好用的Airflow Platform
1. 简介
1.1 为什么是airflow?
Airflow 是 Airbnb 开发的用于工作流管理(管理和调度各种离线定时 Job ,可以替代 crontab)的开源平台,它以编程方式创作,自带 web UI 和调度。基于有向无环图(DAG),可以定义一组有依赖的任务,并按照依赖依次执行。提供了丰富的命令行工具用于系统管控,而其web管理界面同样也可以方便的管控调度任务,并且对任务运行状态进行实时监控,方便系统的运维和管理。
Airflow的调度,有定义图(DAG)、任务(Task)、依赖、监控之类的东西,基本上数仓是一个图对应一个调度,很相似的也可以放在一个图里做。
DAG 的定义使用 Python 完成的,其实就是一个 Python 文件,存放在 DAG 目录,Airflow 会动态的从这个目录构建 DAG object,每个 DAG object 代表了一个 workflow,每个 workflow 都可以包含任意个 task。
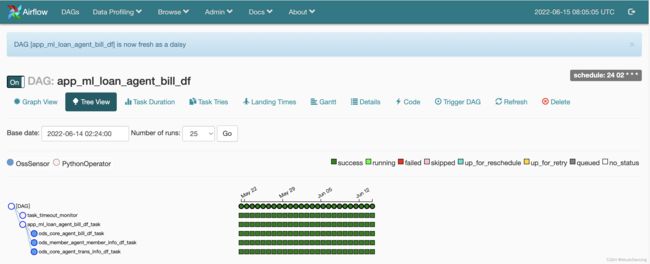
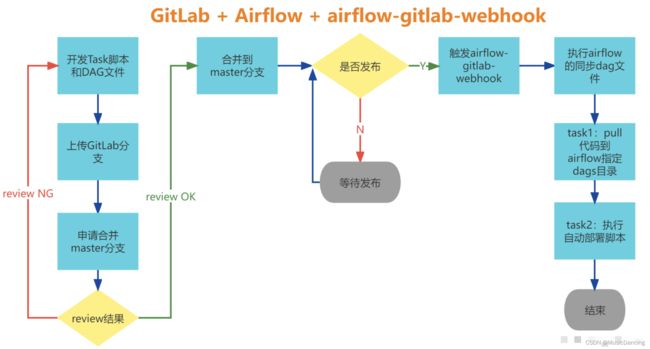
1.2 airflow自动部署流程
Gitlab持续发布自动部署方案
2. 环境配置
2.1 airflow 安装
查看是否已安装 airflow 模块:
pip list
# 或
pip show airflow 安装
pip install apache-airflow
# pip3 install "apache-airflow~=2.2.5"安装版本一般为 2.2.5
2.2 git权限开通
找相关负责人开通 airflow 项目git代码权限。
2.3 Pycharm 项目配置
从git 复制 airflow 项目地址(eg: [email protected]:bigdata/airflow-2.0-sa.git),在本地IDE环境新建项目,并创建个人分支。
2.4 开通airflow 服务器权限
--- 用于代码测试 ---
(1)登录airflow 服务器:
hw-xx-bigdata-prod-airflow-01-11.22.33.44 (通过跳板机登录)
(2)跳转到airflow 账户:
sudo su - airflow
# 激活环境(. ~/venv/bin/activate)(3)新建一个自己的目录(/home/airflow/zz),并把待运行脚本上传到这里
rz test_air_flow.py
(4)测试脚本中每一个任务task
airflow tasks test {dag_id} {task_id} {execution_date} -S {script path}
airflow tasks test app_daily_tj t2 '2023-08-28 10' -S app_daily_tj.py注意:dag_id 尽量多加后缀,不能与其他项目重复!
(5)代码测试通过之后,上传到git;
2.5 airflow平台权限开通
--- 代码正式例行调度 ---
代码上传到git平台后,过几分钟(运维配置会自动同步到Airflow调度任务),在Airflow平台通过筛选DAG或用户名,可以看到自己的任务,点击开关按钮,其会进行调度(并自动执行过往日期任务)。
3. 流程详解
本地编写"app_daily_tj.sql"文件和“app_daily_tj.py”文件(两者同名)。“app_daily_tj.py”脚本实际上只是一个配置文件,将DAG的结构指定为代码。
3.1 导包
# -*- coding: utf-8 -*-
import os
import requests
import logging
import MySQLdb
import time
from datetime import datetime, timedelta
from utils.validate_metrics_utils import *
from utils.connection_helper import get_hive_cursor, get_db_conn
import airflow
from airflow.contrib.hooks.redis_hook import RedisHook
from airflow.hooks.hive_hooks import HiveCliHook, HiveServer2Hook
from airflow.hooks.mysql_hook import MySqlHook
from airflow.operators.bash_operator import BashOperator
from airflow.operators.dagrun_operator import TriggerDagRunOperator
from airflow.operators.hive_operator import HiveOperator
from airflow.operators.hive_to_mysql import HiveToMySqlTransfer
from airflow.operators.impala_plugin import ImpalaOperator
from airflow.operators.python_operator import PythonOperator
from airflow.operators.mysql_operator import MySqlOperator
from airflow.sensors.external_task_sensor import ExternalTaskSensor
from airflow.sensors.hive_partition_sensor import HivePartitionSensor
from airflow.sensors.named_hive_partition_sensor import NamedHivePartitionSensor
from airflow.models import Variable
from plugins.OdsSchemaUpdate import OdsSchemaUpdate
from plugins.TaskTimeoutMonitor import TaskTimeoutMonitor
from plugins.TaskTouchzSuccess import TaskTouchzSuccess3.2 定义默认参数args
主要修改owner、日期、邮箱地址,另外此处还可以添加一些程序中需要使用的变量,其会与环境变量一起,在后续程序中可以直接使用。
args = {
'owner': 'zz.song',
'start_date': datetime(2023, 6, 1), # 脚本调度起始时间
# 'start_date': datetime(2023, 6, 1, 23),
'depends_on_past': False,
'retries': 3,
'retry_delay': timedelta(minutes=3),
'email': ['[email protected]'],
'email_on_failure': True,
'email_on_retry': False,
# 'end_date': datetime(2023, 7, 1), # 与start_date配合,可补跑指定范围的任务
# 'queue': 'bash_queue',
# 'pool': 'backfill',
# 'priority_weight': 40,
# 'provide_context': True,
# 'on_failure_callback': send_email_msg # 设置回调函数
# 'end_date': datetime(2016, 1, 1)
}3.3 定义DAG对象
dag = airflow.DAG(
'app_daily_tj', # dag_id,作为DAG的唯一标识符
schedule_interval = "30 05 * * *", # 每天5:30自动开始执行
# schedule_interval=timedelta(days=1),
default_args=args,
# catchup=False, # 为True会回填start_date至今的任务
# max_active_runs=2,
# concurrency=10,
)注意:dag_id 尽量与脚本名称保持一致!保证唯一性。
3.4 创建任务
任务Task 可分为“依赖检测任务”和“自定义执行任务”,具体参考“任务拆解”章节。
3.5 设置依赖关系
t2.set_upstream(t1)
t3.set_upstream(t1)
# 其他定义方式 (t2依赖t1)
t1.set_downstream(t2)
t1 >> t2
t2 << t1
# t3依赖t2, t2依赖t1,
t1 >> t2 >> t3
t1.set_downstream([t2, t3])
t1 >> [t2, t3]
[t2, t3] << t14. 任务分解
一个DAG图中,任务可以有多个。
4.1 依赖任务
主要是检测文件是否存在。
4.1.1 oss文件检测
from airflow.sensors import OssSensor
table_1_task = OssSensor(
task_id = 'table_1_task', # task_id:与依赖的命名对齐
bucket_key = '{hdfs_path_str}/dt={pt}/_SUCCESS'.format(
hdfs_path_str='oss://bd-datalake/bd_dw/table_1', # 可通过元数据信息查看表文件路径
pt='{{ds}}' # 自带环境变量
# pt='{{macros.ds_add(next_ds, -1)}}'
),
poke_interval=60, # 依赖不满足时,一分钟检查一次依赖状态
dag=dag
)4.1.2 obs文件检测
小时级分区表,execution_date 为环境变量
from airflow.providers.amazon.aws.sensors.s3 import S3KeySensor
t1 = S3KeySensor(
task_id='t1',
bucket_key='{hdfs_path_str}/dt={pt}/hour={h}/_SUCCESS'.format(
hdfs_path_str="obs://bd-datalake/table_1",
pt='{{execution_date.strftime("%Y-%m-%d")}}',
h='{{execution_date.strftime("%H")}}'
),
poke_interval=60, # 依赖不满足时,一分钟检查一次依赖状态
dag=dag
)4.1.3 检查hive表的分区是否存在
1. 元数据检测: hive_partition_sensor
通过连接hive元数据所在的mysql数据库,来检查hive表的分区是否存在,速度比较快。
from airflow.sensors.hive_partition_sensor.MetastorePartitionSensor
# 用于检查hive分区是否生成
check_hive_partition= MetastorePartitionSensor(
task_id='check_hive_artition_task',
mysql_conn_id='mysql-conn', # hive元数据库连接,可在web界面的Connection进行配置
schema='default', # 如果是default,那么table里要加上库名
table='db_name.table_name', # 需要检查的hive表名
partition="dt='{{ ds }}'", # 需要检测的分区
dag=dag
)2. 分区检测:hive_partition_sensor
from airflow.sensors.hive_partition_sensor import HivePartitionSensor
check_hive_partition= HivePartitionSensor(
task_id='check_hive_artition_task',
metastore_conn_id='hive-conn', # hive_metastore连接,可在web界面的Connection进行配置
schema='default', # 如果是default,那么table里要加上库名
table='库名.表名', # 需要检查的hive表名
poke_interval=300, # 两次检查的间隔时间,单位秒。建议该值不小于60。
partition="dt='{{ ds }}'", # 需要检测的分区
# partition="dt='{{ ds }}' and hour='{{ execution_date.strftime(\"%H\") }}'",
dag=dag
)注意:这类非默认op,需要指定conn_id。
4.2 自定义任务
4.2.1 bash任务
在实例化操作对象时生成任务,从运算符实例化的对象称为构造函数。
t1 = BashOperator(
task_id='print_date', # 任务的唯一标识符
bash_command='date',
dag=dag)
t2 = BashOperator(
task_id='sleep',
bash_command='sleep 5',
retries=3,
dag=dag)Airflow利用Jinja 模板的强大功能, 为管道作者提供一组内置参数和宏,还为管道作者提供了定义自己的参数,宏和模板的钩子。最常见的模板变量: {{ ds }} -- 今天的“日期戳”
templated_command = """
{% for i in range(5) %}
echo "{{ ds }}"
echo "{{ macros.ds_add(ds, 7)}}"
echo "{{ params.my_param }}"
{% endfor %}
"""
t3 = BashOperator(
task_id='templated',
bash_command=templated_command,
# bash_command='bash -x test.sh 110 {{ ds }}',
# bash_command='bash -x test.sh ', # 一定要留一个空格
# bash_command='sh /home/airflow/test.sh %s'%datetime.now().strftime("%Y-%m-%d"),
# bash_command='bash -x test.sh 110 {{ arg_params.yesterday }}', # 从arg字典取数
params={'my_param': 'Parameter I passed in'},
dag=dag)Jinja模板常见内置变量说明:
{{ data_interval_start }} 数据间隔的开始(pendulum.DateTime)
{{ data_interval_end }} 数据间隔结束 ( pendulum.DateTime )
{{ ds }} DAG 运行的逻辑日期(YYYY-MM-DD).
{{ ts }} 2018-01-01T00:00:00+00:00
{{ tomorrow_ds }} 2023-08-31
{{ yesterday_ds }} 2023-08-29
{{ execution_date }} DateTime(2023, 8, 30, 10, 0, 0, tzinfo=Timezone('UTC')))
{{ v_execution_time }}
{{ dag }}
{{ task }} 任务对象
{{ task_instance }} task_instance 对象
{{ macros }} 对宏包的引用
{{ params }} 对用户定义的 params 字典的引用
{{ conf }} airflow.configuration.conf代表您的内容的完整配置对象 airflow.cfg。 4.2.2 python任务
t5 = PythonOperator(
task_id='t5',
python_callable=fun,
provide_context=True,
op_kwargs={
'v_execution_time': '{{execution_date.strftime("%Y-%m-%d %H:%M:%S")}}'
},
# on_retry_callback=send_email_msg,
dag=dag
)
from plugins.CountriesAppFrame import CountriesAppFrame
def fun(ds, dag, **kwargs):
v_execution_time = kwargs.get('v_execution_time')
hive_hook = HiveCliHook()
args = [
{
"dag": dag,
"is_countries_online": "true",
"db_name": db_name,
"table_name": table_name,
"data_oss_path": hdfs_path,
"is_country_partition": "true",
"is_result_force_exist": "false",
"execute_time": v_execution_time,
"is_hour_task": "false",
"frame_type": "local",
"business_key": "bd"
}
]
cf = CountriesAppFrame(args)
_sql = "\n" + cf.alter_partition() + "\n" + temp_sql
hive_hook.run_cli(_sql)
cf.touchz_success() # 生产success以上与4.2.3 也是两种执行sql语句以及创建success文件的方式。
4.2.3 hive 任务
hive_table = "ods_xx_di"
# 任务1: 创建分区
app_partiton_task = HiveOperator(
task_id="add_partition_%s" % hive_table,
hql='''
alter table bd_ods.{table} add IF NOT EXISTS partition (dt='{pt}', hour='{dh}')
'''.format(table=hive_table,
pt='{{ds}}',
dh='{{execution_date.strftime("%H")}}',
# hql=open('xx.sql').read().format(pt='{{ ds }}', db='db_name', table='table_name') # 读取sql文件
# schema=hive_db,
dag=dag
)
# 任务2: 创建success文件
cmd = "hadoop fs -touchz obs://bd-datalake/ods_xx_di/"+"dt='{{ ds }}'"+"/_SUCCESS"
touch_success_task = BashOperator(
task_id='touch_success_%s' % str.lower(hive_table),
bash_command=cmd,
dag=dag
)
# 依赖
app_partiton_task >> touch_success_task4.2.4 SparkSql 任务
from pathlib import Path
from airflow.providers.apache.spark.operators.spark_sql import SparkSqlOperator
# 获取服务器sql代码文件地址
dag_var = Variable.get('var_global', deserialize_json=True) # 获取airflow web中Variable配置参数
sql_path = Path(dag_var['code_path']) / 'bd_script' / 'sql'
tt = SparkSqlOperator(
task_id='tt',
name = 'tt',
conn_id='spark_default',
master = 'yarn',
yarn_queue = 'root.bigdata',
num_executors = 8,
executor_cores = 2,
executor_memory = '4G',
sql=open('{}/xx_df.sql'.format(sql_path)).read().format(pt='{{ ds }}'),
# sql="select count(*) from table1 where dt='2023-03-01'"
dag=dag
)4.2.5 其他任务
SSHOperator、PostgresOperator
5. demo实战
5.1 一个简单demo
每天例行统计指定表中分区的数据量
5.1.1 编写任务脚本
# coding: utf-8
import logging
from datetime import datetime, timedelta
from utils.validate_metrics_utils import *
from impala.dbapi import connect
import airflow
from airflow.operators.python_operator import PythonOperator
from airflow.providers.amazon.aws.sensors.s3 import S3KeySensor
from airflow.hooks.base_hook import BaseHook
# --- 1. 定义默认参数 ---
args = {
'owner': 'zz.song',
'start_date': datetime(2023, 8, 28),
'depends_on_past': False,
'retries': 1,
'retry_delay': timedelta(minutes=5),
}
# --- 2. 定义DAG对象 ---
dag = airflow.DAG(
'count_xx_table_daily',
schedule_interval="20 02 * * *",
default_args=args
)
# --- 3. 定义任务 ---
# 3.1 任务1
t1 = S3KeySensor(
task_id='t1',
bucket_key='{hdfs_path_str}/country_code=NG/dt={pt}/_SUCCESS'.format(
hdfs_path_str="obs://db_name/table_name",
pt='{{ds}}'
),
bucket_name='bd-datalake',
poke_interval=60, # 依赖不满足时,一分钟检查一次依赖状态
dag=dag
)
# 3.2 任务2
t2 = PythonOperator(
task_id='t2',
python_callable=fun,
provide_context=True,
dag=dag
)
# --- 4. 设置依赖关系 ---
t1 >> t2具体执行的逻辑
def fun(ds, **kwargs): # ds 为调度传入当前时间
dt = datetime.strptime(ds + ' 00:00:00', '%Y-%m-%d %H:%M:%S')
# dt = kwargs.get('execution_date') # 环境变量
# dt = dt.strftime('%Y-%m-%d')
last_7_day = (dt + timedelta(days=-7)).strftime('%Y-%m-%d')
# 连接hive 客户端
conn = BaseHook.get_connection('hive_cli_default')
conn_hive = connect(host=conn.host,
port=conn.port,
timeout=3600,
auth_mechanism='PLAIN',
user=conn.login,
password=conn.password)
cursor = conn_hive.cursor()
cursor.execute('set mapreduce.job.queuename=root.bigdata')
cursor.execute('set hive.vectorized.execution.enabled=false')
sql = '''
select count(1)
from db_name.table_name
where dt='{dt}'
'''.format(dt=last_7_day)
logging.info('Executing: %s', sql)
cursor.execute(sql)
data = cursor.fetchall()
cursor.close()
logging.info(data)连接其他客户端
# 连接mysql客户端
def get_mysql_conn(conf_name='mysql_default'):
conn = BaseHook.get_connection(conf_name)
conn_mysql = MySQLdb.connect(host=conn.host, port=conn.port, db=conn.schema,
user=conn.login, passwd=conn.password,
charset='utf8mb4', use_unicode=True,
autocommit=True)
return conn_mysql
# 连接redis
def get_redis_connection(conf_name='redis'):
conn = BaseHook.get_connection(conf_name)
return StrictRedis(host=conn.host, port=conn.port)5.1.2 查看任务执行日志
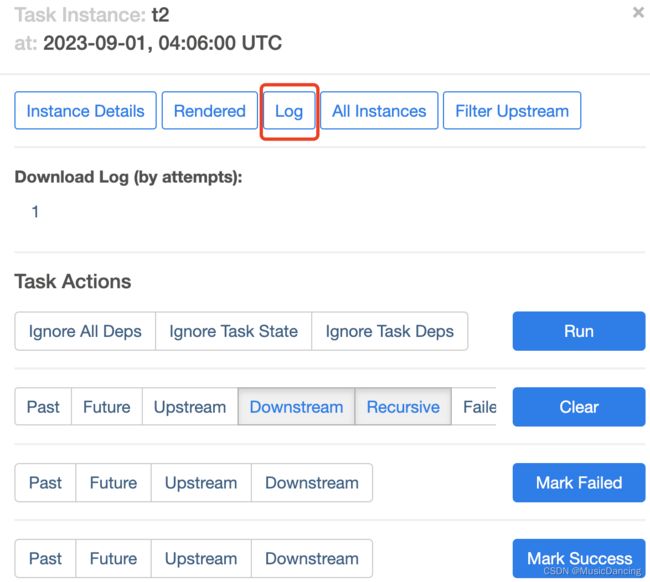
点击下图小方框,可以查看任务执行详情

查看日志
5.2 晋级Demo
批量任务执行
from airflow.operators.dummy import DummyOperator
dag_start = DummyOperator(task_id='dag_start', dag=dag)
dag_end = DummyOperator(task_id='dag_end', dag=dag)
dag_start >> [t1,t2, t3] >> t4 >> t5
dag_start >> [a1, a2] >> a3 >> a4 >> dag_end6. 任务超时监控
一般不作更改
def task_timeout_monitor(ds, dag, **kwargs):
msg = [{
"dag": dag,
"db": "db_name",
"table": "{dag_name}".format(dag_name=dag.dag_id),
"partition": "dt={pt}".format(pt=ds),
# "partition": "country_code=NG/dt={pt}".format(pt=ds)
"timeout": "600"
}]
TaskTimeoutMonitor().set_task_monitor(msg)
xx_task_timeout_monitor = PythonOperator(
task_id='task_timeout_monitor',
python_callable=task_timeout_monitor,
provide_context=True,
dag=dag
)7. 发送飞书报警消息
1. 在飞书中新建一个群(2人即可),加入机器人,并找到机器人的webhook地址;
找到此群 --> 设置 --> 群机器人 --> 添加机器人 --> 自定义机器人 --> 添加即可

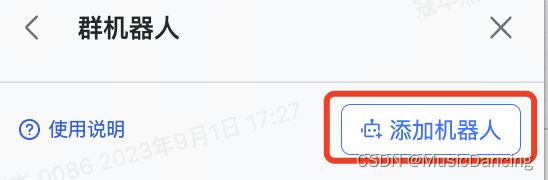

点击机器人头像,复制其 webhook 地址
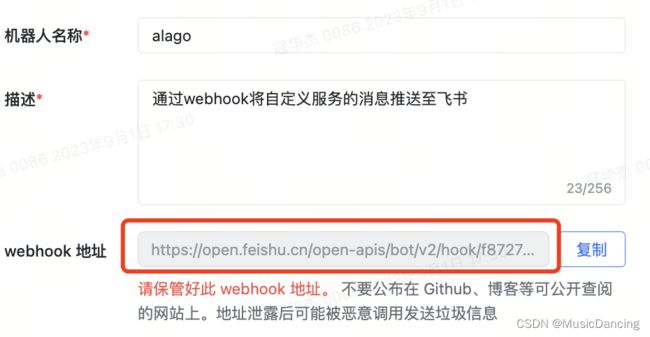
7.1 编辑发送消息函数
def send_feishu_markdown_warning(title, message):
_http_headers = {'content-type': 'application/json'}
_http_feishu_warning_url = 'https://open.feishu.cn/open-apis/bot/v2/hook/f8727e49-bd8e-40f1-8346-00d423d18288'
request_data = {
"msg_type": "interactive",
"card": {
"config": {"wide_screen_mode": True},
"header": {
"title": {
"content": title,
"tag": "plain_text"
}
},
"elements": [
{
"tag": "markdown",
"content": message + "\n" + "调用
def product_email(**kwargs):
dt = kwargs.get('execution_date') # 环境变量
t_day, t_hour = dt.strftime('%Y-%m-%d %H').split(" ")
msg_1 = 'hello'
msg_2 = '哈喽'
message = f"
日期:{str(t_day)+' '+str(t_hour)+':00:00'} \n 下一行" \
f"
{msg_1}" \
f"
{msg_2}"
send_feishu_markdown_warning('XX服务监控日报', message)7.2 使用封装函数
from plugins.QqMailAlert import send_feishu_markdown_warn
def send_lark_msg(context):
execution_date = context.get("execution_date").strftime("%Y-%m-%d")
dag_id = context.get("dag").dag_id
send_feishu_markdown_warn(session_title='数据校验',
warning_message=f"{execution_date} {dag_id} 已延迟产出,请尽快处理!",
token='c42e086d-0b38-4762-ab57-004c45e7d97a',
at_all=True)7.3 发邮件
from plugins.QqMailAlert import send_mail
def send_email_msg(context):
execution_date = context.get("execution_date").strftime("%Y-%m-%d")
dag_id = context.get("dag").dag_id
sender = '110'
password = '123321'
receiver = '[email protected]'
subject = f"失败警告!"
message = f"{execution_date} {dag_id} 已失败,请尽快处理!http://11.22.33.44:8080/tree?dag_id={dag_id}&root="
send_mail(sender, password, receiver, subject, message)7.4 电话报警
import requests
_http_headers = {'content-type': 'application/x-www-form-urlencoded'}
request_url = 'https://ops.bddev.com/api/alarm_channel/?aisle_type=TEL&username=devops&api_password=dL54CW&system=other&level=10&receive_obj=123,134&content=XX核心指标日报紧急报警,请及时关注!'
request_data = {"data": [
{"status": True, "code": "OK", "message": "OK", "request_id": "CF700C2E-4C34-5E76-BE2E-8462546F2CD5"}]}
response = requests.get(request_url, json=request_data, headers=_http_headers)
if response.status_code != 200:
print('告警电话拨打失败,http_code=%s,http_message=%s' % (response.status_code, response.reason))
else:
print('告警电话拨打成功')