Python大数据之Python爬虫学习总结——day13 正则表达式
正则表达式
-
- 1.web服务器
- 2.体验爬虫
- 3.正则表达式_匹配
-
- 知识点:
- match匹配:
- search匹配:
- findall匹配:
- 4.匹配模式练习
-
- 需求:
- 方式一:
- 方式2:
- 5.正则表达式_模式
-
- 知识点:
- 示例:
- 6.正则表达式综合练习
- 7.贪婪模式和非贪婪模式
-
- 示例:
- 8.正则表达式标志位
-
- 知识点:
1.web服务器
web服务器给浏览器响应的是是一个Response对象,这个对象中content就是咱们给浏览器响应的资源
# 实战需求: 现有的服务器代码,重复代码多,不利于以后扩展,需要升级优化
# 1.导包
from fastapi import FastAPI
from fastapi import Response
import uvicorn
# 2.创建对象
zs = FastAPI()
# 3.对象帮助咱们接收浏览器请求,并且给浏览器响应
# 浏览器输入url: 协议/域名:端口号/资源路径
# 注意: get后面就是url里的资源路径
# 接收的url请求: http://192.168.86.41:9091/
#
@zs.get('/')
def show():
# with open任何情况下,文件都会自动关闭
with open('source/html/index.html', mode='r', encoding='utf8') as f:
data = f.read()
return Response(content=data)
# 自动接收用户在浏览器输入的url,然后自动截取文件名赋值给html_name
# 接收的url请求: http://192.168.86.41:9091/页面或者其他资源
@zs.get('/{html_name}')
def show(html_name):
with open(f'source/html/{html_name}', 'rb') as f:
data = f.read()
return Response(content=data)
# 自动接收用户在浏览器输入的url,然后自动截取图片名赋值给img_name
# 接收的url请求: http://192.168.86.41:9091/images/图片
@zs.get('/images/{img_name}')
def show(img_name):
with open(f'source/images/{img_name}', 'rb') as f:
data = f.read()
return Response(data)
# 自动接收用户在浏览器输入的url,然后自动截取图片名赋值给vi_name
# 接收的url请求: http://192.168.86.41:9091/video/视频
@zs.get('/video/{vi_name}')
def show(vi_name):
with open(f'source/video/{vi_name}', 'rb') as f:
data = f.read()
return Response(content=data)
# 4.启动服务器
uvicorn.run(zs, host='192.168.86.44', port=9091)
2.体验爬虫
爬虫本质:模仿人去浏览器发送请求,并且获取Response对象,根据content从对象中提取资源
# 1.准备有效的URL地址
URL = 'https://www.baidu.com/'
# 2.requests模块发送请求
import requests
res = requests.get(URL)
# 打印响应对象测试是否成功
print(res) # 3.正则表达式_匹配
知识点:
正则表达式:(regular expression)描述了一种字符串匹配的模式,可以用来检查一个大字符串中是否含有某种子串、将匹配的子串做替换或者从某个串中取出符合某个条件的子串等
模式:一种特定的字符串模式,这个模式是通过一些特殊的符号组成的
正则表达式:
1.正则表达式的语法很令人头秃,可读性差
2.正则表达式通用性很强,能够适用于很多编程语言
python中正则表达式模块:re
正则表达匹配方式:
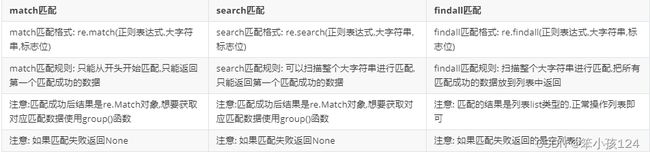
match匹配:
# 1.导包
import re
# 2.匹配
big_str = '传智传智教育集团黑马程序员品牌'
result = re.match('传智', big_str)
# 3.结果
print(result, type(result)) # <...> search匹配:
# 1.导包
import re
# 2.匹配
big_str = "
![]() "
result = re.search('src', big_str)
# 3.结果
print(result,type(result)) # <...>
"
result = re.search('src', big_str)
# 3.结果
print(result,type(result)) # <...> findall匹配:
# 1.导包
import re
# 2.匹配
big_str = "![]() "
result = re.findall('
"
result = re.findall('![]() , big_str)
# 3.结果
print(result, type(result)) # ['
, big_str)
# 3.结果
print(result, type(result)) # ['![]() # 非空即为True
if result:
print(f"匹配成功:{result}")
else:
print('匹配失败!!!')
# 非空即为True
if result:
print(f"匹配成功:{result}")
else:
print('匹配失败!!!')
4.匹配模式练习
需求:
已知页面部分源码,其中包含了很多图片标签,要求扫描整个字符串,提取每个图片的路径
方式一:
# 准备大字符串
html_str = """
惊爆 亚洲舞王卫冕成功



两少年人穷志不短 仅着内裤环游世界



"""
# 1.导包
import re
# 2.匹配
# \d: 任意1个数字
result = re.findall(' , html_str)
# 3.结果
print(result)
# 4.获取所有的图片路径
# 遍历列表
for i in result:
print(i[10:-1])
, html_str)
# 3.结果
print(result)
# 4.获取所有的图片路径
# 遍历列表
for i in result:
print(i[10:-1])
方式2:
# 需求: 已知页面中多个图片,要求匹配出所有的图片路径
html_str = """
惊爆 亚洲舞王卫冕成功
两少年人穷志不短 仅着内裤环游世界
"""
# 1.导包
import re
# 2.匹配
"""
.: 任意1个字符
*: 0个或者多个
+: 1个或者多个
?: 0个或者1个
.*或者.+: 默认贪婪模式
.*?或者.+?: 非贪婪模式
"""
# findall有一个特点: 正则表达式中如果使用小括号,自动只获取小括号内数据,放到列表中
result = re.findall(') , html_str)
# 3.结果
print(result)
# 4.获取所有的图片路径
for i in result:
print(i)
, html_str)
# 3.结果
print(result)
# 4.获取所有的图片路径
for i in result:
print(i)
5.正则表达式_模式
知识点:
单独匹配1个字符:
. : 任意1个字符(除了\n)
[] : 中括号里任意1个字符
[^x]: 如果^在中括号里,代表除了后面的x字符,其他任意1个字符
\d : 任意1个数字
\D : 任意1个非数字
\w : 任意1个正常字符(字母数字下划线汉字)
\W : 任意1个非正常字符(特殊字符)
\s : 任意1个空白(空格,制表符\t,换行符\n)
\S : 任意1个非空白
匹配前一个字符出现次数
* : 匹配前一个字符出现0次或者多次
+ : 匹配前一个字符出现1次或者多次
? : 匹配前一个字符出现0次或者1次
{x} : 匹配前一个字符出现x次
{x,}: 匹配前一个字符至少出现x次
{x,y}: 匹配前一个字符至少x次,最多y次
匹配开头和结尾:
^ : 匹配字符串以...开头
$ : 匹配字符串以...结尾
匹配分组操作:
(xy): 匹配分组,xy内容成为一组数据,自动生成一个从1开始的编号
(x|y): 匹配分组,x或者y是分组数据
示例:
# 导包
import re
# 定义函数用于判断结果
def show(result):
if result:
print(f"匹配成功:{result.group()}")
else:
print('匹配失败!!!')
# . : 任意一个字符,除了\n
result = re.match('.inzi.66.帅.', 'binzi666_帅气')
show(result)
# [] : 中括号中任意一个字符
result = re.match('[a-zA-Z0-9_]', 'binzi666_帅气')
show(result)
# [^x] : 如果^在中括号中,代表除了x外其他所有字符
result = re.match('[^b]', 'Binzi666_帅气')
show(result)
# ^: 不在中括号里,代表以...开头 $: 以...结尾
result = re.match('^binzi666_帅气$', 'binzi666_帅气')
show(result)
# * : 不能单独用,一般放到某个字符后,代表这个字符出现0次或者多次 次数>=0
result = re.match('[a-zA-Z0-9_]*', 'binzi666_帅气')
show(result)
# + : 不能单独用,一般放到某个字符后,代表这个字符出现1次或者多次 次数>=1
result = re.match('[a-zA-Z0-9_]+', 'binzi666_帅气')
show(result)
# ? : 不能单独用,一般放到某个字符后,代表这个字符出现0次或者1次 次数=0或者1
# 需求 : 匹配协议部分
result = re.match('https?://', 'https://www.baidu.com/')
show(result)
# 注意: ^和$一般配合使用,起到限制作用
# {x} : 不能单独用,一般放到某个字符后,代表这个字符出现x次
result = re.match('^[a-zA-Z0-9_]{8}$', 'binzi666')
show(result)
# {x,} : 不能单独用,一般放到某个字符后,代表这个字符 至少 出现x次
result = re.match('[a-zA-Z0-9_]{6,}', 'binzi666888')
show(result)
# {x,y} : 不能单独用,一般放到某个字符后,代表这个字符出现x到y次
result = re.match('^[a-zA-Z0-9_]{6,10}$', 'binzi66688')
show(result)
# \d: 任意1个数字
result = re.match('binzi\d{3}_帅气', 'binzi666_帅气')
show(result)
# \D: 任意1个非数字
result = re.match('\Dinzi666\D帅\D', 'binzi666_帅气')
show(result)
# \w: 任意1个正常字符(字母,数字,下划线,汉字)
result = re.match('\winzi\w66\w帅\w', 'binzi666_帅气')
show(result)
# \W: 任意1个非正常字符(特殊字符)
result = re.match('binzi666\W帅气', 'binzi666%帅气')
show(result)
# \s: 任意1个空白(空格,\t制表符,\n换行符)
result = re.match('binzi666\s帅气', 'binzi666 帅气')
show(result)
# \S: 任意1个非空白
result = re.match('\Sinzi\S66 帅\S', 'binzi666 帅气')
show(result)
6.正则表达式综合练习
# 1.导包
import re
# 提前定义函数用于展示结果
def show(result):
if result:
print(f'匹配成功:{result.group()}')
else:
print('匹配失败!!!')
# 2.匹配
# 需求1: 匹配微博话题
str1 = '#幸福是奋斗出来的#'
result = re.match('#.+#', str1)
show(result)
# 需求2: 匹配1开头的11位手机号
str2 = '13866668888'
result = re.match('^1[3-9]\d{9}$', str2)
show(result)
# 需求3: 匹配163邮箱地址 要求@符号前4到10位的字母数字或者下划线
str3 = '[email protected]'
# \转义符: \.此处.只代表符号原始含义
result = re.match('^[a-zA-Z0-9_]{4,10}@163\.com$', str3)
show(result)
# 补充正则表达式匹配分组
result = re.match('^([a-zA-Z0-9_]{4,10})@(163\.com)$', str3)
# 注意: 0代表匹配到的所有数据,可以省略不写
print(result.group(0))
print(result.group())
# 注意: 上述小括号()代表一个分组,每个分组自动生成了对应的编号(从1开始)
# 获取第1个分组内容
print(result.group(1))
# 获取第2个分组内容
print(result.group(2))
# 注意: 访问不存在的分组就会报错
# print(result.group(3))
# 需求4: 在上述匹配邮箱案例中,优化下既能匹配163邮箱,也能匹配qq邮箱,google邮箱,sina邮箱
str4 = '[email protected]'
result = re.match('^[a-zA-Z0-9_]{4,10}@(163|qq|google|sina)\.com$', str4)
show(result)
7.贪婪模式和非贪婪模式
示例:
# 1.导包
import re
# 需求: 已知以下字符串,采用两种模式匹配内容,观察结果
html_str = ''
# 贪婪模式: .* 或者 .+
data = re.findall('', html_str)
print(data) # 不是咱们想要的结果
# 非贪婪模式: .*? 或者 .+?
data = re.findall('', html_str)
print(data)
8.正则表达式标志位
知识点:
re.I :忽略大小写比较
re.S : 让.匹配到\n,实现真正的任意
示例:
"""
re.I: 忽略大小写比较
re.S: 让.能够匹配到\n
"""
#导包
import re
# 提前定义函数用于展示结果
def show(result):
if result:
print(f'匹配成功:{result.group()}')
else:
print('匹配失败!!!')
# 案例1: 验证码忽略大小写比较
yzm = 'A2cD'
result = re.match('a2cd', yzm, re.I)
show(result)
# 案例2: .匹配\n
name = '传智\n黑马'
# 注意: .默认不能匹配\n
result = re.match('.*', name)
show(result)
# 注意: re.S: 让.能够匹配到\n
result = re.match('.*', name, re.S)
show(result)