详细解析GNMT(Google’s Neural Machine Translation System)
总结:1. GNMT 模型的成功,背后依靠的是 attention 机制和 seq-seq 的结合。
2. 为了解决 OOV(out-of-vocabulary)问题,使用 sub-word units(wordpieces)
3. Encoder 和 decoder 均使用 LSTM 和残差网络搭建,其中 encoder 第一层使用双向 LSTM,decoder 过程中,在 beam search 基础上,增加了 coverage penalty 和 length normalization,以提升翻译质量。
4. 为了加快训练速度和翻译速度,使用模型并行和数据并行,对于没卡的个人玩家, 数据并行更有帮助。
5. 提出了 GLEU,将 reward 融入 seq-seq 模型中,先使用公式 7 来训练模型到收敛, 然后使用公式 9 来重建模型,直到 BLEU 值不再提高。
6. 为了量化模型,提高效率,谷歌限制了 Cti , Xti 的范围,并且在翻译过程中将所有 的浮点运算改成 8-bit 或 16-bit。
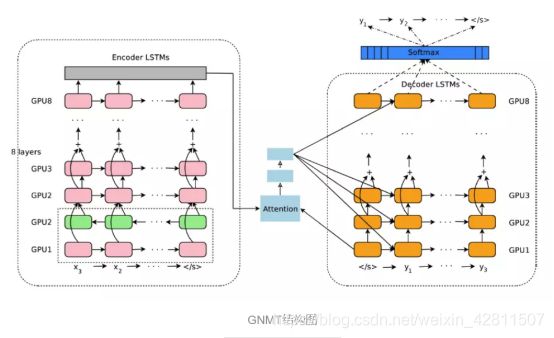
最后,附上系统的网络结构图,全文阅读难度不大,但阅读前需要先了解残差网络,LSTM,attention,seq-seq等模型。
1.摘要和简介
目前NMT的主要缺陷有:1.训练速度慢,2.很难处理生词,3.处理长句无法完全覆盖source sentence,出现漏翻。
因此,谷歌提出了GNMT来解决上述的问题。GNMT包含采用encoder-decoder结构,encoder和decoder中都包含8层LSTM网络,encoder和decoder内部均使用残差连接,encoder和decoder之间使用attention。
为了提高翻译的效率,谷歌在翻译过程中使用低精度的算法。
为了解决输入的生词,谷歌在输入和输出中使用了sub-word units(wordpieces),(比如把’higher’拆分成’high’和’er’)。
在beam search中加入关于长度的正则化项(length normalization),和一个用于鼓励生成的句子尽可能覆盖所有source sentence的惩罚项(a coverage penalty)。
在以上的改进之后,谷歌宣称在英-法,英-德中取得很好的效果,错误率相比于谷歌的PBMT系统减少60%。
2.模型介绍
模型是典型的seq-seq形式,由三部分组成:encoder,decoder和attention。整体流程:输入一个句子,encoder将输入的句子转换为一系列的vector,decoder每次产生一个字,直到出现eos结束翻译,解码过程中,依靠attention来获取上下文信息,并分配不同的权重来关注source sentence中的不同部分。
Encoder和decoder都是使用多层LSTM堆叠而成。
Attention模型公式如下:
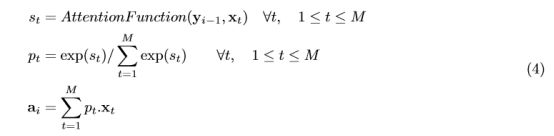
AttentionFunction就是一个只有一层隐藏层的前向传播网络,公式4通过计算与source sentence中的所有字得到,…,,然后计算(也就是权重),最后将source sentence 乘以后求和。
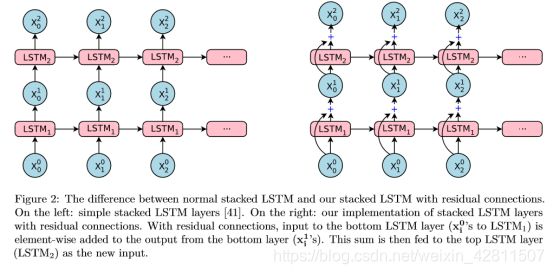
2.1 残差连接
多层堆叠的LSTM固然能带来更好的准确率,但过深的网络容易造成训练困难,梯度消失或爆炸等问题,因此,谷歌使用了残差连接来缓解以上问题,具体结果看下图就行,对残差网络不了解的可以看看ResNet。
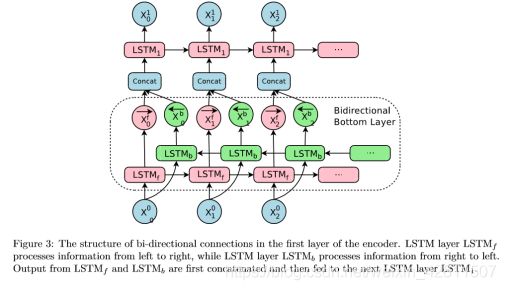
2.2 Encoder的第一层使用双向LSTM
2.3 模型并行
为了加速训练,谷歌使用了数据并行和模型并行两种方法。
数据并行:复制n份模型,模型参数共享,同时训练大小为batch_size的句子,将梯度汇集到统一的优化器Adam和SGD上更新参数,和A3C的异步更新一样,谷歌使用的n为10,batch_size为128。
模型并行:加速每一份模型的梯度计算,将每一层网络部署在一个GPU上。
3 分割方法
NMT系统通常使用一个固定字数和大小的字典,但可能会遇到很多超出字典的词,比如:名字,数字,日期等。会造成OOV(out-of-vocabulary)问题,一般有两种方法来解决OOV问题。第一种:直接将生词从source复制到targe,第二种:使用sub-word units
谷歌采用两种方法,第一种是创建了wordpiece model,例子如下图:

上图中,’_’用于标记字的开始位置。
谷歌指出,使用8k-32k大小的字典能带来较好的BLEU成绩和编码效率。
第二种则是Mixed Word/Character Model,将生词分割成字,并使用特殊字符指定位置。例如,,分别表示词的开始,中间,末尾三中不同的位置,以MIKI为例,如果MIKI是生词,则分割成:M I K I。
4 训练标准
假定有N的并行的模型,我们给定N个输入-输出序列对的文本数据,一般是要最大化下图中的公式7:
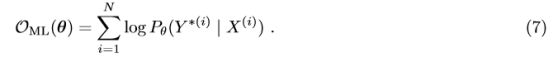
这个公式问题在于BLEU值无法反应对单句翻译质量好坏的奖惩,此外,该目标没有明确鼓励在不正确的输出序列中进行排序,其中具有较高BLEU分数的输出仍应在模型下获得更高的概率 - 因为在训练期间从未观察到不正确的输出。换句话说,仅使用最大似然训练,模型将不会学习对解码期间发生的错误的鲁棒性,因为它们从未被观察到,这在训练和测试过程之间是完全不匹配的。
因此,谷歌将任务奖励和seq-seq模型结合,提出了下面的公式8:
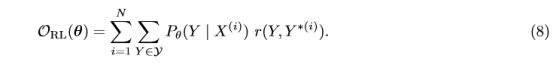
这里,r(Y,Y *(i))表示每句话得分,我们计算对所有输出句子Y的期望。
谷歌提出了GLEU值,GLEU和BLEU具有很好的相关性,又能解决reward表示的问题,对于一个句子,先分割成1,2,3,4元组的形式,然后计算召回率和精确率,取二者最小值为GLEU值,GLEU值大小为0-1之间。
最终,为了进一步稳定训练,谷歌将公式7和8线性组合成了下面的公式9,其中α为0.017。
![]()
谷歌的首先使用公式7来训练模型到收敛,然后使用公式9来重建模型,直到BLEU值不再提高。
5 Quantizable Model and Quantized Inference
这一部分主要讲优化方法,来减少计算量,提高模型的翻译效率,减少翻译时间。
带有残差连接的LSTM网络,有两个值是会不断传递计算的,在时间方向上传递的Cti和在深度方向上传递的Xti,在实验中过程我们发现这些值都是非常小的,为了减少错误的累积,所以在翻译的过程中,明确的这些值限制在[-δ,δ]之间,因此原LSTM的公式调整如下:
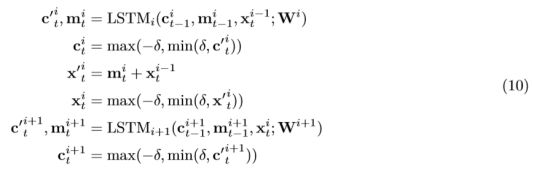
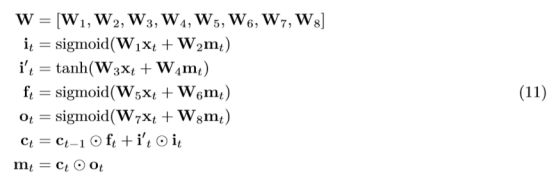
在翻译的过程中,谷歌将所有浮点数运算替代为8位或16位定点整数运算,其中的权重W像下式一样改用8位整数表示:

所有的cit和xit限制在[-δ,δ]之间且改用16位整数表示。
在矩阵乘法(比如W1xt)改用8位定点整数乘法,而其他的所有运算,比如sigmoid,tanh,点乘,加法等,改用16位整数运算。
假设decoder RNN的输出是yt,那在softmax层,概率向量pt改为这样计算:

6.decoder
Decoder过程中采用beam search。上文中提到过两个重要的改进,coverage penalty and length normalization。以往的beam search会有利于偏短的结果,谷歌认为这是不合理的,并对长度进行了标准化处理:
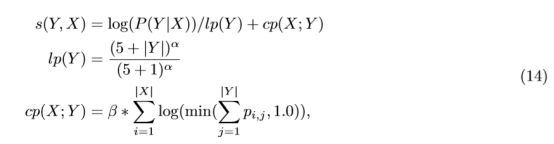
其中α∈[0,1],谷歌建议取值为[0.6,0.7]之间,α用于length normalization,β用于控制coverage penalty。S(Y,X)代表target最终的得分,表示翻译到target j时对应source i的attention。
7 结论
1.wordpiece能有效处理OOV问题,应对生词对翻译质量和推理速度的挑战。
2.模型并行和数据并行能有效的提升模型训练效率,一周内能训练出最先进的NMT模型。
3.模型量化加速了翻译推理,允许在生产环境中部署和使用这些大型模型。
4.length normalization,coverage penalty等措施提升了NMT系统的翻译质量,使其在实际数据上运行良好。
有关实验部分,这里就不再贴图分析了,有需要的朋友自己看原文的实验部分结果就行,个人认为知道摘要中提到的结果就行了。
再阅读论文时遇到的问题:
公式8中的r没有说清楚,计算公式没有??
解决:根据GLUE求出所有句子的得分,然后求出期望(平均值),公式8的r就是target的句子得分减去期望。
参考文献:
1.https://www.jianshu.com/p/f2bd4e4a391b
2.https://arxiv.org/abs/1609.08144