OpenCL并行编程语言及其矢量相加实例——一文带你快速入门
✍️现如今,随着计算的应用场景变得日益复杂多样,为了跟上人工智能算法对算力的需求,GPU硬件架构快速走向多样化,GPU生产厂家众多,且在商业和市场等因素的影响下,GPU通用计算编程模型也日益多元化。在CUDA的章节中我们提到,CUDA就是应对这种异构计算挑战的工具,OpenCL和CUDA一样也是一种异构计算的标准,可以用来针对GPU进行并行编程和计算。但是,NVIDIA 的并行编程语言CUDA仅仅只支持自家的加速卡,对其他显卡不支持,为了应对在不同硬件平台上使用一种并行编程标准,2008年6月苹果提出了OpenCL(Open Computing Language,开放计算语言),它是一个通用的标准,OpenCL规范类似CUDA通过扩展C/C++语言实现并行计算功能,提供了统一的编程API,由API完成各种功能,API的具体编程实现由各个设备厂家来完成,对多核 CPU、GPU、DSP、FPGA等硬件都有较好的支持。这篇文章可以带大家快速入门。
附上OpenCL官方网站地址
https://www.khronos.org/opencl/ https://www.khronos.org/opencl/
https://www.khronos.org/opencl/
先沾上目录:
目录
什么是OpenCL
OpenCL编程框架
平台模型
执行模型
编程模型
存储模型
OpenCL并行程序构建流程
OpenCL实例-矢量相加
什么是OpenCL
OpenCL 是 Khronos 组织制定的异构计算统一编程标准,得到了 AMD、Apple Intel、NVIDIA、ARM、Xilinx、TI 等公司的支持,因此可以运行在多核 CPU、GPU、DSP、FPGA 以及异构加速处理单元上。OpenCL 计算模型在具体硬件上执行时,由各个厂家的运行环境负责将代码在线编译成机器码并建立软硬件映射机制。当硬件计算设备执行的并行程序 kermel启动后会创建大量的线程同时执行,每个线程称为工作单元(work-item)用来具体执行 kermel 程序。当映射到 OpenCL 硬件上执行时,采用两级并行机制,work-group 并发运行在异构计算设备的计算单元上,同一个 work-group 里的多个work-item 相互独立并在处理单元上并行执行。
OpenCL编程框架
OpenCL编程框架包含平台模型、执行模型、编程模型和存储模型等四个模型,简述如下。
平台模型
平台模型如图1所示,一个主机端(host)和多个支持运行OpenCL程序的设备端(device)构成了OpenCL的平台模型。主机端通过调用OpenCL的一些接口管理整个平台的所有计算资源,设备端可以是CPU、GPU、FPGA、MIC等多种异构加速设备,每个OpenCL设备由一个或多个计算单元(Compute Unit,CU)组成,每个CU又可以进一步分割成一个或多个处理单元(Processing Element,PE),PE是并行计算的最基本单元。
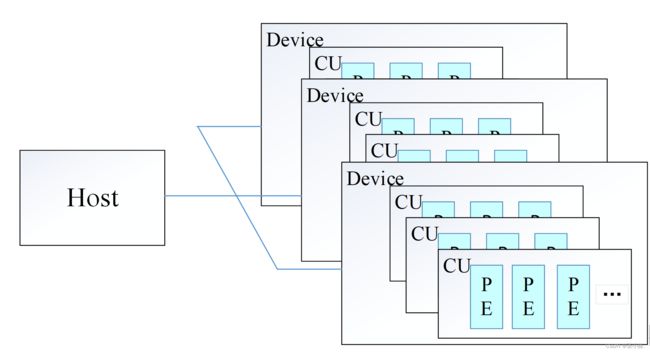
图1 OpenCL平台模型
执行模型
该模型主要包括主机程序和核程序两部分,主程序运行在CPU上,核程序运行在GPU、FPGA等加速设备上。对于一个核函数而言,首先通过主机端发出命令提交到设备端执行,同时会创建一个索引空间NDRange,该空间内的每个处理单元并行执行核程序的一个实例,在NDRange上每个实例系统会分配一个全局ID(global ID)。核函数启动后会创建大量的工作单元(work-item)完成该函数所定义的操作。当映射到GPU平台执行时,也是采用了两级并行机制,不同工作组(work-group)并发运行在异构计算设备的CU上,同一个work-group里的多个work-item相互独立并在PE上并行执行。主机端主要通过定义上下文、NDRange和命令队列来控制核程序执行的方式和时间。在AMD的系统中,基于OpenCL的核函数在实际执行过程中,与CUDA warp类似,线程的数量是以wavefront为单位进行开启。
OpenCL的执行模式可分为两部分:一部分是在host上执行的主程序(host program),另一部分是在OpenCL设备(OpenCL devices)上执行的内核程序(kernel)。主程序定义了上下文并管理着内核程序在OpenCL设备上的执行。
OpenCL执行模型的核心工作就是管理kernel在OpenCL设备上的运行。当kernel程序被提交执行之前,必须先定义一个索引空间,kernel会在索引空间的每个节点(work-item)上执行,每个节点具有在一维、二维或三维等各个维度上的全局ID(global ID)。各个work-tiem执行相同的代码,但不同的work-item可以有不同的执行路径和操作数据。
每个work-item都有一个唯一的工作组(work-group),以及相应的work-group ID。单个work-item可以通过它的global ID识别,也可以通过local ID + work-group ID的方式识别。如图5-4,同一个work-group内的work-item在单个计算单元的处理单元上同时执行。同步只允许在同一个work-group内的work-item间进行。
OpenCL使用NDRange来定义N-维索引空间。它由一个长度为N的整型数组构成(N取1、2或3),数组的元素指定了相应维度上工作节点的个数(加上默认为0的偏移量F)。work-item的global ID和local ID以及work-group ID都是N维的,每个维度都是从0开始依次加1。
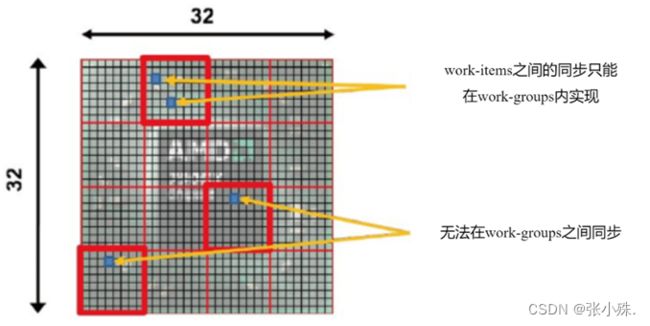
图2 work-item组成work-group
例如,对于如图3所示的一个大小为1024(32×32)二维索引空间,将其划分成16个work-group,其中红色标记所在work-group的ID为(3,1),local size为64 (8×8)。这个work-group中标记的那个work-item的local ID为(4,2),但也可以通过它的global ID(28,10)进行定位。

图3work-group示例
为了更好的理解OpenCL的网格划分形式,我们可以同学习过的CUDA编程中的网格划分形式进行对比,在CDUA中网格划分从大到小依次为Grid、Block和Thread,而OpenCL中网格划分从大到小依次为NDRange、Work-group和Work-item,两者的网格划分形式基本一致,只是在名称上有所区别,在学习OpenCL的过程中可以同CDUA进行对比有助于更进一步的理解。
编程模型
该模型定义了OpenCL应用与设备的映射关系,支持数据并行、任务并行或者数据与任务两者模式的混合。在数据并行中,依据当前工作节点的global ID或者local ID来映射与此节点相对应的数据元素,所有数据元素执行相同的操作指令,包括work-item之间的数据并行和work-group之间的数据并行;而任务并行是指所有的work-item都在执行核程序,对于其他的work-item是不相关的,该模型适合大量任务并行时的应用。通常情况下,数据并行应用的更加广泛。
存储模型
该模型定义了执行核对象所用的存储结构,是独立于设备平台实际硬件架构的一种抽象模型。在异构平台上的存储对象主要分为两类,包括主机上的内存模型和设备上的存储模型,而OpenCL存储模型主要是指设备上的存储模型,包括私有存储(private memory)、局部存储、常量存储和全局存储,存储模型如图4所示。在一个核程序执行过程中,全局存储的数据能够被所有的work-item读写,常量存储是只读的全局显存,在一个work-group中所有的work-item共享同一个局部存储,而在一个work-item中定义的私有存储变量仅对自身可见,对其他的work-item是不可见的。一般来说在大部分的OpenCL设备上,私有存储是在寄存器文件中。程序实现过程中,用户只需考虑抽象的存储模型,而无需考虑具体硬件上的映射关系。
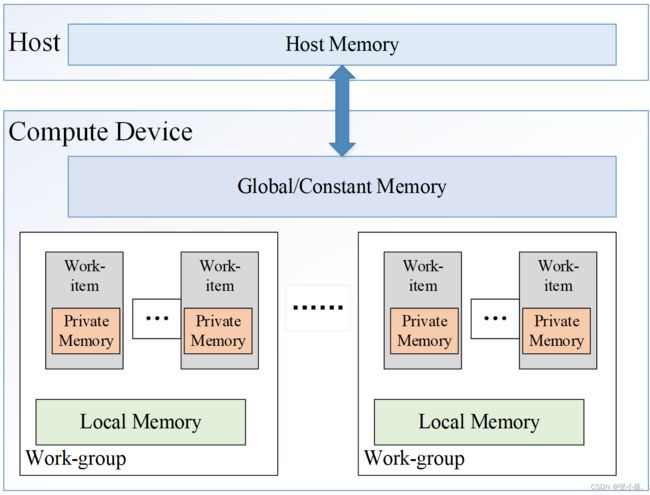
图4 OpenCL存储模型
OpenCL并行程序构建流程
使用OpenCL进行并行程序的开发,和CDUA编程的思想基本一样,其程序设计大致可分为6个步骤,分别如下:
(1)获取计算平台(Platform),查找支持OpenCL的硬件设备,并创建上下文(Context); 函数clGetPlatformIDs可用来获取可用平台的数量和列表,函数clGetDeviceIDs用来获取OpenCL设备的数量和列表。
(2)创建命令队列(Command Queue)及包含了内核的程序(Program)对象,如果该程序是源代码,则还需进行在线编译; 需要使用函数clCreateCommandQueue创建命令队列,使用命令clCreateProgramWithSource创建程序对象,程序对象需要一个字符串指针,这个指针指向GPU计算核代码,使用命令clBuildProgram编译GPU并行程序。
(3) 创建程序执行过程中需要的存储对象(Buffer),并初始化;
在GPU上利用clCreateBuffer函数开辟数据空间,需要设置GPU显存空间的读写属性和开辟空间的大小。利用函数clEnqueueWriteBuffer将数据从内存传输到显存。
(4) 创建内核对象并设置其所需参数;
使用命令clCreateKernel和核函数名称从程序对象中建立核函数对象。使用clSetKernelArg函数设置核程序参数。
(5) 设置内核的索引空间(NDRange)并执行内核,其中,NDRange通过全局尺寸(Global Size)和工作组尺寸(Work Group)来进行管理;
调用函数clEnqueueNDRangeKernel执行核代码。函数中要设置全局网格和局部网格的线程组织方式。然后调用clFinish函数以确保命令队列中的命令执行完毕。
(6) 将运行的结果拷贝回主机(Host)内存。
利用函数clEnqueueReadBuffer将计算结果从显存拷贝回主机内存。
OpenCL实例-矢量相加
// This program implements a vector addition using OpenCL
// System includes
#include
#include
// OpenCL includes
#include
// OpenCL kernel to perform an element-wise addition
const char* programSource =
"__kernel \n"
"void vecadd(__global int *A, \n"
" __global int *B, \n"
" __global int *C) \n"
"{ \n"
" \n"
" // Get the work-item’s unique ID \n"
" int idx = get_global_id(0); \n"
" \n"
" // Add the corresponding locations of \n"
" // 'A' and 'B', and store the result in 'C'. \n"
" C[idx] = A[idx] + B[idx]; \n"
"} \n"
;
int main() {
// This code executes on the OpenCL host
// Host data
int *A = NULL; // Input array
int *B = NULL; // Input array
int *C = NULL; // Output array
// Elements in each array
const int elements = 2048;
// Compute the size of the data
size_t datasize = sizeof(int)*elements;
// Allocate space for input/output data
A = (int*)malloc(datasize);
B = (int*)malloc(datasize);
C = (int*)malloc(datasize);
// Initialize the input data
int i;
for(i = 0; i < elements; i++) {
A[i] = i;
B[i] = i;
}
// Use this to check the output of each API call
cl_int status;
// Retrieve the number of platforms
cl_uint numPlatforms = 0;
status = clGetPlatformIDs(0, NULL, &numPlatforms);
// Allocate enough space for each platform
cl_platform_id *platforms = NULL;
platforms = (cl_platform_id*)malloc(
numPlatforms*sizeof(cl_platform_id));
// Fill in the platforms
status = clGetPlatformIDs(numPlatforms, platforms, NULL);
// Retrieve the number of devices
cl_uint numDevices = 0;
status = clGetDeviceIDs(platforms[0], CL_DEVICE_TYPE_ALL, 0,
NULL, &numDevices);
// Allocate enough space for each device
cl_device_id *devices;
devices = (cl_device_id*)malloc(
numDevices*sizeof(cl_device_id));
// Fill in the devices
status = clGetDeviceIDs(platforms[0], CL_DEVICE_TYPE_ALL,
numDevices, devices, NULL);
// Create a context and associate it with the devices
cl_context context;
context = clCreateContext(NULL, numDevices, devices, NULL,
NULL, &status);
// Create a command queue and associate it with the device
cl_command_queue cmdQueue;
cmdQueue = clCreateCommandQueue(context, devices[0], 0,
&status);
// Create a buffer object that will contain the data
// from the host array A
cl_mem bufA;
bufA = clCreateBuffer(context, CL_MEM_READ_ONLY, datasize,
NULL, &status);
// Create a buffer object that will contain the data
// from the host array B
cl_mem bufB;
bufB = clCreateBuffer(context, CL_MEM_READ_ONLY, datasize,
NULL, &status);
// Create a buffer object that will hold the output data
cl_mem bufC;
bufC = clCreateBuffer(context, CL_MEM_WRITE_ONLY, datasize,
NULL, &status);
// Write input array A to the device buffer bufferA
status = clEnqueueWriteBuffer(cmdQueue, bufA, CL_FALSE,
0, datasize, A, 0, NULL, NULL);
// Write input array B to the device buffer bufferB
status = clEnqueueWriteBuffer(cmdQueue, bufB, CL_FALSE,
0, datasize, B, 0, NULL, NULL);
// Create a program with source code
cl_program program = clCreateProgramWithSource(context, 1,
(const char**)&programSource, NULL, &status);
// Build (compile) the program for the device
status = clBuildProgram(program, numDevices, devices,
NULL, NULL, NULL);
// Create the vector addition kernel
cl_kernel kernel;
kernel = clCreateKernel(program, "vecadd", &status);
// Associate the input and output buffers with the kernel
status = clSetKernelArg(kernel, 0, sizeof(cl_mem), &bufA);
status = clSetKernelArg(kernel, 1, sizeof(cl_mem), &bufB);
status = clSetKernelArg(kernel, 2, sizeof(cl_mem), &bufC);
// Define an index space (global work size) of work
// items for execution. A workgroup size (local work size)
// is not required, but can be used.
size_t globalWorkSize[1];
// There are 'elements' work-items
globalWorkSize[0] = elements;
// Execute the kernel for execution
status = clEnqueueNDRangeKernel(cmdQueue, kernel, 1, NULL,
globalWorkSize, NULL, 0, NULL, NULL);
// Read the device output buffer to the host output array
clEnqueueReadBuffer(cmdQueue, bufC, CL_TRUE, 0,
datasize, C, 0, NULL, NULL);
// Verify the output
int result = 1;
for(i = 0; i < elements; i++) {
if(C[i] != i+i) {
result = 0;
break;
}
}
if(result) {
printf("Output is correct\n");
} else {
printf("Output is incorrect\n");
}
// Free OpenCL resources
clReleaseKernel(kernel);
clReleaseProgram(program);
clReleaseCommandQueue(cmdQueue);
clReleaseMemObject(bufA);
clReleaseMemObject(bufB);
clReleaseMemObject(bufC);
clReleaseContext(context);
// Free host resources
free(A);
free(B);
free(C);
free(platforms);
free(devices);
return 0;
}
上述代码便是实现两个向量相加的完整并行代码。编写完程序后。我们便可以对这个代码进行编译和执行,要编译OpenCL代码,您通常需要使用特定于您的OpenCL平台和编译器的命令.
对于AMD的ROCm平台:
hipcc -o OpenCL_vectorAdd OpenCL_vectorAdd.c对于NVIDIA的CUDA平台:
nvcc -o OpenCL_vectorAdd OpenCL_vectorAdd.c对于Intel的OpenCL SDK:
icpc -o OpenCL_vectorAdd OpenCL_vectorAdd.c对于Khronos Group提供的OpenCL ICD Loader:
gcc -o OpenCL_vectorAdd OpenCL_vectorAdd.c -lOpenCL