十篇最新经典多模态论文梳理
一些思考写在前面
-
训练任务有ITC(图像文本对比学习),ITM(图像文本匹配),MLM(Maked Language Modeling,有时会扩展到MIM),LM(Language Modeling,大部分可以看作是captioning)。然后选其中1到3个作为训练Loss,最后感觉选什么loss无太大所谓,比的还是谁的数据大,模型大...,谁大谁牛逼。不过当然了,能扩大规模最好还是精简一些loss的设计。
-
图像文本对数据量不够多,可以兼容单模态数据一起训练这样可以攒出很大的数据集,如BEIT-3。不过值得注意的是,BEIT-3放出来的时候引起了不小的关注,可是这时候GPT-4已经训练好了...,不知道GPT-4的项目组成员是如何笑话我们没见过大蛇拉屎的...
-
网络搜集的数据还是太脏,如Blip的做法用训练好的模型清洗一遍,可以涨不少点
-
个人感觉有LM loss更有前途,训练完之后直接可以用,而且还可以拿来refine数据集形成闭环
-
如Blip2 可以利用现成的LLM提高模型能力,但感觉还是个中间形态
-
直接用LLM来建模感觉更有前途,不过Kosmos-1的模型大小没做太大实际上还没Beit-3大,而GPT-4就是多模态的,而且22年8月份就训练完,而微软放出Kosmos-1已经是23年3月份的事了,openAI真牛逼,除了它大家都在玩泥沙
-
目前的论文方法不够牛逼可能还缺更大体量的模型、数据和Human Feedback的引入。
-
简单到没朋友的CLIP直接牛逼,说明vision-language pretrain就是需要海量的数据,数据不够方法上怎么建模可能都是白搭,目前发表论文的模型可能还处于“饥饿”状态。
CLIP
Title:Learning Transferable Visual Models From Natural Language Supervision
Paper:https://arxiv.org/pdf/2103.00020.pdf
机构:OpenAI
简单到没朋友,是一个让简单方法重新做牛逼、把VLP(vision-language Pretraining)直接引爆的工作!
贡献
-
从互联网中搜集了一波400M的图文对数据
-
用图-文对比学习去对齐图文embeddding,训练预训练模型
-
训完之后发现模型非常牛逼,甚至可以接做zero-shot learning
方法

如上图(1)所示,双塔结构,文本模态输入到text encoder,视觉模态输入到image encoder
训练的时候,输入一个batch的图-文对,batch内,每个图片和其他文本组成负样本;同理,每个文本也可以和其他图片组成正样本。
如上图(2)、(3)所示,训练完之后,可以很牛逼做zero-shot learning,把类别组成一句话:A photo of a [object],输入到Text encoder,得到embedding,输入一个测试图片到image encoder得到的视觉embedding和文本embedding算cosine相似度取最高的作为预测类别。
训练伪代码如下图所示:

zero-shot效果直接直接炸裂,引爆了整个AI圈,无论是图生文,还是文生图都常见clip的身影
FLIP
Title:Scaling Language-Image Pre-training via Masking
Paper:https://arxiv.org/pdf/2212.00794.pdf
机构:Meta
贡献
如下图所示,训练CLIP的时候,图像支路沿用MAE的MASK方案,丢掉大部分patches。

方法
注意这里的mask不是置0,而是跟MAE那样直接丢掉patches不参与计算,所丢掉多少就省多少计算量和显存!
这样的好处有两点:
-
加速。同样的时间内,训练更多的image-text pairs
-
更大batch。因为CLIP对比学习的loss是batch越大负样本越多,因此目标函数中能组成更多的负样本,预期会带来较大的gain。
FLIP应该会成为vision-language learning的一个通用trick,至少在工业界会被快速广泛尝试和推广。原因很简单,FLIP是CLIP训练速度的3.7倍,基于CLIP做一次实验的预算,可以支撑FLIP做3.7次实验。
ViLT
Title:ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision
Paper:https://arxiv.org/pdf/2102.03334.pdf
机构:NAVER AI Lab
贡献
名字全称:Vision-and-Language Transformer。顾名思义,不管三七二十一,直接把text tokens和image patches 怼到一块过 Transformer,非常大一统,如下图所示:

缺点
效果不是太好...
方法

输入
-
文本,直接输入Word Embedding,其中Word Embedding是bert-base-uncased tokenizer,而非用Bert进行映射。
-
图片,对图片分成多个patches,每个patch用共享参数的线性层映射成Embedding。
-
分别在文本token 序列和图像patch序列前插入一个Learnable 的 Embedding,作为[class] token。
-
灰色的Modal-type Embedding 用于标识模态类型,直接和对应的模态相加。
-
深绿色的Token position embedding 用于标识token在 句子中位置;同理,深紫色的Patch position embedding 用于标识token在 图像中位置。
最后,Word Embedding/Image Patch(插入了 class Embedding) 、Modal-type embedding、Position Embedding 直接加起来,作为模型输入。
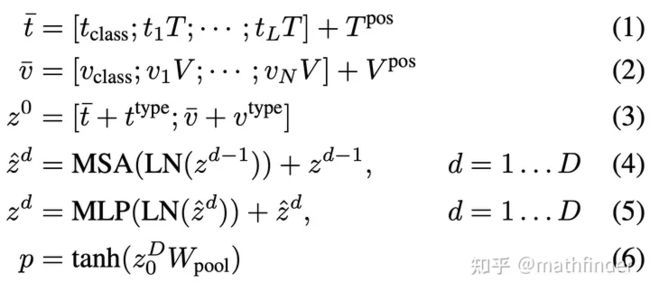
目标函数
2个loss:Image Text Matching、Masked Language Modeling
Image Text Matching
以0.5概率图像-文本是不对齐的,用模型中,第一个token(class token)对应的输出,过一个线性层来分类,图像-文本对是否对齐。
Masked Language Modeling
以0.15的概率随机mask文本token,被mask的token对应的transformer输出,用两层的MLP预测原始token是哪个。这里值得注意的是,文中用的是whole word masking,也就是说,mask的时候一个词对应的所有tokens都会被mask,比如,“giraffe”会被bert-base-uncased tokenizer分成3个tokens ["gi", "##raf", "##fe"],要mask的话,这三个tokens要被同时mask。
ALBEF
Title:Align before Fuse: Vision and Language Representation Learning with Momentum Distillation
Paper:https://arxiv.org/pdf/2107.07651.pdf
机构:Salesforce Research
贡献
-
Align Before fuse:用对比学习把图像、文本数据的embedidng对齐,然后把图像、文本embedding融合起来做其他任务(ITM和MLM),凑齐VLP三板斧同时训练
-
用Momentum distillation来克服noisy data,即用momentum Network来生成伪标签,作用在ITC和MLM上,甚至在下游任务上。
缺点
缺点很明显,做N多个任务,多个网络,一次迭代要前传很多次。
方法

如上图所示,有三个模块:image encoder,text encoder,和multimodal encoder,都用transformer建模,其中multimodal encoder每层多个cross attention来融合不同模态的信息。
这里注意到multimodal encoder和text encoder其实参数量分别只有image encoder的一半,即它是一个12层的transformer劈开两半。
训练loss三板斧:
ITC (Image-Text Contrastive Learning),image encoder和text encoder分别对应的cls token的输出过个现行层,做对比学习。
这里跟CLIP有些区别,该方法会用类似MoCo的方法用momentum networks 维护memory bank来用历史样本充当负样本:具体维护,image encoder和text encoder 各维护一个 momentum network,然后
online image encoder 和 momentum text encoder做对比学习 online text encoder 和 momentum image encoder做对比学习
MLM(Masked Language Modeling),随机mask15%的文本tokens,然后预测之。
ITM(Image-Text Matching),输入image encoder和text encdoer各个token的输出。其中,视觉的tokens输入到每一层的cross attention,文本的tokens从底部输入 。最后文本的cls token的输出过个线性层预测文图是否匹配。
ITM的正样本的ITC里的正样本,负样本则从ITC中选择最难的负样本。
MoD (Momentum Distillation)
动机:数据来源于网络噪声很大,类似mean teacher的方式,用momentum network来制作伪标签蒸馏。
作用模块:ITC和MLM
ITC:原来是online image encoder 和 momentum text encoder,计算相似度,用cross entorpy训练;
这回,两边都用momentum的encoder计算相似度,然后用KL散度拉近两个的相似度分布(softmax后的相似度向量),和原来的itc loss 加权组合起来:
![]()
其中,红框部分为新增的蒸馏loss。
MLM:很简单,用momentum network,MLM预测的结果作为soft-label,用KL散度逼近之:
![]()
其中,红框部分为新增的蒸馏loss。
BLIP
Title:BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation
Paper:https://arxiv.org/pdf/2201.12086.pdf
机构:Salesforce Research
贡献
-
也是三板斧训练目标函数,不过把MLM换成LM:ITC(图像文本对比学习)、ITM(图像文本匹配)、LM(语言模型)
-
利用训练好的LM生成伪标签、训练好的ITM清洗数据,然后再训一轮,如下图所示

训练方法

训练方法其实很常规,如上图所示
ITC:和clip一毛一样,训练image encoder和text encoder
ITM:从ITC里面选最难(最像)的负样本,进入ITM,也就是说正负样本比是1:1;ITM里面输入文本token,以及在cross attention里面注入视觉embedding。训练image encoder和image-grounded text encdoer
LM:自回归,预测下一个词。
训练image encoder和image-grounded text decdoer
CapFilt
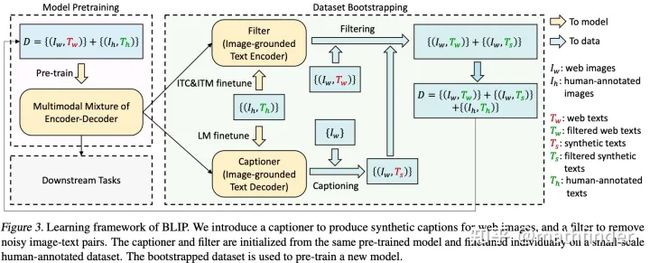
流程如上图所示,
-
用互联网数据+人工标注数据训练了一版pretrain model
-
再用人工标注数据(COCO)finetune一版model
-
用fintune好的image-ground text decoder,过一下互联网数据 生成caption
-
用fintune好的image-ground text encoder,过一下互联网数据,过滤caption,这里caption包括生成的也包括原来数据集的,剩下的caption作为新数据标注。
-
进入下一轮pretrain。
BLIP2
Paper:https://arxiv.org/pdf/2301.12597.pdf
机构:Salesforce Research
贡献
给定一个视觉模态的单模态模型,一个文本模态的大规模语言模型(LLM),训练两者之间的起桥梁作用的模块(Q-former)。训练captioning任务,训练的冻住视觉模型和语言模型,只训其中的Q-former。
这个操作也很好理解:图-文Pair的数据少,但是单模态的数据多,分别训练两个牛逼的单模态模型,然后只用少量参数连着两者,防止训VLP的时候灾难性遗忘。
方法
两阶段训练:可以简单理解为第一级阶段在训练BLIP,只是冻住了图像encoder; 第二阶段再接个LLM,用LLM来引导finetune可训练的网络(Q-Former)
模型结构:如首图所示,整个方法纯纯地就训练一个Q-Former,Q-Former的结构如下图所示,包含两个transformer,两个transformer 共享 Self-Attention层 (这一点跟VLMO差不多非常神奇,不知道学界有什么解释):
-
图像的transformer: 输入图像encoder的特征和多个learnable的query embeddings,图像encoder的特征只在cross attention模块中输入,和query embeddings对应的隐特征交互
-
文本的transformer: 既可以当做文本encoder也可以是decoder
第一阶段训练:Vision-Language Representation Learning from a Frozen Image Encoder
训练任务还是BLIP那三板斧:ITC、ITM、Captioning,只训练Q-Former,不动Encoder。然后通过对self-Attention模块不同的mask方式,来做不欧通的任务。
-
ITC(Image-text Contrastive Learning):图像的transformer会输出queries那么多个embedding;文本transformer 输入cls token和文本tokens,然后[CLS] token的输出embedding和queries对应的embedding计算相似分数,取最高的作为相似度。这里注意,self-attention时,query和文本token是不交互的!
-
ITM(Image-Text Matching):self-attention时,query和文本token是互相交互的。对每个qeury 的输出embedidngs接一个二分类的线性分类器,分图文是否匹配,所有query的分类结果取平均作为最终分类结果。
-
ITG(Image-grounded Text Generation):query tokens只跟query tokens交互,文本tokens只跟前面的文本tokens和query tokens交互。生成文本的起始标识token用[DEC]token。

第二阶段训练:
第一阶段训练的到 Q-Former的 query token的输出 过一层FC,输入到LLM里面用自回归训练。
这里分两种LLM,用不同的方式训练:
-
如果是decoder-only的LLM,就在LLM里面只输入query tokens的embedding
-
如果是encoder-decoder的LLM,就在encoder里面输入query tokens的embedding和文本的前缀,预测文本后缀。
CoCa
Title:CoCa: Contrastive Captioners are Image-Text Foundation Models
Paper:https://arxiv.org/pdf/2205.01917.pdf
机构:Google
贡献
对比学习+captioning
方法
同样简单到没朋友,看图

Dual-Encoder Contrastive Learning:跟 CLIP一毛一样
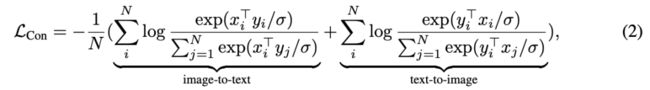
Encoder-Decoder Captioning:

因为方法简单,作者把模型做得很大:
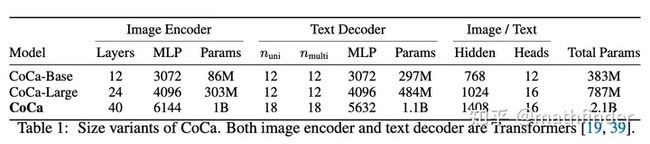
效果直接就牛逼,主要还是因为数据大(数据包含只有Google自家可以用的JFT-3B),模型大(模型直接干到2.1B参数量)...,名场面:

VLMO
Title:VLMO: Unified Vision-Language Pre-Training with Mixture-of-Modality-Experts
Paper:https://arxiv.org/pdf/2111.02358.pdf
机构:微软
贡献
提出了一个能够优雅兼容多模态的Transformer,然后先在大量的单模态数据上训练,再在相对小量的多模态数据上训练。

方法
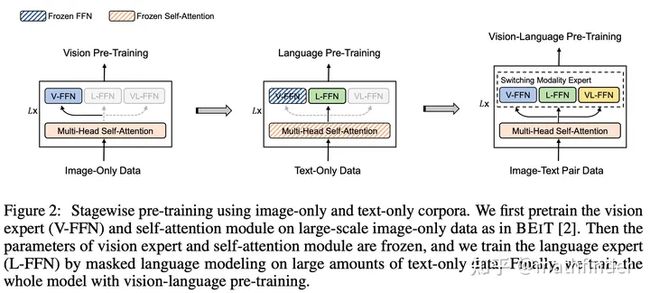
很简单,就是魔改transformer layer,self-attention部分不动;FFN部分分成三:V-FFN,L-FFN,VL-FFN,顾名思义,V-FFN处理视觉模态,L-FFN处理文本模态,VL-FFN处理多模态。
训练步骤如下图:
-
首先,在视觉数据上用MIM(masked image model)任务训练模型,这时候网络跟ViT差不多,FFN只用V-FFN
-
然后,训完之后冻住self-attention layer和V-FFN,在文本数据上用MLM(maked language model)任务训练模型,注意这里有个假设非常神奇,视觉模态上训练好的self-attention layer是可以复用到文本模态的,这里很神奇,不知道有没有懂王解释一下...
-
最后,在图文数据上,VLMO的前几层,用V-FFN和L-FFN分别处理视觉文本数据(也就是说前面的层self-attention图文不交互);最后两层用VL-FFN,这时候self-attention是图文交互的;训练loss三板斧:ITC(Image-Text Contrast),ITM(Image-Text Matching)和 MLM(Masked Language Modeling)
BEiT-V3
Title:Image as a Foreign Language: BEIT Pretraining for All Vision and Vision-Language Tasks
Paper:https://arxiv.org/pdf/2208.10442.pdf
机构:微软
贡献
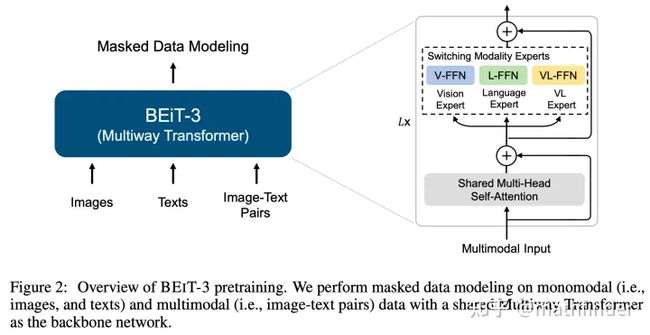
其实就是把VLMO做大做强:backbone用VLMO里提出的Multiway Transformer,训练目标大道至简,只有Masked Data Modeling,没有对比学习了。
方法
在单模态(图片或文本)和多模态数(图像-文本对)据上训练 Maked Data modeling。
-
对于 文本模态,mask 15%的tokens
-
对于 视觉模态,mask 40%的tokens
-
对于 图像-文本对,mask 50%的文本tokens
因为只有一个训练目标,所以不用像前面的工作那样,么个batch要前传n多次,非常高效,因此也很方便扩展训练规模。不用对比学习,因此也不需要很大的batch!
训练细节:
-
backbone:40层的Multiway transfomer,1408的hidden dim,6144的FFN中间层dim,16个attention heads;前面37层用V-expert FFN和L-expert FFN,最后三层用VL-expert FFN。统共参数量是1.9B。
-
训练1M步,每一步batchsize是6144,包含2048个单图,2048个单文本,2048个图文对。
Kosmos-1
Title:Language Is Not All You Need: Aligning Perception with Language Models
Paper:https://arxiv.org/pdf/2302.14045.pdf
机构:微软
贡献

做了一个多模态的LLM。
方法
输入
把所有模态的输入都展平成序列输入到Transformer Decoder中。用表示序列的开始和结束。例如
text
是文本输入;
textImage Embedding text
是插入了图像的文本的输入。
具体case 如下图所示:

模态表示:对于文本token,就用lookup table把token映射成embedding;对于图像模态就用一个训练好的clip,抽取图像特征,用attentive pooling来减少图片的embedding个数。
网络设计
Backbone用MAGNETO(一个大规模Transformer),用xPos这类相对位置编码来建模长文本的上下文信息。
训练目标
自回归:模型训练预测下一个token,值得注意的是只有文本token会计算loss,预测视觉的token是不计算loss。
模型训练细节
数据
-
Text Corpora: Pile, Common Crawl (CC), Common Crawl snapshots (2020-50 and 2021-04) datasets, CC-Stories, and RealNews。排除了GitHub, arXiv, Stack Exchange和 PubMed Central的数据来源。
-
Image-Caption Pairs:English LAION-2B, LAION-400M, COYO-700M, Conceptual Captions
-
Interleaved Image-Text Data:从Common Crawl snapshot里爬网页,从2B的网页里面筛选剩下71M。筛选主要是限制图片数量。
训练配置
文中训练连MLLM(多模态LLM)是个24层,隐层2048维,FFN中间特征大小8192维,32个attention heads的包含1.3B参数的模型。
每个batch包含1.2M个tokens,其中,0.5M来自 Text Corpora,0.5M来自Image-Caption Pairs,0.2来自Interleaved Image-Text Data。
Language-Only Instruction Tuning
用格式为(instructions, inputs, outputs) 的instruction数据继续训练模型,这里数据是Language-only的。这里训练的时候,predict instructions和inputs的时候是不计算loss的,只有outputs计算loss。