压力测试与服务端调优(1)
压力测试与服务端调优
- 环境准备
-
- 数据库
- 秒杀工程
-
- 服务打包
- 服务部署
- 压力测试与性能分析
-
- 压力测试维度
- Jmeter工具
-
- Jmeter下载安装
- 下载Jmeter插件
- 压力测试
-
- 定制压测
- 开始测试
-
- 并发测试
- TPS性能曲线图
- RT(Response Time)
- 聚合报告
- 性能分析
-
- CPU
- 内存
- 磁盘
- 网络
- 服务端调优
-
- Tomcat调优
-
- 问题1
- 问题2
- 问题3
- KeepAlive
- JVM调优
-
- 为什么要进行JVM调优
- 调优原则
- 调优原理
-
- 什么是垃圾?
- 怎么找垃圾?
- 如何清除垃圾?
-
- 标记-清除
- 复制
- 标记-整理
- 分代收集
- 垃圾回收器
-
- 特点
- 常用垃圾回收器组合
- 垃圾回收器原理
-
- Serial + Serial old
- Parallel Scavenge + Parallel old
- ParNew + CMS
- G1
- 内存分代模型
- JVM实战调优
-
- 典型参数设置
- GC日志输出
- GC日志分析
-
- JVM内存使用情况
- 关键指标
- 存在问题
- Full GC频繁发生
- Young & Old 比例
- Eden & S0 & S1
- 总结
- GC组合
-
- 吞吐量优先
- 响应时间优先
- G1
环境准备
数据库
- 使用自己本机的虚拟机安装,虚拟机配置:4核4G。
- MySQL:192.168.254.128:3306
- Redis:192.168.254.128:6379
秒杀工程
- github地址:https://github.com/shouwangyw/vshop-seckill
服务打包
- 这里我们进行服务部署时,采用手动打包的方式,还没有使用 jenkins 来进行打包部署,后面再进行微服务改造时再使用 jenkins 进行打包部署。
- 项目打包的时候: 必须引入以下的插件,否则打包将会出现依赖包无法打包到项目中。
<plugin>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-maven-pluginartifactId>
plugin>
服务部署

- 后端服务部署命令:
# start.sh
nohup java -jar seckill-web.jar --spring.config.addition-location=application.yml > seckill-web.log 2>&1 &
- 注意:
--spring.config.addition-location=application.yml加载外挂配置文件,为了方便服务的部署(本地开发,测试都是使用外网IP进行测试),服务部署必须使用内网IP地址,为了不再重新打包部署,使用外挂的配置文件。 - 外挂配置文件:MySQL 和 Redis 的 IP 都修改为 127.0.0.1

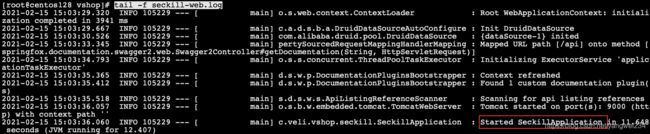
- 查看日志:启动成功
tail -f seckill-web.log
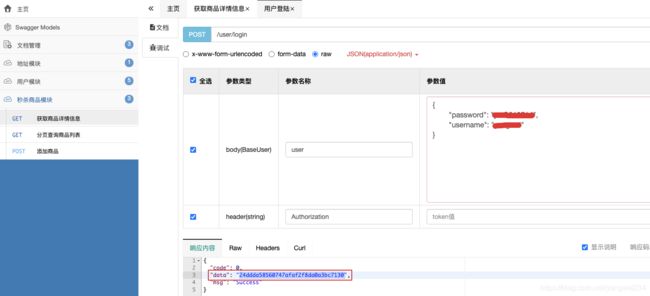
- 测试访问下 swagger 文档地址:http://192.168.254.128:9000/doc.html,首先登陆获取token,然后测一下
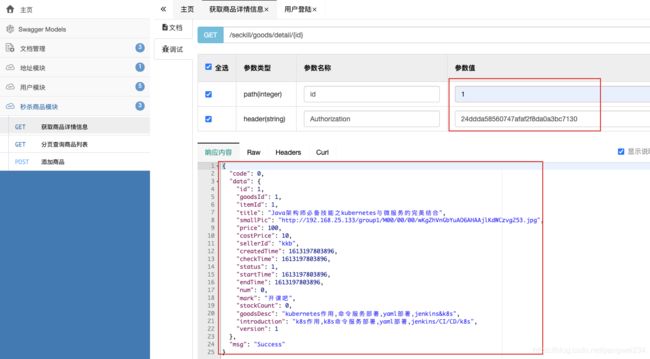
获取商品详情信息的接口:
- 接口是OK的!
压力测试与性能分析
- 压力测试:及时发现系统问题,系统瓶颈(预期系统达到的吞吐能力),及时对系统进行优化改进,对系统的问题进行修复,因此压力测试在整个项目研发中非常重要。
- 架构师:掌握一定的压力测试方法,压力测试是保障软件高质量交付手段之一。主要模拟海量的用户的并发,测试系统在高并发模式下,系统响应时间、TPS、BUG 等问题。
压力测试维度
- 负载测试:确定系统在连续的负载压力模式下(梯形压力施加模式,逐渐增加压力),是否能坚持多少时间;评估系统性能:TPS 。
- 强度测试:极限施压,使得服务器一直处于满负荷的状态;测试系统在满负荷的状态运行情况(运行是否稳定)。
- 容量测试:确定系统可以同时在线的用户数量。
Jmeter工具
- 测试工具:
- AB 测试工具
- ngrinter 压力测试工具
- 阿里云测试服务(阿里云施加机器)
- jmeter工具,可视化的效果
注意问题: 开始压力测试之前,必须思考压力机的问题?施加多大的压力,单机压力是否足够?压力测试干扰问题(网络干扰)。
Jmeter下载安装
- jmeter镜像下载地址:https://jmeter.apache.org/
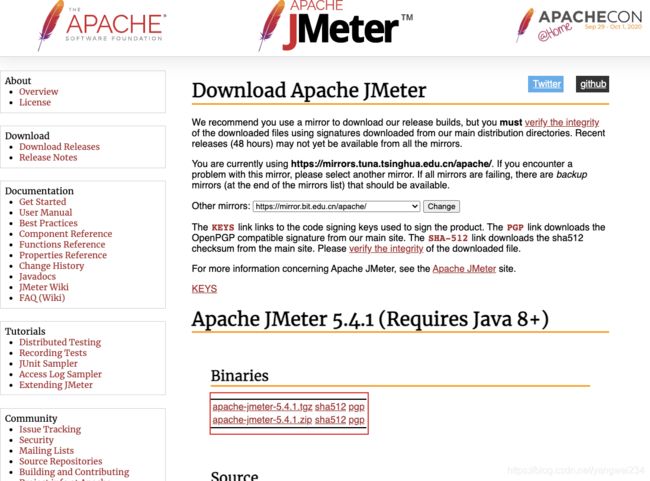
wget https://mirrors.tuna.tsinghua.edu.cn/apache//jmeter/binaries/apache-jmeter-5.4.1.tgz
# 解压到 /Volumes/D/tools/jmeter/ 目录
# jmeter环境变量
export JMETER_HOME=/Volumes/D/tools/jmeter/apache-jmeter-5.4.1
export PATH=$JAVA_HOME/bin:$JMETER_HOME/bin:$PATH
下载Jmeter插件
- 下载地址:http://jmeter-plugins.org/downloads/all/,官网上下载 plugins-manager.jar 直接在线下载,然后执行在线下载即可。
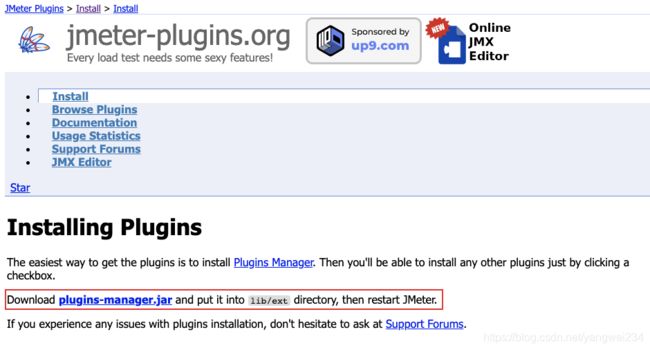
- 注意:下载插件在英文模式下下载,如果在中文模式下下载,貌似不好使
主要插件介绍:
1、PerfMon:监控服务器硬件,如CPU,内存,硬盘读写速度等
2、Basic Graphs:主要显示平均响应时间,活动线程数,成功/失败交易数等
3、Additional Graphs:主要显示吞吐量,连接时间,每秒的点击数等
...
添加响应时间:事务控制器_添加_监听器_jp@gc – Response Times Over Time
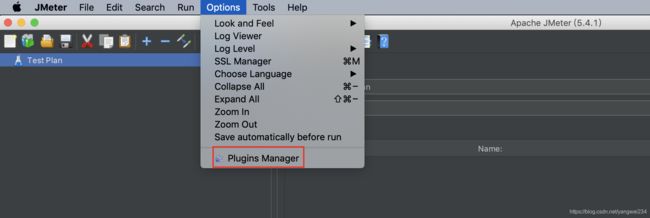
- 在线下载方法如下图所示:

- 还可以选择jmter语言:
- 修改jmeter默认语言:
vim jmeter.properties

压力测试
定制压测
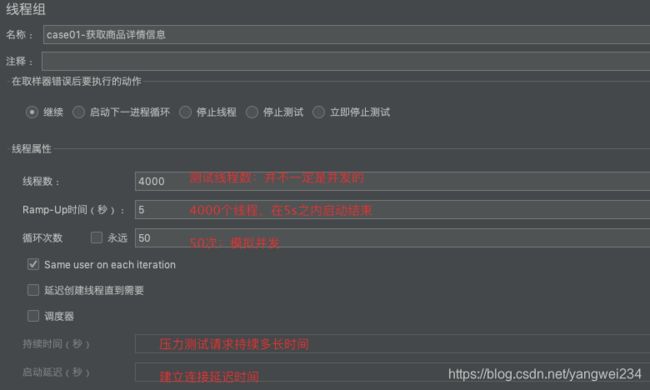
- 新建测试计划:

- 添加取样器:为了方便测试,这里将代码中拦截器配置去掉了,即不需要token校验。

- 继续添加监听器:察看结果树、聚合报告、TPS、RT等
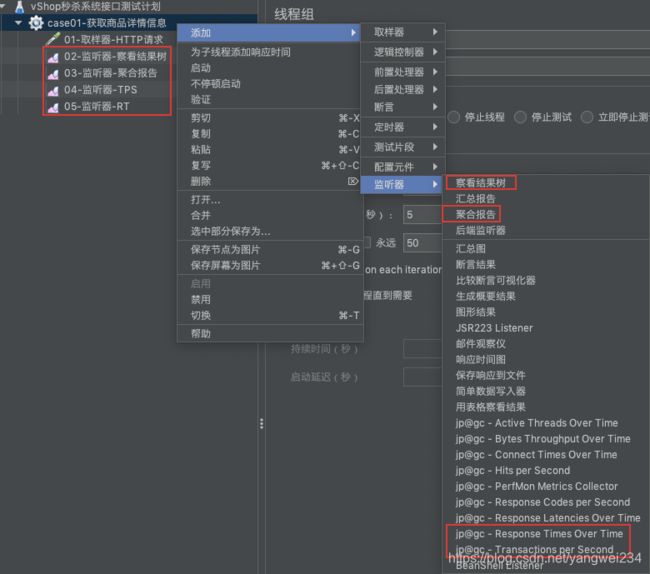
开始测试
- 使用jmeter进行压力测试,查看几个性能指标: TPS、RT、聚合报告。
并发测试
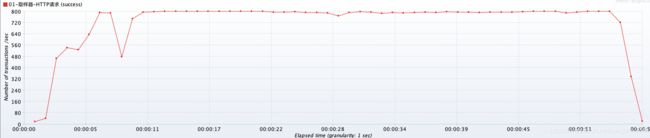
TPS性能曲线图
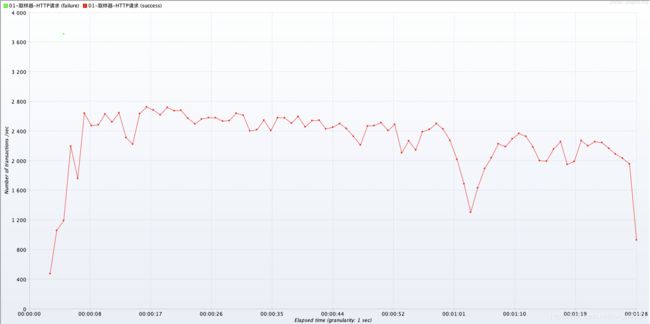
- 根据 TPS 性能曲线图:TPS 在 2400 左右,目前该接口只是做了一个简单的主键查询。
- TPS:从发送请求到获取到响应结果的一次请求,叫做一次 TPS。
- QPS:每秒查询数,大多数的情况下,QPS = TPS。
- 例如:访问一个页面 /index.html 是,可能还要加载一些 js、css,那么 QPS = 3、TPS = 1。如果把聚焦的点:主关注接口,QPS = TPS。
RT(Response Time)
- RT:一个请求从发送到响应耗时。
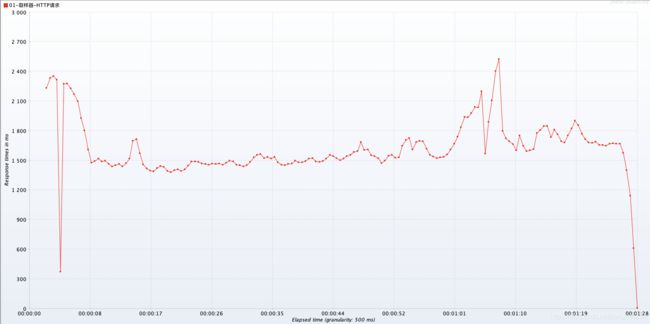
- 可以看到,大部分请求都在 1、2 秒左右返回,响应时间并不是很理想。主要是因为服务部署在本地 VMware 虚拟机,测试机也都是在本地。
聚合报告
![]()
- #样本: 20w 个样本
- #平均值:所有请求平均耗时 1576ms
- #中位数:50%的请求在 1552ms 之内响应结束
- #90%百分位:90%的请求在 1876ms 之内响应结束
- #最小值:请求的最小耗时 0ms
- #最大值:请求的最大耗时 10018ms
- #异常率:发送异常频率
性能分析
系统出现问题分类:
- 系统异常:CPU占用率高、磁盘满了、磁盘IO频繁、网络流量异常等;排查指令:top、free、dstat、pstack、vmstat、strace 获取异常信息,排查系统异常情况。
- 业务异常:流量太多系统扛不住、耗时长、线程死锁、多线程并发问题、频繁full gc、oom等;排查指令:top、jstack、pstack、strace、日志等。
CPU
- top 指令监控 CPU 使用情况,根据 CPU 使用情况分析系统整体运行情况:

- 关注指标:load average 代表系统的繁忙程度,三个参数分别是 1 分钟、5 分钟、15 分钟 CPU 的平均负载。
- 单核CPU:
- Load average < 1 , cpu比较空闲,没有出现线程等待cpu执行现象;
- Load average = 1 , cpu刚刚占满,没有空闲空间;
- Load average > 1 , cpu已经出现了线程等待,比较繁忙;
- Load average > 3 , cpu阻塞非常严重,出现了严重线程等待,必须进行优化处理。
- 4和CPU:
- Load average < 4 , cpu比较空闲,没有出现线程等待cpu执行现象;
- Load average = 4 , cpu刚刚占满,没有空闲空间;
- Load average > 4 , cpu已经出现了线程等待,比较繁忙;
- Load average > 9 , cpu阻塞非常严重,出现了严重线程等待,必须进行优化处理。
内存
- free 指令排查线上问题重要指令,内存问题很多时候是引起 CPU 较高的原因。

磁盘
- df 指令查看磁盘使用情况,有时候服务出现问题,可能就是磁盘不够了。
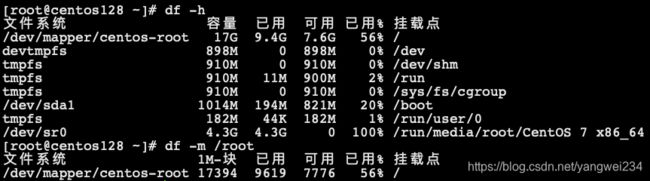
网络
- dstat 指令:其集成了 vmstat、iostat、netstat 等工具的特色。使用该命令需要先进行安装:
yum install dstat
- -c 查看cpu情况;-d 磁盘读写;-n 网络状态;-l 显示系统负载…

服务端调优
Tomcat调优
问题1
服务调优是在什么时间点介入调优?
测试发现问题:解决业务异常,也有一部分调优;而调优更多的时候,是在上线以后介入调优。
- Tomcat 服务器:是我们现在使用的内置服务器,默认的线程数?最大连接数?
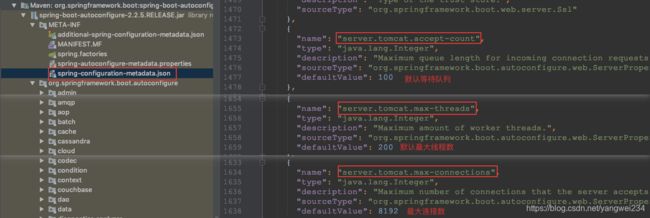
问题2
修改以上参数的大小,是否可以提升tomcat服务器性能?
答案:不考虑其他因数(硬件资源限制),改大tomcat最大线程数、最大连接数、等待队列数,理论上一定是可以提升服务器性能。
- Tomcat参数原理分析:
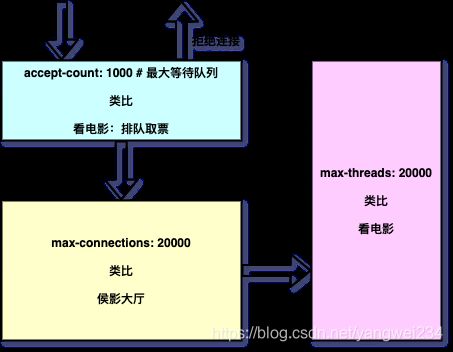
- 优化配置:最大线程数提升4倍
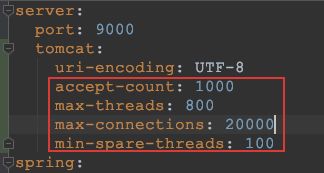
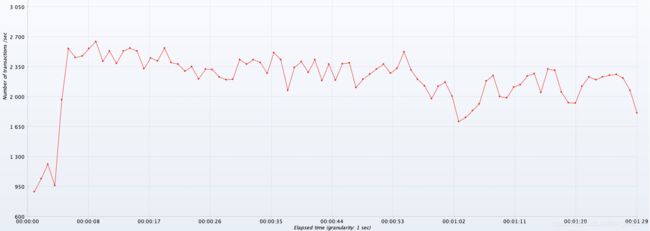
问题3
优化后的TPS并没有太大变化,是什么原因?
业务代码没有任何业务执行,只执行业主键查询,主键查询是数据库最快的查询方式,耗时0-10ms,因此此操作不是一个耗时操作,不耗时不需要调优
- 修改业务代码,模拟耗时操作,然后重新打包部署
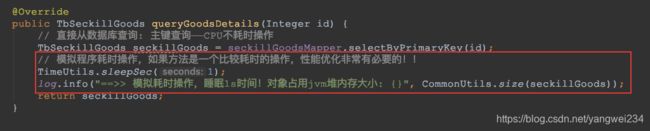
- tomcat配置没有做优化前的TPS:稳定在 200 左右
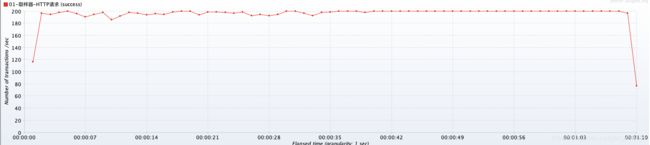
- tomcat配置优化后的TPS:可以发现TPS提升4倍,变成了800个TPS
KeepAlive
- 客户端和服务器连接的时候,为了防止频繁建立连接,释放连接,浪费资源,这样会消耗资源造成性能下降。
- Jmeter使用长连接进行测试:
- 问题:keep-alive 连接数是否是越多越好呢?
- 答案:keep-alive 连接本身消耗大量的资源,如果不能及时释放,系统TPS就上不去,因此 keep-alive 连接数也必须要设置一个合理的连接数。
@Configuration
public class WebServerConfig implements WebServerFactoryCustomizer<ConfigurableWebServerFactory> {
@Override
public void customize(ConfigurableWebServerFactory factory) {
// 获取tomcat连接器
((TomcatServletWebServerFactory) factory).addConnectorCustomizers((TomcatConnectorCustomizer) connector -> {
// 获取protocol
Http11NioProtocol protocolHandler = (Http11NioProtocol) connector.getProtocolHandler();
// 如果keepalive连接30s,还没有人使用,释放此链接
protocolHandler.setKeepAliveTimeout(30000);
// 允许开启最大长连接数量
protocolHandler.setMaxKeepAliveRequests(10000);
});
}
}
JVM调优
为什么要进行JVM调优
问题1:项目上线后,是什么原因促使必须进行jvm调优?
答案:调优的目的就是提升服务性能
- JVM 堆内存空间对象太多(Java线程、垃圾对象),导致内存被占满,程序跑不动—性能严重下降。
- 调优:及时释放内存
- 垃圾回收线程太多,频繁回收垃圾(垃圾回收线程也会占用内存资源,抢占cpu资源),必然会导致程序性能下降
- 调优:防止频繁GC
- 垃圾回收导致 STW (stop the world)
- 调优:尽可能的减少 GC 次数
问题2:JVM 调优本质是什么?
答案: JVM 调优的本质就是(对内存的调优) 及时回收垃圾对象,释放内存空间;让程序性能得以提升,让其他业务线程可以获得更多内存空间。
问题3:是否可以把 JVM 内存空设置的足够大(无限大),是不是就不需要垃圾回收呢?
前提条件:内存空间被装满了以后,才会触发垃圾回收器来回收垃圾。
理论上是的,现实情况不行的!
寻址能力:(是否有这么大的空间)32位操作系统 —— 4GB 内存;64位操作系统 —— 16384 PB 内存空间
- 堆内存空间大小的设置:必须设置一个合适的内存空间,不能太大,也不能太小。
- 考虑到寻址速度的问题,寻址一个对象消耗的时间比较长的;一旦触发垃圾回收,将会是一个灾难。(只能重启服务器)。
调优原则
- 原则一:GC 的时间足够小:JVM 堆内存设置足够小。
- 垃圾回收时间足够小,意味着 JVM 堆内存空间设置小一些,这样的话,垃圾对象寻址的时候消耗的时间就非常短,然后整个垃圾回收非常快速。
- 原则二:GC 的次数足够少:JVM 堆内存设置足够大。
- GC 次数足够少,JVM 堆内存空间必须设置的足够大,这样垃圾回收触发次数就会相应减少。
- 原则一、原则二 是相互冲突的,因此需要权衡,内存空间既不能设置太大,也不能设置太小。
- 原则三:发生 Full GC 周期足够长:最好不发生 Full GC。
- MetaSpace 永久代空间设置大小合理,MetaSpace 一旦扩容,就会发生 Full GC;
- 年代空间设置一个合理的大小,防止 Full GC;
- 尽量让垃圾对象在年轻代被回收(90%);
- 尽量防止大对象的产生,一旦大对象多了以后,就可能发生 Full GC,甚至 OOM。
调优原理
- 参考我的另一篇博文:https://blog.csdn.net/yangwei234/article/details/84778681
什么是垃圾?
- JVM调优的本质:回收垃圾,及时释放内存空间,但是什么是垃圾?
- 在内存中间中,那些没有被引用的对象就是垃圾(高并发模式下,大量的请求在内存空间中创建了大量的对象,这些对象并不会主动消失,因此必须进行垃圾回收,当然 Java 垃圾回收不需要我们自己编写垃圾回收代码,Java 提供各种垃圾回收器帮助回收垃圾,JVM垃圾回收是自动进行的)。
- 一个对象的引用消失了,这个对象就是垃圾,因此此对象就必须被垃圾回收器进行回收,及时释放内存空间。
怎么找垃圾?
- JVM 提供了2种方式找到这个垃圾对象:引用计数算法、根可达算法(hotspot 垃圾回收器都是使用这个算法)。
- 引用计数算法:对每一个对象的引用数量进行一个计数,当引用数为0时,那么此对象就变成了一个垃圾对象。
- 不能解决循环引用的问题,如果存在循环引用的话,无法发现垃圾。
- 根可达算法:根据根对象向下进行遍历,如果遍历不到的对象就是垃圾。
如何清除垃圾?
- JVM提供了3种方式清除垃圾,分别是:
- mark-sweep:标记-清除算法
- coping:复制算法
- mark-compact:标记-整理(压缩)算法
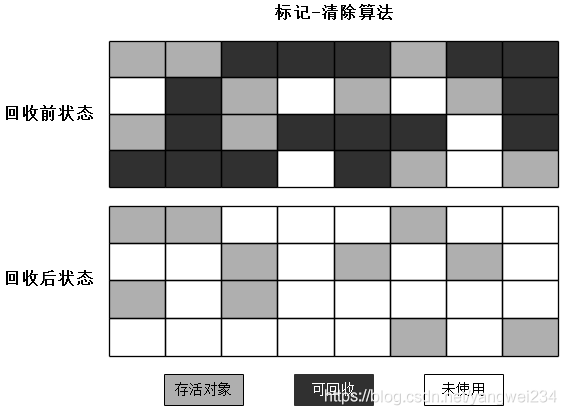
标记-清除
- 该算法分为”标记“和”清除“两个阶段:首先标记所有需要回收的对象,在标记完成后统一回收所有垃圾。
- 缺点:效率不高,标记和清除两个过程的效率都不高;产生碎片,碎片太多会导致提前GC。
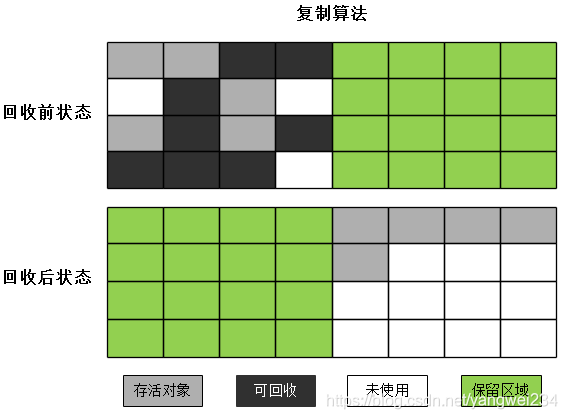
复制
- 该算法将可用内存按容量划分为大小相等的两块,每次只是用其中的一块,当这一块的内存用完了,就将还存活着的对象复制到另外一块上面,然后再把已使用过的内存空间一次清除掉(Young区就是使用的这种算法)。
- 优缺点:实现简单,运行高效,但是空间利用率低。
标记-整理
- 标记过程仍然与”标记-清除“算法一样,但后续步骤不是直接对可回收对象进行清理,而是让所有存活的对象都向一端移动,然后直接清理掉端到边界以外的内存。
- 优缺点:没有了内存碎片,但是整理内存比较耗时。
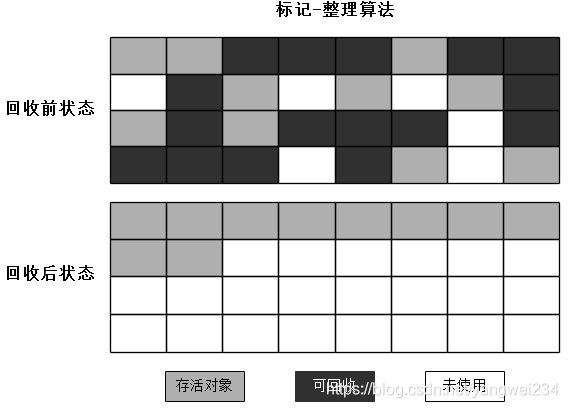
分代收集
- 在新生代中,每次垃圾收集时都发现有大批对象死去,只有少量存活,那就选用复制算法;
- 而老年代中因为对象存活率高、没有额外空间对它进行分配担保,就必须使用”标记-清除“或”标记-整理“算法进行收回。
垃圾回收器
- Java提供很多的垃圾回收器:10种垃圾回收器。

- 串行回收器:Serial、Serial old
- 并行回收器:ParNew、Parallel Scavenge、Parallel old
- 并发回收器:CMS、G1(分区算法)
特点
- Serial、Serial old、ParNew、Parallel Scavenge、Parallel old、CMS 都属于物理分代垃圾收集器;年轻代、老年代分别使用不同的垃圾回收器。
- Serial、Serial old 是串行化的垃圾回收器。
- ParNew、CMS 组合是并行、并发的垃圾回收器。
- Parallel Scavenge、Parallel old 是并行的垃圾回收器
- G1是在逻辑上进行分代的,因此在使用上非常方便,关于年轻代、老年代只需要使用一个垃圾回收器即可。
- ZGC是一款JDK 11中新加入的具有实验性质的低延迟垃圾收集器。
- Shenandoah 是 OpenJDK 的垃圾回收器。
- Epsilon 是 Debug 使用的,调试环境下,验证 JVM 内存参数设置的可行性。
常用垃圾回收器组合
- Serial + Serial old:是串行化的垃圾回收器,适合单核心的 CPU 的情况;
- ParNew + CMS:是响应时间优先组合;
- Parallel Scavenge + Parallel old:是吞吐量优先组合。
- G1:逻辑上分代的垃圾回收器组合。
垃圾回收器原理
Serial + Serial old
- Serial 是年轻代的垃圾回收器,单线程的垃圾回收器;Serial Old 是老年代的垃圾回收器,也是一个单线程的垃圾回收器,适合单核心的 CPU。
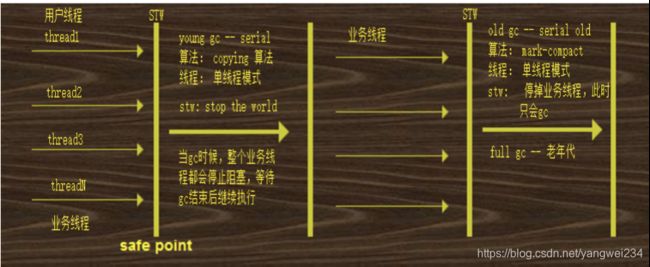
- 注意特点:
- STW:当进行 GC 的时候,整个业务线程都会被停止,如果 STW 时间过长,或者 STW 发生次数过多,都会影响程序的性能。
- 垃圾回收器线程:多线程、单线程、并发、并行。
Parallel Scavenge + Parallel old
- 并行的垃圾回收器,是吞吐量优先的垃圾回收器组合,是JDK8默认的垃圾回收器。
什么是并发、并行?
并发:在一段时间内,多个线程抢占 CPU 的执行,并发执行,这些线程就叫并发线程。
并行:多个线程在同一时刻,在多个 CPU 上同时执行,这些线程叫做并行线程。
- PS + PO 回收垃圾的时候,采用的多线程模式回收垃圾。
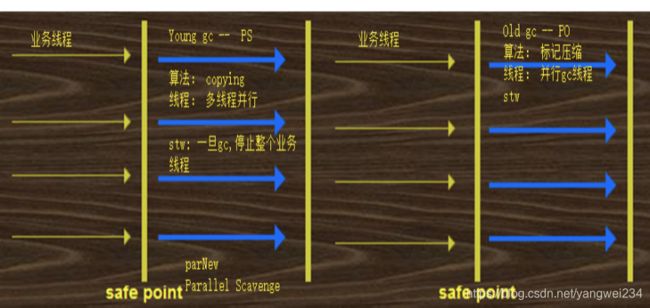
- 注意特点:
- STW:当进行 GC 的时候,整个业务线程都会被停止,如果 STW 时间过长,或者 STW 发生次数过多,都会影响程序的性能。
- 垃圾回收器线程:多线程、单线程、并发、并行。
ParNew + CMS
- ParNew 是并行垃圾回收器,年轻代的垃圾回收器;CMS 是并发垃圾回收器,回收老年代的垃圾。
- CMS 是响应时间优先的垃圾回收器,充分考虑了 STW 时间的问题,减少 STW 的时间,延长业务执行时间。
- 注意:任何的垃圾回收器都无法避免 STW,因此 JVM 调优实际上就是调整 STW 的时间。
G1
- 使用G1收集器时,它将整个Java堆划分成约2048个大小相同的独立 Region 块,每个 Region 块大小根据堆空间的实际大小而定,整体被控制 在1MB到32MB之间,且为2的N次幂,即1MB、2MB、4MB、8MB、16MB、32MB。可以通过
-XX:G1HeapRegionsize设定。 - 所有的Region大小相同,且在JVM生命周期内不会被改变。
内存分代模型
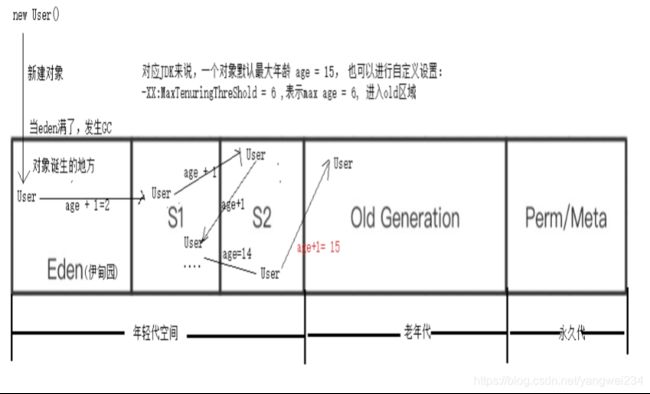
- 通过内存分代模型结构:大多数对象都会在年轻代被回收掉(90%+),很多对象都在15次的垃圾回收中被回收掉了,只有超过15次还没被回收掉的才会进入到老年代区域。
- 垃圾回收触发的时机:
- PS+PO:当堆内存被装满了,才会触发垃圾回收(eden区域满了,触发了垃圾回收;old区域满了,触发垃圾回收)。
- CMS:JDK1.5 时,当 eden 区域装对象达到68%时候,就会触发垃圾回收;JDK1.6+时,92% 才会触发垃圾回收器。
一个新对象被创建了,但是这个对象是一个大对象(查询全表),eden区域已经放不下了,此时会发生什么?

JVM实战调优
- 明确 JVM 调优的本质:GC-垃圾回收,及时释放内存空间;GC 次数要少,GC 时间少,防止 Full GC。进行内存参数设置。
典型参数设置
服务器硬件配置:4cpu、8GB 内存 — jvm调优内存,考虑内存。
- -Xmx4000m:设置 JVM 最大堆内存(经验值:3500m ~ 4000m,内存设置大小,没有一个固定的值,根据业务实际情况来进行设置的,根据压力测试、性能反馈情况,去做参数调试);
- -Xms4000m:设置 JVM 堆内存初始化的值,一般情况下,初始化的值和最大堆内存值必须一致,防止内存抖动;
- -Xmn2g:设置年轻代内存对象(eden、s1、s2);
- -Xss256k:设置线程栈大小,JDK 1.5+ 版本线程栈默认是 1MB,相同的内存情况下,线程堆栈越小,操作系统创建的线程越多。
# 4核4G
nohup java -Xmx2000m -Xms2000m -Xmn1g -Xss256k -jar seckill-web.jar --spring.config.addition-location=application.yml > seckill-web.log 2>&1 &
- 再次进行压力测试:查看在此内存设置模式下性能情况。
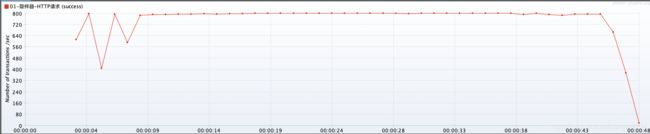
- 根据压力测试结果,发现JVM参数设置,和之前没有设置吞吐能力没有太大的变化,因为测试样本不足以造成 GC、Full GC 时间上的差异。
问题:根据什么标准判断参数设置是否合理呢?根据什么指标进行调优呢?
- 发生几次 GC、是否频繁的发送GC?是否发生 Full GC、Full GC 发生是否合理?GC 的时间是否合理?OOM?
GC日志输出
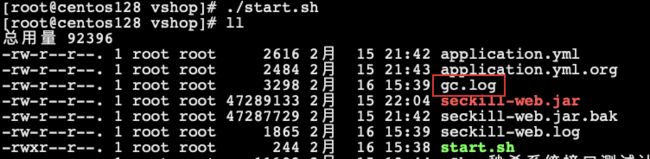
- 启动命令:
nohup java -Xmx2000m -Xms2000m -Xmn1g -Xss256k -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintGCDateStamps -XX:+PrintHeapAtGC -Xloggc:gc.log -jar seckill-web.jar --spring.config.addition-location=application.yml > seckill-web.log 2>&1 &
- 输出GC日志的参数说明:
- -XX:+PrintGCDetails 打印 GC 详细信息
- -XX:+PrintGCTimeStamps 打印 GC 时间信息
- -XX:+PrintGCDateStamps 打印 GC 日期信息
- -XX:+PrintHeapAtGC 打印 GC 堆内存信息
- -Xloggc:gc.log 把 GC信息输出到 gc.log 文件中
- 执行启动命令后,就会产生 GC 日志:
GC日志分析
- 可以使用 GCeasy进行 GC日志分析:导入gc.log 进行在线分析即可。
JVM内存使用情况

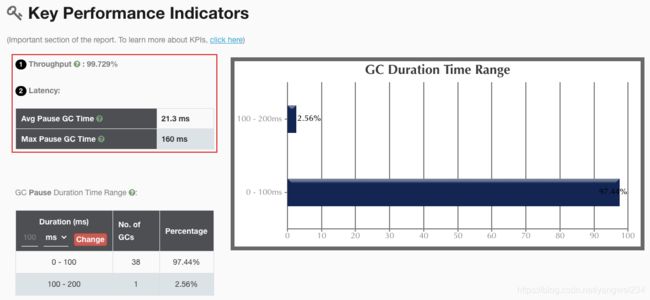
关键指标

- 总结:可以发现业务线程执行时间占比达到99%+,说明 GC 时间在整个业务执行期间所占用的时间非常少,几乎不会影响程序性能;导致业务线程执行时间占比高的原因是:
- 程序样本数不够;
- 程序运行的时间不够;
- 业务场景不符合要求(查询没有太多的对象数据)
存在问题
- 在一开始就发生了FullGC:
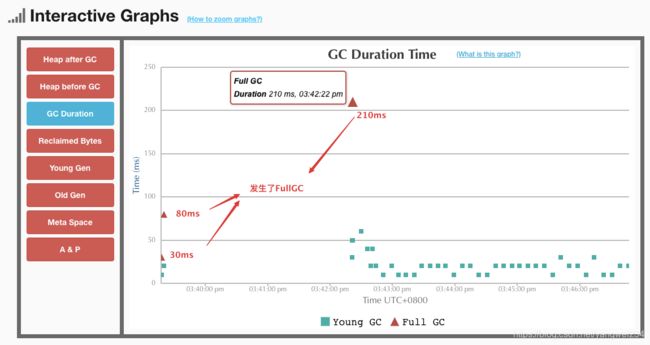
- GC 详细数据分析:
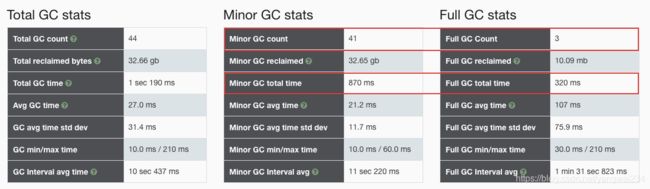
Full GC频繁发生
- 查询 GC 内存模型:
jstat -gcutil PID查询此进程的内存模型

- Metaspace 永久代空间:默认为 20 M(初始化大小),当 Metaspace 被占满后,就会发生扩容,一旦metaspace 发生一次扩容,就会同时发送一次 Full GC。
- 启动命令:参数设置
-XX:MetaspaceSize=256m
nohup java -Xmx2000m -Xms2000m -Xmn1g -Xss256k -XX:MetaspaceSize=256m -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintGCDateStamps -XX:+PrintHeapAtGC -Xloggc:gc.log -jar seckill-web.jar --spring.config.addition-location=application.yml > seckill-web.log 2>&1 &
- 调整参数后,重启项目,并进行压力测试,重新生成 GC 日志,并进行分析
- 经过参数调优后,发现 Full GC 已经没有发生了。

Young & Old 比例
- Sun公司推荐设置:整个堆的大小 = 年轻代 + 老年代 + 永久代(256m),推荐年轻代占整个堆内存 3/8, 因此当整个堆内存设置大小为 2000m 时,也就是说年轻代大小应该设置为 750m。
- 所以,定义年轻代 -Xmn750m,剩下的空间就是老年代空间。或者定义参数 -XX:NewRatio=4,表示年轻代(eden、s0、s1)和老年代区域占比是 1:4。
- 年轻代大小、老年代大小比值可以根据业务实际情况设置比例,通过设置相应的比例来减少相应 YoungGC、Full GC。
- 启动命令:修改参数
-Xmn750m
nohup java -Xmx2000m -Xms2000m -Xmn750m -Xss256k -XX:MetaspaceSize=256m -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintGCDateStamps -XX:+PrintHeapAtGC -Xloggc:gc.log -jar seckill-web.jar --spring.config.addition-location=application.yml > seckill-web.log 2>&1
- 调整参数后,重启项目,并进行压力测试,重新生成 GC 日志,并进行分析

- Young GC 增多了几次,但是在 JVM调优的原则中:要求尽量防止 Full GC 的发生,因此可以把 Full GC 设置的稍微大一些,意味着 Old 区域装载对象很长时间才能装满(或者永远都装不满),发生 Full GC 概率就非常小。
Eden & S0 & S1
- 官方给定设置:可以设置 eden、s 区域大小为 8:1:1,即 -XX:SurvivorRatio=8。
- 此调优的原理:尽量让对象在年轻代被回收,调大了eden区域的空间,让更多对象进入到 eden 区域,触发 GC 时,更多的对象被回收。
- 启动命令:增加参数
-XX:SurvivorRatio=8
nohup java -Xmx2000m -Xms2000m -Xmn750m -Xss256k -XX:MetaspaceSize=256m -XX:SurvivorRatio=8 -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintGCDateStamps -XX:+PrintHeapAtGC -Xloggc:gc.log -jar seckill-web.jar --spring.config.addition-location=application.yml > seckill-web.log 2>&1 &
- 调整参数后,重启项目,并进行压力测试,重新生成 GC 日志,并进行分析

- 发现 Young GC 次数和时间有所减少和降低。
总结
- JVM 调优(调整 JVM 内存大小、比例),降低 GC 次数,减少 GC 时间,从而提升服务性能。
- 调优标准:项目上线后,遇到问题,调优。
- GC 消耗时间:业务时间占比
- 频繁发生 Full GC:调优 STW——程序暂停时间比较长,发生阻塞可能导致整个程序崩溃
- OOM:调优
GC组合
吞吐量优先
- 并行的垃圾回收器:Parallel Scavenge(年轻代) + Parallel Old(老年代) ---- 是JDK默认的垃圾回收器。
- 显式的配置PS+PO垃圾回收器:-XX:+UseParallelGC -XX:+UseParallelOldGC。

响应时间优先
- 并行垃圾回收器(年轻代),并发垃圾回收器(老年代) :ParNew + CMS (响应时间优先垃圾回收器)。
- 显式配置:ParNew + CMS 垃圾回收器组合:-XX:+UseParNewGC -XX:+UseConcMarkSweepGC。

- CMS 只有在发生 Full GC 时才起到作用,CMS一般情况下不会发生,因此在 JVM 调优原则中表示尽量防止发生 FullGC,因此 CMS 在 JDK14 已经被废弃。
G1
- G1 垃圾回收器是逻辑上分代模型,使用配置简单。
- 显式配置:-XX:+UseG1GC

- 调整参数后,重启项目,并进行压力测试,重新生成 GC 日志,并进行分析

- 经过测试,发现 G1 GC 次数减少了,但是 GC 总时长增加很多;时间增加,意味着服务性能就没有提升上去。