Python 网络爬虫教程1
那么
前言:最近小编收到很多信息说是要学习Python 网络爬虫,那么今天它来了。
推荐诸位一本教孩子学习语言的书,很多家长看了都说管用!

另外再推荐几本程序猿必备的精品读物:《C语言:从看懂到看开》、《JAVA语言:从精通到陌生》、《NET语言:从放弃到坚持放弃》、《21天精通Dreamweaver:从安装到卸载》、《数据结构:从蒙圈到无限茫然》、《软件工程:从空白到空白》、《UNIX:还没入门就夺门而逃》……那么

那么正文开始:
IDE 选择
PyCharm
Sublime Text 2
VS2015
装python2还是python3
python目前有2个版本,python2和python3.
为啥现阶段还是学习python2.X,不学python3
基于以下理由:
python2.x还会流行多年。python社区需要很多年才能将现有的模块移植到支持python3. django web.py flask等还不支持python3掌握python2.x,过度到python3也很容易。现在找工作,大部分用python2.x.
Windows 平台
- 从 Download Python | Python.org 上安装Python 2.7.
您需要修改 PATH 环境变量,将Python的可执行程序及额外的脚本添加到系统路径中。将以下路径添加到 PATH 中:
C:\Python2.7\;C:\Python2.7\Scripts\;
- 从 Python for Windows Extensions download | SourceForge.net 安装 pywin32
请确认下载符合您系统的版本(win32或者amd64)
Linux Ubuntu 平台
- 安装Python
sudo apt-get install python-dev python-pip libxml2-dev libxslt1-dev zlib1g-dev libffi-dev libssl-dev
首先我们要学习爬虫的基本原理:
虫是 模拟用户在浏览器或者某个应用上的操作,把操作的过程、实现自动化的程序
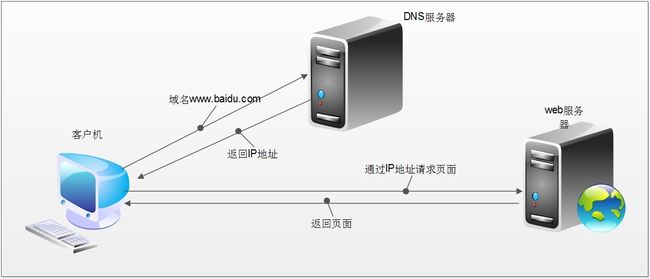
当我们在浏览器中输入一个url后回车,后台会发生什么?比如说你输入新浪网
简单来说这段过程发生了以下四个步骤:
-
查找域名对应的IP地址。
-
向IP对应的服务器发送请求。
-
服务器响应请求,发回网页内容。
-
浏览器解析网页内容。
网络爬虫本质
本质就是浏览器http请求
浏览器和网络爬虫是两种不同的网络客户端,都以相同的方式来获取网页:
网络爬虫要做的,简单来说,就是实现浏览器的功能。通过指定url,直接返回给用户所需要的数据,而不需要一步步人工去操纵浏览器获取。
浏览器是如何发送和接收这个数据呢?
HTTP简介
HTTP协议(HyperText Transfer Protocol,超文本传输协议)目的是为了提供一种发布和接收HTML(HyperText Markup Language)页面的方法。
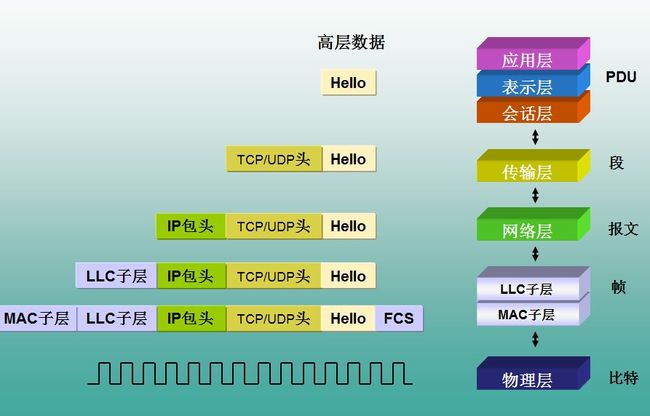
HTTP协议所在的协议层(了解)
HTTP是基于TCP协议之上的。在TCP/IP协议参考模型的各层对应的协议如下图,其中HTTP是应用层的协议。默认HTTP的端口号为80,HTTPS的端口号为443。

HTTP工作过程
一次HTTP操作称为一个事务,其工作整个过程如下:
1 ) 、地址解析,
如用客户端浏览器请求这个页面:http://localhost.com:8080/index.htm
从中分解出协议名、主机名、端口、对象路径等部分,对于我们的这个地址,解析得到的结果如下: 协议名:http 主机名:localhost.com 端口:8080 对象路径:/index.htm
在这一步,需要域名系统DNS解析域名localhost.com,得主机的IP地址。
2)、封装HTTP请求数据包
把以上部分结合本机自己的信息,封装成一个HTTP请求数据包
3)封装成TCP包,建立TCP连接(TCP的三次握手)
在HTTP工作开始之前,客户机(Web浏览器)首先要通过网络与服务器建立连接,该连接是通过TCP来完成的,该协议与IP协议共同构建Internet,即著名的TCP/IP协议族,因此Internet又被称作是TCP/IP网络。HTTP是比TCP更高层次的应用层协议,根据规则,只有低层协议建立之后才能,才能进行更层协议的连接,因此,首先要建立TCP连接,一般TCP连接的端口号是80。这里是8080端口
4)客户机发送请求命令
建立连接后,客户机发送一个请求给服务器,请求方式的格式为:统一资源标识符(URL)、协议版本号,后边是MIME信息包括请求修饰符、客户机信息和可内容。
5)服务器响应
服务器接到请求后,给予相应的响应信息,其格式为一个状态行,包括信息的协议版本号、一个成功或错误的代码,后边是MIME信息包括服务器信息、实体信息和可能的内容。
实体消息是服务器向浏览器发送头信息后,它会发送一个空白行来表示头信息的发送到此为结束,接着,它就以Content-Type应答头信息所描述的格式发送用户所请求的实际数据
6)服务器关闭TCP连接
一般情况下,一旦Web服务器向浏览器发送了请求数据,它就要关闭TCP连接,然后如果浏览器或者服务器在其头信息加入了这行代码
Connection:keep-alive
TCP连接在发送后将仍然保持打开状态,于是,浏览器可以继续通过相同的连接发送请求。保持连接节省了为每个请求建立新连接所需的时间,还节约了网络带宽。
HTTP协议栈数据流
HTTPS
HTTPS(全称:Hypertext Transfer Protocol over Secure Socket Layer),是以安全为目标的HTTP通道,简单讲是HTTP的安全版。即HTTP下加入SSL层,HTTPS的安全基础是SSL。其所用的端口号是443。
SSL:安全套接层,是netscape公司设计的主要用于web的安全传输协议。这种协议在WEB上获得了广泛的应用。通过证书认证来确保客户端和网站服务器之间的通信数据是加密安全的。
有两种基本的加解密算法类型:
1)对称加密(symmetrcic encryption):密钥只有一个,加密解密为同一个密码,且加解密速度快,典型的对称加密算法有DES、AES,RC5,3DES等;
对称加密主要问题是共享秘钥,除你的计算机(客户端)知道另外一台计算机(服务器)的私钥秘钥,否则无法对通信流进行加密解密。解决这个问题的方案非对称秘钥。
2)非对称加密:使用两个秘钥:公共秘钥和私有秘钥。私有秘钥由一方密码保存(一般是服务器保存),另一方任何人都可以获得公共秘钥。
这种密钥成对出现(且根据公钥无法推知私钥,根据私钥也无法推知公钥),加密解密使用不同密钥(公钥加密需要私钥解密,私钥加密需要公钥解密),相对对称加密速度较慢,典型的非对称加密算法有RSA、DSA等。
网络爬虫的基本工作流程如下:
-
首先选取一部分精心挑选的种子URL;
-
将这些URL放入待抓取URL队列;
-
从待抓取URL队列中取出待抓取在URL,解析DNS,并且得到主机的ip,并将URL对应的网页下载下来,存储进已下载网页库中。此外,将这些URL放进已抓取URL队列。
-
分析已抓取URL队列中的URL,分析其中的其他URL,并且将URL放入待抓取URL队列,从而进入下一个循环。
import requests #用来爬取网页
from bs4 import BeautifulSoup #用来解析网页
#我们的种子
seds = ["http://www.lagou.com/"]
sum = 0
#我们设定终止条件为:爬取到10000个页面时,就不玩了
while sum < 10000 :
if sum < len(seds):
r = requests.get(seds[sum])
sum = sum + 1
#提取结构化数据;做存储操作
do_save_action(r)
soup = BeautifulSoup(r.content)
urls = soup.find_all("href",.....) //解析网页所有的链接
for url in urls:
seds.append(url)
else:
break当然作为初学者我们,肯定会在Python上遇到很多问题,那么小编在这块给大家罗列几个大家都常遇到的问题。
-
如何判断需求数据在哪?
A) 静态数据,可通过查看网页源代码
B) 定位具体哪一个url请求,抓包,在Fidder里面找,怎么快速定位我要的数据呢?(通过Body大小,除了图片之外的Http请求)
-
判断是什么请求方式?Get还是Post
在Composer raw 模拟发送数据
A) 删除Header信息(为什么删除?代码简介美观、易于理解)
B) 如果做翻页,最好拿第二三页做测试,不要用首页(因为什么?有时候第二页是Post请求,而第一也是静态Get请求;并且拿第二页测试的时候返回的是第一页,容易错误还不自知)
-
参考案例Get、Post案例
写python程序
-
确认返回数据是什么格式的,返回json还是html
A) 那如果是json呢,格式化数据,应该做存储; B) 那如果是html呢,提取数据,使用XPath、CSS选择器、正则表达式
Get和Post
-
右键查看源代码和 F12 Elements区别 右键查看源代码:实质是一个Get请求 F12 Elements是整个页面 所有的请求url 加载完成的页面
-
GET 和Post区别的方法 为什么拉钩用的Post,不是表单提交密码,原因是Post用户体验更好;局部加载
案例1:抓取百度贴吧
采集 网络爬虫吧 的所有贴吧信息
百度贴吧
解决问题思路:
-
确认需求数据在哪
右键查看源代码
-
Fidder模拟发送数据
源码:
# -*- coding:utf-8 -*-
import urllib2
import urllib
from lxml import etree
import chardet
import json
import codecs
def GetTimeByArticle(url):
request = urllib2.Request(url)
response = urllib2.urlopen(request)
resHtml = response.read()
html = etree.HTML(resHtml)
time = html.xpath('//span[@class="tail-info"]')[1].text
print time
return time
def main():
output = codecs.open('tieba0812.json', 'w', encoding='utf-8')
for pn in range(0, 250, 50):
kw = u'网络爬虫'.encode('utf-8')
url = 'http://tieba.baidu.com/f?kw=' + urllib.quote(kw) + '&ie=utf-8&pn=' + str(pn)
print url
request = urllib2.Request(url)
response = urllib2.urlopen(request)
resHtml = response.read()
print resHtml
html_dom = etree.HTML(resHtml)
# print etree.tostring(html_dom)
html = html_dom
# site = html.xpath('//li[@data-field]')[0]
for site in html.xpath('//li[@data-field]'):
# print etree.tostring(site.xpath('.//a')[0])
title = site.xpath('.//a')[0].text
Article_url = site.xpath('.//a')[0].attrib['href']
reply_date = GetTimeByArticle('http://tieba.baidu.com' + Article_url)
jieshao = site.xpath('.//*[@class="threadlist_abs threadlist_abs_onlyline "]')[0].text.strip()
author = site.xpath('.//*[@class="frs-author-name j_user_card "]')[0].text.strip()
lastName = site.xpath('.//*[@class="frs-author-name j_user_card "]')[1].text.strip()
print title, jieshao, Article_url, author, lastName
item = {}
item['title'] = title
item['author'] = author
item['lastName'] = lastName
item['reply_date'] = reply_date
print item
line = json.dumps(item, ensure_ascii=False)
print line
print type(line)
output.write(line + "\n")
output.close()
print 'end'
if __name__ == '__main__':
main()那么今天的分享就到这了,下期见!