eclipse连接Hadoop并实现词频统计(大数据分析)
1、简介
Eclipse是一个集成开发环境(IDE),包含一个基工作区和定制环境的可扩展插件系统。大部分使用 Java 编写,Eclipse 可以用来开发应用程序。
通过各种插件,Eclipse 也可以用于其他编程语言开发应用程序:Ada、ABAP、C、C++、COBOL、 Fortran、Haskell、 JavaScript、Lasso、Natural、Perl、 PHP、 Prolog、 Python、Ruby、Scala、Clojure、 Groovy、Scheme 和 Erlang。它也可以用来开发Mathematica软件包。
开发环境包括 Eclipse Java 开发工具(JDT)支持 Java与Scala,Eclipse CDT C / C + +和Eclipse PDT PHP,等等。
eclipse-linux百度云下载链接,提取码(fm01)
2、解压安装eclipse
在home下创建文件夹eclipse—bag(这是我根据自己的习惯创建的,文件路径以及文件夹名根据自己的需求自行调整)
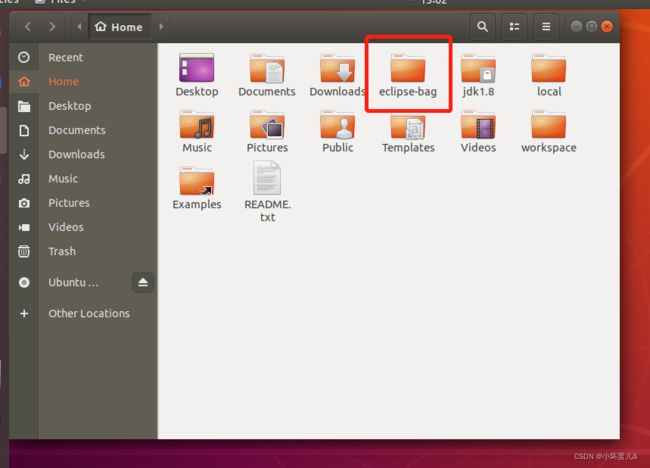
打开命令行,将桌面的压缩包移动到eclipse-bag文件夹下:
mv eclipse-jee-luna-SR2-linux-gtk-x86_64.tar /home/hadoop/eclipse-bag
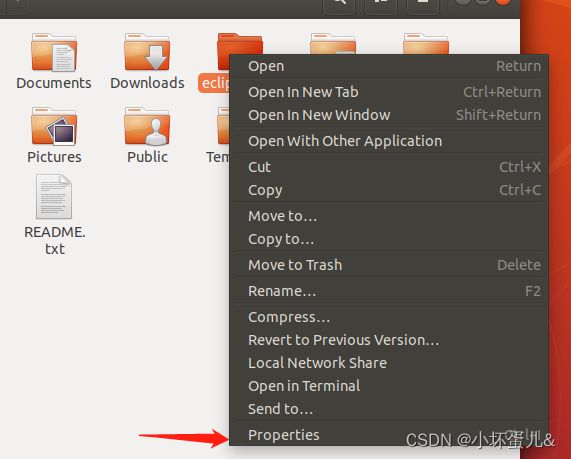
这里插入一下,当你不确定你的文件所属路径时,右键,点击Properties,即可查看文件所属路径
然后切换到该目录
cd /home/hadoop/eclipse-bag
将压缩包进行解压
tar -zxvf eclipse-jee-luna-SR2-linux-gtk-x86_64.tar
效果如下
为eclipse创建快捷方式并发送到桌面,方便以后打开
ln -s /eclipse-bag/eclipse/eclipse /home/hadoop/Desktop
效果如图:

3、安装Hadoop插件
Hadoop插件百度云下载链接,提取码(fm01)
直接将下载好的插件复制到eclipse,即/home/hadoop/exlipse-bag/eclipseplugins路径下,将插件拖入这个目录后打开eclipse,出现下图红框内文件夹即说明成功!
4、配置Hadoop
点击windows–>Preferences
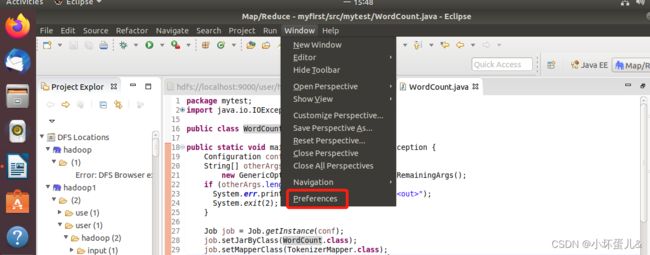
选择Hadoop的安装目录,点击右下角的Apply and Close关闭对话框
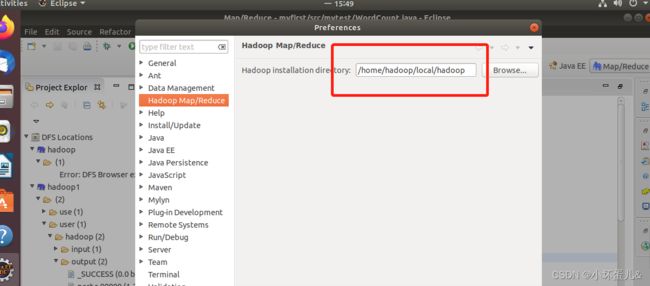
添加Map/Reduce视图,点击最上方的Window—>Perspective—>Open Perspective—>Other,
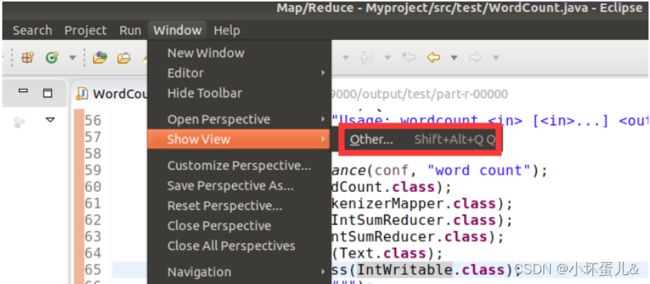
找到Map/Reduce后选择点击OK

此时页面底部效果如图:

5、连接Hadoop
右键选择New Hadoop location

这里边需要填写三个空,locatio name可以根据需求自行决定,左侧port端口是配置yarn的端口号,没有配置可以按照默认的;右侧port端口号是配置hadoop时coresite.xml文件中配置的端口号,一般应该9000.
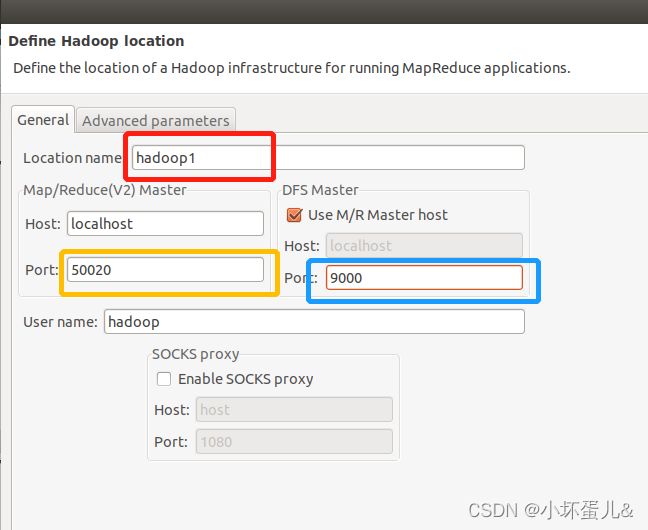
Host那里默认的应该是localhost,可以不改,当然这是在伪分布的前提下,如果不是伪分布的话就需要在Host中填写节点主机ip。
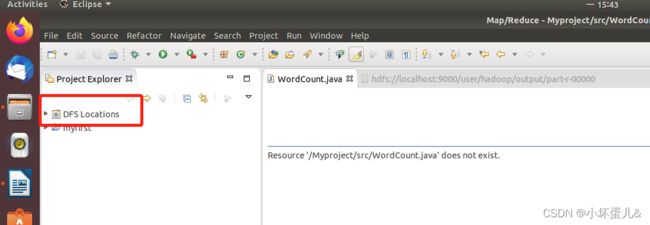
配置完成之后,可以在Eclipse的左侧视图中点开DFS Locations查看你的HDFS文件系统,以后可以直接在这里查看HDFS的文件,而不需要通过命令行进行控制
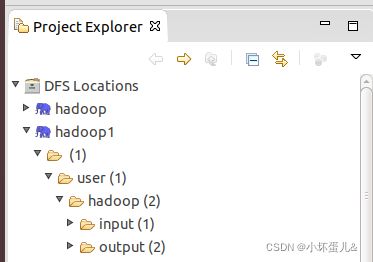
之后打开命令行,使用 HDFS,首先需要在 HDFS 中创建用户目录:
cd /home/hadoop/local/hadoop
./bin/hdfs dfs -mkdir -p /user/hadoop
创建用户目录之后,在目录下创建输入文件夹
./bin/hdfs dfs -mkdir input
接着将 我这里直接右键点击**upload files
to DFS…**上传了Hadoop安装目录下的README.txt文件作为输入文件复制到分布式文件系统中的input文件夹中

当然上述创建用户目录与input文件夹也可以直接通过右键创建文件夹实现
6、创建Map/Reduce项目
在File中new下选择Project,找到Map/Reduce Project点击Next
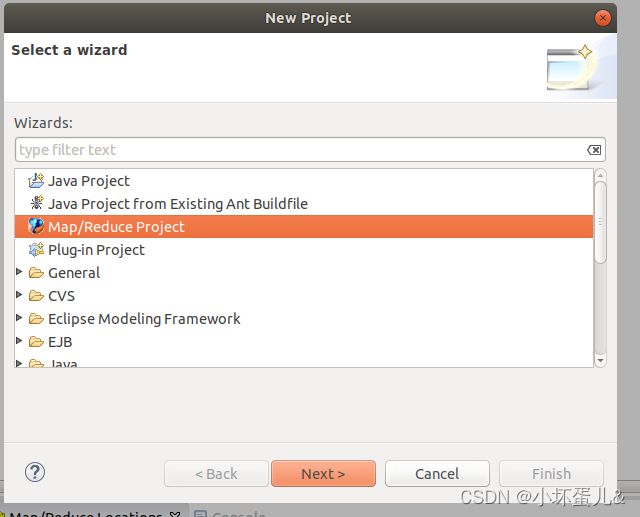
为项目名创建个名字,我这里用的是myfirst,之后点击Next就成功创建了一个Map/Reduce项目

7、运行WordCount实现词频统计
右键myfirst项目,依次点击new——>class,创建一个名为WordCount的文件

之后点击finish,将下列代码复制到其中,
package myfirst;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs =
new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println("Usage: wordcount " );
System.exit(2);
}
Job job = Job.getInstance(conf);
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
public static class TokenizerMapper extends
Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context)
throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer extends
Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
}
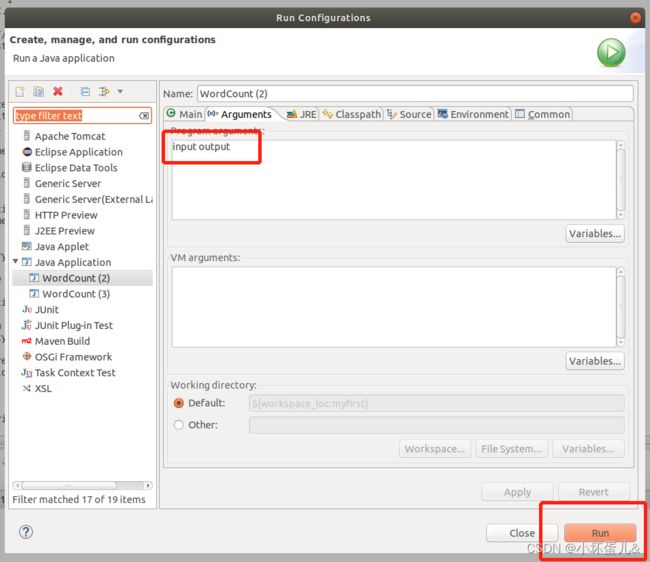
之后右键该java文件,依次选择Run as–>Run configurations…
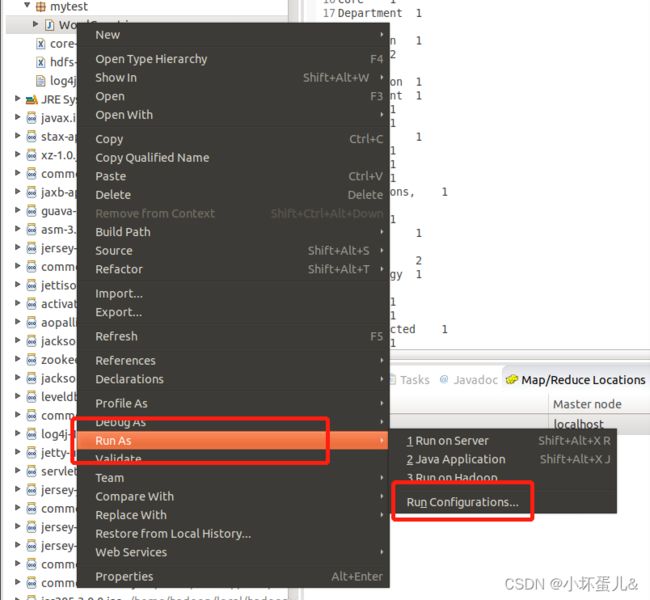
打开之后切换到Arguments那一栏,输入input output,其中
(input为DFS文件系统中hadoop下的input文件夹,output为结果输出的文件夹,output必须不存在,如果已经存在则删除,否则会出错)

之后点击右下角Run即可开始运行
运行过程

(9)查看运行结果
运行结束后,hadoop文件夹右键刷新,会出现一个output文件夹

双击output文件夹打开,点击par-r-00000文件,查看结果
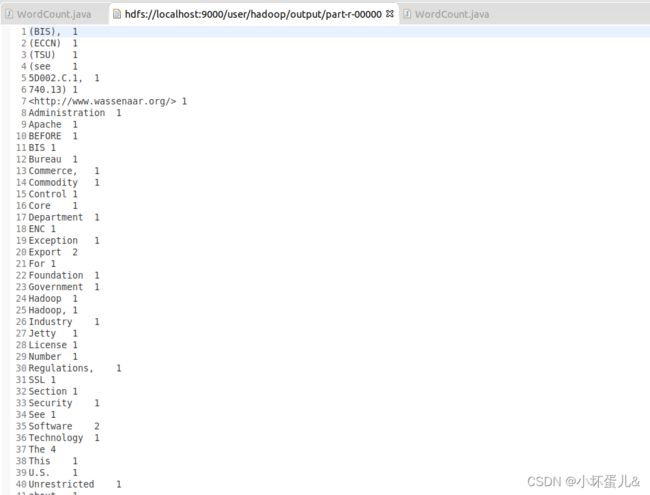
词频统计完成!