实战JVM高CPU、内存问题分析定位
背景:
业务中台组件MOSC开展压测工作,并发场景下发现CPU使用率达到100%,虽然程序没有报错,但是这种情况显然已经达到性能瓶颈,对服务带来了验证的效能影响,所以针对该CPU问题必须进行详细的根因分析处理。
这次针对分析过程做了详细的记录,希望给大家在日常工作中,遇到CPU和内存问题能高效准确的进行分析定位。
一、通过监控确定问题
应用研发这边可以通过Grafana监控观察相关资源使用情况:
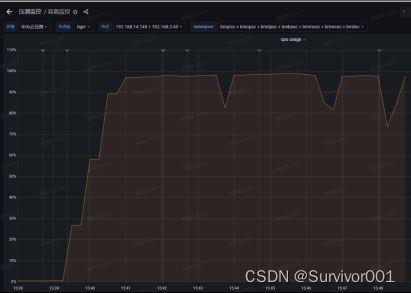
这里可以看到CPU已经达到99%以上,已经达到了瓶颈。
二、CPU问题分析
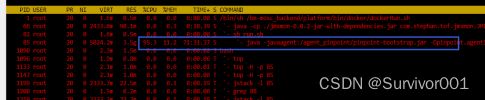
1、进入容器查看当前CPU占比最高的进程信息
使用TOP命令查看,可以发现确实是因为mosc服务导致
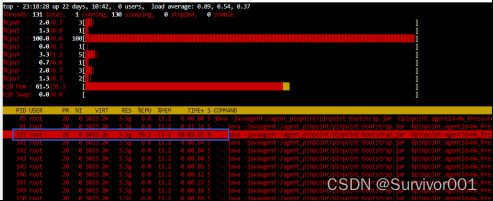
2、定位占用CPU最高的具体线程,可以使用TOP -H -p pid指令查看
3、通过jvm指令查看当前线程栈信息,jstack -l pid | grep nid -A 50
注:
jstack信息中记录nid是16进制,需要将当前线程ID转成16进制
jstack是在容器中打印栈信息,正常情况下建议通过jmap导出dump文件然后进行搜索定位,避免jstack指令给当前执行服务造成影响。
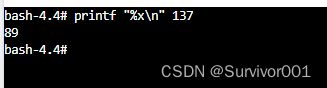
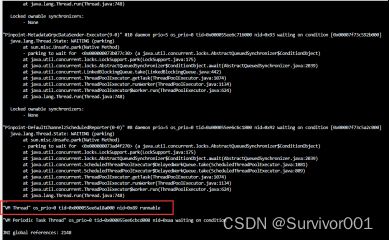
这里发现已经搜索定位到了nid为89的线程栈信息,注意当前线程是VM Thread,大概率推测当前线程是GC线程。
注:如果是正常的请求线程,这里就可以通过栈信息定位到具体的程序,例如上图的nid=0x92。
4、检查GC情况
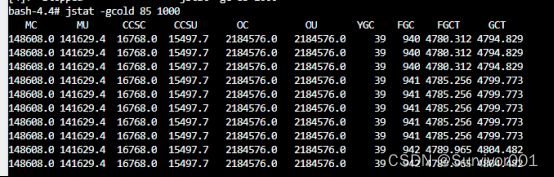
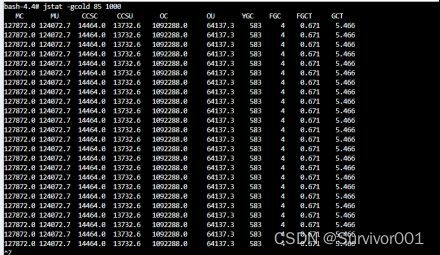
使用jstat -gcold 85 1000 ,查看Old区GC和内存实时状态。大致的可以看出来,Old区使用率已经100%了,FULLGC非常的频繁,差不多5秒一次。
- 查看GC原因
使用jsta -gccause 85 1000指令,查看当前GC实时情况包括原因。

这里可以看出来频繁的FULLGC原因都是相同的Allocation Failure,无法分配资源。
其实到此,基本上已经可以测出来一些结论了:
压测过程中虚拟机内存吃满无法分配资源,导致频繁的FULLGC而占用过多的CPU资源。所以程序执行过程中可能产生了大数据量,导致了大对象的诞生,根据Jvm内存分配原理,大对象会直接放入到Old区,并发场景下Old区很快就会被大对象吃满,从而引发FGC。
三、内存占用分析
1、导出dump日志信息
针对内存分析,最好的方式的就是导出dump快照文件,借助工具来分析,比如MAT、Jvisualvm、Jprofile等,我这里使用的就是Jprofile。
使用jmap -dump:live,format=b,file=/路径/dump.hprof 85 指令导出dump文件。
2、分析内存情况
使用Jprofile打开dump文件

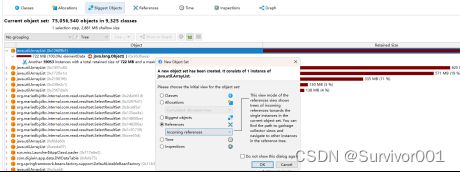
可以看出来这里存在这比较大的实例,选择String实例看下引用情况,
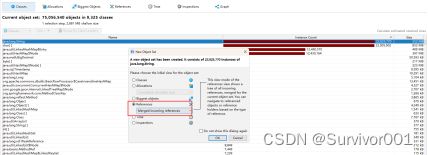
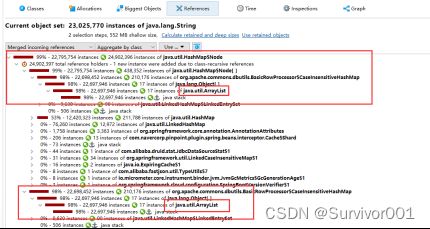
这个可以知道当前实例最终的引用来自于ArrayList对象。
3、查看大对象试图
Jprofile提供了BiggestObjects视图,可以观察当前内存中的大对象
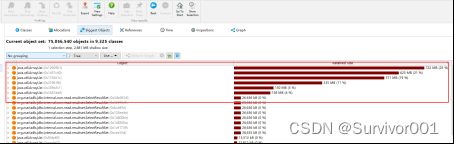
这里可以看到和上面分析的一样,确实存在这ArrayList大对象,继续查看当前对象的引用信息
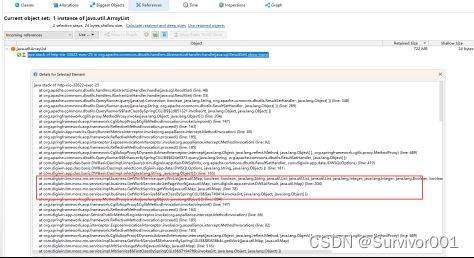
到此就已经可以定位到了大致的程序了:GetWorkService.getWork#doGetPageWork#WoList().select()
当前select方法是数据库调用方法,所以结合前面分析的内容,可以推测当前程序可能获取到了大数据量信息,并使用了ArrayList对象接收。
四、结合请求日志定位具体程序问题和优化
既然已经清楚了大致的程序和原因,那就可以按照这个思路具体的验证和程序分析了
1、内存占用验证
关闭其他的API脚本,只启动当前API观察内存使用情况。

这里可以看到执行了一次API后,Old区上升了约350m,正如上面我们推测的,当前API产生了大对象,直接放入到Old区,并发后导致内存吃满。
2、结合pinpoint链路分析具体SQL
因为清楚了问题API和大致的程序,我们跟容易就可以通过pinpoint分析到具体的执行SQL。
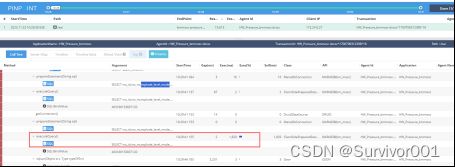
通过测试执行该SQL,发现当前SQL会读取出来约7w数据量,以及约120个栏位信息。
3、结合程序分析优化
结合当前程序分析后发现,当前API虽然支持分页查询,但是在获取total时,使用原SQL查询所有数据,然后获取size,导致了获取到了7w多笔数据,导致了效能问题。
到此全部的问题都已经分析完了,接下来就是联系PR做优化调整了,获取total直接通过select count获取总数total。
4、结果验证
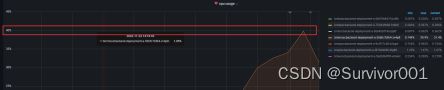
再PR程序调整后,验证结果。现在继续压测当前API使用10U并发(之前是跑一次,消耗300mb内存占用)
耗时结果对比:从之前100s降到了1秒多
![]()
内存对比:现在10U下,内存几乎没有浮动
CPU对比:现在max CPU是40%左右
搞定!
PS:
大数据问题往往是导致CPU、内存问题最主要原因之一,造成的影响可能是服务级别,所以日常开发过程中,在非业务需求场景下,尽量减少内存数据量,避免导致资源问题和效能风险。
对于上述分页场景中需要获取总数total,后续也会纳入应用开发规范要求:分页场景下获取数据总数,使用统计函数获取,例如select count,禁止获取全部数据,在内存获取size。