论文阅读:Fast-BEV: Towards Real-time On-vehicleBird’s-Eye View Perception
Abstract
- 现有的BEV解决方案要么需要大量的资源执行车载推理,要么效果一般。
- Fast-BEV包含五部分:
1)一个轻量化部署友好的视角转换方式,可以快速将2D图像特征转到3D体素空间。
2)一个多尺度图像编码器利用多尺度特征。
3)高效的BEV编码器,专为车载推理加速。
4)对图像和BEV空间的数据增强(Data Augmentation)策略,以避免过拟合。
5)一种多帧融合机制利用空间信息。
Introduction
- 纯相机鸟瞰方法(Pure camera-based Brid’s-Eye View)遵循一下策略:
- 多相机2D图像特征转车辆坐标下的3D BEV特征。
- 然后在统一的BEV表示形式上用不同的Head执行特定的任务。
- SoTA的BEV方法nuScenes [2] 要么使用基于查询的转换或者基于隐式或显式的深度变换。

- 基于Attention的方法需要特别的复杂芯片支持,基于深度的方法需要不友好的体素池化操作。
- 遵循 M 2 B E V M^2BEV M2BEV[8]的原则:假设在Image-to-BEV的过程中深度沿相机射线均匀分布,我们提出 Fast-Ray Transformation:通过Look-Up-Table和Multi-View到One-Voxel的操作,加速了BEV的转换到一个新的水平。基于快速射线变换,我们进一步提出了Fast-BEV,一种更快更强的全卷积BEV感知框架,而不需要代价更大的Transformer或深度表示。
Methods
Rethink BEV Preception 2D-to-3D Projection
- 基于查询的方法(Query Based)通过Transformer中的注意力机制获得3D BEV特征。这个过程可以展示为:
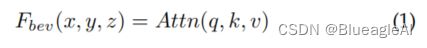
- q,k,v分别为query, key以及value, q ∈ P x y z , k , v ∈ F 2 D ( u , v ) q \in P_{xyz}, k,v \in F_{2D}(u,v) q∈Pxyz,k,v∈F2D(u,v)。
- 基于深度的方法(depth-based)通过计算2D特征与预测深度的外积。
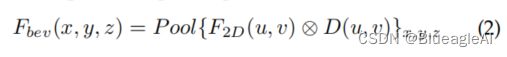
- Pool 是体素(voxel)池化操作(voxel pooling operation)。
Overview of Fast-BEV

- Fast-BEV 输入多摄像头图像作为输入,预测3D Bounding Boxes. 它的主要框架可以分成五个关键部分:
- 从图像空间到体素空间的投影造成延迟,所以提出了快速-射线转换(Fast-Ray Transformation),投影多幅2D图像特征沿相机射线到3D体素,并且有两个操作优化车载平台。
- 我们预先计算固定投影引索并且存储成 Look-Up-Table, 在推理中非常高效。
- 让所有的相机投影到相同体素以避免昂贵的体素聚合(Multi-View to One-Voxel)。
- 多尺度图像编码器(Multi-Scale Image Encoder), 图像编码器通过3层FPN输出结构从统一的单尺度图像输入中获得多尺度图像特征输出。
- 高效的 BEV encoder(Efficient BEV Encoder):实验发现,在快速增加耗时的同时,在3D编码器中使用更多的块(Blocks)和更大的分辨率并不能显著提高模型的性能。除了“space-to-channel”(S2C)外,我们只使用了一层multi-scale concatenation fusion(MSCF)和multi-frame concatenation fusion(MFCF)模块作为BEV编码器,且剩余结构较少的BEV编码器,大大减少了时间消耗,对精度没有损失。
- 数据增强(Data Augmentation):我们增加强数据增强方法在图像和鸟瞰(BEV)空间,比如random flip, rotation etc…
- 时域融合Temporal Fusion. 在自动驾驶场景下,输入图像是连续的,有大量的互补信息。我们通过引入temporal feature fusion module扩展框架到时间域。
Reference
[1] Li Y, Huang B, Chen Z, et al. Fast-BEV: A Fast and Strong Bird’s-Eye View Perception Baseline[J]. arXiv preprint arXiv:2301.12511, 2023.
[2] H. Caesar, V. Bankiti, A. H. Lang, S. Vora, V. E. Liong, Q. Xu, A. Krishnan, Y. Pan, G. Baldan, and O. Beijbom, “nuscenes: A multimodal dataset for autonomous driving,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020,
pp. 11 621–11 631.
[3] Z. Li, W. Wang, H. Li, E. Xie, C. Sima, T. Lu, Q. Yu, and J. Dai, “Bevformer: Learning bird’s-eye-view representation from multicamera images via spatiotemporal transformers,” arXiv preprint arXiv:2203.17270, 2022.
[4] Y. Wang, V. C. Guizilini, T. Zhang, Y. Wang, H. Zhao, and J. Solomon, “Detr3d: 3d object detection from multi-view images via 3d-to-2d queries,” in Conference on Robot Learning. PMLR, 2022, pp. 180–191.
[5] J. Philion and S. Fidler, “Lift, splat, shoot: Encoding images from arbitrary camera rigs by implicitly unprojecting to 3d,” in European Conference on Computer Vision. Springer, 2020, pp. 194–210.
[6] J. Huang, G. Huang, Z. Zhu, and D. Du, “Bevdet: High-performance multi-camera 3d object detection in bird-eye-view,” arXiv preprint arXiv:2112.11790, 2021.
[7] Y. Li, Z. Ge, G. Yu, J. Yang, Z. Wang, Y. Shi, J. Sun, and Z. Li, “Bevdepth: Acquisition of reliable depth for multi-view 3d object
detection,” arXiv preprint arXiv:2206.10092, 2022.
[8] E. Xie, Z. Yu, D. Zhou, J. Philion, A. Anandkumar, S. Fidler, P. Luo, and J. M. Alvarez, “M2bev: Multi-camera joint 3d detection and segmentation with unified birds-eye view representation,” arXiv preprint arXiv:2204.05088, 2022.