UCAS - AI学院 - 自然语言处理专项课 - 第12讲 - 课程笔记
文本分类与聚类
文本分类
- 文本——领域信息分类
传统机器学习方法
-
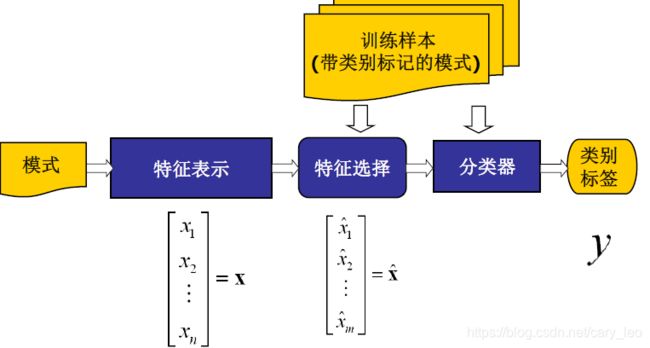
文本表示
- 向量空间模型——BoW模型
- 词的权重
- 词频TF
- 布尔变量
- 逆文档频率IDF
- TF-IDF
-
特征选择
-
文档频率:根据训练语料中的文档频率,对所有特征进行排序
-
词频:根据训练语料中特征的频率,对所有特征进行排序
-
基于无监督思想,特征选择缺乏类别信息的指导
-
相关概率估计(文档数)

- P ( c j ) ≈ ( A i j + C i j ) / N a l l P(c_j) \approx (A_{ij} + C_{ij}) / N_{all} P(cj)≈(Aij+Cij)/Nall
- P ( t i ) ≈ ( A i j + b i j ) / N a l l P(t_i) \approx (A_{ij} + b_{ij}) / N_{all} P(ti)≈(Aij+bij)/Nall
- P ( t ˉ i ) ≈ ( C i j + D i j ) / N a l l P(\bar t_i) \approx (C_{ij} + D_{ij}) / N_{all} P(tˉi)≈(Cij+Dij)/Nall
- P ( c j ∣ t i ) ≈ ( A i j + 1 ) / ( A i j + B i j + N C ) P(c_j | t_i) \approx (A_{ij} + 1) / (A_{ij} + B_{ij} + N_C) P(cj∣ti)≈(Aij+1)/(Aij+Bij+NC)
- P ( c j ∣ t ˉ i ) ≈ ( C i j + 1 ) / ( C i j + D i j + N C ) P(c_j | \bar t_i) \approx (C_{ij} + 1) / (C_{ij} + D_{ij} + N_C) P(cj∣tˉi)≈(Cij+1)/(Cij+Dij+NC)
-
互信息
- 关于两个随机变量互相依赖程度的一种度量
- I ( X , Y ) = H ( X ) − H ( X ∣ Y ) = ∑ x ∑ y p ( x , y ) log p ( x , y ) p ( x ) p ( y ) I(X, Y) = H(X) - H(X|Y) = \sum_x \sum_y p(x, y) \log \frac{p(x, y)}{p(x)p(y)} I(X,Y)=H(X)−H(X∣Y)=∑x∑yp(x,y)logp(x)p(y)p(x,y)
- MI ( t i , c j ) = log P ( t i , c j ) P ( t i ) P ( c j ) ≈ log A i j N a l l ( A i j + C i j ) ( A i j + B i j ) \operatorname{MI}(t_i, c_j) = \log \frac{P(t_i, c_j)}{P(t_i) P(c_j)} \approx \log \frac{A_{ij}N_{all}}{(A_{ij} + C_{ij}) (A_{ij} + B_{ij})} MI(ti,cj)=logP(ti)P(cj)P(ti,cj)≈log(Aij+Cij)(Aij+Bij)AijNall
- MI a v g ( t i ) = ∑ j = 1 C P ( c j ) MI ( t i , c j ) \operatorname{MI}_{avg}(t_i) = \sum_{j = 1}^C P(c_j) \operatorname{MI}(t_i, c_j) MIavg(ti)=∑j=1CP(cj)MI(ti,cj)
-
信息增益
- 衡量特征为分类系统带来多少信息
- IG ( t i ) = { − ∑ j C P ( c j ) log p ( c j ) } + { P ( t i ) [ ∑ j c P ( c j ∣ t i ) log P ( c j ∣ t i ) ] + P ( t ˉ i ) [ ∑ j c P ( c j ∣ t ˉ i ) log P ( c j ∣ t ˉ i ) ] } \operatorname{IG}(t_i) = \left\{-\sum_j^C P(c_j) \log p(c_j) \right\} + \left\{ P(t_i) \left[ \sum_j^c P(c_j | t_i) \log P(c_j|t_i) \right] + P(\bar t_i) \left[ \sum_j^c P(c_j | \bar t_i) \log P(c_j| \bar t_i) \right]\right\} IG(ti)={−∑jCP(cj)logp(cj)}+{P(ti)[∑jcP(cj∣ti)logP(cj∣ti)]+P(tˉi)[∑jcP(cj∣tˉi)logP(cj∣tˉi)]}
- 信息增益可以通过互信息计算
- IG ( t i ) = ∑ j C P ( t i , c j ) MI ( t i , c j ) + ∑ j C P ( t ˉ i , c j ) MI ( t ˉ i , c j ) \operatorname{IG}(t_i) = \sum_j^C P(t_i, c_j) \operatorname{MI}(t_i, c_j) + \sum_j^C P(\bar t_i, c_j) \operatorname{MI}(\bar t_i, c_j) IG(ti)=∑jCP(ti,cj)MI(ti,cj)+∑jCP(tˉi,cj)MI(tˉi,cj)
-
X 2 \Chi^2 X2统计量
- 检验两个事件的独立性,度量了期望计数 E E E与观察计数 N N N之间的关系,越大越相关
- X 2 ( t , c ) = ∑ I t ∑ I c ( N I t , I c − E I t , I c ) 2 E I t , I c \Chi^2(t, c) = \sum_{It} \sum_{Ic} \frac {(N_{It,Ic} - E_{It, Ic})^2}{E_{It, Ic}} X2(t,c)=∑It∑IcEIt,Ic(NIt,Ic−EIt,Ic)2
- X 2 ( t , c ) = N a l l ( A i j D i j − C i j B i j ) 2 ( A i j + C i j ) ( B i j + D i j ) ( A i j + B i j ) ( C i j + D i j ) \Chi^2(t, c) = \frac {N_{all} (A_{ij} D_{ij} - C_{ij} B_{ij})^2}{(A_{ij} + C_{ij}) (B_{ij} + D_{ij}) (A_{ij} + B_{ij}) (C_{ij} + D_{ij})} X2(t,c)=(Aij+Cij)(Bij+Dij)(Aij+Bij)(Cij+Dij)Nall(AijDij−CijBij)2
- CHI a v g ( t i ) = ∑ j P ( c j ) X 2 ( t i , c j ) \operatorname{CHI}_{avg}(t_i) = \sum_j P(c_j) \Chi^2(t_i, c_j) CHIavg(ti)=∑jP(cj)X2(ti,cj)
-
-
分类算法
- 监督学习
- 朴素贝叶斯
- 假设: P ( X ∣ c j ) ≈ ∏ k N P ( w k ∣ c j ) ≈ ∏ i M P ( w i ∣ c j ) N ( w i ) P(X | c_j) \approx \prod_k^N P(w_k | c_j) \approx \prod_i^M P(w_i | c_j)^{N(w_i)} P(X∣cj)≈∏kNP(wk∣cj)≈∏iMP(wi∣cj)N(wi)
- 决策规则: P ( c j ∣ x ) ∝ p ( x , c j ) = P ( c j ) ∏ i M P ( w i ∣ c j ) N ( w i ) P(c_j | x) \propto p(x, c_j) = P(c_j) \prod_i^M P(w_i | c_j)^{N(w_i)} P(cj∣x)∝p(x,cj)=P(cj)∏iMP(wi∣cj)N(wi)
- 最大似然估计: P ( c j ) ≈ 1 + N ( c j ) C + N a l l P(c_j) \approx \frac {1 + N(c_j)}{C + N_{all}} P(cj)≈C+Nall1+N(cj), P ( w i ∣ c j ) ≈ 1 + N ( w i , c j ) M + ∑ i ′ N ( w i ′ , c j ) P(w_i | c_j) \approx \frac {1 + N(w_i, c_j)}{M+ \sum_{i^\prime} N(w_{i^\prime}, c_j)} P(wi∣cj)≈M+∑i′N(wi′,cj)1+N(wi,cj)
- 线性判别函数
- g ( x ) = w ⊤ x + w 0 = ∑ l = 1 M w l x l + w 0 g(\bold x) = \bold w^\top \bold x + w_0 = \sum_{l = 1}^M w_l x_l + w_0 g(x)=w⊤x+w0=∑l=1Mwlxl+w0
- 不同的优化准则决定的不同的线性判别面
- 优化——随机梯度下降
- 支持向量机
- 最大间隔优化 y = w ⊤ x + b y = \bold w^\top \bold x + b y=w⊤x+b
- 优化准则 min 1 2 ∥ w ∥ 2 , s.t. y i ( w ⊤ x i + b ) ≥ 1 , i = 1 , … , n \min \frac 12 \|\bold w\|^2,\ \text{s.t.} \ y_i(\bold w^\top \bold x_i + b) \ge 1, i = 1, \dots, n min21∥w∥2, s.t. yi(w⊤xi+b)≥1,i=1,…,n
- 最大熵模型
- 朴素贝叶斯
- 无监督、半监督学习
- 监督学习
深度学习方法
-
基于CNN的方法
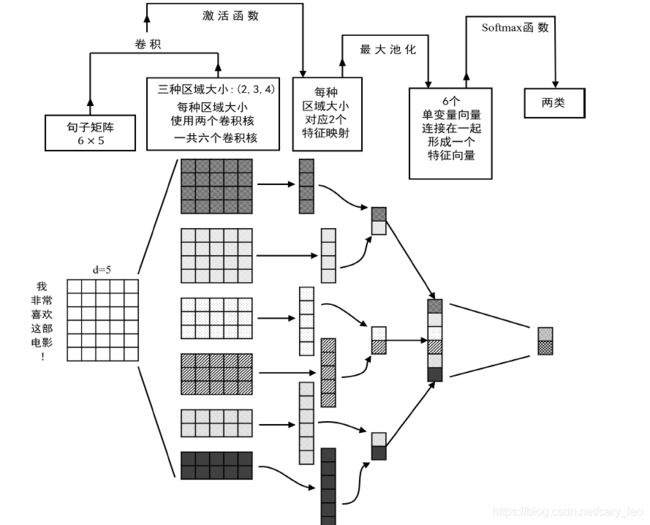
- 文本视为词序列,每个词用词向量表示
- 文本按词窗口卷积(一维向量特定个词卷积) y i t = F t ( W x i : i + h − 1 + b ) y_i^t = F_t(W x_{i:i + h - 1} + b) yit=Ft(Wxi:i+h−1+b)
- 多个卷积结果最大池化 y ^ t = max ( y i t ) \hat y^t = \max (y^t_i) y^t=max(yit)
- 不同词窗口卷积结果构造最终分类向量
-
基于循环神经网络的方法
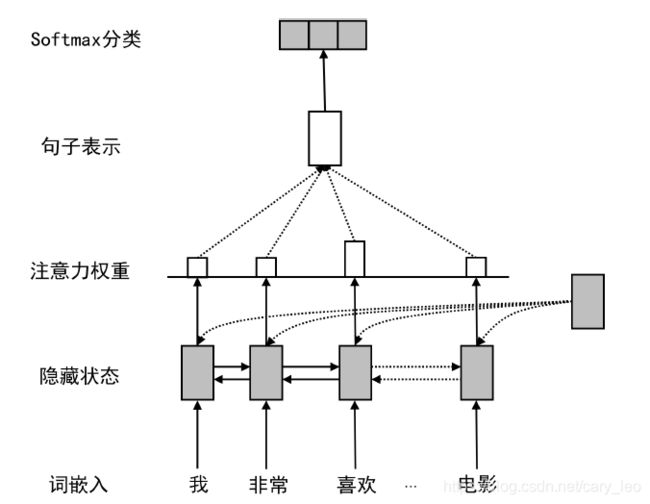
- RNN+注意力机制
-
基于层次化网络的方法
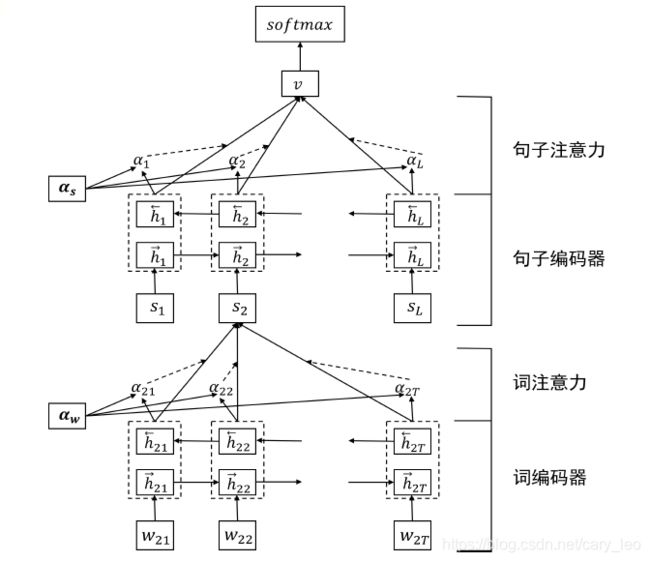
- 文本看作句子的序列
- 句子看作词的序列
- 层次化处理得到文本表示
文本分类性能评估
- 分类效果评估
- TP、TN、FP、FN
- 召回率、精确率、F-1值
- 正确率、宏平均(少类)、微平均(多类)
- 二分类且类别互斥的情况下,微观平均准确率、召回率和F1值均相同
- P-R曲线、ROC曲线
文本聚类
文本相似度度量
- 两个文本对象之间的相似度
- 基于距离的度量
- 欧式距离
- 曼哈顿距离
- 切比雪夫距离 d ( a , b ) = max k ∣ a k − b k ∣ d(a, b) = \max_k |a_k - b_k| d(a,b)=maxk∣ak−bk∣
- 闵可夫斯基距离 d ( a , b ) = ( ∑ k = 1 M ( a k − b k ) p ) 1 / p d(a, b) = \left(\sum_{k = 1}^M (a_k - b_k) ^p \right)^{1 / p} d(a,b)=(∑k=1M(ak−bk)p)1/p
- 基于余弦的度量
- cos ( a , b ) = a ⊤ b ∥ a ∥ ∥ b ∥ \cos (a, b) = \frac {a^\top b}{\|a\|\|b\|} cos(a,b)=∥a∥∥b∥a⊤b
- 杰卡德相似系数
- Jaccard = ∣ a ∩ b ∣ ∣ a ∪ b ∣ \operatorname{Jaccard} = \frac {|a \cap b|}{|a \cup b|} Jaccard=∣a∪b∣∣a∩b∣
- 基于分布的度量
- D K L ( P ∣ ∣ Q ) = ∑ i P ( i ) log P ( i ) Q ( i ) D_{KL}(P||Q) = \sum_i P(i) \log \frac {P(i)}{Q(i)} DKL(P∣∣Q)=∑iP(i)logQ(i)P(i)
- 对称化处理 D S K L = D K L ( P ∣ ∣ Q ) + D K L Q ∣ ∣ P D_{SKL} = D_{KL}(P||Q) + D_KL{Q||P} DSKL=DKL(P∣∣Q)+DKLQ∣∣P
- 基于距离的度量
- 两个文本集合之间的相似度
- 最短距离法
- 最长距离法
- 簇平均法
- 重心法(各自重心之间的距离)
- 离差平方和法
- 两个簇中格言本到两个簇合并后的簇中心的距离平方和,相比于各样本到各自簇中心之间的距离平方和增量
- d ( C m , C n ) = ∑ x ( k ) ∈ C m ∪ C n d ( x ( k ) , x ˉ ( C M ∪ C n ) ) − ∑ x ( i ) ∈ C m d ( x ( i ) , x ˉ ( C m ) ) − ∑ x ( j ) ∈ C n d ( x ( j ) , x ˉ ( C m ) ) d(C_m, C_n) = \sum_{x^{(k)} \in C_m \cup C_n} d(x^{(k)}, \bar x (C_M \cup C_n)) - \sum_{x^{(i)} \in C_m} d(x^{(i)}, \bar x (C_m)) - \sum_{x^{(j)} \in C_n} d(x^{(j)}, \bar x(C_m)) d(Cm,Cn)=∑x(k)∈Cm∪Cnd(x(k),xˉ(CM∪Cn))−∑x(i)∈Cmd(x(i),xˉ(Cm))−∑x(j)∈Cnd(x(j),xˉ(Cm))
- 文本对象和文本集合的相似性
- 样本与簇之间的相似性通常转化为样本间的相似度或簇间的相似度进行计算
- 如果用均值向量来表示一个簇,那么样本与簇之间的相似性可以转化为样本与均值向量的样本相似性
- 如果将一个样本视为一个簇,那么就可以采用前面介绍的簇间的相似性度量方法进行计算
文本聚类算法
- K-means聚类
- 簇内平方和法
- 词频作为特征
- 文本降维后进行聚类
- Pros:理解简单、易于实现、应用广泛
- Cons:聚类数难确定、中心点选择需要技巧、距离函数选择没有确定准则
- 单遍聚类
- 遍历一遍即可完成聚类
- 初始化:读入一个文本,作为一个簇
- 逐个读入文本,相似度小于阈值,产生一个新的簇,否则归类到最大相似度的簇
- 层次聚类
- 依据一种层次架构将数据逐层进行聚合或分裂,最终将数据对象组织成聚类树状的结构
- 自底向上的聚合式层次聚类
- 自顶向下的分裂式层次聚类
- 分裂式需要注意的问题
- 选择哪个类进行分裂
- 具体的分裂策略
- 密度聚类
- 样本空间中分布密集的样本点被分布稀疏的样本点分割
- DBSCAN算法相关概念
- 邻域半径 r r r
- 高密度区域形成的最小样本数 x x x
- r r r邻域:某样本 P P P的 r r r邻域指以 p p p为中心、 r r r为半径形成圆形领域
- 核心样本:如果某点 P P P的 r r r邻域中的样本数不少于 n n n,则称 P P P为核心样本
- 密度直达:如果样本 Q Q Q在核心样本 P P P的 r r r邻域内,则称 Q Q Q从 P P P密度直达
- 密度可达:如果存在一个样本序列 P 1 , … , P T P_1, \dots, P_T P1,…,PT,且对任意 t = 1 , … , T − 1 t = 1, \dots, T-1 t=1,…,T−1, P t + 1 P_{t + 1} Pt+1可由 P t P_t Pt密度直达,则称 P T P_T PT从 P 1 P_1 P1密度可达,序列中的传递样本 P 2 , … , P T − 1 P_2, \dots, P_{T - 1} P2,…,PT−1均为核心样本
- 密度相连:如果存在核心样本 P P P,使得样本 Q 1 Q_1 Q1和 Q 2 Q_2 Q2均从 P P P密度可达,则称 Q 1 Q_1 Q1和 Q 2 Q_2 Q2密度相连
- DBSCAN算法认为,对于任一核心样本 P P P,样本集中所有从 P P P密度可达的样本构成的集合属于同一个聚类
- DBSCAN算法
- 从某个核心样本出发,不断向密度可达的区域扩张,从而得到一个包含核心样本和边界样本的最大区域,该区域中任意两点密度相连,聚合为一个簇
- 继续寻找未被标记的核心样本,重复上述过程,直到样本集中无新核心样本为止
- 样本集中未包含在任何簇中的样本点构成噪声点簇
文本聚类性能评估
- 外部标准
- 通过测量聚类结果与参考标准的一致性评价聚类结果的优劣
- 参考标准通常由专家构建或人工标注获得
- 聚类标准 P = { P 1 , … , P m } \mathcal P = \{P_1, \dots, P_m\} P={P1,…,Pm}
- 聚类结果 C = { C 1 , … , C k } \mathcal C = \{C_1, \dots, C_k\} C={C1,…,Ck}
- 对于数据集 D D D中两个不同样本 d i d_i di和 d j d_j dj,其隶属于 C \mathcal C C和 P \mathcal P P的情况,定义四种关系
- SS:二者在结果中属于同簇,标准中也属于同簇——a
- SD:二者在结果中属于同簇,标准中属于不同簇——b
- DS:二者在结果中属于不同簇,标准中属于同簇——c
- DD:二者在结果中属不同簇,标准中也属不同簇——d
- Rand统计量: R S = a + d a + b + c + d RS = \frac {a + d} {a + b + c + d} RS=a+b+c+da+d
- Jaccard系数: J C = a a + b + c JC = \frac {a}{a+b+c} JC=a+b+ca
- FM指数: F M I = a a + b ⋅ a a + c FMI = \sqrt{\frac {a}{a + b} \cdot \frac {a}{a + c}} FMI=a+ba⋅a+ca
- 主要考察聚类宏观性能,在传统的聚类有效性分析中被较多地使用,在文本聚类研究中并不多见
- 微观指标
- 精准率 P ( P j , C i ) = ∣ P j ∩ C i ∣ ∣ C i ∣ P(P_j, C_i) = \frac {|P_j \cap C_i|}{|C_i|} P(Pj,Ci)=∣Ci∣∣Pj∩Ci∣
- 召回率 R ( P j , C i ) = ∣ P j ∩ C i ∣ ∣ P j ∣ R(P_j, C_i) = \frac {|P_j \cap C_i|}{|P_j|} R(Pj,Ci)=∣Pj∣∣Pj∩Ci∣
- F-1值 F 1 ( P j , C i ) = 2 P ( P j , C i ) R ( P j C i ) P ( P j , C i ) + R ( P j , C i ) F_1(P_j, C_i) = \frac {2 P(P_j, C_i) R(P_j C_i)}{P(P_j, C_i) + R(P_j, C_i)} F1(Pj,Ci)=P(Pj,Ci)+R(Pj,Ci)2P(Pj,Ci)R(PjCi)
- 宏观F-1值: F 1 ( P j ) = max i F 1 ( P j , C i ) , F 1 = ∑ j ∣ P j ∣ F 1 ( P j ) ∑ j ∣ P j ∣ F_1(P_j) = \max_i {F_1(P_j, C_i)},\ F_1 = \frac {\sum_j |P_j| F_1(P_j)}{\sum_j|P_j|} F1(Pj)=maxiF1(Pj,Ci), F1=∑j∣Pj∣∑j∣Pj∣F1(Pj)
- 更加丰富地刻画了各簇聚类结果与聚类参考标准之间的吻合度
- 通过测量聚类结果与参考标准的一致性评价聚类结果的优劣
- 内部标准
- 基于内部标准的聚类性能评价方法不依赖于外部标注,而仅靠考察聚类本身的分布结构评估聚类的性能
- 簇间最大,簇内最小
- 常用方法:轮廓系数
- d d d所在簇未 C m C_m Cm, a ( d ) a(d) a(d)为其于簇中其他样本的平均距离, b ( d ) b(d) b(d)为其于其他簇中样本的最小平均距离
- 样本 d d d的轮廓系数 S C ( d ) = b ( d ) − a ( d ) max a ( d , b ( d ) ) SC(d) = \frac {b(d) - a(d)}{\max{a(d, b(d))}} SC(d)=maxa(d,b(d))b(d)−a(d)
- 总体轮廓系数 S C = 1 N ∑ i = 1 N S C ( d i ) SC = \frac 1N \sum_{i = 1}^N SC(d_i) SC=N1∑i=1NSC(di)
- 系数越大,聚类效果越好