由神经网络参数化
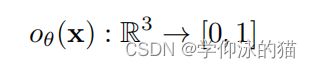
其中,![]() 是一个三维点,
是一个三维点, 是模型参数。该曲面被定义为所有三维点的集合,其中三维点的占用概率为一半:
是模型参数。该曲面被定义为所有三维点的集合,其中三维点的占用概率为一半:![]() 。为了将颜色与表面上的每个3D点xs关联起来,颜色场
。为了将颜色与表面上的每个3D点xs关联起来,颜色场 ![]() 可以与占用场共同学习。因此,一个特定的像素/射线
可以与占用场共同学习。因此,一个特定的像素/射线![]() 的颜色被预测如下:
的颜色被预测如下:
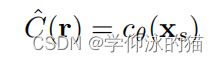
其中,![]() 是通过沿射线
是通过沿射线![]() 查找根检索的,详细信息请参见[38]。如[24,38,61]中所述,占用场和颜色场的参数是通过梯度下降优化重建损失来确定的。
查找根检索的,详细信息请参见[38]。如[24,38,61]中所述,占用场和颜色场的参数是通过梯度下降优化重建损失来确定的。
虽然表面渲染可以准确地估计几何图形和外观,但现有的方法强烈依赖于使用对象掩模的监督,因为表面渲染方法只能推理与表面相交的光线
体渲染模型。与隐式表面模型相比,NeRF [34]将场景表示为彩色体积密度,并通过alpha混合集成了沿光线的辐射。更具体地说,NeRF使用神经网络将3D位置 ![]() 和观测方向
和观测方向 ![]() 映射到体积密度
映射到体积密度 ![]() 和颜色
和颜色 ![]() 。以观察方向为条件,可以模拟镜面反射等视角相关效应 [34,40],并在违反朗伯假设的情况下提高重建质量。设
。以观察方向为条件,可以模拟镜面反射等视角相关效应 [34,40],并在违反朗伯假设的情况下提高重建质量。设![]() 表示相机中心的位置。给定沿射线
表示相机中心的位置。给定沿射线 ![]() 的N个样本,NeRF使用数值积分近似像素/射线
的N个样本,NeRF使用数值积分近似像素/射线 ![]() 的颜色。
的颜色。
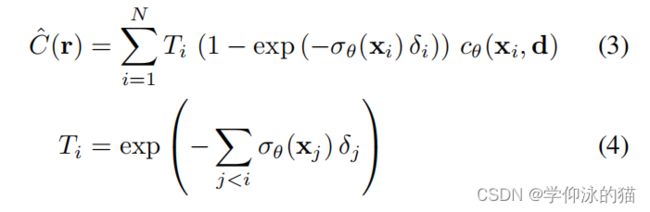
这里, 是沿射线的累积透射率,
是沿射线的累积透射率,![]() 是相邻样本之间的距离。“等式”(3)是可微的,密度场和色场的参数可以通过优化重建损失来估计。
是相邻样本之间的距离。“等式”(3)是可微的,密度场和色场的参数可以通过优化重建损失来估计。
虽然NeRF由于其体积辐射表示而不需要物体掩模进行训练,但从体积密度中提取场景几何形状需要仔细调整密度阈值,并由于密度场中存在的模糊性而导致伪影,见图3。
1.2.2 统一曲面和体积渲染
与NeRF 适用于非实体场景(如雾、烟)相比,作者只关注实体物体,这些物体可以用三维表面和视图相关的表面颜色来表示。作者的方法同时利用了体积辐射表示法和曲面渲染法,前者可以在没有掩膜监督的情况下学习粗略的场景结构,后者则是通过一组精确的三维曲面来表示物体,从而实现精确的重建。
作者将公式(3)重写为:

使用alpha值 ![]() 。假设固体对象,α成为一个离散的占用率指标变量
。假设固体对象,α成为一个离散的占用率指标变量 ![]() ,在自由空间为0,占用空间为1。
,在自由空间为0,占用空间为1。
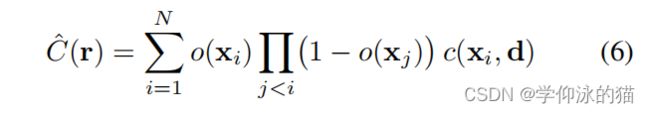
我们将这个表达式视为为固体物体[55]的图像形成模型,其中对沿射线 ![]() 的第一个占用样本
的第一个占用样本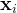
![]() 的值为1,对所有其他样本值为0。
的值为1,对所有其他样本值为0。![]() 是可见性指标,如果在样本之前不存在被占用的样本
是可见性指标,如果在样本之前不存在被占用的样本![]() 。因此,
。因此,![]() 沿着光线
沿着光线 ![]() 取第一个被占用的样品的颜色
取第一个被占用的样品的颜色 ![]() 。
。
为了统一隐式表面辐射模型和体积辐射模型,直接通过连续占用场 ![]() 来参数化
来参数化 ![]() ,而不是预测体积密度σ。根据文献[61],我们将表面法线和几何网络的特征向量作为颜色场的条件,根据经验,这种方法会产生有用的偏差,正如文献[61]中针对隐式表面所观察到的那样。重要的是,我们的统一公式允许体积和表面渲染。
,而不是预测体积密度σ。根据文献[61],我们将表面法线和几何网络的特征向量作为颜色场的条件,根据经验,这种方法会产生有用的偏差,正如文献[61]中针对隐式表面所观察到的那样。重要的是,我们的统一公式允许体积和表面渲染。
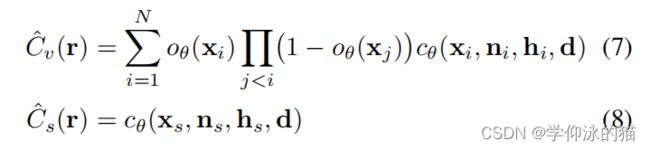
其中 ![]() 通过沿射线
通过沿射线  寻根检索,
寻根检索,![]() ,
,![]() 分别表示
分别表示 ![]() 处的法线和几何特征。注意,
处的法线和几何特征。注意,![]() 依赖于占用场
依赖于占用场 ![]() ,但是为了清晰起见,我们在这里放弃了这个依赖关系。
,但是为了清晰起见,我们在这里放弃了这个依赖关系。
这种统一表述的优势在于,它既可以直接渲染表面,也可以渲染整个体积,从而在优化过程中逐步消除模糊之处。我们的实验证明,要想在没有掩膜监督的情况下获得准确的重建,将两者结合起来确实至关重要。通过寻根快速恢复表面,可以更有效地进行体积渲染,如我们将在第 4.3 节中介绍的那样,连续聚焦和细化物体表面。此外,表面渲染可以实现更快的新视图合成,如图5所示。

1.2.3 损失函数
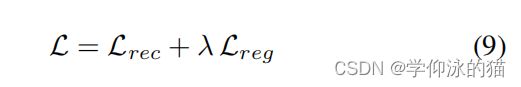
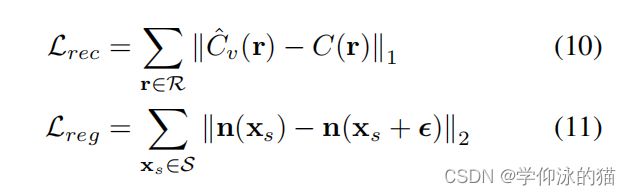
这里,![]() 表示小批中所有像素/光线的集合,S是对应的表面点的集合,C (r)是像素/射线r所观察到的颜色,ϵ是一个小的随机均匀的三维扰动。在
表示小批中所有像素/光线的集合,S是对应的表面点的集合,C (r)是像素/射线r所观察到的颜色,ϵ是一个小的随机均匀的三维扰动。在![]() 处的法线是由
处的法线是由
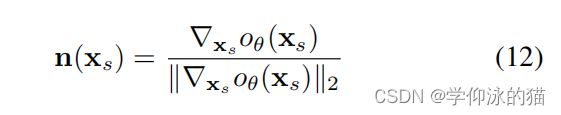
1.3 文献实验结果分析
1.3.1 数据集
DTU MVS Dataset. DTU MVS数据集包含49到64张分辨率为1200×1600的图像,以及所有视图的外部和内部相机参数。该数据集由具有不同形状和外观的对象组成。非朗伯的外观效果使一些物体特别具有挑战性。对于每一次扫描,都可提供地面真实 3D 图形以及官方评估程序。与之前的工作[38, 61]一样,我们使用了评估脚本中的 "表面 "方法,并在使用相应掩膜清理过的网格上对所有方法进行评估。官方评估程序会计算预测形状的采样点与数据集中提供的真实形状之间的倒角距离。
为了评估 IDR [61],我们使用了 IDR 作者提供的所有图像的像素精确掩膜。
BlendedMVS Dataset. BlendedMVS 数据集是一个大型数据集,包含多视图图像以及各自的相机外参和内参。我们使用的示例来自 BlendedMVS 低分辨率集,图像分辨率为 768 × 576。这些示例包含 24 到 64 个未遮挡图像的不同视图。我们将场景定义为物体位于中心,最近的摄像机位于单位球附近。
SceneNet Dataset. 为了在复杂的室内场景中测试我们的模型,我们从文献[29]中选取了两个场景进行评估。使用 BlenderProc [10] 渲染包含多个物体的部分场景图像。第一个场景是卧室场景,包括一张床、一盏灯和一个床头柜。另一个场景是客厅场景,包括沙发、窗帘和圆桌。我们分别使用了 83 幅和 40 幅图像。
1.3.2 在DTU数据集上的比较
在表1中,作者的方法与DTU MVS数据集上的基线进行了定量比较。虽然带有修剪参数ζ = 7的COLMAP基线在倒角距离上显示出了最佳的性能,但它产生了具有不完整表面的漏水网格。该方法的性能几乎与最先进的神经隐式模型IDR相当,而不依赖于强大的掩膜监督。NeRF和COLMAP(ζ = 0)也不使用输入掩膜,但在倒角距离方面表现出较差的性能。

在图6中,我们显示了我们的方法和基线的定性结果。虽然COLMAP提供了详细的重建,但由于修剪导致不完整的几何。对于NeRF,在重建过程中可以观察到孔洞和噪声伪影。相比之下,我们的方法和 IDR(带输入掩膜)能生成具有高质量细节的精确表面。我们注意到,我们的模型在准确捕捉场景整体空间布局的同时,还能捕捉几何细节,如头骨的牙齿和其他表面细节。
1.3.3 在BlendedMVS和SceneNet数据集上的比较
为了展示我们的模型在更多样化的场景上的能力,我们使用了BlendedMVS数据集的样本和来自SceneNet的室内场景。由于这些场景不存在对象掩模,我们只考虑COLMAP和NeRF作为基线方法。当我们尝试运行IDR时,没有一个场景收敛,从而导致退化输出。对于具有复杂背景的场景,我们使用一个背景模型,学习捕获我们的区域兴趣之外的外观信息,我们建议读者参考补充材料以获得更多细节。
我们在图8中的定性结果表明,与现有的隐式表面模型不同,我们的方法能够重建具有多个对象和背景的复杂场景的合理几何形状。虽然COLMAP在室内场景中工作得很好,但它在均匀颜色的区域上显示伪影(例如,第二行的圆桌)。在BlendedMVS实验中,NeRF可以解释整体空间结构,但与UNISURF相比,表面精度较低,噪声水平明显更高。更多的结果可以在补充材料中找到。
1.3.4 消融实验
渲染过程。我们通过比较图7中的不同变化来论证我们对渲染过程的选择:首先,我们考虑一个在优化过程中只使用表面渲染的基线。我们在表面颜色上使用ℓ1重建损失,并根据[38]通过隐式微分进行反向传播。第二个基线使用具有96个查询点的统一体积渲染。第三,我们使用NeRF的分层体积采样和64+64个样本点来查询占用场。虽然曲面渲染不会趋同,但 Uniform VR 和 HVR 会导致形状过于平滑和臃肿,细节缺失。这证明,与基线相比,所提出的统一模型能带来更精确的重建。

损失函数。在图 7 中,我们还展示了 (9) 中表面正则化项的消融研究。如果没有这个正则化项,平坦和模糊区域的表面就会变得不那么光滑,例如在桌子上。这个正则化项对于观察频率较低的区域特别有用,因为它包含了对光滑表面的归纳偏差。
2. 实验结果及代码

这里不能同时编译c++的扩展模块,会出现错误。需要进入不同的目录下分别编译扩展模块。
cd utils/libmise
python setup.py build_ext --inplace
setup.py文件要改为:
from distutils.core import setup
from distutils.extension import Extension
from Cython.Build import cythonize
import numpy as np
ext_modules = [Extension("mise",sources=["mise.pyx"],)]
setup(ext_modules=cythonize(ext_modules),include_dirs=[np.get_include()])同理:
cd utils/libmcubes
python setup.py build_ext --inplace从预训练的模型中提取网格:
python extract.py configs/DTU_pre/scan_0$id.yaml 可视化网格:
