支持向量机原理(Support Vector Machine)学习笔记
支持向量机原理(Support Vector Machine)学习笔记
-
- 前言
- 1. SVM算法原理
- 2. 硬间隔(Hard margin)SVM
-
- 2.1 拉格朗日乘子法
- 2.2 KKT条件
- 2.3 对偶问题
- 3. 软间隔(Soft margin)SVM
- 4. 核函数
- 5. SMO算法
-
- α \alpha α的更新
- b b b的更新
- 优化变量的选择
- 参考资料
前言
支持向量机(SVM)是以监督学习训练出来的二元分类模型,目的是将带有未知标签的数据进行合理分类。
1. SVM算法原理
假设当前数据的类别为两类,并且是线性可分的,此时我们可以找到一个超平面,使两类数据分隔开。(下面以二维数据举例)
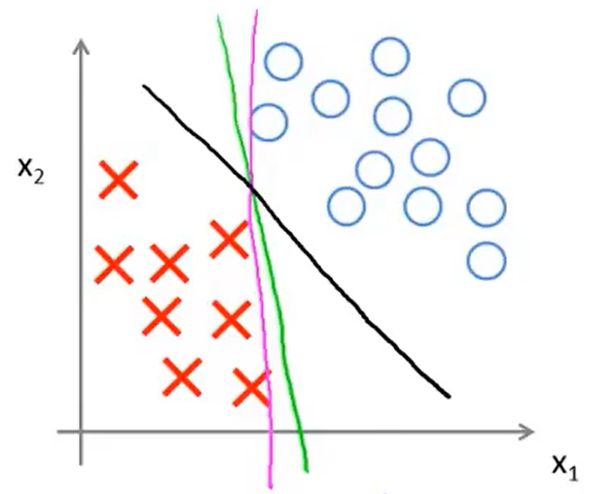
从图中可以看到,使两类数据分隔开的超平面可以有无数条,但显然粉色和绿色超平面不是那么合适,而黑色超平面则要好很多。那么如何找到像黑色超平面那样的决策边界呢?
在SVM中,我们需要找到一个超平面,使得在所有数据中离此超平面最近的数据到此超平面的间隔(margin)最大,如下图所示:
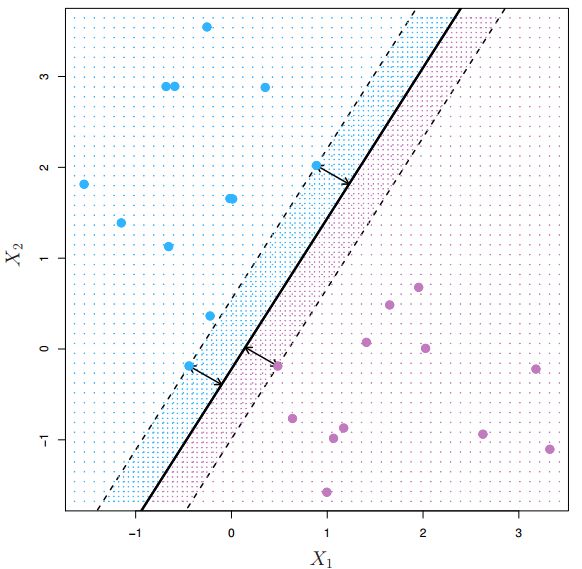
超平面只被这三个点所决定,故这些数据被称为支持向量(support vectors),虚线为间隔边界。这样决定的超平面比较健壮耐用,具有更高的容错性,因为每一边的支持向量到超平面还留有足够的距离,即使新数据出现在超平面周围(两条间隔边界内),模型对其分类的结果也有很大的可信度。
2. 硬间隔(Hard margin)SVM
硬间隔SVM模型的特点是使所有训练样本都能够被正确分类。我们假设所提供的数据都为线性可分的,也就是存在超平面使得两类的数据能够被完美地分隔开。适用硬间隔SVM模型的数据点分布如下图所示:
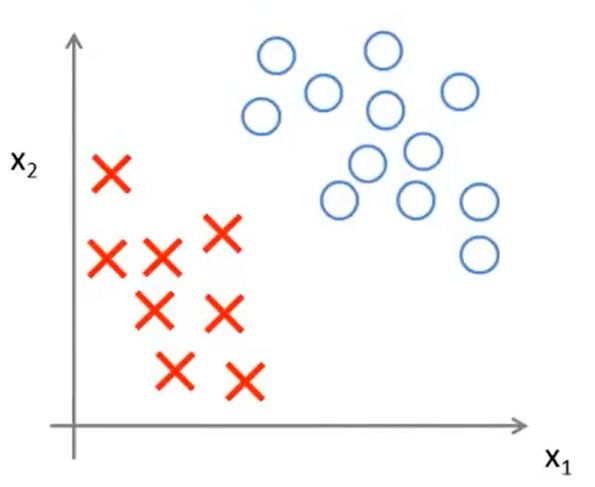
设决策边界的超平面方程为 w T x + b = 0 w^Tx + b = 0 wTx+b=0, m m m个样本 { ( x 1 , y 1 ) , ( x 2 , y 2 ) , ⋯ , ( x m , y m ) } \{(x_1,y_1),(x_2,y_2),\cdots,(x_m,y_m)\} { (x1,y1),(x2,y2),⋯,(xm,ym)}, ( x i , y i ) (x_i,y_i) (xi,yi)为第 i i i个样本, i ∈ 1 , 2 , ⋯ , m i \in 1,2,\cdots,m i∈1,2,⋯,m, x i x_i xi为第 i i i个样本的特征值,以向量形式表示, x i ∈ R d x_i \in \mathbb R^d xi∈Rd, y i y_i yi为样本的类别, y i ∈ { − 1 , + 1 } y_i \in \{-1,+1\} yi∈{ −1,+1}。 f ( x ) = s i g n ( w T x + b ) f(x) = sign(w^Tx + b ) f(x)=sign(wTx+b)为分类模型,其中 s i g n ( x ) sign(x) sign(x)为指示函数:
s i g n ( x ) = { + 1 , if x ≥ 0 − 1 , if x < 0 sign(x) = \begin{cases} +1, & \text{if $x \ge 0$} \\ -1, & \text{if $x < 0$} \end{cases} sign(x)={ +1,−1,if x≥0if x<0
即把输入样本的特征 x i x_i xi代入到决策边界方程,若 w T x i + b ≥ 0 w^Tx_i + b \ge 0 wTxi+b≥0,则把样本归为“+1”类,反之则归为“-1”类。
在硬间隔SVM模型中,所有训练样本需要被正确分类,因此模型需满足约束:
{ w T x i + b ≥ 0 , if y i = + 1 ( 1 ) w T x i + b < 0 , if y i = − 1 ( 2 ) \begin{cases} w^Tx_i + b \ge 0, & \text{if $y_i = +1$} \qquad (1)\\ w^Tx_i + b < 0, & \text{if $y_i = -1$} \qquad (2) \end{cases} { wTxi+b≥0,wTxi+b<0,if yi=+1(1)if yi=−1(2)
结合式 (1),(2) 得
y i ( w T x i + b ) ≥ 0 (3) y_i(w^Tx_i + b) \ge 0 \tag{3} yi(wTxi+b)≥0(3)
根据SVM的原理,接下来我们需要计算出离超平面最近的训练样本到超平面的距离。根据点到超平面的距离公式,我们可以得到每个样本点到超平面的距离 d i d_i di:
d i = 1 ∥ w ∥ ∣ w T x i + b ∣ i = 1 , 2 , ⋯ , m d_i = \frac{1}{\lVert w\rVert} \lvert w^Tx_i + b\rvert \qquad i = 1,2,\cdots,m di=∥w∥1∣wTxi+b∣i=1,2,⋯,m
最小距离 d i s t dist dist只与 x i x_i xi相关,即
d i s t = min x i 1 ∥ w ∥ ∣ w T x i + b ∣ i = 1 , 2 , ⋯ , m (4) dist = \min_{x_i}\frac{1}{\lVert w\rVert} \lvert w^Tx_i + b\rvert \qquad i = 1,2,\cdots,m \tag{4} dist=ximin∥w∥1∣wTxi+b∣i=1,2,⋯,m(4)
有人可能会问,为什么最小距离不与 w , b w,b w,b相关呢?这是因为想要在样本当中找到离超平面最近的点,必须得是在同一平面的前提下才行,不然就无法比较样本到超平面的远近了。在超平面固定的情况下,无论 w , b w,b w,b为何值,最小距离的表示方法都为式(4)。
(P.S 而 min w , b , x i 1 ∥ w ∥ ∣ w T x i + b ∣ \min_{w,b,x_i}\dfrac{1}{\lVert w\rVert} \lvert w^Tx_i + b\rvert minw,b,xi∥w∥1∣wTxi+b∣的目的就不是寻找离超平面最近的点了,而是寻找一组 w , b , x i w,b,x_i w,b,xi,即寻找一个超平面,使得 x i x_i xi这个点到超平面的距离最小。这样的话 min w , b , x i 1 ∥ w ∥ ∣ w T x i + b ∣ \min_{w,b,x_i}\dfrac{1}{\lVert w\rVert} \lvert w^Tx_i + b\rvert minw,b,xi∥w∥1∣wTxi+b∣就会等于0,因为一定会存在无数个超平面,使得这个点到超平面的距离为0。因此 min w , b , x i 1 ∥ w ∥ ∣ w T x i + b ∣ \min_{w,b,x_i}\dfrac{1}{\lVert w\rVert} \lvert w^Tx_i + b\rvert minw,b,xi∥w∥1∣wTxi+b∣不是我们目标的数学表达形式。)
根据式(3),可以将上式改写为
min x i 1 ∥ w ∥ y i ( w T x i + b ) i = 1 , 2 , ⋯ , m (5) \min_{x_i}\frac{1}{\lVert w\rVert} y_i(w^Tx_i + b) \qquad i = 1,2,\cdots,m \tag{5} ximin∥w∥1yi(wTxi+b)i=1,2,⋯,m(5)
而对于同一个超平面,它的参数 w , b w,b w,b是不确定的。假设有一平面 x 1 + 3 x 2 + 2 x 3 − 4 = 0 x_1+3x_2+2x_3-4 = 0 x1+3x2+2x3−4=0,接下来将两边同时乘2,,得平面 2 x 1 + 6 x 2 + 4 x 3 − 8 = 0 2x_1+6x_2+4x_3-8 = 0 2x1+6x2+4x3−8=0。虽然它们的参数不同,但却是同一个平面。所以对于之后得出的最优超平面方程来说,有无数组成比例的参数 w , b w,b w,b符合条件,而我们只需要确定一个即可。
为了方便计算,我们令 min y i ( w T x i + b ) = 1 \min y_i(w^Tx_i + b)= 1 minyi(wTxi+b)=1。这个约束的言外之意就是在计算最近的样本到超平面距离时,存在唯一的 w , b w,b w,b,使得所使用的距离公式的分子部分等于1。
(1)为什么这个约束能使 w , b w,b w,b唯一呢?
因为超平面已经固定,所以无数组 w , b w,b w,b是线性成比例的,要想继续保证超平面固定, w , b w,b w,b只能成比例改变,也就是说只允许 w , b w,b w,b乘上一个相同的数,即 ξ w T x + ξ b \xi w^Tx + \xi b ξwTx+ξb。假设现在有一组 w , b w,b w,b满足上述约束,即把最近的样本 ( x i , y i ) (x_i,y_i) (xi,yi)代入超平面方程后,得 y i ( w T x i + b ) = 1 y_i(w^Tx_i + b)= 1 yi(wTxi+b)=1,若想寻找其他满足约束的 w , b w,b w,b,我们首先需将 w , b w,b w,b成比例变换,即 y i ( ξ w T x i + ξ b ) = 1 y_i(\xi w^Tx_i + \xi b)= 1 yi(ξwTxi+ξb)=1,将 ξ \xi ξ提到外面,得 ξ y i ( w T x i + b ) = 1 \xi y_i(w^Tx_i + b)= 1 ξyi(wTxi+b)=1,由于 y i ( w T x i + b ) = 1 y_i(w^Tx_i + b)= 1 yi(wTxi+b)=1,所以 ξ = 1 \xi = 1 ξ=1。因此其他满足约束的 ξ w , ξ b \xi w,\xi b ξw,ξb其实就是原来的 w , b w,b w,b,即这个约束能使 w , b w,b w,b唯一。
(2)为什么 min y i ( w T x i + b ) \min y_i(w^Tx_i + b) minyi(wTxi+b)对应的是最近样本到超平面距离公式的分子呢?
距离公式的分子的大小也能反映出样本到超平面的远近,分子越小,样本点离超平面越近。所以能得到最小的分子就意味着它是离超平面最近的点。
(上面说的有点啰嗦,以便未来失忆的自己能够回忆起这些苦思冥想出来的细节,哈哈哈)
由于最小距离与 w , b w,b w,b无关,式(5)可改写为
1 ∥ w ∥ min x i y i ( w T x i + b ) i = 1 , 2 , ⋯ , m (6) \frac{1}{\lVert w\rVert} \min_{x_i} y_i(w^Tx_i + b) \qquad i = 1,2,\cdots,m \tag{6} ∥w∥1ximinyi(wTxi+b)i=1,2,⋯,m(6)
又因为 min y i ( w T x i + b ) = 1 \min y_i(w^Tx_i + b)= 1 minyi(wTxi+b)=1,所以最小距离 d i s t dist dist可表示为
d i s t = 1 ∥ w ∥ dist = \frac{1}{\lVert w\rVert} dist=∥w∥1
我们需要找到一个超平面,使得 d i s t dist dist最大,即
max w , b 1 ∥ w ∥ s.t. y i ( w T x i + b ) ≥ 0 i = 1 , 2 , ⋯ , m min y i ( w T x i + b ) = 1 i = 1 , 2 , ⋯ , m \begin{aligned} \max_{w,b} & \;\;\frac{1}{\lVert w \rVert} \\[1ex] \text {s.t. }& \;\;y_i(w^Tx_i + b) \ge 0 \qquad i = 1,2,\cdots,m\\[1ex] & \;\; \min y_i(w^Tx_i + b)= 1 \qquad i = 1,2,\cdots,m \end{aligned} w,bmaxs.t. ∥w∥1yi(wTxi+b)≥0i=1,2,⋯,mminyi(wTxi+b)=1i=1,2,⋯,m
上式等价于
min w , b 1 2 w T w s.t. 1 − y i ( w T x i + b ) ≤ 0 i = 1 , 2 , ⋯ , m (7) \begin{aligned} \min_{w,b} & \;\;\frac{1}{2} w^Tw\\[1ex] \text {s.t. }& \;\;1-y_i(w^Tx_i + b) \le 0 \qquad i = 1,2,\cdots,m \end{aligned}\tag{7} w,bmins.t. 21wTw1−yi(wTxi+b)≤0i=1,2,⋯,m(7)
这是一个带约束的二次凸优化问题,我们一般用拉格朗日乘子法解决此类问题。
2.1 拉格朗日乘子法
下面用一个二维的例子来说明:

黑色虚线代表待优化函数 f ( x ) f(x) f(x)的等高线,中心为函数的最小值,红色实线为约束条件 h ( x ) h(x) h(x)。我们需要在这条红线上找到一个点来满足 f ( x ) f(x) f(x)最小。在左图中,使得 f ( x ) f(x) f(x)最小的点是 x 1 x_1 x1,在点 x 1 x_1 x1处 f ( x ) f(x) f(x)一定与 h ( x ) h(x) h(x)相切。如果在 x 1 x_1 x1处 f ( x ) f(x) f(x)与 h ( x ) h(x) h(x)相交,如右图所示,则 x 1 x_1 x1一定不是最小值处,因为 h ( x ) h(x) h(x)是连续的,所以一定可以找到其他的点,如点 x 2 x_2 x2,使得 f ( x 2 ) < f ( x 1 ) f(x_2) < f(x_1) f(x2)<f(x1)。
设极小值点为 x ∗ x^* x∗,在 x ∗ x^* x∗处, f ( x ) f(x) f(x)与 h ( x ) h(x) h(x)相切,这就意味着 ∇ f ( x ∗ ) \nabla f(x^*) ∇f(x∗)与 ∇ h ( x ∗ ) \nabla h(x^*) ∇h(x∗)平行,即存在 λ ≠ 0 \lambda \neq 0 λ=0,使得
∇ f ( x ∗ ) + λ ∇ h ( x ∗ ) = 0 (8) \nabla f(x^*) + \lambda \nabla h(x^*) = 0 \tag{8} ∇f(x∗)+λ∇h(x∗)=0(8)
定义拉格朗日函数 L ( x , λ ) \mathcal L(x,\lambda) L(x,λ)为
L ( x , λ ) = f ( x ) + λ h ( x ) \mathcal L(x,\lambda) = f(x) + \lambda h(x) L(x,λ)=f(x)+λh(x)
对 L ( x , λ ) \mathcal L(x,\lambda) L(x,λ)中的 x , λ x, \lambda x,λ求偏导后分别等于0,就得到了式(8)与约束条件 h ( x ) = 0 h(x) = 0 h(x)=0。
2.2 KKT条件
上述解决的是带等式约束的优化问题,而对于不等式约束的优化,则需要满足额外的条件。
假设我们的优化问题为
min x f ( x ) s.t. g i ( x ) ≤ 0 , i = 1 , 2 , ⋯ , m h j ( x ) = 0 , j = 1 , 2 , ⋯ , n \begin{aligned} \min_{x} & \;\;f(x) \\[1ex] \text {s.t. }& \;\;g_i(x) \le 0, \qquad i = 1,2,\cdots,m\\[1ex] & \;\; h_j(x) = 0, \qquad j = 1,2,\cdots,n \end{aligned} xmins.t. f(x)gi(x)≤0,i=1,2,⋯,mhj(x)=0,j=1,2,⋯,n
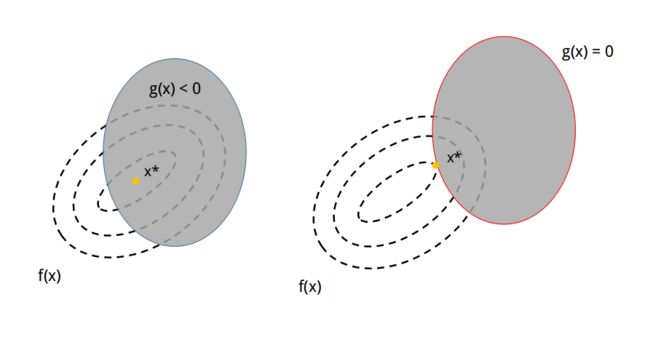
上图中灰色区域表示约束条件 g i ( x ) ≤ 0 g_i(x) \le 0 gi(x)≤0的范围,也就是说最后找到的最小值必须落在灰色区域中。设 x ∗ x^* x∗为最小值处,我们分两种情况讨论:
(1) 最小值落在了 g ( x ) < 0 g(x) < 0 g(x)<0 区域中(左图)。这种情况意味着约束条件根本没有起作用,不管有没有这个约束条件,最后 x ∗ x^* x∗的位置都是相同的。所以这种情况等同于最小化 f ( x ) f(x) f(x)时没有 g ( x ) ≤ 0 g(x) \le 0 g(x)≤0这个约束,此时在式(8)上等同于 λ = 0 \lambda = 0 λ=0。
(2) 最小值落在了 g ( x ) = 0 g(x) = 0 g(x)=0上(右图)。这种情况与等式约束类似,不同的是 f ( x ) f(x) f(x)与 g ( x ) g(x) g(x)在最小值处的梯度一定是相反的。这是因为 f ( x ) f(x) f(x)等高线的值越往中心越小,所以在 x ∗ x^* x∗处, ∇ f ( x ∗ ) \nabla f(x^*) ∇f(x∗)是朝向灰色区域的;而对于 g ( x ) g(x) g(x),灰色区域小于0,灰色区域外大于0,所以 ∇ g ( x ∗ ) \nabla g(x^*) ∇g(x∗)方向是朝向灰色区域外的。因此, ∇ f ( x ∗ ) \nabla f(x^*) ∇f(x∗)与 ∇ g ( x ∗ ) \nabla g(x^*) ∇g(x∗)是相反的,此时在式(8)上等同于 λ > 0 \lambda > 0 λ>0。
综合上述两种情况,得
{ λ > 0 , if g ( x ∗ ) = 0 λ = 0 , if g ( x ∗ ) < 0 \begin{cases} \lambda > 0, & \text{if $g(x^*) = 0$} \\ \lambda = 0, & \text{if $g(x^*) < 0$} \end{cases} { λ>0,λ=0,if g(x∗)=0if g(x∗)<0
则
{ λ ≥ 0 λ g ( x ∗ ) = 0 ( 9 ) \begin{cases} \lambda \ge 0 \\ \lambda g(x^*) = 0 \qquad (9) \end{cases} { λ≥0λg(x∗)=0(9)
式(9)被称作互补松弛条件(complementary slackness)。
构造拉格朗日函数
L ( x , α , β ) = f ( x ) + ∑ i = 1 m α i g i ( x ) + ∑ j = 1 n β j h j ( x ) \mathcal L(x,\alpha,\beta) = f(x) + \sum_{i=1}^m \alpha_i g_i(x) + \sum_{j=1}^n \beta_j h_j(x) L(x,α,β)=f(x)+i=1∑mαigi(x)+j=1∑nβjhj(x)
其中最优解 x ∗ x^* x∗满足KKT条件:
{ g i ( x ∗ ) ≤ 0 h j ( x ∗ ) = 0 α i ≥ 0 α i g i ( x ∗ ) = 0 \begin{cases} g_i(x^*) \le 0 \\ h_j(x^*) = 0 \\ \alpha_i \ge 0 \\ \alpha_i g_i(x^*) = 0 \end{cases} ⎩⎪⎪⎪⎨⎪⎪⎪⎧gi(x∗)≤0hj(x∗)=0αi≥0αigi(x∗)=0
回到硬间隔SVM的优化问题,构造拉格朗日函数 L ( w , b , α ) \mathcal L(w,b,\alpha) L(w,b,α)为
L ( w , b , α ) = 1 2 w T w + ∑ i = 1 m α i ( 1 − y i ( w T x i + b ) ) i = 1 , 2 , ⋯ , m (10) \mathcal L(w,b,\alpha) = \frac{1}{2}w^Tw + \sum_{i=1}^m \alpha_i (1-y_i(w^Tx_i + b)) \qquad i = 1,2,\cdots,m \tag{10} L(w,b,α)=21wTw+i=1∑mαi(1−yi(wTxi+b))i=1,2,⋯,m(10)
其最优解满足KKT条件:
{ 1 − y i ( w T x i + b ) ≤ 0 i = 1 , 2 , ⋯ , m α i ≥ 0 i = 1 , 2 , ⋯ , m α i ( 1 − y i ( w T x i + b ) ) = 0 i = 1 , 2 , ⋯ , m (11) \begin{cases} 1-y_i(w^Tx_i + b) \le 0 &i = 1,2,\cdots,m\\ \alpha_i \ge 0 & i = 1,2,\cdots,m\\ \alpha_i (1-y_i(w^Tx_i + b)) = 0 & i = 1,2,\cdots,m \end{cases} \tag{11} ⎩⎪⎨⎪⎧1−yi(wTxi+b)≤0αi≥0αi(1−yi(wTxi+b))=0i=1,2,⋯,mi=1,2,⋯,mi=1,2,⋯,m(11)
接下来可以对拉格朗日函数 L ( w , b , α ) \mathcal L(w,b,\alpha) L(w,b,α)求导并解方程组,求出超平面的参数。然而,在现实中,我们很有可能会遇到数量很多、维度很高的样本,此时求导的方法会变得很慢。为了解决这个问题,我们可以把原始问题转化为对偶问题。通过求解对偶问题,得到超平面的参数。
2.3 对偶问题
首先将带约束优化问题的式(7)转化为无约束问题,那么式(7)等价于下面式子:
min w , b max α L ( w , b , α ) s.t. α i ≥ 0 i = 1 , 2 , ⋯ , m (12) \begin{aligned} \min_{w,b}\max_{\alpha} & \;\;\mathcal L(w,b,\alpha)\\[1ex] \text {s.t. }& \;\;\alpha_i \ge 0 \qquad i = 1,2,\cdots,m \end{aligned}\tag{12} w,bminαmaxs.t. L(w,b,α)αi≥0i=1,2,⋯,m(12)
且式(12)满足式(7)的约束。
为了解释它们为什么等价,下面分两种情况讨论:
(1) 当式(12)中参数不满足式(7)约束。
此时,存在 i ∈ 1 , 2 , ⋯ , m i \in 1,2,\cdots,m i∈1,2,⋯,m,使得 1 − y i ( w T x i + b ) > 0 1-y_i(w^Tx_i + b) > 0 1−yi(wTxi+b)>0,而 α i ≥ 0 \alpha_i \ge 0 αi≥0,所以 max α L ( w , b , α ) = + ∞ \max_{\alpha} \mathcal L(w,b,\alpha) = + \infty maxαL(w,b,α)=+∞。
(2) 当式(12)中参数满足式(7)约束。
此时, 1 − y i ( w T x i + b ) ≤ 0 , i = 1 , 2 , ⋯ , m 1-y_i(w^Tx_i + b) \le 0,i = 1,2,\cdots,m 1−yi(wTxi+b)≤0,i=1,2,⋯,m,而 α i ≥ 0 \alpha_i \ge 0 αi≥0,所以 max α L ( w , b , α ) = 1 2 w T w \max_{\alpha} \mathcal L(w,b,\alpha) = \dfrac{1}{2}w^Tw maxαL(w,b,α)=21wTw。
综合上述两种情况
{ max α L ( w , b , α ) = + ∞ if 1 − y i ( w T x i + b ) > 0 max α L ( w , b , α ) = 1 2 w T w if 1 − y i ( w T x i + b ) ≤ 0 \begin{cases} \max_{\alpha} \mathcal L(w,b,\alpha) = + \infty & \text{if $1-y_i(w^Tx_i + b) > 0$}\\ \max_{\alpha} \mathcal L(w,b,\alpha) = \dfrac{1}{2}w^Tw & \text{if $1-y_i(w^Tx_i + b) \le 0$} \end{cases} ⎩⎨⎧maxα