What Is Cloud Native Infrastructure?
Infrastructure is all the software and hardware that support applications.This includes data centers, operating systems, deployment pipelines, configuration management, and any system or software needed to support the life cycle of applications.
Countless time and money has been spent on infrastructure. Through years of evolving(改进) the technology and refining(精炼) practices, some companies have been able to run infrastructure and applications at massive scale and with renowned(著名的) agility. Efficiently(高效地) running infrastructure accelerates(加速) business by enabling faster iteration and shorter times to market.
Cloud native infrastructure is a requirement to effectively run cloud native applications. Without the right design and practices to manage infrastructure, even the best cloud native application can go to waste. Immense(巨大的) scale is not a prerequisite(先决条件) to follow the practices laid out in this book, but if you want to reap(收获) the rewards(回报) of the cloud, you should heed(注意) the experience of those who have pioneered(开拓) these patterns.
Before we explore how to build infrastructure designed to run applications in the cloud, we need to understand how we got where we are. First, we’ll discuss the benefits of adopting(采用) cloud native practices. Next, we’ll look at a brief history of infrastructure and then discuss features of the next stage, called “cloud native,” and how it relates(联系) to your applications, the platform where it runs, and your business.
Once you understand the problem, we’ll show you the solution and how to implement it.
Cloud Native Benefits
The benefits of adopting the patterns in this book are numerous(许多的). They are modeled(为榜样) after successful companies such as Google, Netflix, and Amazon—not that the patterns alone(单独的) guaranteed(保证) their success, but they provided the scalability and agility these companies needed to succeed.
By choosing to run your infrastructure in a public cloud, you are able to produce value faster and focus on your business objectives(目标). Building only what you need to create your product, and consuming services from other providers, keeps your lead time(交付周期) small and agility high. Some people may be hesitant(犹豫的) because of “vendor lock-in”(厂商绑定) but the worst kind of lock-in is the one you build yourself. See Appendix B for more information about different types of lock-in and what you should do about it.
Consuming services also lets you build a customized(定制的) platform with the services you need (sometimes called Services as a Platform [SaaP]). When you use cloud-hosted(云托管) services, you do not need expertise(专长) in operating every service your applications require. This dramatically(极大的) impacts your ability to change and adds value to your business.
When you are unable to consume services, you should build applications to manage infrastructure. When you do so, the bottleneck(瓶颈) for scale no longer depends on how many servers can be managed per operations engineer. Instead, you can approach scaling your infrastructure the same way as scaling your applications. In other words, if you are able to run applications that can scale, you can scale(拓展) your infrastructure with applications.
The same benefits apply for making infrastructure that is resilient(弹性的) and easy to debug. You can gain insight into(对..深刻理解) your infrastructure by using the same tools you use to manage your business applications.
Cloud native practices can also bridge(弥补) the gap(隔阂) between traditional engineering roles (a common goal of DevOps). Systems engineers will be able to learn best practices from applications, and application engineers can take ownership of the infrastructure where their applications run.
Cloud native infrastructure is not a solution for every problem, and it is your responsibility to know if it is the right solution for your environment (see Chapter 2). However, its success is evident(明显地) in the companies that created the practices and the many other companies that have adopted the tools that promote these patterns. See Appendix C for one example.
Before we dive into the solution, we need to understand how these patterns evolved(演变) from the problems that created them.
Servers【物理服务器】
At the beginning of the internet, web infrastructure got its start with physical servers. Servers are big, noisy, and expensive, and they require a lot of power and people to keep them running. They are cared for extensively and kept running as long as possible. Compared to cloud infrastructure, they are also more difficult to purchase(购买) and prepare for an application to run on them.
Once you buy one, it’s yours to keep, for better or worse. Servers fit into the well established capital expenditure cost of business. The longer you can keep a physical server running, the more value you will get from your money spent. It is always important to do proper(合适的) capacity(容量) planning and make sure you get the best return on investment(投资).
Physical servers are great because they’re powerful and can be configured however you want. They have a relatively low failure rate(故障率) and are engineered to avoid failures with redundant(多余的) power supplies(电力), fans, and RAID controllers. They also last a long time. Businesses can squeeze extra value out of hardware they purchase through extended warranties(维修期) and replacement(更换) parts.
However, physical servers lead to(导致) waste. Not only are the servers never fully utilized(利用), but they also come with a lot of overhead. It’s difficult to run multiple applications on the same server. Software conflicts, network routing, and user access all become more complicated when a server is maximally(最大地) utilized with multiple applications.
Hardware virtualization promised to solve some of these problems.
Virtualization 【虚拟化】
Virtualization emulates(模拟) a physical server’s hardware in software. A virtual server can be created on demand(按需), is entirely(完全地) programmable in software, and never wears out(磨损) so long as you can emulate the hardware.
Using a hypervisor2 increases these benefits because you can run multiple virtual machines (VMs) on a physical server. It also allows applications to be portable(可移植的) because you can move a VM from one physical server to another.
One problem with running your own virtualization platform, however, is that VMs still require hardware to run. Companies still need to have all the people and processes required to run physical servers, but now capacity planning becomes harder because they have to account for VM overhead too. At least, that was the case until the public cloud.
Infrastructure as a Service 【IaaS】
Infrastructure as a Service (IaaS) is one of the many offerings of a cloud provider. It provides raw networking, storage, and compute that customers can consume as needed. It also includes support services such as identity and access management (IAM), provisioning, and inventory(库存) systems.
IaaS allows companies to get rid of(摆脱) all of their hardware and to rent VMs or physical servers from someone else. This frees up a lot of people resources and gets rid of pro‐ cesses that were needed for purchasing, maintenance, and, in some cases, capacity planning.
IaaS fundamentally changed infrastructure’s relationship with businesses. Instead of being a capital expenditure benefited from over time, it is an operational expense for running your business. Businesses can pay for their infrastructure the same way they pay for electricity and people’s time. With billing based on consumption, the sooner you get rid of infrastructure, the smaller your operational costs will be.
Hosted infrastructure also made consumable HTTP Application Programming Inter‐ faces (APIs) for customers to create and manage infrastructure on demand. Instead of needing a purchase order and waiting for physical items to ship, engineers can make an API call, and a server will be created. The server can be deleted and dis‐ carded just as easily.
Running your infrastructure in a cloud does not make your infrastructure cloud native. IaaS still requires infrastructure management. Outside of purchasing and managing physical resources, you can—and many companies do—treat IaaS identi‐ cally to the traditional infrastructure they used to buy and rack in their own data centers.
Even without “racking and stacking,” there are still plenty of operating systems, moni‐ toring software, and support tools. Automation tools3 have helped reduce the time it takes to have a running application, but oftentimes ingrained processes can get in the way of reaping the full benefit of IaaS.
Platform as a Service 【PaaS】
Just as IaaS hides physical servers from VM consumers, platform as a service (PaaS) hides operating systems from applications. Developers write application code and define the application dependencies, and it is the platform’s responsibility to create the necessary infrastructure to run, manage, and expose it. Unlike IaaS, which still requires infrastructure management, in a PaaS the infrastructure is managed by the platform provider.
It turns out, PaaS limitations required developers to write their applications differ‐ ently to be effectively managed by the platform. Applications had to include features that allowed them to be managed by the platform without access to the underlying operating system. Engineers could no longer rely on SSHing to a server and reading log files on disk. The application’s life cycle and management were now controlled by the PaaS, and engineers and applications needed to adapt.
With these limitations came great benefits. Application development cycles were reduced because engineers did not need to spend time managing infrastructure. Applications that embraced running on a platform were the beginning of what we now call “cloud native applications.” They exploited the platform limitations in their code and in many cases changed how applications are written today.
12-Factor Applications
Heroku was one of the early pioneers who offered a publicly consumable PaaS. Through many years of expanding its own platform, the company was able to identify patterns that helped applications run better in their environment. There are 12 main factors that Heroku defines that a developer should try to implement.
The 12 factors are about making developers efficient by separating code logic from data; automating as much as possible; having distinct build, ship, and run stages; and declaring all the application’s dependencies.
If you consume all your infrastructure through a PaaS provider, congratulations, you already have many of the benefits of cloud native infrastructure. This includes plat‐ forms such as Google App Engine, AWS Lambda, and Azure Cloud Services. Any successful cloud native infrastructure will expose a self-service platform to applica‐ tion engineers to deploy and manage their code.
However, many PaaS platforms are not enough for everything a business needs. They often limit language runtimes, libraries, and features to meet their promise of abstracting away the infrastructure from the application. Public PaaS providers will also limit which services can integrate with the applications and where those applica‐ tions can run.
Public platforms trade application flexibility to make infrastructure somebody else’s problem. Figure 1-1 is a visual representation of the components you will need to manage if you run your own data center, create infrastructure in an IaaS, run your applications on a PaaS, or consume applications through software as a service (SaaS).
The fewer infrastructure components you are required to run, the better; but running all your applications in a public PaaS provider may not be an option.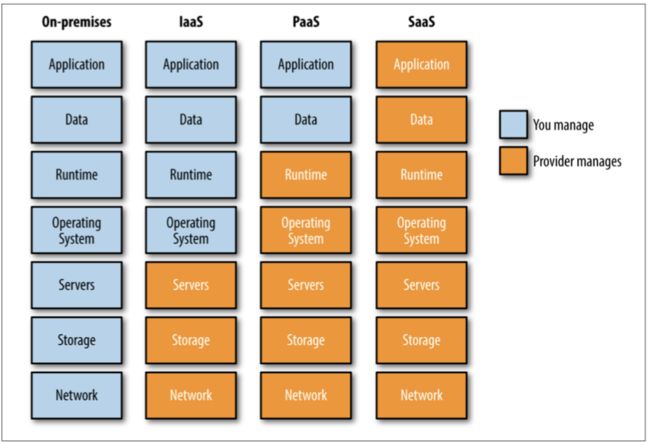
Cloud Native Infrastructure
“Cloud Native”是一个被市场过度解读的术语,但是它对于工程与管理来说仍然具有意义,对于我们,这是公有云提供商的技术演变史。
“Cloud native” is a loaded term. As much as it has been hijacked by marketing departments, it still can be meaningful for engineering and management. To us, it is the evolution of technology in the world where public cloud providers exist.
“Cloud native infrastructure”是为了运行程序而隐藏在组件背后的由API控制,软件管理基础设施。通过此些特征运行的基础设施产生了一种新的可拓展的,高效的模式。
Cloud native infrastructure is infrastructure that is hidden behind useful abstractions, controlled by APIs, managed by software, and has the purpose of running applications. Running infrastructure with these traits(特征) gives rise to a new pattern for managing that infrastructure in a scalable, efficient way.
当“抽象”对客户可以隐藏复杂性的时候,它是有用的。它可以实现更复杂的技术使用方式,但它也限制了技术的使用方式。 它适用于底层技术,例如TCP基于IP的抽象,或更高级别的协议,再例如虚拟机如何抽象物理服务器。 抽象应该总是让用户的关注点向上层移动,而不是重新实现底层技术。
Abstractions are useful when they successfully hide complexity for their consumer. They can enable more complex uses of the technology, but they also limit how the technology is used. They apply to low-level technology, such as how TCP abstracts IP, or higher levels, such as how VMs abstract physical servers. Abstractions should always allow the consumer to “move up the stack” and not reimplement the lower layers.
Cloud native infrastructure需要抽象底层IaaS产品以提供自己的组件。 新的抽象层负责控制其下层的IaaS,并通过开发API以供客户端控制。
Cloud native infrastructure needs to abstract the underlying IaaS offerings to provide its own abstractions. The new layer is responsible for controlling the IaaS below it as well as exposing its own APIs to be controlled by a consumer.
由软件管理的基础设施是云中的关键差异化因素。 软件控制的基础设施可以使基础设施变得可扩展,而且它在弹性、资源调配和可维护性方面也发挥着作用。该软件需要了解基础设施的抽象,并知道如何获取抽象资源并相应地在可消耗的IaaS组件中实现它。
Infrastructure that is managed by software is a key differentiator in the cloud. Software-controlled infrastructure enables infrastructure to scale, and it also plays a role in resiliency, provisioning, and maintainability. The software needs to be aware of the infrastructure’s abstractions and know how to take an abstract resource and implement it in consumable IaaS components accordingly.
这些模式不仅仅影响基础设施的运行方式。在“Cloud Native Infrastructure”上运行的App以及相应的工作人员也与传统基础设施中有所不同。
These patterns influence more than just how the infrastructure runs. The types of applications that run on cloud native infrastructure and the kinds of people who work on them are different from those in traditional infrastructure.
如果“Cloud Native Infrastructure”看起来非常像PaaS产品,那么我们在构建自己的基础设施时应该注意什么?让我们快速描述一些看起来像解决方案但不提供全面的Cloud Native Infrastructure的案例。
If cloud native infrastructure looks a lot like a PaaS offering, how can we know what to watch out for when building our own? Let’s quickly describe some areas that may appear like the solution, but don’t provide all aspects of cloud native infrastructure.
What Is Not Cloud Native Infrastructure? (什么不是云原生基础设施)
Cloud Native Infrastructure不仅仅是运行在公有云上的基础设施。仅仅从其他人那租用服务器的使用时间并不能使您的基础设施Cloud Native。管理IaaS的过程往往与运行一个物理的机房没有区别,许多将现有基础设施迁移到云上的公司都未能获得回报。
Cloud native infrastructure is not only running infrastructure on a public cloud. Just because you rent server time from someone else does not make your infrastructure cloud native. The processes to manage IaaS are often no different than running a physical data center, and many companies that have migrated existing infrastructure to the cloud have failed to reap the rewards.
Cloud Naive不是在容器内运行程序,当Netflix率先推出云本机基础设施时,其几乎所有应用程序都部署在虚拟机映像里,而不是容器。这种打包整个程序并不意味着你将能够拥有拓展性和自运维系统的好处。即使您的应用程序是通过持续集成和持续交付流水线自动构建和部署的,也不意味着您将受益于这种可以补全API驱动部署的基础设施中。
Cloud native is not about running applications in containers. When Netflix pioneered cloud native infrastructure, almost all its applications were deployed with virtualmachine images, not containers. The way you package your applications does not mean you will have the scalability and benefits of autonomous systems. Even if your applications are automatically built and deployed with a continuous integration and continuous delivery pipeline, it does not mean you are benefiting from infrastructure that can complement API-driven deployments.
它也不意味着您只需要运行一个容器编排系统(例如Kubernetes和Meos)。容器编排系统提供了Cloud Native Infrastructure中所需的许多平台功能,但不按预期使用这些feature的话,就意味着不的应用程序是被动态调度运行在一组服务器上。这是非常好的第一步,但还不够。
It also doesn’t mean you only run a container orchestrator (e.g., Kubernetes and Mesos). Container orchestrators provide many platform features needed in cloud native infrastructure, but not using the features as intended means your applications are dynamically scheduled to run on a set of servers. This is a very good first step, but there is still work to be done.
Cloud Native不是关于微服务的,也不是“infrastructure as code”,微服务通过更细粒度的不同的功能划为,实现更快的开发周期,但单体应用也可以具有相同的功能,被有效地管理,也可以从Cloud Native Infrastruture中受益。
Cloud native is not about microservices or infrastructure as code. Microservices enable faster development cycles on smaller distinct functions, but monolithic applications can have the same features that enable them to be managed effectively by software and can also benefit from cloud native infrastructure.
Infrastructure as code是通过“机器可解析语言”或领域特定语言(DSL)使基础设施自动化。将code应用于基础设施的传统工具包括配置管理工具(如Chef和Puppet)。这些工具在自动化任务和一致性方面有很大的帮助,但是它无法提供必要的抽象来描述单个服务器之外的基础设施。
Infrastructure as code defines and automates your infrastructure in machine-parsible language or domain-specific language (DSL). Traditional tools to apply code to infrastructure include configuration management tools (e.g., Chef and Puppet). These tools help greatly in automating tasks and providing consistency, but they fall short in providing the necessary abstractions to describe infrastructure beyond a single server.
配置管理工具可以在人的操作下,一次性自动化将配置与程序联系在一起进行部署,“人”就可能成为扩容的瓶颈。 这些工具也不会自动生成一个完整系统所需的额外部分(例如,存储和网络)。
Configuration management tools automate one server at a time and depend on humans to tie together the functionality provided by the servers. This positions humans as a potential bottleneck for infrastructure scale. These tools also don’t automate the extra parts of cloud infrastructure (e.g., storage and network) that are needed to make a complete system.
虽然配置管理工具为操作系统的资源(例如,部署包管理)提供了一些抽象,但它们并没有抽象出足够的底层操作系统来轻松管理它。 如果工程师想要管理系统上的每个包和文件,那么这将是一个非常艰苦的过程,而且对于每个配置变量都是独一无二的。 同样,不定义或定义不正确的配置管理,只会消耗系统资源并且不提供任何价值。
While configuration management tools provide some abstractions for an operating system’s resources (e.g., package managers), they do not abstract away enough of the underlying OS to easily manage it. If an engineer wanted to manage every package and file on a system, it would be a very painstaking process and unique to every configuration variant. Likewise, configuration management that defines no, or incorrect, resources is only consuming system resources and providing no value.
虽然配置管理工具可以帮助实现部分基础设施的自动化,但它们不能更好地帮助管理应用程序。我们将在后面的章节中介绍部署、管理、测试和操作基础设施的流程,以探索Cloud Native Infrastuture的不同之处,但首先我们将了解哪些应用程序是成功的,以及何时应使用Cloud Native Infrastuture。
While configuration management tools can help automate parts of infrastructure, they don’t help manage applications better. We will explore how cloud native infrastructure is different by looking at the processes to deploy, manage, test, and operate infrastructure in later chapters, but first we will look at which applications are successful and when you should use cloud native infrastructure.
Cloud Native Applications(云原生应用)
像云改变业务与基础设施直接的关系一样,云原生基础设施改变了应用与基础设施的关系。我们需要看到Cloud Native应用与传统应用之间的不同,以便我们了解它们与基础设施的新关系。
Just as the cloud changed the relationship between business and infrastructure, cloud native applications changed the relationship between applications and infrastructure. We need to see what is different about cloud native compared to traditional applications so we can understand their new relationship with infrastructure.
出于本书需要有一个共享的词汇表的目的,我们需要定义当我们说“cloud native application”时的含义。Cloud Native与12-Factor App不同,即使它们可能有一些类似的特征。 如果您想了解更多有关它们如何不同的详细信息,我们建议您阅读Kevin Hoffman撰写的Beyond the Twelve-Factor App(O'Reilly,2012)。
For the purposes of this book, and to have a shared vocabulary, we need to define what we mean when we say “cloud native application.” Cloud native is not the same thing as a 12-factor application, even though they may share some similar traits. If you’d like more details about how they are different, we recommend reading Beyond the Twelve-Factor App, by Kevin Hoffman (O’Reilly, 2012).
一个云原生应用程序是被设计在平台上运行,旨在实现弹性,敏捷性,可操作性和可观察性。
- 弹性:允许失败,而不是试图阻止它; 它利用了运行在平台上的动态特性。
- 敏捷性:允许快速部署和快速迭代。
- 可操作性增加了程序内部对于App生命周期的控制,而不是依赖于外部进程和监控服务。
-
可观察性提供了有关应用程序状态问题的信息。
Cloud Native Application的定义仍在不断发展。 CNCF等组织还有其他定义。A cloud native application is engineered to run on a platform and is designed for resiliency, agility, operability, and observability. Resiliency embraces failures instead of trying to prevent them; it takes advantage of the dynamic nature of running on a platform. Agility allows for fast deployments and quick iterations. Operability adds control of application life cycles from inside the application instead of relying on external processes and monitors. Observability provides information to answer questions about application state.
The definition of a cloud native application is still evolving. There are other definitions available from organizations like the CNCF.
云原生应用程序通过各种方法获取这些特征。 它通常取决于您的应用程序运行的位置以及业务的流程和文化。 以下是实现云原生应用程序所需特征的常用方法:
Cloud native applications acquire these traits through various methods. It can often depend on where your applications run5 and the processes and culture of the business. The following are common ways to implement the desired characteristics of a cloud native application:
- Microservices(微服务)
- Health reporting(健康报告)
- Telemetry data(遥测数据,通过传感器被遥测终端接收到的实时数据)
- Resiliency(弹性)
- Declarative, not reactive(声明式,而非反应式)
Microservices (微服务)
作为单个实体管理和部署的应用程序通常称为单体应用程序。在最初开发应用程序时,单体应用有很多好处。它们更容易理解并允许您在不影响其他服务的情况下更改主要功能。
Applications that are managed and deployed as single entities are often called monoliths. Monoliths have a lot of benefits when applications are initially developed. They are easier to understand and allow you to change major functionality without affect‐ ing other services.
随着应用程序的复杂性的增加,单体应用程序的好处逐渐减少。它们变得越来越难理解,并且它们失去了敏捷性,因为工程师很难对代码进行推理和更改。
As complexity of the application grows, the benefits of monoliths diminish. They become harder to understand, and they lose agility because it is harder for engineers to reason about and make changes to the code.
对抗复杂性的最佳方法之一是将明确定义的功能分离为较小的服务,并让每个服务独立地迭代。通过按需更改的应用程序的部分,来提高应用程序的灵活性。每个微服务可以由单独的团队管理,用适当的语言编写,并根据需要独立扩展。
One of the best ways to fight complexity is to separate clearly defined functionality into smaller services and let each service independently iterate. This increases the application’s agility by allowing portions of it to be changed more easily as needed. Each microservice can be managed by separate teams, written in appropriate lan‐ guages, and be independently scaled as needed.
只要每个服务都坚守约定,应用程序就可以快速改进和更改。当然,迁移到微服务体系结构还需要考虑其他许多因素。其中最重要的是我们在附录A中提到的弹性通讯。
So long as each service adheres to strong contracts, the application can improve and change quickly. There are of course many other considerations for moving to micro‐ service architecture. Not the least of these is resilient communication, which we address in Appendix A.
我们不可能想到所有的迁移微服务的考虑点。拥有microservices并不意味着您拥有cloud native infrastructure。如果您想了解更多信息,我们建议Sam Newman的《Building Microservices》(O'Reilly,2015)。正如我们前面所说,虽然微服务是实现应用程序敏捷性的一种方法,但对于Cloud Native Application来说,不是必须的。
We cannot go into all considerations for moving to microservices. Having microser‐ vices does not mean you have cloud native infrastructure. If you would like to read more, we suggest Sam Newman’s Building Microservices (O’Reilly, 2015). While microservices are one way to achieve agility with your applications, as we said before, they are not a requirement for cloud native applications.
Health Reporting(健康报告)
没有人比开发人员更了解应用程序在健康状态下运行需要什么。 很长一段时间,一直试图弄清楚“健康”对于他们负责运行的应用程序意味着什么。 如果不了解实际使应用程序健康的原因,他们在应用程序“不健康时”监控和告警的尝试往往是脆弱和不完整的。
No one knows more about what an application needs to run in a healthy state than the developer. For a long time, infrastructure administrators have tried to figure out what “healthy” means for applications they are responsible for running. Without knowledge of what actually makes an application healthy, their attempts to monitor and alert when applications are unhealthy are often fragile and incomplete.
为了提高云原生应用的可操作性,应用程序应暴露一个运行状况检查的接口。 开发人员可以将其实现为应用程序在执行自检后可以响应的命令或进程信号,或者更常见的是,作为由通过HTTP提供返回运行状况的应用程序的Web端点。
监控报告在Google Borg的一篇论文中出现:几乎每个在borg下运行的任务都包含一个内置的HTTP服务器,它发布有关任务运行状况和数千个性能指标(例如,RPC延迟)的信息。BORG监视健康检查URL,并重新启动没有及时响应或返回HTTP错误代码的任务。其他数据由仪表盘的监控工具和服务级别目标(SLO)违规警报跟踪。
To increase the operability of cloud native applications, applications should expose a health check. Developers can implement this as a command or process signal that the application can respond to after performing self-checks, or, more commonly, as a web endpoint provided by the application that returns health status via an HTTP code.
Google Borg Example,One example of health reporting is laid out in Google’s Borg paper:
Almost every task run under Borg contains a built-in HTTP server that publishes information about the health of the task and thousands of performance metrics (e.g., RPC latencies). Borg monitors the health-check URL and restarts tasks that do not respond promptly or return an HTTP error code. Other data is tracked by monitor‐ ing tools for dashboards and alerts on service-level objective (SLO) violations.
将健康责任转移到应用程序中使App更易于管理和自动化。应用程序应该知道它是否正常运行,以及它依赖什么(例如,对数据库的访问)来提供业务价值。这意味着开发人员需要与产品经理一起定义应用程序服务的业务功能,并相应地编写测试。
Moving health responsibilities into the application makes the application much easier to manage and automate. The application should know if it’s running properly and what it relies on (e.g., access to a database) to provide business value. This means developers will need to work with product managers to define what business function the application serves and to write the tests accordingly.
提供健康检查的应用程序示例包括ZooKeeper的ruok命令和etcd的http/health端点。
Examples of applications that provide heath checks include Zookeeper’s ruok com‐mand and etcd’s HTTP /health endpoint.
应用程序不仅仅具有健康或不健康的状态。它将经历一个启动和关闭过程,在此过程中,他们应该通过健康检查报告他们的状态。如果应用程序能够让平台准确地知道它处于什么状态,那么平台就更容易知道如何操作它。
Applications have more than just healthy or unhealthy states. They will go through a startup and shutdown process during which they should report their state through their health check. If the application can let the platform know exactly what state it is in, it will be easier for the platform to know how to operate it.
一个很好的例子是,当平台需要知道应用程序何时可以接收流量时。当应用程序启动时,它不能正确地处理流量,它应该表现为还没有准备好。此附加状态将阻止应用程序过早终止,因为如果健康检查失败,平台可能会假定应用程序不健康,并反复停止或重新启动应用程序。
A good example is when the platform needs to know when the application is available to receive traffic. While the application is starting, it cannot properly handle traffic(流量), and it should present itself as not ready. This additional state will prevent the application from being terminated prematurely, because if health checks fail, the platform may assume the application is not healthy and stop or restart it repeatedly.
应用程序运行状况只是能够自动化应用程序生命周期的一部分。除了知道应用程序是否健康外,还需要知道应用程序是否在执行工作。这些信息来自遥测数据。
Application health is just one part of being able to automate application life cycles. In addition to knowing if the application is healthy, you need to know if the application is doing any work. That information comes from telemetry data.
Telemetry Data(遥测数据)
遥测数据(类似于SLA数据)是决策所必需的信息。 确实,遥测数据可能与健康报告有些重叠,但它们有不同的用途。 健康报告通知我们应用程序的生命周期状态,而遥测数据通知我们应用程序业务目标。
Telemetry data is the information necessary for making decisions. It’s true that telemetry data can overlap somewhat with health reporting, but they serve different purposes. Health reporting informs us of application life cycle state, while telemetry data informs us of application business objectives.
您度量的指标有时称为服务级别指标(SLI)或关键性能指标(KPI)。这些是特定于应用程序的数据,允许您确保应用程序的性能在服务级别目标(SLO)内。如果您想要更多关于这些条款的信息以及它们如何与您的应用程序和业务需求相关,我们建议您阅读《Site Reliability Engineering》(O'Reilly)的第4章。
The metrics you measure are sometimes called service-level indicators (SLIs) or key performance indicators (KPIs). These are application-specific data that allow you to make sure the performance of applications is within a service-level objective (SLO). If you want more information on these terms and how they relate to your application and business needs, we recommend reading Chapter 4 from Site Reliability Engineering (O’Reilly).
遥测与指标被用来回答类似下列的问题:
- 应用程序每分钟接收多少请求?
- 有什么错误吗?
- 什么是应用程序延迟?
- 下订单需要多长时间?
Telemetry and metrics are used to solve questions such as:
- How many requests per minute does the application receive?
- Are there any errors?
- What is the application latency?
- How long does it take to place an order?
这些数据通常被采集或推送到时序数据库(用于存储和管理时间序列数据的专业化数据库,例如Prometheus或influxdb)进行聚合。对遥测数据的唯一要求是按照将要收集数据的系统进行格式化。
The data is often scraped or pushed to a time series database (e.g., Prometheus or InfluxDB) for aggregation. The only requirement for the telemetry data is that it is formatted for the system that will be gathering the data.
最好至少实现度量的RED方法,RED指速率(Rate)、错误(Error)和持续时间(Duration)。
- 速率:收到多少请求
- 错误:应用程序中的错误数
- 持续时间:收到响应的时间
It is probably best to, at minimum, implement the RED method for metrics, which collects rate, errors, and duration from the application.
- Rate:How many requests received
- Errors:How many errors from the application
- Duration:How long to receive a response
遥测数据应该应用于告警而不是健康监测。在动态的自我修复环境中,我们不太关心单个应用程序实例的生命周期,而更关心整个应用程序的SLO。健康报告对于自动化应用程序管理仍然很重要,但不应用于页面工程师。
Telemetry data should be used for alerting rather than health monitoring. In a dynamic, self-healing environment, we care less about individual application instance life cycles and more about overall application SLOs. Health reporting is still important for automated application management, but should not be used to page engineers.
如果一个应用程序的1个或50个实例不正常,只要满足该应用程序的业务需求,我们可能不希望收到警报。度量指标可以让您知道是否满足SLO、应用程序如何被使用以及应用程序的“正常”情况。警报可以帮助您将系统恢复到已知的良好状态。
如果它迁移,我们跟踪它。有时我们会绘制一个尚未移动的图形,以防万一决定让它run。
—Ian Malpass, Measure Anything, Measure Everything
If 1 instance or 50 instances of an application are unhealthy, we may not care to receive an alert, so long as the business need for the application is being met. Metrics let you know if you are meeting your SLOs, how the application is being used, and what “normal” is for your application. Alerting helps you to restore your systems to a known good state.
If it moves, we track it. Sometimes we’ll draw a graph of something that isn’t moving yet, just in case it decides to make a run for it.
—Ian Malpass, Measure Anything, Measure Everything
告警也不应与日志记录混淆。 日志记录用于调试,开发和观察模式。 它暴露了应用程序的内部设计。 指标(例如,错误率)有时可以从日志中计算,但是需要额外的聚合服务(例如,ElasticSearch)和处理。
Alerting also shouldn’t be confused with logging. Logging is used for debugging, development, and observing patterns. It exposes the internal functionality of your application. Metrics can sometimes be calculated from logs (e.g., error rate) but requires additional aggregation services (e.g., ElasticSearch) and processing.
Resiliency(弹性)
一旦您拥有遥测和监控数据,您需要确保您的应用程序能够抵御故障。 弹性曾经是基础设施的责任,但云原生应用程序需要承担部分工作。
Once you have telemetry and monitoring data, you need to make sure your applica‐ tions are resilient to failure. Resiliency used to be the responsibility of the infrastruc‐ ture, but cloud native applications need to take on some of that work.
基础设施旨在抵御失败。 硬件过去需要多个硬盘驱动器,电源以及全天候监控和部件更换以保持应用程序可用。 使用云原生应用程序,应用程序有责任接受失败而不是避免失败。
在任何平台中,尤其是在云中,最重要的特征是其可靠性。
—David Rensin, The ARCHITECHT Show: A crash course from Google on engineering for the cloud
Infrastructure was engineered to resist failure. Hardware used to require multiple hard drives, power supplies, and round-the-clock monitoring and part replacements to keep an application available. With cloud native applications, it is the application’s responsibility to embrace failure instead of avoid it.
In any platform, especially in a cloud, the most important feature above all else is its reliability.
—David Rensin, The ARCHITECHT Show: A crash course from Google on engineering for the cloud
设计弹性应用程序本身就是一本书。 我们将考虑使用云原生应用程序实现弹性的两个主要方面:故障设计和优雅降级。
Designing resilient applications could be an entire book itself. There are two main aspects to resiliency we will consider with cloud native application: design for failure, and graceful degradation.
Design for failure(故障设计)
唯一不应该故障的系统是让你活着的系统(例如,心脏搭桥和刹车)。 如果您的服务永远不会停止,您花费了太多时间来设计它们以抵御失败并且没有足够的时间来增加业务价值。 您的SLO确定服务需要多长的正常运行时间。 您用于设计超出SLO的正常运行时间的任何资源都被浪费了。
The only systems that should never fail are those that keep you alive (e.g., heart implants, and brakes). If your services never go down,8 you are spending too much time engineering them to resist failure and not enough time adding business value. Your SLO determines how much uptime is needed for a service. Any resources you spend to engineer uptime that exceeds the SLO are wasted.
您应该为每项服务测量的两个值,应该是您的平均故障间隔时间(MTBF)和平均恢复时间(MTTR)。 通过监控和指标,您可以检测是否满足SLO,但运行应用程序的平台是保持MTBF较高且MTTR较低的关键。
Two values you should measure for every service should be your your mean time between failures (MTBF) and mean time to recovery (MTTR). Monitoring and metrics allow you to detect if you are meeting your SLOs, but the platform where the applications run is key to keeping your MTBF high and your MTTR low.
在任何复杂的系统中,都会出现故障。 您可以管理硬件中的某些故障(例如,RAID和冗余电源)以及基础设施中的某些故障(例如,负载均衡器); 因为应用程序知道它们何时健康,所以它们也应该尽力管理自己的故障。
In any complex system, there will be failures. You can manage some failures in hardware (e.g., RAID and redundant power supplies) and some in infrastructure (e.g., load balancers); but because applications know when they are healthy, they should also try to manage their own failure as best they can.
与假设可用性的应用程序相比,设计有故障预期的应用程序将以更具防御性的方式开发。 当故障不可避免时,将在应用程序中内置额外的检查,故障模式和日志记录。
An application that is designed with expectations of failure will be developed in a more defensive way than one that assumes availability. When failure is inevitable, there will be additional checks, failure modes, and logging built into the application.
知道应用程序的每种失败方式是不可能的。假设任何事情都可能并且可能会失败的假设,是一种云原生应用程序模式。
It is impossible to know every way an application can fail. Developing with the assumption that anything can, and likely will, fail is a pattern of cloud native applications.
应用程序的最佳状态是健康。第二个最佳状态为失败。其他一切都是非二进制的,很难监控和排除故障。蜂窝公司的首席执行官慈善专业人士在她的文章“Ops: It’s Everyone’s Job Now”中指出,“分布式系统永远不会完全work;它们以一种持续的、部分退化的服务状态存在。接受失败,弹性设计,保护和缩小关键路径。”
The best state for your application to be in is healthy. The second best state is failed. Everything else is nonbinary and difficult to monitor and troubleshoot. Charity Majors, CEO of Honeycomb, points out in her article “Ops: It’s Everyone’s Job Now” that “distributed systems are never up; they exist in a constant state of partially degraded service. Accept failure, design for resiliency, protect and shrink the critical path.”
无论失败是什么,云本机应用程序都应该具有适应性。他们接收失败,所以当它被检测到时,他们会进行调整。
Cloud native applications should be adaptable no matter what the failure is. They expect failure, so they adjust when it’s detected.
有些故障不能也不应该设计进应用程序(例如,网络分区和可用性区域故障)。平台应自动处理未集成到应用程序中的故障领域。
Some failures cannot and should not be designed into applications (e.g., network partitions and availability zone failures). The platform should autonomously handle fail‐ ure domains that are not integrated into the applications.
Graceful degradation(优雅降级)
云本地应用程序需要有一种方法来处理过多的负载,不管它是应用程序还是依赖服务。处理负载的一种方法是优雅地降级。《Site Reliability Engineering》一书将应用程序中的优雅降级描述为在过载情况下提供“不如正常响应准确或包含的数据少于正常响应,但更容易计算的响应”。
Cloud native applications need to have a way to handle excessive load, no matter if it’s the application or a dependent service under load. One way to handle load is to degrade gracefully. The Site Reliability Engineering book describes graceful degradation in applications as offering “responses that are not as accurate as or that contain less data than normal responses, but that are easier to compute” when under excessive load.
某些减少应用程序负载的方面由基础设施处理。智能负载均衡和动态伸缩可能会有所帮助,但在某些时候,您的应用程序可能承受的负载可能会超过它所能处理的负载。云原生应用程序需要意识到这一必然性并做出相应的反应。
Some aspects of shedding application load are handled by infrastructure. Intelligent load balancing and dynamic scaling can help, but at some point your application may be under more load than it can handle. Cloud native applications need to be aware of this inevitability and react accordingly.
优雅降级的要点是允许应用程序总是返回对请求的响应。如果应用程序没有足够的本地计算资源,以及依赖服务没有及时返回信息,则这种情况确实如此。依赖于一个或多个其他服务的服务对于响应请求应该是可用的,即使无法依赖于这些服务。当服务降级时,解决方案可能是返回部分答案或从本地缓存返回旧信息的答案。
The point of graceful degradation is to allow applications to always return an answer to a request. This is true if the application doesn’t have enough local compute resources, as well as if dependent services don’t return information in a timely manner. Services that are dependent on one or many other services should be available to answer requests even if dependent services are not. Returning partial answers, or answers with old information from a local cache, are possible solutions when services are degraded.
虽然应该在应用程序中实现优雅降级和故障处理,但平台的多个层应该也有所帮助。如果采用微服务,则网络基础设施将成为需要在提供应用程序弹性方面发挥积极作用的关键组件。有关构建弹性网络层的更多信息,请参阅附录A.
While graceful degradation and failure handling should both be implemented in the application, there are multiple layers of the platform that should help. If microservices are adopted, then the network infrastructure becomes a critical component that needs to take an active role in providing application resiliency. For more information on building a resilient network layer, please see Appendix A.
Declarative, Not Reactive(声明式,而非响应式)
由于云原生应用程序设计为在云环境中运行,因此它们与基础架构和支持应用程序的交互方式与传统应用程序不同。在云原生应用程序中,与任何其他服务通信的方式都是通过网络。许多时候,网络通信是通过RESTful HTTP调用完成的,但也可以通过其他接口实现,如远程过程调用(RPC)。
Because cloud native applications are designed to run in a cloud environment, they interact with infrastructure and supporting applications differently than traditional applications do. In a cloud native application, the way to communicate with anything is through the network. Many times network communication is done through RESTful HTTP calls, but it can also be implemented via other interfaces such as remote procedure calls (RPC).
传统应用程序可以通过消息队列、写在共享存储上的文件或触发shell命令的本地脚本来自动执行任务。 通信方法对发生的事件作出反应(例如,如果用户点击提交,运行提交脚本)并且通常需要信息存在于同一物理或虚拟服务器上。
Serverless:Serverless平台是云原生的,是事件反应式设计。 他们在云中工作得很好的一个原因是因为他们通过HTTP API进行通信,是单一用途的功能,并且在他们所称的内容中是声明性的。 该平台还有助于使它们在云中可扩展和访问。
Traditional applications would automate tasks through message queues, files written on shared storage, or local scripts that triggered shell commands. The communication method reacted to an event that happened (e.g., if the user clicks submit, run the submit script) and often required information that existed on the same physical or virtual server.
Serverless:Serverless platforms are cloud native and reactive to events by design. A reason they work so well in a cloud is because they communicate over HTTP APIs, are single- purpose functions, and are declarative in what they call. The platform also helps by making them scalable and accessible from within the cloud.
传统应用程序中的反应式通信通常是一种构建弹性的尝试。如果应用程序在磁盘或消息队列中写入文件然后应用程序死亡,则仍可以完成消息或文件的结果。
Reactive communication in traditional applications is often an attempt to build resiliency. If the application wrote a file on disk or into a message queue and then the application died, the result of the message or file could still be completed.
这并不是说不应该使用消息队列之类的技术,而是在动态且不断出现故障的系统中不能依赖它们作为唯一的弹性层。从根本上说,应用程序之间的通信应该在云原生环境中进行更改 - 不仅因为还有其他方法可以构建通信弹性(请参阅附录A),还因为在云中复制传统通信方法通常需要做更多工作。
This is not to say technologies like message queues should not be used, but rather that they cannot be relied on for the only layer of resiliency in a dynamic and constantly failing system. Fundamentally, the communication between applications should change in a cloud native environment—not only because there are other methods to build communication resiliency (see Appendix A), but also because it is often more work to replicate traditional communication methods in the cloud.
当应用程序可以信任通信的弹性时,它们应该停止响应式并开始声明式。声明式通信确信网络能够传递消息,还相信应用程序将返回成功或错误。这并不是说让应用程序注意变化并不重要。 Kubernetes的控制器就是这样做的API服务器。但是,一旦找到更改,它们就会声明一个新状态并信任API服务器和kubelet来执行必要的操作。
When applications can trust the resiliency of the communication, they should stop reacting and start declaring. Declarative communication trusts that the network will deliver the message. It also trusts that the application will return a success or an error. This isn’t to say having applications watch for change is not important. Kubernetes’ controllers do exactly that to the API server. However, once change is found, they declare a new state and trust the API server and kubelets to do the necessary thing.
由于许多原因,声明式通信模型变得更加健壮。最重要的是,它将通信模型标准化,并将一些功能实现从应用程序转移到远程API或服务端点,使其达到所需状态。这有助于简化应用程序,并使它们之间的行为更具可预测性。
The declarative communication model turns out to be more robust for many reasons. Most importantly, it standardizes a communication model and it moves the functional implementation of how something gets to a desired state away from the application to a remote API or service endpoint. This helps simplify applications and allows them to behave more predictably with each other.
How Do Cloud Native Applications Impact Infrastructure?(云原生应用程序如何影响基础设施?)
您可以知道云本机应用程序不同于传统应用程序。云本机应用程序不受益于直接在iaas上运行或与服务器的操作系统紧密耦合。他们希望在动态环境中运行,其中大部分是自主系统。
Hopefully, you can tell that cloud native applications are different than traditional applications. Cloud native applications do not benefit from running directly on IaaS or being tightly coupled to a server’s operating system. They expect to be run in a dynamic environment with mostly autonomous systems.
云原生基础架构在IaaS之上创建了一个提供自主应用程序管理的平台。该平台建立在动态创建的基础设施之上,以抽象出单个服务并促进动态资源分配调度。
Cloud native infrastructure creates a platform on top of IaaS that provides autonomous application management. The platform is built on top of dynamically created infrastructure to abstract away individual servers and promote dynamic resource allocation scheduling.
Automation is not the same thing as autonomous. Automation allows humans to have a bigger impact on the actions they take.
Cloud native is about autonomous systems that do not require humans to make decisions. It still uses automation, but only after deciding the action needed. Only when the system cannot automatically determine the right thing to do should it notify a human.
具有这些特征的应用程序需要一个可以实时监控,收集指标,然后在发生故障时做出反应的平台。 云原生应用程序不依赖于人员来设置ping检查或创建syslog规则。 它们需要从选择基本操作系统或包管理器中抽象出来的自助服务资源,并且它们依靠服务发现和强大的网络通信来提供功能丰富的体验
Applications with these characteristics need a platform that can pragmatically monitor, gather metrics, and then react when failures occur. Cloud native applications do not rely on humans to set up ping checks or create syslog rules. They require self-service resources abstracted away from selecting a base operating system or package manager, and they rely on service discovery and robust network communication to provide a feature-rich experience.
Conclusion
运行云原生应用程序所需的基础设施与传统应用程序不同。 过去许多需要基础设施处理的职责都已转移到应用程序中。
The infrastructure required to run cloud native applications is different than traditional applications. Many responsibilities that infrastructure used to handle have moved into the applications.
云原生应用程序通过分解为更小的服务来简化其代码复杂性。 这些服务提供监控,指标和直接构建到应用程序中的弹性。 需要新的工具来自动化服务扩散和生命周期管理的管理。
Cloud native applications simplify their code complexity by decomposing into smaller services. These services provide monitoring, metrics, and resiliency built directly into the application. New tooling is required to automate the management of service proliferation and life cycle management.
基础设施现在负责整体资源管理,动态编排,服务发现等等。 它需要提供一个服务不依赖于单个组件而是依赖于API和自动系统的平台。 第2章更详细地讨论了云原生基础设施的功能。
The infrastructure is now responsible for holistic resource management, dynamic orchestration, service discovery, and much more. It needs to provide a platform where services don’t rely on individual components, but rather on APIs and autonomous systems. Chapter 2 discusses cloud native infrastructure features in more detail.