缓存-基础理论和Guava Cache介绍
缓存-基础理论和Guava Cache介绍
缓存基础理论
缓存的容量和扩容
缓存初始容量、最大容量,扩容阈值以及相应的扩容实现。
缓存分类
本地缓存:运行于本进程中的缓存, 如Java的 concurrentHashMap, Ehcache,Guava Cache。
分布式缓存:支持分布式环境读取的缓存, 如Redis,
另外还有其他特定场景的缓存,如:浏览器缓存、CDN、反向代理、数据库缓存。
多级缓存
缓存在系统中根据作用域形成的层次级的缓存,如mybatis的一级(sqlSession级)、二级缓存(跨sqlSession mapper级); 本地缓存+分布式缓存的多级组合;
缓存过期策略
缓存数据的过期清理算法。通常有:设置key的过期时间,当内存不足时的数据淘汰算法,常见的淘汰算法如:LRU (Least Recently Used)最近最少使用算法,FIFO先进先出算法,LFU (Least Frequently Used)剔除最近使用频率最低的数据,随机算法等。
缓存更新策略
缓存更新策略是指定时对缓存中数据进行更新的策略。包括定时刷新,另外也指缓存和后台数据源的数据同步策略。如常见的三种更新策略:
Cache Aside Pattern(旁路缓存模式):写数据:先更新db,删除缓存;读数据时如果存在,则直接返回;如果不存在从db加载写入缓存。
Read/Write Through Pattern(读写穿透模式):缓存作为主数据源,写入数据写入缓存,缓存再负责更新到db。读取时如读取不到则将数据从db加载到缓存再从缓存返回。
Write Behind Pattern (异步缓存写入模式):和Read/Write Through Pattern区别是更新db时是异步的批量更新模式。
缓存预热
根据业务场景,提前将缓存数据加载到缓存中,可以避免使用时才查询数据库。
缓存命中率
缓存命中是指通过缓存读取数据时直接从缓存获取数据,未命中是指无法从缓存获取数据,或者是缓存中不存在,或者是数据已过期,需要重新从该数据库或其他敌法加载数据到缓存中。缓存命中率是缓存使用的最重要指标,命中率越高缓存的提升越高。缓存框架应提供缓存命中率的统计和查看工具。
缓存命中率的影响因素主要包括:业务场景、缓存粒度、缓存容量、过期策略等因素。
缓存雪崩/缓存穿透/缓存击穿
缓存雪崩:缓存大量数据失效或则缓存系统出现异常,造成大量请求直接形成对数据库的巨大压力。解决方法:缓存失效随机;缓存集群; key永不失效; 请求加锁等。
缓存穿透:请求数据库中不存在的数据,缓存失效。解决方案:布隆过滤器;缓存空对象。
缓存击穿:指当缓存中热点数据过期,在热点数据重新载入缓存之前,大量的查询请求穿过缓存,直接查询数据库。 解决方案:key 永不过期;分布式锁。
Guava Cache
Guava Cache 是Guava Java工具包中提供的本地缓存工具,可以作为独立的本地缓存或多级缓存中的本地缓存使用。
数据结构
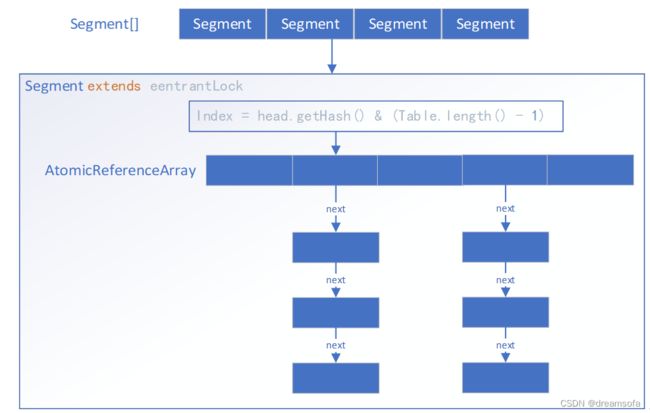
图1 Guava Cache存储数据结构
Guava Cache 将缓存换分为多个段(Segment[]), 每个段都是ReentrantLock的子类,段和段之间是完全并行,段内是写入加锁,读取不加锁的并发控制。
Segment内部数据结构使用AtomicReferenceArray来表示Hash入口,相同hash在AtomicReferenceArray的同一位置形成一个链表。
有多少个Segment?
- 由配置参数ConcurrencyLevel决定:ConcurrencyLevel 默认是4,最大是65536(1<<16)
- (!evictsBySize() ||segmentCount * 20 <= maxWeight):当制定了最大数据权值时,通过段数*20 < 最大权值来避免过于稀疏的端。
| int segmentShift = 0; int segmentCount = 1; while (segmentCount < concurrencyLevel && (!evictsBySize() || segmentCount * 20 <= maxWeight)) { ++segmentShift; segmentCount <<= 1; } this.segmentShift = 32 - segmentShift; segmentMask = segmentCount - 1; |
如 segmentCount = 4时, segmentShift = 32 – 2 = 30, segmentMask = 0x03
无符号Hash, 最高的两位用于识别Segment位置, segments[(hash >>> segmentShift) & segmentMask]。
数据的释放
除了根据缓存协议的过期时间、数据替换策略对缓存元素进行释放外, Guava Cache可以设置缓存key/value应用强度,是的在内存不足时缓存数据可以得到释放。
Java引用强度
强引用:普通对象引用,当对象存在引用时不会回收。
软引用: SoftReference
弱引用:WeakReference
虚引用: PhantomReference
查找过程
- 定位Segment
- 定位Segment内数组Hash索引: table.get(hash & (table.length() - 1));
- 遍历同hash的队列找出相等的key
- 检查是否过期, 如不过期返回,过期则尝试加载后返回。
过期检查
accessQueue: 缓存元素引用的队列,当元素被使用(包括加载)时加入accessQueue的队尾,也就是accessQueue中包含缓存所有元素的引用。
writeQueue: 缓存元素引用的队列,当元素被写入时,加入到writeQueue队尾。
当每次获取某个元素时,都对段内元素按AccessQueue和WriteQueue顺序检查元素是否过期,因为两个队列都是按照操作顺序(加载或写)加入队列的, 所以只需要从头移除过期元素直到碰到第一个未过期的元素即可。
注: 将元素提前进行排序或分组以加快后续功能的查找速度是常用的优化方法,类似如RocketMQ延期队列按延期时间划分到不同的子主题中,也体现了性能优化:分而治之、提前部署、异步非阻塞的思维之一:提前部署。 缓存本身也是该思维的体现。
加载
当查找无法找到元素或元素已过期时将触发一个元素加载的过程, 元素加载细分为两个操作: 在Segment中加入引用;实际进行元素加载。
- 在Segment上加锁,完成添加引用操作后释放Segment锁。
- 在新的引用入口上加同步锁,完成实际的元素加载后释放。如果是新建的引用,针对引用对象进行枷锁,完成加载。如其他线程此时读取对象,发现该引用对象属于加锁状态,则等待元素的加载完成后获取。
注:分段加锁体现了多并发所操作的重要原则之一:正确确定锁的作用范围。 引入更多层次上的锁,避免粗放使用,造成锁的范围扩大。其他类似如:数据库的表锁、行锁。
新增/更新(put)
Put操作时,在Segment中根据key对应hash值查找到元素, 如查找则更新值,如无法找到,新建元素引用并加入到响应的索引位置。新增元素将放置于AtomicRefereceArray中索引位置, 新增元素的Next引用指向原索引位置的元素。
吸入之前将对Segment进行清除: 已过期的,或因弱引用已经被释放的key/value对象。
扩容
当Segment中元素数量超过指定阈值时将触发扩容。阈值是当前AtomicReferencyArray长度的3/4。扩容在Segment锁下进行。
扩容过程:
- 新建一个常度为原长度两倍的AtomicReferenceArray。
- 遍历原AtomicReferenceArray 所有元素,计算Key的hash值,按照新的长度取余插入新引用数组中, 插入方式同新增。
- 使用新的AtomicReferenceArray。
数据同步方案
Guava Cache 的数据同步有三种模式:
- 客户PUT或REPLACE数据。
- 查找时无法找到或则元素已经过期时进行同步的加载。
- 异步批量刷新。
过期策略
设置过期时间
Guava Cache 通过设置expireAfterAccess(读取后过期时间),expireAfterWrite(写入后过期时间),refreshAfterWrite(写入后刷新过期时间)三个过期时间触发数据刷新
最近最少使用替换算法
当设置了缓存的最大权重并且当前段的总权重已经超过最大权重,则需要进行数据的主动清理,也就是缓存中的过期策略或替换算法。
Guava Cache使用最近最少使用的算法。 当超过是使用AccessQueue将最早的元素释放,直到总权重小于最大权重。
命中率
Guava cache使用 StatsCounter 统计缓存的命中,当缓存命中或未命中时进行计数。通过Cache接口的CacheStats stats()方法展示信息。