【机器学习】K近邻算法

一、原理
参数k的确定

带权重的k近邻算法 与 模糊k近邻算法

KNN算法用于回归问题

在使用欧氏距离时应将特征向量归一化

mahalanobis距离

如何确定数据的协方差矩阵

Bhattacharyya距离

距离度量学习

距离度量学习大边界最近邻分类

二、示例代码1
import numpy as np # 导入numpy库,用于进行数值计算
import matplotlib.pyplot as plt # 导入matplotlib库的pyplot模块,用于绘制图形
from sklearn import datasets # 导入sklearn库的datasets模块,用于加载数据集
from sklearn.neighbors import KNeighborsClassifier # 导入sklearn库的neighbors模块中的KNeighborsClassifier类,用于创建k近邻分类器
import matplotlib # 导入matplotlib库,用于图形绘制
#%matplotlib inline # 这是一个Jupyter Notebook的魔法命令,用于在Notebook中直接显示图形
# 定义一个函数,用于生成所有测试样本点
def make_meshgrid(x, y, h=.02):
x_min, x_max = x.min() - 1, x.max() + 1 # 计算x的最小值和最大值
y_min, y_max = y.min() - 1, y.max() + 1 # 计算y的最小值和最大值
xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h)) # 生成网格点
return xx, yy # 返回网格点
# 定义一个函数,对测试样本进行预测,并显示
def plot_test_results(ax, clf, xx, yy, **params):
Z = clf.predict(np.c_[xx.ravel(), yy.ravel()]) # 对测试样本进行预测
Z = Z.reshape(xx.shape) # 调整预测结果的形状
ax.contourf(xx, yy, Z, **params) # 绘制等高线图
# 载入iris数据集
iris = datasets.load_iris()
# 只使用前面两个特征
X = iris.data[:, :2]
# 样本标签值
y = iris.target
# 创建kNN分类器
knn = KNeighborsClassifier()
knn.fit(X,y) # 对分类器进行训练
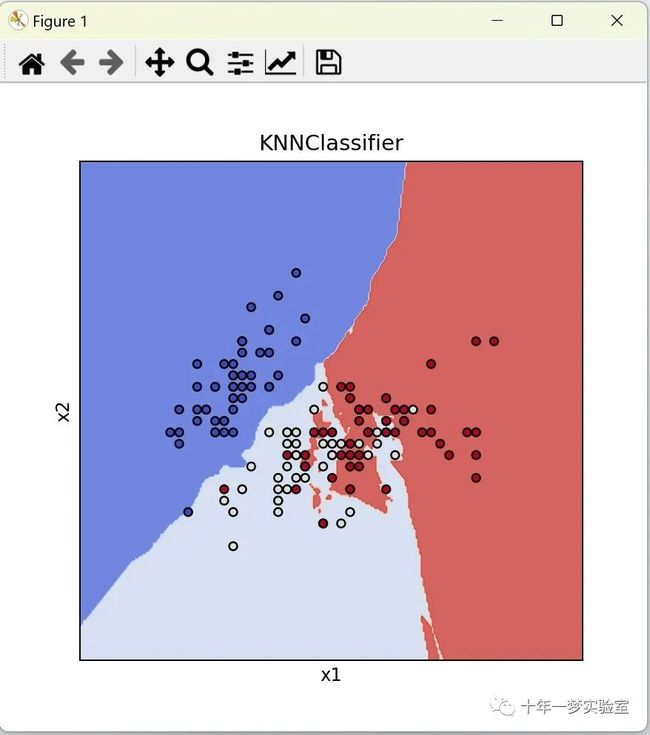
title = ('KNNClassifier')
fig, ax = plt.subplots(figsize = (5, 5)) # 创建一个新的图形窗口
plt.subplots_adjust(wspace=0.4, hspace=0.4) # 调整子图之间的间距
X0, X1 = X[:, 0], X[:, 1] # 提取特征值
# 生成所有测试样本点
xx, yy = make_meshgrid(X0, X1)
# 显示测试样本的分类结果
plot_test_results(ax, knn, xx, yy, cmap=plt.cm.coolwarm, alpha=0.8)
# 显示训练样本
ax.scatter(X0, X1, c=y, cmap=plt.cm.coolwarm, s=20, edgecolors='k')
ax.set_xlim(xx.min(), xx.max()) # 设置x轴的范围
ax.set_ylim(yy.min(), yy.max()) # 设置y轴的范围
ax.set_xlabel('x1') # 设置x轴的标签
ax.set_ylabel('x2') # 设置y轴的标签
ax.set_xticks(()) # 清空x轴的刻度
ax.set_yticks(()) # 清空y轴的刻度
ax.set_title(title) # 设置标题
plt.show() # 显示图形三、示例代码2
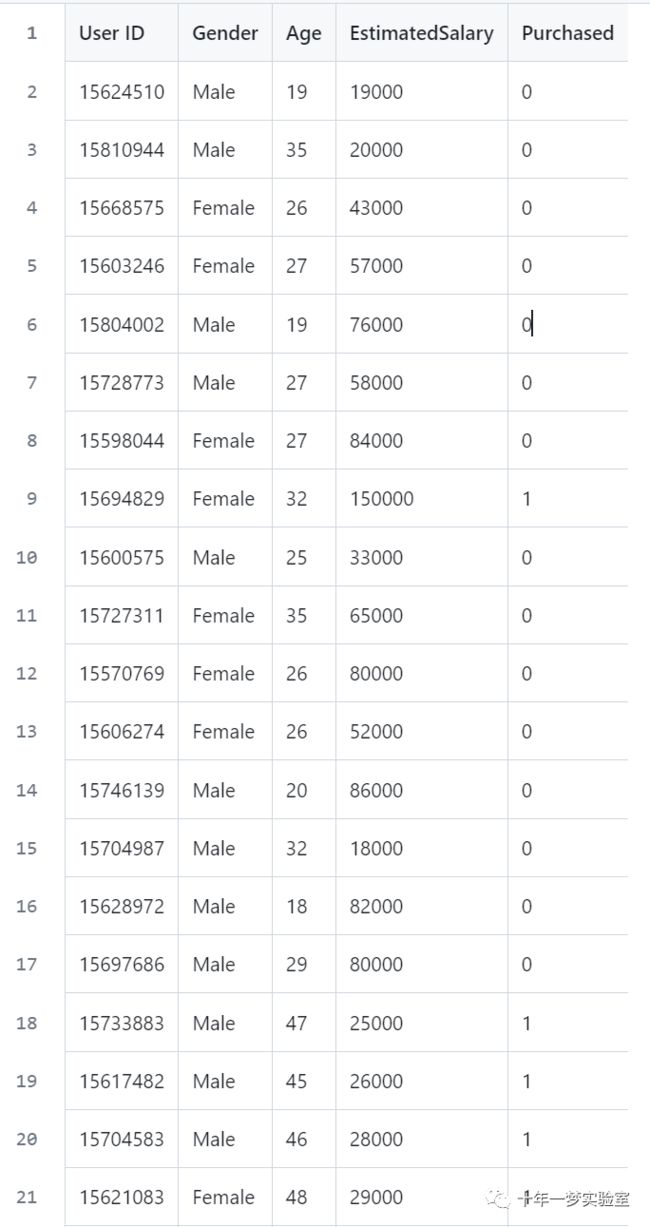
数据集

输出的混淆矩阵和分类报告
# 导入必要的库
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
# 导入数据集 注意,Python 中索引是从 0 开始的。
dataset = pd.read_csv('../datasets/Social_Network_Ads.csv')
X = dataset.iloc[:, [2, 3]].values # 获取数据集中的第3列和第4列数据 年龄 薪水,并将其转换为NumPy数组
y = dataset.iloc[:, 4].values # 获取数据集中的第4列数据 是否购买,并将其转换为NumPy数组
# 将数据集划分为训练集和测试集
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.25, random_state = 0) # 将数据集划分为75%的训练集和25%的测试集
# 特征缩放
from sklearn.preprocessing import StandardScaler
sc = StandardScaler() # 创建标准化对象
X_train = sc.fit_transform(X_train) # 对训练集进行标准化
X_test = sc.transform(X_test) # 对测试集进行标准化
# 使用K-NN算法训练模型
from sklearn.neighbors import KNeighborsClassifier
classifier = KNeighborsClassifier(n_neighbors = 5, metric = 'minkowski', p = 2) # 创建K-NN分类器,设置参数n_neighbors为5,metric为闵可夫斯基距离,p为2
classifier.fit(X_train, y_train) # 使用训练集训练模型
# 使用训练好的模型预测测试集结果
y_pred = classifier.predict(X_test) # 使用训练好的模型预测测试集的结果
# 生成混淆矩阵
from sklearn.metrics import confusion_matrix
from sklearn.metrics import classification_report
cm = confusion_matrix(y_test, y_pred) # 生成混淆矩阵
print(cm) # 打印混淆矩阵
print(classification_report(y_test, y_pred)) # 打印分类报告

参考
https://github.com/noobgod/100-Days-Of-ML-Code
《机器学习-原理、算法与应用》,清华大学出版社,雷明著
The End