4.Python数据分析项目之广告点击转化率预测
1.总结
| 流程 | 具体操作 |
|---|---|
| 基本查看 | 查看缺失值(可以用直接查看方式isnull、图像查看方式查看缺失值missingno)、查看数值类型特征与非数值类型特征、一次性绘制所有特征的分布图像 |
| 预处理 | 缺失值处理(填充)拆分数据(获取有需要的值) 、统一数据格式、特征工程(特征编码、0/1字符转换、自定义) 、特征衍生、降维(特征相关性、PCA降维) |
| 数据分析 | groupby分组求最值数据、seaborn可视化 |
| 预测 | 拆分数据集、建立模型(RandomForestRegressor、LogisticRegression、GradientBoostingRegressor、RandomForest)、训练模型、预测、评估模型(ROC曲线、MSE、MAE、RMSE、R2)、调参(GridSearchCV) |
数量查看:条形图
占比查看:饼图
数据分区分布查看:概率密度函数图
查看相关关系:条形图、热力图
分布分析:分类直方图(countplot)、分布图-带有趋势线的直方图(distplot)
2.项目背景
广告投放效果通常通过曝光、点击和转化各环节来衡量,大多数广告系统受广告效果数据回流的限制只能通过曝光或点击作为投放效果的衡量标准开展优化。
本项目以腾讯移动App广告为研究对象,预测App广告点击后被激活的概率:pCVR=P(conversion=1 | Ad,User,Context),即给定广告、用户和上下文情况下广告被点击后发生激活的概率。
3.数据解释
- 训练数据
从腾讯社交广告系统中某一连续两周的日志中按照推广中的App和用户维度随机采样。每一条训练样本即为一条广告点击日志(点击时间用clickTime表示),样本label取值0或1,其中0表示点击后没有发生转化,1表示点击后有发生转化,如果label为1,还会提供转化回流时间(conversionTime)。 - 转化回流时间
App 的激活定义为用户下载后启动了该App,即发生激活行为。从用户点击广告到广告系统得知用户激活了App(如果有),通常会有较长的时间间隔回流时间表示了广告主把App激活数据上报给广告系统的时间,回流时间超过5天的数据会被系统忽略。 值得注意的是,训练数据提供的截止第31天0点的广告日志,因此,对于最后几天的训练数据,某些label=0并不够准确,可能广告系统会在第31天之后得知label实际上为1 - 特征数据解释



特别地,出于数据安全的考虑,对于userID,appID,特征,以及时间字段,我们不提供原始数据,按照如下方式加密处理:

- 训练数据文件(train.csv)
每行代表一个训练样本,各字段之间由逗号分隔,顺序依次为:“label,clickTime,conversionTime,creativeID,userID,positionID,connectionType,telecomsOperator”。当label=0时,conversionTime字段为空字符串。特别的,训练数据时间范围为第17天0点到第31天0点(定义详见下面的“补充说明”)。为了节省存储空间,用户、App、广告和广告位相关信息以独立文件提供(训练数据和测试数据共用),具体如下:

注:若字段取值为0或空字符串均代表未知。(站点集合ID(sitesetID)为0并不表示未知,而是一个特定的站点集合。) - 测试数据文件(test.csv)
从训练数据时段随后1天(即第31天)的广告日志中按照与训练数据同样的采样方式抽取得到,测试数据文件(test.csv)每行代表一个测试样本,各字段之间由逗号分隔,顺序依次为:“instanceID,-1,clickTime,creativeID,userID,positionID,connectionType,telecomsOperator”。其中,instanceID唯一标识一个样本,-1代表label占位使用,表示待预测。
评估方式(逻辑回归损失函数)
通过Logarithmic Loss评估(越小越好),公式如下:
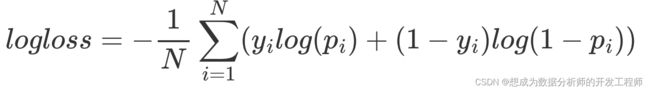
其中,N是测试样本总数,yi是二值变量,取值0或1,表示第i个样本的label,pi为模型预测第i个样本 label为1的概率。
评估公式的Python代码如下:
import scipy as sp
def logloss(act, pred):
epsilon = 1e-15
pred = sp.maximum(epsilon, pred)
pred = sp.minimum(1-epsilon, pred)
ll = sum(act*sp.log(pred) +sp.subtract(1,act)*sp.log(sp.subtract(1,pred)))
ll = ll * -1.0/len(act)
return ll
4.Baseline(基线版本)模型(基于AD统计)
什么是基线版本
- 基线是软件文档或源码(或其它产出物)的一个稳定版本,它是进一步开发的基础.
- 先快速建立一个简单的模型 然后在模型的基础上进行优化
两个基线版本
本项目实现两个基线版本 - 基于AD统计的版本——不使用模型,只是简单的根据统计预测
- AD+LR(逻辑回归)版本
4.1 Baseline模型(AD统计版本)
不使用模型,只是简单的根据统计预测
import numpy as np
import pandas as pd
import warnings
warnings.filterwarnings('ignore') # 忽略警告信息
# 1.加载数据
train = pd.read_csv('data/train.csv')
test = pd.read_csv('data/test.csv')
ad = pd.read_csv('data/ad.csv')# 广告数据
# 2.合并数据集
train = pd.merge(train, ad, on='creativeID') # 根据“素材ID”合并train和ad
test = pd.merge(test, ad, on='creativeID') # 根据“素材ID”合并test和ad
y_train = train['label'].values # 获取训练数据集的标签
# 3.统计处理(代替建模)
# 先计算出根据appID分组聚合计算出每种的平均值,再根据appID合并数据表,作为预测值
cvr = train.groupby("appID").apply(lambda df:np.mean(df['label'])).reset_index()
cvr.columns = ['appID','avg_cvr']
test = pd.merge(test, cvr, how='left', on='appID') # 测试集与cvr左外连接
# 对test中的“avg_cvr”列为空的数据填充
test['avg_cvr'].fillna(np.mean(train['label']),inplace=True)
proba_test = test['avg_cvr'].values # avg_cvr列提取出来,作为预测概率
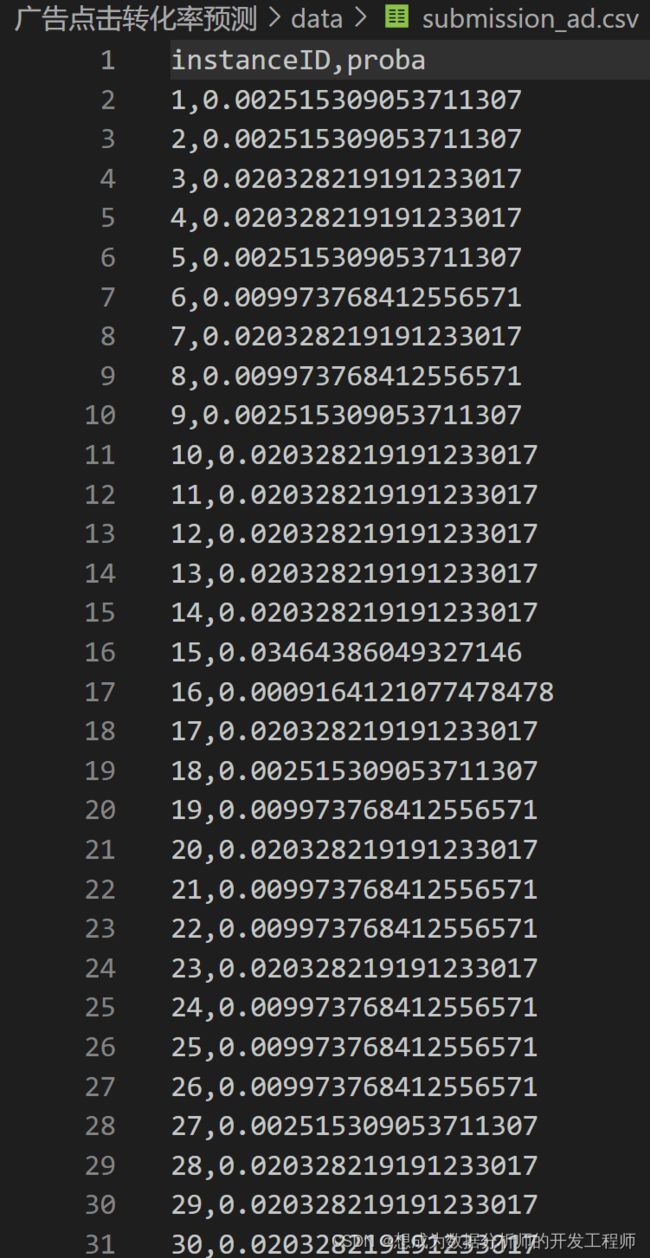
# 4.保存结果
# 创建dataframe
df = pd.DataFrame({'instanceID':test['instanceID'].values,
'proba':proba_test})
# 根据instanceID排序
df.sort_values("instanceID", inplace=True)
# 结果保存到CSV文件中
df.to_csv("data/submission_ad.csv", index=False)
合并数据后的train

合并数据后的test

预测结果的保存
4.2Baseline模型(基于AD+LR逻辑回归的版本)
from scipy import sparse
from sklearn.preprocessing import OneHotEncoder # 机器学习中的onehot编码方法
from sklearn.linear_model import LogisticRegression # 逻辑回归
# 1.加载数据
train = pd.read_csv('data/train.csv')
test = pd.read_csv('data/test.csv')
ad = pd.read_csv('data/ad.csv')# 广告数据
# 2.合并数据集
train = pd.merge(train, ad, on='creativeID') # 根据“素材ID”合并train和ad
test = pd.merge(test, ad, on='creativeID') # 根据“素材ID”合并test和ad
y_train = train['label'].values # 获取训练数据集的标签
# 3.特征工程(one-hot编码)
enc = OneHotEncoder()
# 对这些特征进行one-hot编码
feats = ['appID', 'appPlatform']
for i, feat in enumerate(feats):
# 使用训练数据集的对应特征进行拟合并进行one-hot编码转换
x_train = enc.fit_transform(train[feat].values.reshape(-1,1))
# 对测试集直接进行转换(只能是训练集中存在的特征值进行one-hot编码转换)
x_test = enc.transform(test[feat].values.reshape(-1,1))
# 如果遍历到第一个特征(“appID特征”)
if i == 0:
X_train, X_test = x_train, x_test
else:
X_train, X_test = sparse.hstack((X_train, x_train)), sparse.hstack((X_test, x_test))
# 4.建立模型(逻辑回归)
lr = LogisticRegression()
lr.fit(X_train, y_train)
proba_test = lr.predict_proba(X_test)[:,1] #预测概率
# 5.保存结果
# 创建dataframe
df = pd.DataFrame({'instanceID':test['instanceID'].values,
'proba':proba_test})
# 根据instanceID排序
df.sort_values("instanceID", inplace=True)
# 结果保存到CSV文件中
df.to_csv("data/submission_ad_lr.csv", index=False)

5.数据分析
提醒:
"点击时间"字段clickTime的格式为DDHHMM,其中DD代表第几天,HH代表小时,MM代表分钟
每天点击行为分析_分析点击日期与每日点击次数
# 该函数实现截取点击时间的前两位(获取第几天)
def ofday(clickTime):
return int(str(clickTime)[:2])
# 1.加载数据
train = pd.read_csv('data/train.csv')
test = pd.read_csv('data/test.csv')
ad = pd.read_csv('data/ad.csv')# 广告数据
cate = pd.read_csv('data/app_categories.csv') # 种类数据
# 2.合并数据
train = pd.merge(train, ad, on='creativeID', how='left')
train = pd.merge(train, cate, on='appID', how='left')
test = pd.merge(test, ad, on='creativeID', how='left')
test = pd.merge(test, cate, on='appID', how='left')
# 3.提取点击时间字段的前两位(第几天),存储在新列中(click_date为新列)
train['click_date'] = train['clickTime'].apply(ofday)
test['click_date'] = test['clickTime'].apply(ofday)
# 4.绘制条形图展示每日点击次数
# 获取调色板
p = sns.color_palette()
# 获取点击日期出现的次数
click = train.click_date.value_counts()
# 绘制条形图
sns.barplot(click.index, click.values, alpha=0.8, color=p[2])
plt.xlabel("click_date", fontsize=12)
plt.ylabel('click count per day', fontsize=12)
plt.show()
每天安装数分析
# 安装成功的记录也就是label为1的记录
install = train[train['label']==1].click_date.value_counts()
plt.figure(figsize=(12,4))
sns.barplot(install.index, install.values, alpha=0.8, color=p[1])
plt.xlabel("click_date", fontsize=12)
plt.ylabel('install count per day', fontsize=12)
plt.show()

每日转化率分析(安装次数/点击次数)
transfer_rate = install/click
plt.figure(figsize=(12,4))
sns.barplot(transfer_rate.index, transfer_rate.values, alpha=0.8, color=p[3])
plt.xlabel("click_date", fontsize=12)
plt.ylabel('transfer_rate per day', fontsize=12)
plt.show()
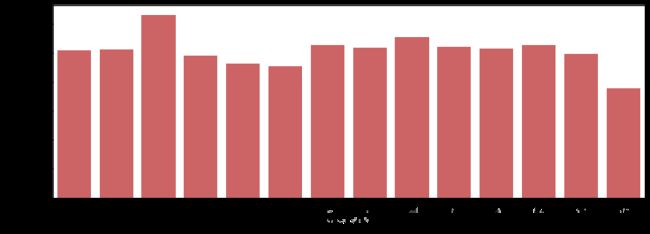
用户分析:点击次数
# 每个用户在某日重复点击算一次点击
t = train[['click_date','userID']].drop_duplicates()
users = t.click_date.value_counts()
plt.figure(figsize=(12,4))
sns.barplot(users.index, users.values, alpha=0.8, color=p[4])
plt.xlabel("click_date", fontsize=12)
plt.ylabel('num of user appear of day', fontsize=12)
plt.show()
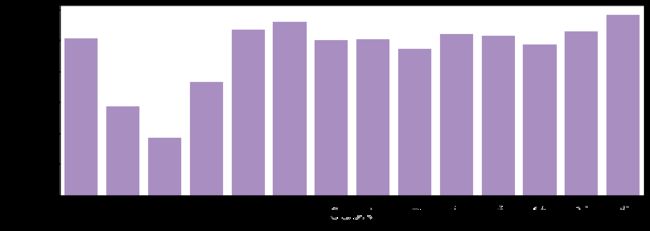
app分类分析:每日app种类的点击次数
# 每个app种类在每日的重复点击算作是一次点击
t = train[['click_date','appID']].drop_duplicates()
apps = t.click_date.value_counts()
plt.figure(figsize=(12,4))
sns.barplot(apps.index, apps.values, alpha=0.8, color=p[5])
plt.xlabel("click_date", fontsize=12)
plt.ylabel('num of apps appear of day', fontsize=12)
plt.show()

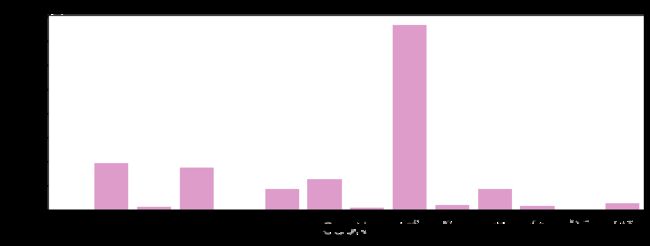
app分类点击次数:每种app对应的点击次数
click = train.appCategory.value_counts()
plt.figure(figsize=(12,4))
sns.barplot(click.index, click.values, alpha=0.8, color=p[6])
plt.xlabel("click_date", fontsize=12)
plt.ylabel('click count', fontsize=12)
plt.show()
6.特征工程
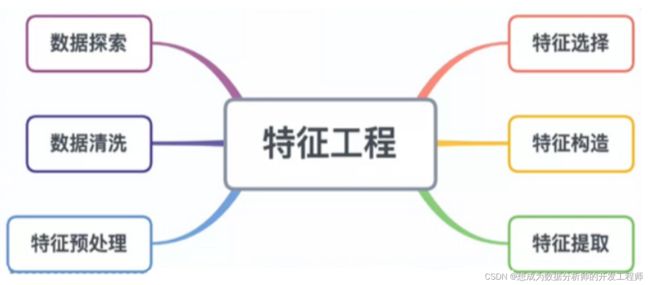
自定义工具函数库
可以先对用户数据(user.csv)进行观察,然后处理特征
本项目特征较多,所以可以编写一些函数,用来处理相应的特征:
- 第一类编码、第二类编码的处理
appCategory:App开发者设定的App类目标签,类目标签有两层,使用3位
数字编码,百位数表示一级类目,十位个位数表示二级类目,如"210"表示
一级类目编号为2,二级类目编号为10,类目未知或者无法获取时,标记为0 - 年龄处理
可以对年龄进行分段处理 - 省份、城市处理
家乡/籍贯(hometown)与常住地(residence)取值具体到市级城市,使用二级编码,千位百位数表示省份,十位个位数表示省内城市,如1806表示省份编号为18,城市编号是省内的6号,编号0表示未知 - 时间处理(DDHHMM)
获取天;根据小时将一天分成4段 随后,读取数据,调用工具函数进行特征处理
# 自定义工具函数库
# 1.文件读取
def read_csv_file(f, logging=False):
print("======读取文件数据=========")
data = pd.read_csv(f)
if logging: # 如果想要查看文件的信息
print(data.head())
print(f,'包含以下列:')
print(data.columns.values)
print(data.describe())
print(data.info())
return data
# 2.第一类编码
def categories_process_first_class(cate):
cate = str(cate)
if len(cate) == 1: # 如果长度为1
return int(cate)
else:
return int(cate[0])
# 3.第二类编码
def categories_process_second_class(cate):
cate = str(cate)
if len(cate) < 3:
return 0
else:
return int(cate[1:])
# 4.年龄处理,切分年龄段(没有固定切分方法)
def age_process(age):
age = int(age)
if age == 0:# 年龄未知
return 0
elif age <15:
return 1
elif age < 25:
return 2
elif age <28:
return 3
else:
return 4
# 5.省份处理
def process_province(hometown):
hometown = str(hometown)
province = int(hometown[:2])
return province
# 6.城市处理
def process_city(hometown):
hometown = str(hometown)
if len(hometown) > 1:
city = int(hometown[2:])
else:
city = 0 # 城市未知
return city
随后,读取数据,调用工具函数进行特征处理
# 1.读取数据
train_data = read_csv_file('data/train.csv')
ad = read_csv_file('data/ad.csv')
app_categories = read_csv_file('data/app_categories.csv')
user = read_csv_file('data/user.csv')
test_data = read_csv_file('data/test.csv')
# 2.调用自定义函数进行处理
app_categories['categories_process_first_class'] = app_categories['appCategory'].apply(categories_process_first_class)
app_categories['categories_process_second_class'] = app_categories['appCategory'].apply(categories_process_second_class)
# 对用户的age、hometown、residence调用工具函数分别处理、储存到新的列中
user['age_process'] = user['age'].apply(age_process)
user['hometown_province'] = user['hometown'].apply(process_province)
user['hometown_city'] = user['hometown'].apply(process_city)
user['residence_province'] = user['residence'].apply(process_province)
user['residence_city'] = user['hometown'].apply(process_city)
train_data['clickTime_day'] = train_data['clickTime'].apply(get_time_day)
train_data['clickTime_hour'] = train_data['clickTime'].apply(get_time_hour)
# 对clickTime字段进行处理,并存储到新列中
test_data['clickTime_day'] = test_data['clickTime'].apply(get_time_day)
test_data['clickTime_hour'] = test_data['clickTime'].apply(get_time_hour)
# 3.合并数据集
# 先合并train_data与user
train_user = pd.merge(train_data,user,on="userID")
# 合并的结果,再与ad合并
train_user_ad = pd.merge(train_user,ad,on="creativeID")
# 最后再与app_categories合并
train_user_ad_app = pd.merge(train_user_ad,app_categories,on="appID")
# 4.取出数据和label
# 特征部分
x_user_ad_app = train_user_ad_app.loc[:,['creativeID','userID','positionID',
'connectionType','telecomsOperator','clickTime_day','clickTime_hour','age', 'gender' ,'education',
'marriageStatus' ,'haveBaby' , 'residence' ,'age_process',
'hometown_province', 'hometown_city','residence_province', 'residence_city',
'adID', 'camgaignID', 'advertiserID', 'appID' ,'appPlatform' ,
'app_categories_first_class' ,'app_categories_second_class']]
x_user_ad_app = x_user_ad_app.values
x_user_ad_app = np.array(x_user_ad_app,dtype='int32')
#标签部分
y_user_ad_app =train_user_ad_app.loc[:,['label']].values
7.算法的选择与调参
-
随机森林了解
假设现在针对的是分类问题,那么随机森林(RandomForest)是一个包含多个决策树的分类器, 并且其输出的类别是由个别树输出的类别的众数而定。其实从直观角度来解释,每棵决策树都是一个分类器,那么对于一个输入样本,N棵树会有N个分类结果。而随机森林集成了所有的分类投票结果,将投票次数最多的类别指定为最终的输出
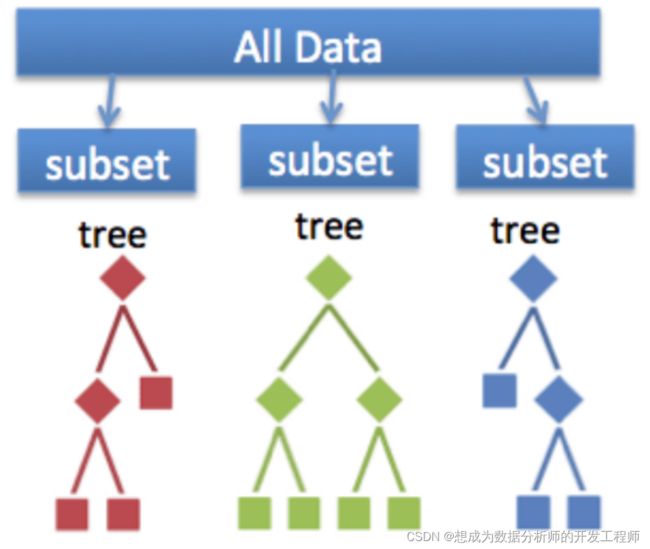
-
调参
针对同一个模型不同的参数对最终的效果影响较大,所以需要进行算法调参,通常使用网格搜索的办法(GridSearchCV)进行调参
from sklearn.model_selection import GridSearchCV # 网格搜索(用来调参)
from sklearn.ensemble import RandomForestClassifier # 随机森林算法
# 提前写好参数组合,用于搜索
param_grid = {
'n_estimators':[10,100,500,1000],
'max_features':[0.6,0.7,0.8,0.9]
}
rf = RandomForestClassifier() # 创建随机森林算法对象
gs = GridSearchCV(rf,param_grid) # 用来进行网格搜索参数的
# 进行最佳参数搜索(调参),此步骤很耗时!
gs.fit(x_user_ad_app,y_user_ad_app.reshape(y_user_ad_app.shape[0],-1))
# 打印最终调好的最佳参数
print(gs.best_params_)