实验5 MapReduce初级编程实践(Python实现)
一、实验目的
- 通过实验掌握基本的 MapReduce 编程方法;
- 掌握用 MapReduce 解决一些常见数据处理问题的方法,包括数据合并、数据去重、数据排序和数据挖掘等。
二、实验平台
- 操作系统:Ubuntu 18.04(或 Ubuntu 16.04)
- Hadoop 版本:3.2.2
三、实验内容和要求
1. 编程实现文件合并和去重操作
问题如下:
对于两个输入文件,即文件A和文件B,请编写 MapReduce 程序,对两个文件进行合并,并剔除其中重复的内容,得到一个新的输出文件C。下面是输入文件和输出文件的一个样例,以供参考。
输入文件A的样例如下:
20150101 x
20150102 y
20150103 x
20150104 y
20150105 z
20150106 x
输入文件B的样例如下:
20150101 y
20150102 y
20150103 x
20150104 z
20150105 y
根据输入文件A和B合并得到的输出文件C的样例如下:
20150101 x
20150101 y
20150102 y
20150103 x
20150104 y
20150104 z
20150105 y
20150105 z
20150106 x
代码如下:
编写 Map 的 Python 代码如下(mapper.py):
#!/usr/bin/env python3
# encoding=utf-8
lines = {}
import sys
for line in sys.stdin:
line = line.strip()
key, value = line.split()
if key not in lines.keys():
lines[key] = []
if value not in lines[key]:
lines[key].append(value)
lines[key] = sorted(lines[key])
for key, value in lines.items():
print(key, end = ' ')
for i in value:
print(i, end = ' ')
print()
编写 Reduce 的 Python 代码如下(reducer.py):
#!/usr/bin/env python3
# encoding=utf-8
import sys
key, values = None, []
for line in sys.stdin:
line = line.strip().split(' ')
if key == None:
key = line[0]
if line[0] != key:
key = line[0]
values = []
if line[1] not in values:
print('%s\t%s' % (line[0], line[1]))
values.append(line[1])
简单测试:
简单在本地测试一下,运行如下代码:
cat A B | python3 mapper.py | python3 reducer.py
输出如下:
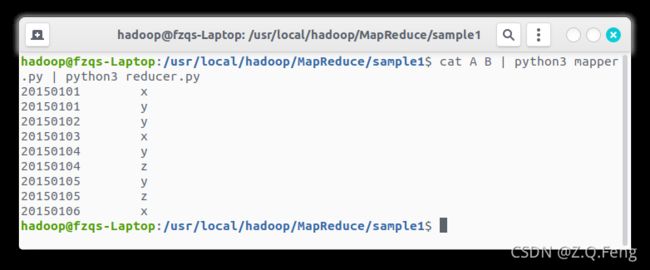
文末我会介绍如何将 Python 程序应用于 HDFS 文件系统中。
2. 编写程序实现对输入文件的排序
问题如下:
现在有多个输入文件,每个文件中的每行内容均为一个整数。要求读取所有文件中的整数,进行升序排序后,输出到一个新的文件中;输出的数据格式为每行两个整数,第一个数字为第二个整数的排序位次,第二个整数为原待排列的整数。下面是输入文件和输出文件的一个样例,以供参考。
输入文件 1 的样例如下:
33
37
12
40
输入文件 2 的样例如下:
4
16
39
5
输入文件 3 的样例如下:
1
45
25
根据输入文件 1、2 和 3 得到的输出文件如下:
1 1
2 4
3 5
4 12
5 16
6 25
7 33
8 37
9 39
10 40
11 45
代码如下:
编写 Map 的 Python 代码如下(mapper.py):
#!/usr/bin/env python3
# encoding=utf-8
lines = []
import sys
for line in sys.stdin:
line = line.strip()
try:
line = int(line)
except ValueError:
continue
lines.append(line)
lines = sorted(lines)
for line in lines:
print(line)
编写 Reduce 的 Python 代码如下(reducer.py):
#!/usr/bin/env python3
# encoding=utf-8
import sys
i = 1
for line in sys.stdin:
line = line.strip()
print("%d %s" % (i, line))
i = i + 1
简单测试:
简单在本地测试一下,运行如下代码:
cat 1 2 3 | python3 mapper.py | python3 reducer.py
输出如下:
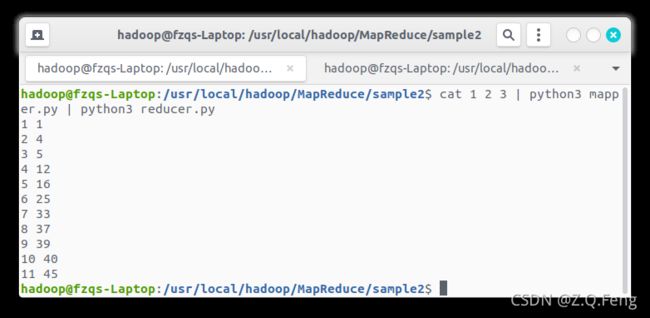
3. 对给定的表格进行信息挖掘
问题如下:
下面给出一个child-parent的表格,要求挖掘其中的父子辈关系,给出祖孙辈关系的表格。
输入文件内容如下:
child parent
Steven Lucy
Steven Jack
Jone Lucy
Jone Jack
Lucy Mary
Lucy Frank
Jack Alice
Jack Jesse
David Alice
David Jesse
Philip David
Philip Alma
Mark David
Mark Alma
输出文件内容如下:
grandchild grandparent
Steven Alice
Steven Jesse
Jone Alice
Jone Jesse
Steven Mary
Steven Frank
Jone Mary
Jone Frank
Philip Alice
Philip Jesse
Mark Alice
Mark Jesse
代码如下:
编写 Map 的 Python 代码如下(mapper.py):
#!/usr/bin/env python3
# encoding=utf-8
import sys
lines = list(sys.stdin)
for line in lines[1:]:
line = line.strip()
child, parent = line.split()
print('%s %s' % (child, parent))
编写 Reduce 的 Python 代码如下(reducer.py):
#!/usr/bin/env python3
# encoding=utf-8
import sys
lines = []
for line in sys.stdin:
line = line.strip()
child, parent = line.split()
lines.append([child, parent])
print('grandchild\tgrandparent')
for line in lines:
c, p = line[0], line[1]
for line in lines:
if line[0] == p:
print('%s\t\t%s' % (c, line[1]))
简单测试:
简单在本地测试一下,运行如下代码:
cat child-parent | python3 mapper.py | python3 reducer.py
输出如下:
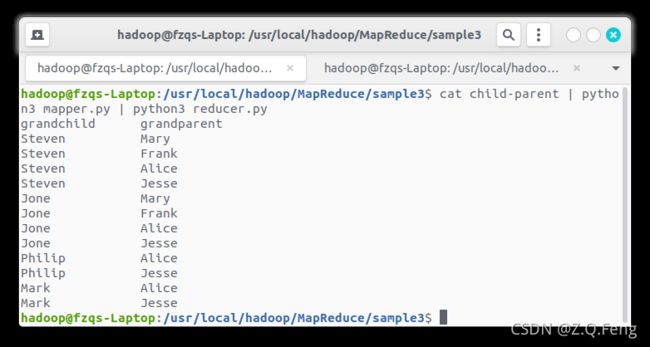
四、在HDFS中运行Python程序
首先启动 Hadoop:
cd /usr/local/hadoop
sbin/start-dfs.sh
创建 input 文件夹,把我们的数据文件传进去(注意这里你的 A、B 数据文件所处的位置):
bin/hdfs dfs -mkdir /input
bin/hdfs dfs -copyFromLocal /usr/local/hadoop/MapReduce/sample1/A /input
bin/hdfs dfs -copyFromLocal /usr/local/hadoop/MapReduce/sample1/B /input
确保 output 文件夹之前不存在:
bin/hdfs dfs -rm -r /output
我们只需要使用 Hadoop 提供的 Jar 包来为我们的 Python 程序提供一个接口就好了,这里我们所使用的 Jar 包一般在此目录下:
ls /usr/local/hadoop/share/hadoop/tools/lib/
找到名为 hadoop-streaming-x.x.x.jar 的包:
hadoop@fzqs-Laptop:/usr/local/hadoop/MapReduce/sample3$ ls /usr/local/hadoop/share/hadoop/tools/lib/
…
hadoop-streaming-3.2.2.jar
…
运行之前,赋予 python 文件相应的权限:
sudo chmod 777 mapper.py
sudo chmod 777 reducer.py
调用此包,把我们本地的 Python 文件作为参数传进去即可(注意这里我的 streaming 包是 3.2.2,看你自己的版本号):
/usr/local/hadoop/bin/hadoop jar /usr/local/hadoop/share/hadoop/tools/lib/hadoop-streaming-3.2.2.jar \
-file /usr/local/hadoop/MapReduce/sample1/mapper.py -mapper /usr/local/hadoop/MapReduce/sample1/mapper.py \
-file /usr/local/hadoop/MapReduce/sample1/reducer.py -reducer /usr/local/hadoop/MapReduce/sample1/reducer.py \
-input /input/* -output /output
查看我们的输出:
bin/hdfs dfs -cat /output/*
输出正确,执行成功:
