力扣刷题
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
H指数
- 题目介绍
- 一、实现思路
-
-
- 方法一:排序
-
-
- 分析
- 复杂度分析
-
- 方法二:计数
-
-
- 分析
- 算法
- 复杂度分析
-
-
- 二、使用算法
-
- 1.python实现
- 2.C++实现
- 3.java实现
- 总结
地址:https://leetcode-cn.com/problems/h-index-ii/
开发语言:python或C++
题目:H 指数
难度: 中等
题目介绍
序号:274. H 指数
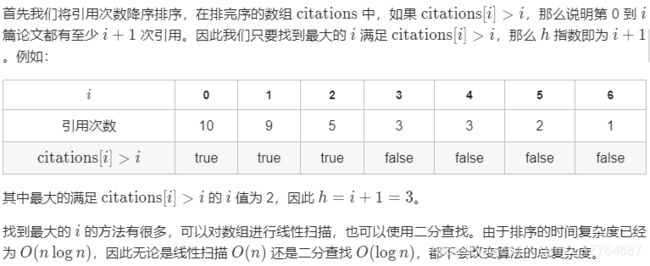
给定一位研究者论文被引用次数的数组(被引用次数是非负整数)。编写一个方法,计算出研究者的 h 指数。
h 指数的定义:h 代表“高引用次数”(high citations),一名科研人员的 h 指数是指他(她)的 (N 篇论文中)总共有 h 篇论文分别被引用了至少 h 次。(其余的 N - h 篇论文每篇被引用次数 不超过 h 次。)
例如:某人的 h 指数是 20,这表示他已发表的论文中,每篇被引用了至少 20 次的论文总共有 20 篇。
示例:
输入:citations = [3,0,6,1,5]
输出:3
解释:给定数组表示研究者总共有 5 篇论文,每篇论文相应的被引用了 3, 0, 6, 1, 5 次。
由于研究者有 3 篇论文每篇 至少 被引用了 3 次,其余两篇论文每篇被引用 不多于 3 次,所以她的 h 指数是 3。
提示:如果 h 有多种可能的值,h 指数是其中最大的那个。
序号:275. H 指数 II
给定一位研究者论文被引用次数的数组(被引用次数是非负整数),数组已经按照 升序排列 。编写一个方法,计算出研究者的 h 指数。
h 指数的定义: “h 代表“高引用次数”(high citations),一名科研人员的 h 指数是指他(她)的 (N 篇论文中)总共有 h 篇论文分别被引用了至少 h 次。(其余的 N - h 篇论文每篇被引用次数不多于 h 次。)"
示例:
输入: citations = [0,1,3,5,6]
输出: 3
解释: 给定数组表示研究者总共有 5 篇论文,每篇论文相应的被引用了 0, 1, 3, 5, 6 次。
由于研究者有 3 篇论文每篇至少被引用了 3 次,其余两篇论文每篇被引用不多于 3 次,所以她的 h 指数是 3。
说明:
如果 h 有多有种可能的值 ,h 指数是其中最大的那个。
一、实现思路
方法一:排序
分析
我们想象一个直方图,其中 x 轴表示文章,y 轴表示每篇文章的引用次数。如果将这些文章按照引用次数降序排序并在直方图上进行表示,那么直方图上的最大的正方形的边长 h就是我们所要求的 h。
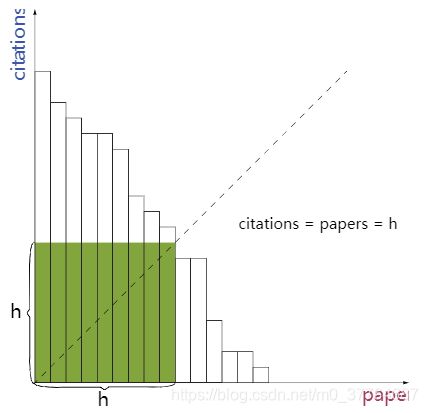
复杂度分析
时间复杂度:O(n\log n)O(nlogn),即为排序的时间复杂度。
空间复杂度:O(1)O(1)。大部分语言的内置 sort 函数使用堆排序,它只需要 O(1)O(1) 的额外空间。
方法二:计数
分析
基于比较的排序算法存在时间复杂度下界 O(n\log n)O(nlogn),如果要得到时间复杂度更低的算法,就必须考虑不基于比较的排序。
算法
方法一中,我们通过降序排序得到了 h 指数,然而,所有基于比较的排序算法,例如堆排序,合并排序和快速排序,都存在时间复杂度下界 O(n\log n)O(nlogn)。要得到时间复杂度更低的算法. 可以考虑最常用的不基于比较的排序,计数排序。
然而,论文的引用次数可能会非常多,这个数值很可能会超过论文的总数 nn,因此使用计数排序是非常不合算的(会超出空间限制)。在这道题中,我们可以通过一个不难发现的结论来让计数排序变得有用,即:
如果一篇文章的引用次数超过论文的总数 n,那么将它的引用次数降低为 n 也不会改变 h 指数的值。
由于 h指数一定小于等于 n,因此这样做是正确的。在直方图中,将所有超过 y轴值大于 n 的变为n 等价于去掉y>n 的整个区域。
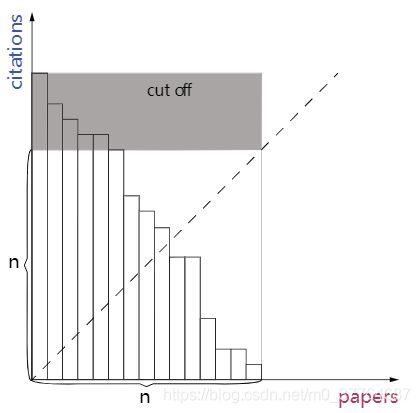
从直方图中可以更明显地看出结论的正确性,将 y>n 的区域去除,并不会影响到最大的正方形,也就不会影响到 h指数。
我们用一个例子来说明如何使用计数排序得到 hh 指数。首先,引用次数如下所示:
![]()
将所有大于 n=5的引用次数变为 n,得到
![]()
计数排序得到的结果如下:

![]()
public class Solution {
public int hIndex(int[] citations) {
int n = citations.length;
int[] papers = new int[n + 1];
// 计数
for (int c: citations)
papers[Math.min(n, c)]++;
// 找出最大的 k
int k = n;
for (int s = papers[n]; k > s; s += papers[k])
k--;
return k;
}
}
复杂度分析
时间复杂度:O(n)O(n)。在计数时,我们仅需要遍历 \mathrm{citations}citations 数组一次,因此时间复杂度为 O(n)O(n)。在找出最大的 k 时,我们最多需要遍历计数的数组一次,而计数的数组的长度为 O(n)O(n),因此这一步的时间复杂度为 O(n)O(n),即总的时间复杂度为 O(n)O(n)。
空间复杂度:O(n)O(n)。我们需要使用 O(n)O(n) 的空间来存放计数的结果
作者:LeetCode
链接:https://leetcode-cn.com/problems/h-index/solution/hzhi-shu-by-leetcode/
来源:力扣(LeetCode) 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 作者:LeetCode
链接:https://leetcode-cn.com/problems/h-index/solution/hzhi-shu-by-leetcode/
来源:力扣(LeetCode) 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
二、使用算法
1.python实现
代码如下(示例):
class Solution(object):
def hIndex(self, citations):
"""
:type citations: List[int]
:rtype: int
"""
citations.sort(reverse = True) #逆序,从大到小排序
i = 0
n = len(citations)
while(i<n and citations[i]>i):
i+=1
return i
注意!!!!!!!!!!!
#逆序会多花费时间,所以还是选择顺序排列,即从小到大排序
class Solution(object):
def hIndex(self, citations):
"""
:type citations: List[int]
:rtype: int
"""
citations.sort() #逆序会多花费时间,所以还是选择顺序排列,即从小到大排序
i = 0
n = len(citations)
while(i<n and citations[n-1-i]>i):
i+=1
return i
2.C++实现
class Solution {
public:
int hIndex(vector<int>& citations) {
sort(citations.begin(), citations.end());
int i = 0;
int n = citations.size();
while (i < n && citations[n - 1 - i] > i) {
i++;
}
return i;
}
};
这里sort()中的参数加上 greater() 运行结果不对
3.java实现
代码如下(示例):
class Solution {
public int hIndex(int[] citations) {
Arrays.sort(citations);
int i = 0;
while (i < citations.length && citations[citations.length - 1 - i] > i) {
i++;
}
return i;
}
}
总结
提示:这里对易错点进行总结:
1、对于程序中多次用到的东西,可以先算出来
2、排序时能用顺序从小到大就用顺序,逆序会增加时间
3、注意不同语言的排序函数不同,函数中的参数也不同
4、注意这里的C++排序中不能加greater()
可以对比下一篇文章
5、多个判断条件时可以用while实现,比for运行时间短