力扣刷题篇之哈希表1
系列文章目录
目录
系列文章目录
前言
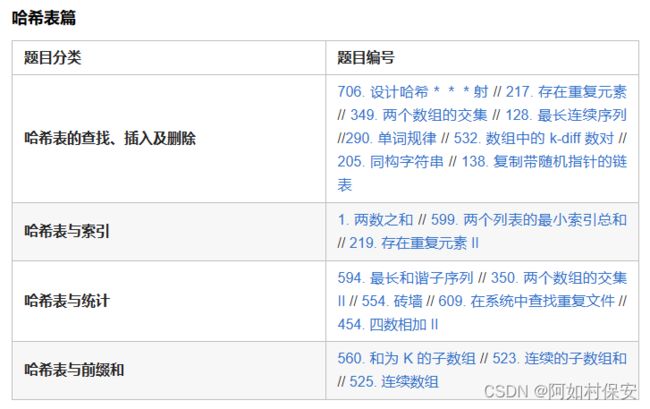
一、哈希表的查找、插入及删除
二、哈希表与索引
三、哈希表与统计
四、哈希表与前缀和
总结
前言
本系列是个人力扣刷题汇总,本文是哈希表。刷题顺序按照[力扣刷题攻略] Re:从零开始的力扣刷题生活 - 力扣(LeetCode)
一、哈希表的查找、插入及删除
在做706设计哈希表映射之前,先看看705设计哈希表


讲实话,我一看到这种设计的题我就头痛,但这个还行,用Boolean。
class MyHashSet {
/** Initialize your data structure here. */
boolean[] map = new boolean[1000005];
public MyHashSet() {
}
public void add(int key) {
map[key] = true;
}
public void remove(int key) {
map[key] = false;
}
/** Returns true if this set contains the specified element */
public boolean contains(int key) {
return map[key] == true;
}
}
/**
* Your MyHashSet object will be instantiated and called as such:
* MyHashSet obj = new MyHashSet();
* obj.add(key);
* obj.remove(key);
* boolean param_3 = obj.contains(key);
*/ 下面这个官方题解好复杂:
下面这个官方题解好复杂:
// class MyHashSet {
// /** Initialize your data structure here. */
// boolean[] map = new boolean[1000005];
// public MyHashSet() {
// }
// public void add(int key) {
// map[key] = true;
// }
// public void remove(int key) {
// map[key] = false;
// }
// /** Returns true if this set contains the specified element */
// public boolean contains(int key) {
// return map[key] == true;
// }
// }
// /**
// * Your MyHashSet object will be instantiated and called as such:
// * MyHashSet obj = new MyHashSet();
// * obj.add(key);
// * obj.remove(key);
// * boolean param_3 = obj.contains(key);
// */
class MyHashSet {
private static final int BASE = 769;
private LinkedList[] data;
/** Initialize your data structure here. */
public MyHashSet() {
data = new LinkedList[BASE];
for (int i = 0; i < BASE; ++i) {
data[i] = new LinkedList();
}
}
public void add(int key) {
int h = hash(key);
Iterator iterator = data[h].iterator();
while (iterator.hasNext()) {
Integer element = iterator.next();
if (element == key) {
return;
}
}
data[h].offerLast(key);
}
public void remove(int key) {
int h = hash(key);
Iterator iterator = data[h].iterator();
while (iterator.hasNext()) {
Integer element = iterator.next();
if (element == key) {
data[h].remove(element);
return;
}
}
}
/** Returns true if this set contains the specified element */
public boolean contains(int key) {
int h = hash(key);
Iterator iterator = data[h].iterator();
while (iterator.hasNext()) {
Integer element = iterator.next();
if (element == key) {
return true;
}
}
return false;
}
private static int hash(int key) {
return key % BASE;
}
}

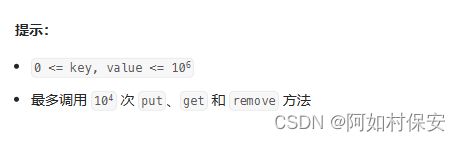
用一个values数组解决,初始化-1,需要映射的就变成了value。
class MyHashMap {
int[] values;
public MyHashMap() {
values = new int[1_000_000 + 1];
Arrays.fill(values, -1);
}
public void put(int key, int value) {
values[key] = value;
}
public int get(int key) {
return values[key];
}
public void remove(int key) {
values[key] = -1;
}
}
/**
* Your MyHashMap object will be instantiated and called as such:
* MyHashMap obj = new MyHashMap();
* obj.put(key,value);
* int param_2 = obj.get(key);
* obj.remove(key);
*/ 
优化:
使用两个数组 s 和 v 分别存储键和值。在构造函数中,初始化数组 s 和 v 的大小为 n,并用 Arrays.fill(s, n) 将数组 s 的所有元素填充为 n。这里的 n 是一个固定的常数,初始化为 6774。
class MyHashMap {
static int n=6774;
int[] s;
int[] v;
public MyHashMap() {
s=new int[n];
v=new int[n];
Arrays.fill(s,n);
}
public void put(int key, int value) {
int k=f(key);
s[k]=key;
v[k]=value;
}
public int get(int key) {
int k=f(key);
if(s[k]==n) return -1;
return v[k];
}
public void remove(int key) {
v[f(key)]=-1;
}
public int f(int x){
int k=x%n;
while(s[k]!=x&&s[k]!=n){
k++;
if(k==n) k=0;
}
return k;
}
}
/**
* Your MyHashMap object will be instantiated and called as such:
* MyHashMap obj = new MyHashMap();
* obj.put(key,value);
* int param_2 = obj.get(key);
* obj.remove(key);
*/
这个简化的哈希表实现并不处理动态扩容、哈希碰撞过多等复杂情况。
class MyHashMap {
private static class TreeNode {
private int key;
private int value;
private boolean color;
private TreeNode left;
private TreeNode right;
private TreeNode parent;
private TreeNode(int key, int value) {
this.key = key;
this.value = value;
}
}
private static final boolean RED = false;
private static final boolean BLACK = true;
private TreeNode[] hashtable = new TreeNode[1024];
private int currentSize;
public void put(int key, int value) {
if (currentSize >= hashtable.length) {
resize(); // 从结果来看,加载因子选 1.0 效率较高。
}
int index = key & (hashtable.length - 1);
insert(index, new TreeNode(key, value));
}
public int get(int key) {
int index = key & (hashtable.length - 1);
TreeNode node = getNode(index, key);
return node == null ? -1 : node.value;
}
public void remove(int key) {
int index = key & (hashtable.length - 1);
delete(index, key);
}
// 对哈希表进行扩容。
private void resize() {
TreeNode[] oldTable = hashtable;
hashtable = new TreeNode[hashtable.length << 1];
for (TreeNode root : oldTable) {
postorderTraversal(root);
}
currentSize >>= 1;
}
// 获取指定位置上的指定结点。
private TreeNode getNode(int index, int key) {
TreeNode current = hashtable[index];
while (current != null) {
if (current.key == key) {
break;
}
if (current.key < key) {
current = current.right;
} else {
current = current.left;
}
}
return current;
}
// 在指定位置上插入结点。
private void insert(int index, TreeNode insert) {
TreeNode current = hashtable[index], parent = null; // 分别保存当前结点及其父结点。
while (current != null) {
parent = current;
if (current.key == insert.key) {
current.value = insert.value;
return;
}
if (current.key < insert.key) {
current = current.right;
} else {
current = current.left;
}
}
insert.parent = parent;
if (parent == null) {
hashtable[index] = insert;
} else if (parent.key < insert.key) {
parent.right = insert;
} else {
parent.left = insert;
}
currentSize++;
fixAfterInsertion(index, insert);
}
// 删除指定位置上的指定结点。
private void delete(int index, int key) {
TreeNode delete = getNode(index, key);
if (delete == null) {
return;
}
if (delete.left != null && delete.right != null) {
TreeNode successor = delete.right;
while (successor.left != null) {
successor = successor.left;
}
delete.key = successor.key;
delete.value = successor.value;
delete = successor;
}
TreeNode replacement = delete.left == null ? delete.right : delete.left;
if (replacement == null) {
fixAfterDeletion(index, delete);
if (delete.parent == null) {
hashtable[index] = null;
} else if (delete.parent.left == delete) {
delete.parent.left = null;
} else {
delete.parent.right = null;
}
} else { // 被删除的结点只有一个子结点,那它一定是黑色结点,且它的子结点为红色。
replacement.parent = delete.parent;
if (delete.parent == null) {
hashtable[index] = replacement;
} else if (delete.parent.left == delete) {
delete.parent.left = replacement;
} else {
delete.parent.right = replacement;
}
replacement.color = BLACK;
}
currentSize--;
}
// 对插入后的结点进行调整。
private void fixAfterInsertion(int index, TreeNode insert) {
while (colorOf(insert.parent) == RED) { // 只有父结点是红色才进行处理。
// 分别保存当前结点的父结点、叔父结点、祖父结点。
TreeNode parent = insert.parent, uncle = sibling(parent), grand = parent.parent;
grand.color = RED; // 不管是哪种情况,祖父结点都需要染成红色。
if (colorOf(uncle) == BLACK) { // 叔父结点为黑色。
if (grand.left == parent) {
if (parent.right == insert) {
rotationLeft(index, parent); // LR 情况:先对父结点进行左旋转。
parent = insert;
}
rotationRight(index, grand); // LL 情况:对祖父结点进行右旋转。
} else {
if (parent.left == insert) {
rotationRight(index, parent); // RL 情况:先对父结点进行右旋转。
parent = insert;
}
rotationLeft(index, grand); // RR 情况:对祖父结点进行左旋转。
}
parent.color = BLACK; // 将旋转后的中心结点染成黑色。
insert = hashtable[index]; // 处理完直接退出循环。
} else { // 叔父结点为红色,则将父结点与叔父结点都染成黑色,将祖父结点作为新插入的结点继续处理。
uncle.color = BLACK;
parent.color = BLACK;
insert = grand;
}
}
hashtable[index].color = BLACK; // 根结点必须是黑色。
}
// 对删除后的结点进行调整。
private void fixAfterDeletion(int index, TreeNode delete) {
while (delete.parent != null && delete.color == BLACK) { // 只有删除的是黑色结点才进行处理。
// 分别保存当前结点的父结点、兄弟结点。
TreeNode parent = delete.parent, sibling = sibling(delete);
if (sibling.color == BLACK) { // 兄弟结点是黑色。
if (colorOf(sibling.left) == BLACK && colorOf(sibling.right) == BLACK) { // 兄弟结点没有红色子结点。
if (parent.color == BLACK) {
delete = parent;
}
parent.color = BLACK;
sibling.color = RED;
} else { // 兄弟结点有红色子结点。
if (parent.left == sibling) {
if (colorOf(sibling.left) == BLACK) {
rotationLeft(index, sibling); // LR 情况:先对兄弟结点进行左旋转。
sibling = sibling.parent;
}
rotationRight(index, parent); // LL 情况:对父结点进行右旋转。
} else {
if (colorOf(sibling.right) == BLACK) {
rotationRight(index, sibling); // RL 情况:先对兄弟结点进行右旋转。
sibling = sibling.parent;
}
rotationLeft(index, parent); // RR 情况:对父结点进行左旋转。
}
sibling.color = parent.color; // 旋转后中心结点继承父结点的颜色。
sibling.left.color = BLACK;
sibling.right.color = BLACK;
delete = hashtable[index]; // 处理完直接退出循环。
}
} else { // 兄弟结点是红色。
if (parent.left == sibling) {
rotationRight(index, parent);
} else {
rotationLeft(index, parent);
}
parent.color = RED;
sibling.color = BLACK;
}
}
}
// 获取指定结点的兄弟结点。
private TreeNode sibling(TreeNode node) {
if (node.parent.left == node) {
return node.parent.right;
}
return node.parent.left;
}
// 对指定位置上的指定结点进行左旋转。
private void rotationLeft(int index, TreeNode node) {
TreeNode newRoot = node.right; // 结点的右子结点会成为这颗子树的根结点。
node.right = newRoot.left;
if (newRoot.left != null) {
newRoot.left.parent = node;
}
newRoot.left = node;
newRoot.parent = node.parent;
if (node.parent == null) {
hashtable[index] = newRoot;
} else if (node.parent.left == node) {
node.parent.left = newRoot;
} else {
node.parent.right = newRoot;
}
node.parent = newRoot;
}
// 对指定位置上的指定结点进行右旋转。
private void rotationRight(int index, TreeNode node) {
TreeNode newRoot = node.left; // 结点的左子结点会成为这颗子树的根结点。
node.left = newRoot.right;
if (newRoot.right != null) {
newRoot.right.parent = node;
}
newRoot.right = node;
newRoot.parent = node.parent;
if (node.parent == null) {
hashtable[index] = newRoot;
} else if (node.parent.left == node) {
node.parent.left = newRoot;
} else {
node.parent.right = newRoot;
}
node.parent = newRoot;
}
// 获取指定结点的颜色。
private boolean colorOf(TreeNode node) {
return node == null || node.color;
}
// 对结点进行后序遍历。
private void postorderTraversal(TreeNode node) {
if (node == null) {
return;
}
postorderTraversal(node.left);
postorderTraversal(node.right);
node.left = node.right = node.parent = null;
node.color = RED;
int index = node.key & (hashtable.length - 1);
insert(index, node);
}
}
/**
* Your MyHashMap object will be instantiated and called as such:
* MyHashMap obj = new MyHashMap();
* obj.put(key,value);
* int param_2 = obj.get(key);
* obj.remove(key);
*/

方法一、利用哈希表的不重复性
class Solution {
public boolean containsDuplicate(int[] nums) {
Set set = new HashSet<>();
for(int num:nums){
if(!set.add(num)){
return true;
}
}
return false;
}
} 
方法二、不用哈希表,
保持当前元素最大,下一个比当前还要大,无需挨个对比// class Solution {
// public boolean containsDuplicate(int[] nums) {
// Set set = new HashSet<>();
// for(int num:nums){
// if(!set.add(num)){
// return true;
// }
// }
// return false;
// }
// }
class Solution {
public boolean containsDuplicate(int[] nums) {
//00,11 0
//01,10 1
//011 3
//101 5
//110 6
//101 5
//011 3
//3^5^5=3
int length=nums.length;//长度记录
if(length==0 || length==1){
return false;//排除极端情况
}
//保持当前元素最大,下一个比当前还要大,无需挨个对比
for(int i=1;i=0;j--){//递推
if(nums[i]==nums[j]){//相等
return true;//返回值
}
}
nums[i]^=nums[i-1];//异或判断相等两个
nums[i-1]^=nums[i];
nums[i]^=nums[i-1];
}
}
return false;//互不同
}
} 

用两个hashset
import java.util.HashSet;
import java.util.Set;
class Solution {
public int[] intersection(int[] nums1, int[] nums2) {
Set num1 = new HashSet<>();
for (int num : nums1) {
num1.add(num);
}
Set res = new HashSet<>();
for (int num : nums2) {
if (num1.contains(num)) {
res.add(num);
}
}
int[] result = new int[res.size()];
int index = 0;
for (int num : res) {
result[index++] = num;
}
return result;
}
} 
// class Solution {
// public int[] intersection(int[] nums1, int[] nums2) {
// int[] temp = new int[1001];
// for (int i = 0; i < nums1.length; i++) {
// if (temp[nums1[i]]==0) temp[nums1[i]]=1;
// }
// int num = 0;
// for (int i = 0; i < nums2.length; i++) {
// if (temp[nums2[i]]==1){
// temp[nums2[i]]=2;
// num++;
// }
// }
// int[] res = new int[num];
// for (int i = 0; i < 1001; i++) {
// if (temp[i]==2){
// res[--num] = i;
// }
// }
// return res;
// }
// }
class Solution {
public int[] intersection(int[] nums1, int[] nums2) {
return intersectionNoSorted(nums1, nums2);
}
/**
* 不排序
*/
private int[] intersectionNoSorted(int[] nums1, int[] nums2){
boolean[] exists1 = new boolean[1001];
boolean[] exists2 = new boolean[1001];
for(int num : nums1){
exists1[num] = true;
}
int minLen = Math.min(nums1.length, nums2.length);
int[] sameArr = new int[minLen];
int i = 0;
for(int num : nums2){
if(exists1[num] && !exists2[num]){
sameArr[i++] = num;
}
exists2[num] = true;
}
return Arrays.copyOf(sameArr, i);
}
/**
* 排序后比较
*/
private int[] intersectionBySorted(int[] nums1, int[] nums2){
Arrays.sort(nums1);
Arrays.sort(nums2);
int p1 = 0, p2 = 0;
Set same = new HashSet<>();
while(p1 < nums1.length && p2 < nums2.length){
if(nums1[p1] == nums2[p2]){
same.add(nums1[p1]);
p1++;
p2++;
}else if(nums1[p1] < nums2[p2]){
p1++;
}else{
p2++;
}
}
int[] sameArr = new int[same.size()];
Iterator it = same.iterator();
int i = 0;
while(it.hasNext()){
sameArr[i++] = it.next();
}
return sameArr;
}
} 

不用哈希表,先排序,然后遍历,连续就不断累积,不连续就更新,找最长的。
时间复杂度为 O(nlogn)。空间复杂度为 O(1)
class Solution {
public int longestConsecutive(int[] nums) {
if(nums==null||nums.length==0){
return 0;
}
int res=1;
int num=1;
int n=nums.length;
Arrays.sort(nums);
for(int i=1;i
用哈希表的查找,很慢
遍历数组 nums,将每个元素添加到 set 中。
接下来,我们定义一个变量 res,用于记录最长连续序列的长度。
然后,我们再次遍历数组 nums,对于每个元素 num,我们判断 num 是否为连续序列的起点。如果 num - 1 不在 set 中,说明 num 是一个连续序列的起点。
我们以 num 为起点,通过向后搜索连续的元素来计算连续序列的长度。我们通过不断增加 currentNum 的值,并检查 currentNum + 1 是否在 set 中,来判断是否继续向后搜索。
在搜索的过程中,我们用 currentStreak 记录当前连续序列的长度,并更新 res 的值为当前最大的连续序列长度。
最后,我们返回 res 作为结果,即最长连续序列的长度。
使用哈希表的解法可以将时间复杂度优化至 O(n),因为在哈希表中查找元素的时间复杂度为 O(1)。
import java.util.HashSet;
class Solution {
public int longestConsecutive(int[] nums) {
if (nums == null || nums.length == 0) {
return 0;
}
HashSet set = new HashSet<>();
for (int num : nums) {
set.add(num);
}
int res = 0;
for (int num : nums) {
// 只考虑连续序列的起点
if (!set.contains(num - 1)) {
int currentNum = num;
int currentStreak = 1;
// 连续地增加当前数的值来计算连续序列的长度
while (set.contains(currentNum + 1)) {
currentNum++;
currentStreak++;
}
res = Math.max(res, currentStreak);
}
}
return res;
}
} 

先把字符串s按空格分割成字符型数组;然后存进哈希表判断
class Solution {
public boolean wordPattern(String pattern, String s) {
String[] strings = s.split(" ");
if (pattern.length() != strings.length) {
return false;
}
Map map = new HashMap<>();//key可以是任意类型
for (int i = 0; i < strings.length; i++) {
if (!Objects.equals(map.put(strings[i], i), map.put(pattern.charAt(i), i))) {
//判断两个键在哈希表中是否有相同的旧值
return false;
}
}
return true;
}
} 


法一,用哈希表记录每个元素出现的次数。遍历哈希表,找到count次数。
class Solution {
public int findPairs(int[] nums, int k) {
Map map=new HashMap<>();
int count=0;
if(k<0)return count;
for(int i=0;i1)
count++;
}
else if(map.containsKey(i+k)){
count++;
}
}
return count;
}
} 
方法二、 使用 BitSet 来记录数组中出现的数和已使用过的数,以减少内存消耗.
更多bitset可以看Java中BitSet的使用及详解_java bitset函数用法-CSDN博客
Java Bitset类 | 菜鸟教程 (runoob.com)
Java位运算工具类-BitSet详细介绍 - Rookie--; - 博客园 (cnblogs.com)
// class Solution {
// public int findPairs(int[] nums, int k) {
// Map map=new HashMap<>();
// int count=0;
// if(k<0)return count;
// for(int i=0;i1)
// count++;
// }
// else if(map.containsKey(i+k)){
// count++;
// }
// }
// return count;
// }
// }
class Solution {
public int findPairs(int[] nums, int k) {
final int n = nums.length;
int max = Integer.MIN_VALUE, min = Integer.MAX_VALUE;
for (final int num : nums) {
if (num > max) { max = num; }
if (num < min) { min = num; }
}
// cbs whether exist
// ubs whether used
final BitSet cbs = new BitSet(max-min+1);
final BitSet ubs = new BitSet(max-min+1);
int cnt = 0;
if (k == 0) {
for (final int num : nums) {
if (cbs.get(num-min)) {
if (!ubs.get(num-min)) {
cnt += 1;
ubs.set(num-min);
}
} else {
cbs.set(num-min);
}
}
return cnt;
}
for (final int num : nums) { cbs.set(num-min); }
for (final int num : nums) {
if (!ubs.get(num-min) && num+k<=max && cbs.get(num+k-min)) {
cnt += 1;
ubs.set(num-min);
}
}
return cnt;
}
} 

和上面290类似
class Solution {
public boolean isIsomorphic(String s, String t) {
if(t.endsWith("{|}~?\"bcdefg&ijklmnopqrstuvwxyzABCD")){
return true;
}
if(t.endsWith("{|}~?\"bcdefg&ijklmnopqrstuvwxyzA@CD")){
return false;
}
if(s.length()!=t.length()){
return false;
}
Map mapS=new HashMap<>();
Map mapT=new HashMap<>();
for(int i=0;i 
也可以写成
class Solution {
public boolean isIsomorphic(String s, String t) {
if(t.endsWith("{|}~?\"bcdefg&ijklmnopqrstuvwxyzABCD")){
return true;
}
if(t.endsWith("{|}~?\"bcdefg&ijklmnopqrstuvwxyzA@CD")){
return false;
}
if(s.length()!=t.length()){
return false;
}
Map mapS=new HashMap<>();
Map mapT=new HashMap<>();
for(int i=0;i 
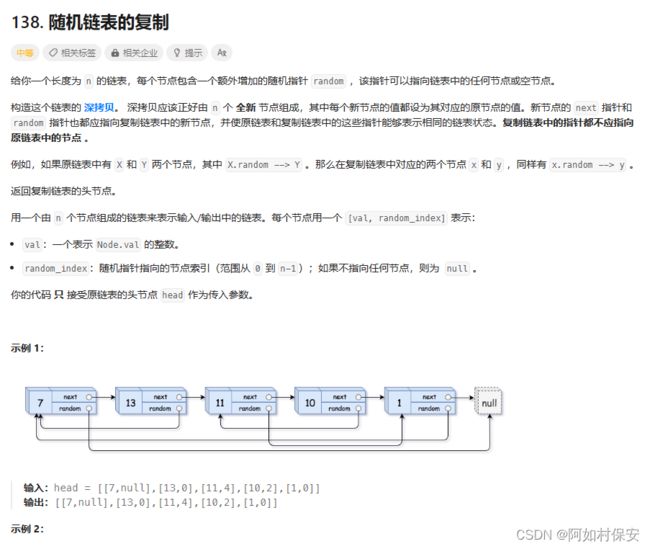
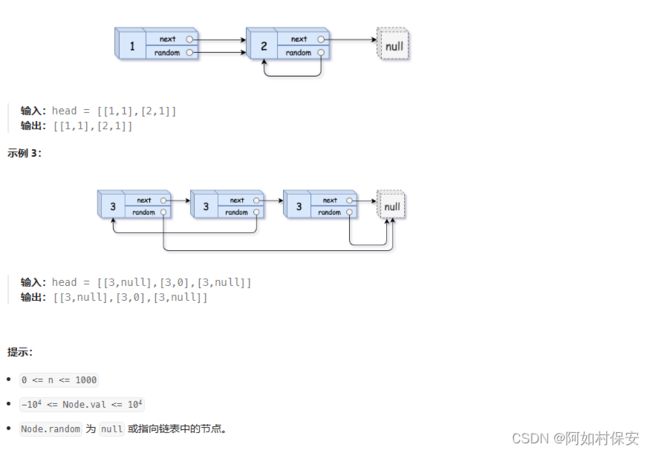
这一题之前左的链表汇总也有写:左程云算法与数据结构代码汇总之链表(Java)-CSDN博客
1.hashmap
采用一个Hash表,老结点的内存地址作为KEY值,从老结点中复制得来的新结点内存地址作为VALUE值,当结点遍历完毕后,所有的新旧结点均拷贝完毕。
从头遍历老链表,每遍历一个结点,就得出他的rand和next指针,然后因为next指针和rand指针都是作为Hash表key存在,所以可以依据这个next和rand指针经由hash函数得出其对应新结点的所在地址(假设为N和R),再根据当前结点和哈希函数,得出当前结点的新结点,然后再设置新结点的next和rand指针分别指向N和R,重复步骤二,直到链表遍历完毕。
第一次遍历旧链表,使用哈希map,key为旧链表,value为新链表,新链表只是单纯地串起来并拷贝int value值,rand没有设置;第二次遍历旧链表,调用key-value,设置rand node。
/*
// Definition for a Node.
class Node {
int val;
Node next;
Node random;
public Node(int val) {
this.val = val;
this.next = null;
this.random = null;
}
}
*/
class Solution {
public Node copyRandomList(Node head) {
HashMap map = new HashMap();
Node cur = head;
while (cur != null) {
map.put(cur, new Node(cur.val));
cur = cur.next;
}
cur = head;
while (cur != null) {
map.get(cur).next = map.get(cur.next);
map.get(cur).random = map.get(cur.random);
cur = cur.next;
}
return map.get(head);
}
} 
2.原地克隆,这个方法太genius了!!!
为每一个结点生成一个克隆结点,克隆结点只包含原结点的data值,将其作为对应老结点的下一个结点。比如对于链表 1 -> 2 -> 3 -> null,其中1的rand域指向3,2的rand域指向1;按照该规则,链表则变化为 1 -> 1’ -> 2 -> 2’ -> 3 -> 3’ -> null;
采用双指针pre和cur,pre始终指向cur的前一个结点,cur为当前遍历结点,当cur遍历到克隆节点时,比如1’,则pre指向该克隆节点的原结点,此时通过pre.rand.next即可得到cur结点(即1’)的rand指针指向的地址,随后cur跳到下一个旧结点(指2),如此直到遍历到链表空结点。
将新的链表进行撕裂,分成两个链表,一个全部由新结点组成,另一个全部由旧结点组成,然后返回全部由克隆节点组成的链表表头。
第一次遍历旧链表,不用哈希map,在旧map中,插入克隆node,拷贝int value值;第二次遍历链表,一对一对处理,设置rand node;第三次遍历,把旧节点删除。省去了hashmap的空间。
/*
// Definition for a Node.
class Node {
int val;
Node next;
Node random;
public Node(int val) {
this.val = val;
this.next = null;
this.random = null;
}
}
*/
class Solution {
public Node copyRandomList(Node head) {
if (head == null) {
return null;
}
Node cur = head;
Node next = null;
// copy node and link to every node
while (cur != null) {
next = cur.next;
cur.next = new Node(cur.val);
cur.next.next = next;
cur = next;
}
cur = head;
Node curCopy = null;
// set copy node rand
while (cur != null) {
next = cur.next.next;
curCopy = cur.next;
curCopy.random = cur.random != null ? cur.random.next : null;
cur = next;
}
Node res = head.next;
cur = head;
// split
while (cur != null) {
next = cur.next.next;
curCopy = cur.next;
cur.next = next;
curCopy.next = next != null ? next.next : null;
cur = next;
}
return res;
}
}
二、哈希表与索引

哈希表记录所有的(nums[i],i),看能不能找到,break很关键。
class Solution {
public int[] twoSum(int[] nums, int target) {
HashMap map=new HashMap<>();
int res[]=new int[2];
for(int i=0;i 

使用 HashMap 来记录 list1 数组中的元素及其索引位置,然后遍历 list2 数组,查找共同喜爱的餐厅,并将其存储到 list1 数组中。最后返回list1中前cnt个字符串。
class Solution {
public String[] findRestaurant(String[] list1, String[] list2) {
int n1 = list1.length, n2 = list2.length;
if (n1 < n2) return findRestaurant(list2, list1);
Map map = new HashMap<>((int) (n1 / 0.75f));
for (int i = 0; i < n1; ++i) {
map.put(list1[i], i);
}
int cnt = 0, x = Integer.MAX_VALUE;
for (int i = 0; i < n2 && i <= x; ++i) {
String s = list2[i];
if (map.containsKey(s)) {
int t = map.get(s) + i;
if (t <= x) {
if (t < x) {
x = t;
cnt = 0;
}
list1[cnt++] = list2[i];
}
}
}
return Arrays.copyOf(list1, cnt);
}
} 

class Solution {
public boolean containsNearbyDuplicate(int[] nums, int k) {
Map map = new HashMap<>();
for(int i = 0; i < nums.length; ++i){
if(map.containsKey(nums[i])){
if((i - map.get(nums[i]) <= k)) return true;
}
// 覆盖之后的位置和下一个相同值肯定离得更近
map.put(nums[i], i);
}
return false;
}
} 
总结
今天把哈希表的第一二专题写完了,没那么简单,因为可以用很多方法,有时候哈希表并不是最优解。今天就写到这里吧,要开题了,我去搞搞机器人导航,扶额头痛。。。。
