金融风控数据分析
一、信贷底层库表详解与数据集市构建
1.信贷业务底层数据核心库表穿透式详解
1)客户信息表结构与数据(customer_info)
客户信息表是根据客户在前端申请信贷产品时主动填写的信息收集的,部分可验证字段可直接用于风控规则,而有些无法验证的字段在前期没有贷后表现的情况下只能用于参考,不适合直接用于制定规则。
结构:基本信息(姓名、年龄、性别);单位信息(单位名称,单位地址);教育程度;工作信息(工龄、职位);收支情况;家庭信息(户籍地址、子女数量)
数据:customer_no,customer_name,sex,age,id_no,mobile,education_level,marry_status ····
2)合同信息表结构与数据(credit_loan)
合同信息表是根据客户完成申请全流程,确认借款且审批通过后生成贷款合同信息收集的。合同信息表在做产品推广,客户经营(如交叉销售、调额)时尤其重要,比如根据分析结合逾期和利率数据,期限为6期的客户投资回报率最高,则可通过调整利率吸引客户申请6期的产品。
结构:放款信息(放款时间、期限、放款金额);合同状态;利率(贷款利率、逾期利率、提前还款利率);逾期信息(逾期次数、首次逾期日期、累计逾期天数);贷款用途;还款信息(还款方式、约定还款日)
数据:contract_no,customer_no,loan_amt,loan_time,expiration_data,loan_status·····
3)还款计划表结构与数据(repaying_plan_detail)
还款计划表记录了客户的还款轨迹,能够直接定性一个客户的好坏,计算逾期率、账龄以及定义建模时的目标变量等都需要通过这个表的数据,因此还款计划表是策略迭代、建模、数据分析中最为重要的表。
数据:
2.数据集市开发与构建核心信贷指标
数据集市:基础层(清洗)、中间层(设计)、应用层(加工)
1)中间表结构及字段设计
最常见的中间表是将一些明细数据做成汇总数据,如以天/周/月为单位,汇总审批量,通过量,拒绝量,批核金额、放款金额、拒绝原因等,在做报表时可直接应用;
还有些中间表需要从竖表中挑选变量转成横表,以审批数据为例,在生产库中会将一笔订单在决策引擎每一个节点的输入、输出变量都保存下来,然而若每个变量都做成一个字段,那表的结构会非常大,而且一旦策略修改,表结构也要跟着修改,会给各方带来诸多不便,故都是设计成竖表,风控在搭建数据集市的时候就需要从竖表中挑选出需要的变量,转化成横表,方便后期统计分析。
2)中间表字段含义详解
中间表字段含义:通过率、批核件均、放款件均、平均通过率、其余字段以审批日期单位(天/周/月),对单量、金额汇总求和;
3)逾期率、首逾、vintage等核心指标详解
逾期率:
首逾:FPD首逾、SPD首二逾、TPD首三逾、QPD首四逾,即客户发生逾期在第几期,计算公式:
F P D = 第 1 期 逾 期 客 户 剩 余 本 金 第 1 期 可 观 测 客 户 放 款 总 额 FPD=\frac{第1期逾期客户剩余本金}{第1期可观测客户放款总额} FPD=第1期可观测客户放款总额第1期逾期客户剩余本金
若首逾较高需考虑客群是否存在恶意欺诈情况,提醒政策同事及时调整策略;若后几期增高明显需考虑客群是否存在多头借贷、负债较高等情况,可借助外部数据源加强贷中监控。
vintage:是以账龄MOB(month on book)为轴,观察贷后每个月的后续质量情况,分母为对应月份的放款本金,分子是截止期末时点逾期Mn+客户的所有剩余未还本金,可观测一个多期产品的风险全貌
备注:vintage这个词源于葡萄酒业,意思是葡萄酒的酿造年份。我们在生活中经常会进行各种各样的比较,但是比较有个前提,就是比较的事物应该是位于同一层面上的。如果你拿四年级的学生和1年级的学生比较身高,或者拿成年人和未成年人比较体重那是毫无意义的。同理,我们在比较放贷质量的时候,也要按账龄(month of book,MOB )的长短同步对比,从而了解同一产品不同时期放款的资产质量情况。
举例来说,今天是2018年5月25日,我们取今天贷款第一期到期的客户作为观察群体,观察他们今后29天的还款情况。如果你将将今天所有贷款到期的客户作为观察群体(里面有第一期到期的,也有第二期到期的,也有第三期到期的,等等),那么这个群体里面的客户就不是位于同一层面上了。
到了下个月,6月25号,我们取6月25号贷款第一期到期的客户作为观察群体,观察他们之后29天的还款情况。这样你就可以比较5月25号的群体和6月25号的群体的还款情况差异。如果6月25号的群体还款质量有显著性降低(如下图),那么你可能会审视一下你这一个月来的营销策略是否变宽松了,或者这一个月来国家政策有什么改动等等。
计算公式:
V i n t a g e 30 + = 逾 期 30 + 剩 余 本 金 当 月 放 款 本 金 Vintage30+=\frac{逾期30+剩余本金}{当月放款本金} Vintage30+=当月放款本金逾期30+剩余本金
流转率(Flow Rate):流转率体现的是余额在不同逾期区间的变化,目的是观察前期逾期金额经历一番催收后落入
下一区间的比率,所以既可以作为风控指标也可以作为催收指标。
4)基于中间表的核心指标计算


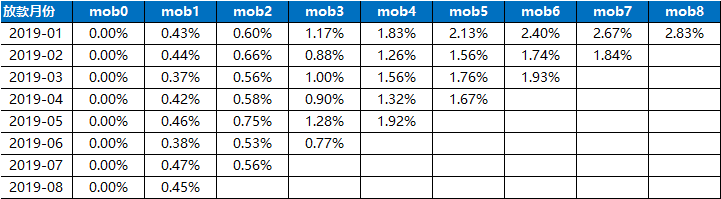
计算vintage:
select c.放款月,
round(sum(放款金额/10000),2) 放款金额,
case when sum(放款金额)>0 then round(sum(mob1)/sum(放款金额),4) else null end as mob_1,
case when sum(放款金额)>0 then round(sum(mob2)/sum(放款金额),4) else null end as mob_2,
case when sum(放款金额)>0 then round(sum(mob3)/sum(放款金额),4) else null end as mob_3,
case when sum(放款金额)>0 then round(sum(mob4)/sum(放款金额),4) else null end as mob_4,
case when sum(放款金额)>0 then round(sum(mob5)/sum(放款金额),4) else null end as mob_5,
case when sum(放款金额)>0 then round(sum(mob6)/sum(放款金额),4) else null end as mob_6
from(
select 分期数,
放款月,
sum(case when mob=1 and 当前最大逾期天数>0 then 剩余本金 else 0 end) as mob1,
sum(case when mob=2 and 当前最大逾期天数>0 then 剩余本金 else 0 end) as mob2,
sum(case when mob=3 and 当前最大逾期天数>0 then 剩余本金 else 0 end) as mob3,
sum(case when mob=4 and 当前最大逾期天数>0 then 剩余本金 else 0 end) as mob4,
sum(case when mob=5 and 当前最大逾期天数>0 then 剩余本金 else 0 end) as mob5,
sum(case when mob=6 and 当前最大逾期天数>0 then 剩余本金 else 0 end) as mob6
from (
select m.分期数,
m.剩余本金,
m.放款月,
m.观测月,
m.当前最大逾期天数,
case when substr(m.观测月,1,4)=substr(m.放款月,1,4) then substr(m.观测月,6,2)-substr(m.放款月,6,2)
when substr(m.观测月,1,4)=substr(m.放款月,1,4)+1 then 12+substr(m.观测月,6,2)-substr(m.放款月,6,2)
else 0 end as mob
from risk_test.repayment_sum_month m
) a
group by 分期数,放款月
) b
join (
select 合同期限,
substr(放款日期,1,7) 放款月,
sum(合同金额) 放款金额
from risk_test.customer_detail
where 放款日期>='2017-11-01'
and 放款日期<='2018-04-30'
and 合同期限=6
group by 合同期限,substr(放款日期,1,7)
) c
on b.分期数=c.合同期限 and b.放款月=c.放款月
group by c.放款月;
二、常用SQL实练与风控报表体系设计
1.信贷数据分析必备核心SQL语言全览
1)SQL实现增删改查
Step1:先在本地数据库中创建一个表,建表时要注意字段类型
Step2:插入数据(insert)
可仅插入部分列
Step3:删除数据(delete)
可清空全表也可带条件删除某些行
Step4:修改数据(update)
可带条件批量修改
Step5:查询数据(select)
简单查询、关联查询、嵌套查询
-- 建表
CREATE TABLE table_a
(id int,
name varchar(40),
sex char(10),
birthday date);
-- 增
INSERT into table_a(id,name,sex,birthday) VALUES (001,'张三','男','1990-01-01');
INSERT into table_a(id,name) VALUES (111,'李四');
INSERT into table_a(id,name,sex,birthday) VALUES (333,'李四','女','1991-01-01');
-- 删
DELETE from table_a where name='李四';
-- 改
UPDATE table_a set sex='男' where name='张三';
-- 查
select name,birthday from table_a;
SELECT * FROM table_a;
2)SQL实现查询主语句
-- SQL实现查询主语句 练习
Select * from customer_info a where a.sex='男' and a. marry_status='未婚';
Select * from credit_loan b where b.loan_term='6' and b.loan_status='未结清';
Select distinct c.contract_no,overdue_days
from repaying_plan_detail c
where current_end_date>='2018-08-01' and current_end_date<='2018-08-31';
3)数据分析常用SQL函数
select date_format (now(),’%Y-%m-%d’) date_time;
-- 数据分析常用SQL函数
-- 聚合函数
select count(1) from customer_info a ;
SELECT b.loan_time,count(1)
from credit_loan b
GROUP BY b.loan_time;
-- 日期、时间函数
select DATE_FORMAT('2019-01-01 10:28:09','%Y') as create_date;
-- select DATE_FORMAT(b.create_date,'%Y-%m-%d') as create_date from table_b b;
-- 流程控制函数
select a.customer_name,a.age,
case when a.age>=20 and a.age<=30 then '20-30'
when a.age>=31 and a.age<=40 then '31-40'
when a.age>=41 and a.age<=50 then '41-50'
else '>=51' end as age_level
from customer_info a;
-- 字符串截取函数
SELECT substr(a.id_no,7,8) birthday from customer_info a;
流程控制函数:
select num1,
max(case when num2 = ‘data_01’ then num3 else null end) data_01,
max(case when num2 = ‘data_02’ then num3 else null end) data_01,
max(case when num2 = ‘data_03’ then num3 else null end) data_03
from table_a group by num1;
4)SQL实现表链接与嵌套表查询
-- 随堂实操
-- 关联查询
select a.customer_no as customer_no_a,b.customer_no as customer_no_b
from customer_info a
join credit_loan b on a.customer_no=b.customer_no;
select a.customer_no as customer_no_a,b.customer_no as customer_no_b
from customer_info a
left join credit_loan b on a.customer_no=b.customer_no;
select a.customer_no as customer_no_a,b.customer_no as customer_no_b
from customer_info a
RIGHT join credit_loan b on a.customer_no=b.customer_no;
-- 嵌套查询
SELECT *
from credit_loan b
where b.customer_no in (select a.customer_no
from customer_info a
where a.age>=20 and a.age<=35 and a.sex='女');
-- 练习
-- 1、查询customer_info内有多少个客户在credit_loan内有合同
SELECT count(a.customer_no) num
from customer_info a
join credit_loan b on a.customer_no=b.customer_no;
-- 2、查询customer_info内有多少个客户在credit_loan内没有合同
SELECT count(a.customer_no) num
from customer_info a
left join credit_loan b on a.customer_no=b.customer_no
where b.customer_no is null;
-- 3、查询credit_loan内有多少笔合同在customer_info内没有客户信息
SELECT count(b.customer_no) num
from customer_info a
RIGHT join credit_loan b on a.customer_no=b.customer_no
where a.customer_no is null;
-- 4、查询已还期数>3期的所有客户信息
select *
from customer_info a
where a.customer_no in (select DISTINCT c.customer_no
from repaying_plan_detail c
where c.repayed_period>3);
2.数据备份与详解信贷报表体系
1)数据备份说明
-- 数据备份
-- 新建表 CREATE TABLE Table_B LIKE Table_A;
set @str=concat('create table customer_info_',DATE_FORMAT(CURDATE(),'%Y%m%d'),'(like customer_info)');
PREPARE stmt1 from @str;
EXECUTE stmt1;
-- 备份数据 INSERT INTO Table_B SELECT * FROM Table_A where ;
set @str=concat('insert into customer_info_',DATE_FORMAT(CURDATE(),'%Y%m%d'),'(select * from customer_info)');
PREPARE stmt2 from @str;
EXECUTE stmt2;
2)历史数据回朔说明
以账龄MOB(month on book)为例,分母为对应月份放款本金,分子是截止期末时点逾期Mn+客户所有剩余未还本金
此处的“期末时点”一般是月末最后一天,这要求我们有每笔合同在放款后每个月末的截面数据,而还款数据表里的数据都是动态更新的,无法直接查询客户的还款轨迹(逾期轨迹),如果没有在一开始就设定每个月末去做好数据备份或者备份出错没有及时发现,那就需要根据目前的还款数据去回溯。
MySQL里面可通过自定义带参函数实现:
declare start_date date;
set @start_date = daydate;
可通过参数回传一个日期,去还原历史任一天客户的还款情况,还可加工出一些定性变量,如截止某一天客户是否逾期、逾期多少天、逾期金额是多少等。
3)报表模块详解
审批监控:审批情况、拒绝原因、放款情况;
贷中监控:NpD表现、vintage表现、截面风险表现;
风险运营:催收、资产保全;
模型监控:评分分布、入模变量值分布、逾期分布;
数据源监控:变量值分布、费用成本;
外部报表:运营、产品、财务;
整个风控流程所涉及的具体模块由:内部(审批、贷中、模型、数据源、风险运营等)和外部(运营、产品、财务等)组成。
4)报表框架设计
由于消费金融业务组织较大,分工比较细,因此各部门的需求考虑未必相同,报表设计人员需深入了解各个报表的用途及所期望的效益,设计时需依其用途与目的做全面性判断规划,避免单点考虑,并给使用单位提出合理建议;
一、角色设计
管理者:偏重于探索数字背后所代表的意义,要求内容更加深入,涵盖层面更为广泛,要求设计人员对业务有深入的理解;
风控内部:要求实时性、正确性、完整性,能够实现风控流程监控,展示风控效益的核心指标;
风控外部:仅展示与该部门相关的指标,非特殊情况下不可展示风险(逾期、账龄等)相关指标;
二、内容设计
报表导航:在报表首页设置导航,可以快速定位到读者想看的内容;
数据、图表结合:为使内容一目了然,合理将数据与饼图、折线图、柱状图结合展示;
指标计算逻辑说明:有些指标的计算口径会存在争议,故在报表中需增加各个指标的计算口径;
数据解读:在每份报表的开端或末尾附上自己从报表内解读到的重点内容;
详细内容:
1.授权登录:每个人有特定账号,账号权限区分只读(只能阅读系统中相关报表)、管理(可对系统中报表做:增删改操作);
2.报表工作台
1)增加/删除报表模块(仅有后台管理权限的账号可增加/删除报表模块(只能删除本人新建模块)
审批、运营、产品
2)报表展示:进入【审核】模块后可增删改审核相关报表(以审批日报表为例)
(仅有后台管理权限的账号可增加/删除报表模块(只能删除本人新建报表)
审批日报、贷后周报、审批周报、贷后周报
进件量、审批量、通过量、放款量
5)SQL代码实操实现数据回溯及备份(案例)
三、报表⾃动化及数据验证和监控
1.基于风控数据集市的报表自动化
python发送邮件测试:
import smtplib
from email.mime.text import MIMEText
from email.header import Header
host = 'smtp.qq.com' # 服务器地址
port = 465 # 端口
user = '[email protected]' # 发件人账号
password = '***********' # 发件账号密码(授权码)
sender = '[email protected]' # 发件人账号
receivers = ['[email protected]'] # 收件人账号,此处设置为本人
subject = 'Python邮件测试' # 邮件标题
# 三个参数:第一个为文本内容,第二个 plain 设置文本格式,第三个 utf-8 设置编码
message = MIMEText('Python 邮件发送测试', 'plain', 'utf-8')
try:
message = MIMEText('Python 邮件发送测试', 'plain', 'utf-8')
message['Subject'] = Header(subject, 'utf-8')
message['From'] = ' '
message['To'] = ';'.join(receivers)
smtp_obj = smtplib.SMTP_SSL(host) # 开启发信服务,加密传输
smtp_obj.connect(host, port)
smtp_obj.login(user, password) # 登录邮箱
smtp_obj.sendmail(sender, receivers, message.as_string()) #发送邮件
print ("邮件发送成功")
except smtplib.SMTPException:
print ("邮件发送失败")
python链接数据库
# 方法一:
import pymysql
import pandas as pd
risk1 =pymysql.connect(host="localhost",user="root",
password="你的数据库密码",database="risk_test",
charset="utf8")
query1="""select * from risk_test.daily_report where 日期<='2018-03-31'"""
data1=pd.read_sql(query1,risk1)
print(data1)
# 方法二:
import pandas as pd
import sqlalchemy
risk2 = sqlalchemy.create_engine('mysql+pymysql://root:你的数据库密码@localhost:3306/?charset=utf8')
query2="""select * from risk_test.daily_report where 日期 > '2018-03-31' and 日期 <= '2018-04-30'"""
data2=pd.read_sql(query2,risk2)
print(data2)
1)基于python生成报表
环境准备:邮箱 anaconda——python;
python连接风控数仓:
基础层:customer_info:客户信息表,一般存放可分析客户特征的一些字段;
中间层:repayment_sum_month:截止每个月末客户的逾期截面数据
应用层:daily_report:风控日报中统计的部分信息
方法一:通过pymysql,配置数据客户的IP地址、用户名、密码、库名和编码方式;
方法二:通过sqlalchemy,配置数据库的用户名、密码、IP地址、端口和编码方式;
import pandas as pd
import pymysql
import xlrd
from xlutils.copy import copy
#%% 第一种情况:新建一张报表
# 1、连接数据库
risk = pymysql.connect(host="localhost",user="root",
password="root",database="risk_test",
charset="utf8")
# 2、查询数据
query="""select * from risk_test.daily_report where 日期<='2018-03-31'"""
data=pd.read_sql(query,risk)
# 3、新建xls及sheet,把data写在这个sheet里
writer = pd.ExcelWriter('E:\\FAL课程\\daily_report.xls')
data.to_excel(writer,'daily_report',index=False)
# 4、保存报表
writer.save()
#%% 第二种情况:更新已有报表中的数据
# 1、复制原有的报表文件,formatting_info=True表示保留原文件格式
oldWb = xlrd.open_workbook('E:\\FAL课程\\daily_report.xls', formatting_info=True);
newWb = copy(oldWb)
newWs = newWb.get_sheet('daily_report')
# 2、测出data_1长度、宽度,以range列出赋值给list_1、list2
list_1=range(len(data))
list_2=range(len(data.columns))
# 3、按照一定的格式和位置循环写入EXCEL表格
data['总进件']=data['总进件'].astype('float64')
for i in list_1:
for j in range(1):
newWs.write(i+1,j+1,data['总进件'][i])#写入EXCEL表格
newWs.write(i+1,j+2,data['审批量'][i])
newWs.write(i+1,j+3,data['准入拒绝量'][i])
newWs.write(i+1,j+4,data['通过量'][i])
newWs.write(i+1,j+5,data['拒绝量'][i])
newWs.write(i+1,j+6,data['通过率'][i])
newWs.write(i+1,j+7,data['批核金额'][i])
newWs.write(i+1,j+8,data['批核日件均'][i])
newWs.write(i+1,j+9,data['放款量'][i])
newWs.write(i+1,j+10,data['放款金额'][i])
newWs.write(i+1,j+11,data['放款日件均'][i])
i += 1
print ("write new values ok")
# 4、保存报表
newWb.save('E:\\FAL课程\\daily_report.xls')
2)通过python实现报表的自动更新
以vintage为例,
1.配置报表更新时间;
2.编写报表逻辑,到指定时间运行代码从数据库中取数,更新报表内容;
3.报表监控,更新成功则输出“报表更新成功”,否则输出“报表更新失败”
3)通过python实现报表的定时发送
1.配置邮件发送时间;
2.配置邮箱参数,发件人邮箱账号,密码,收件人邮箱账号,邮件标题、邮件正文;
3.将要发送的报表添加为邮件附件;
4.发送邮件,发送成功则输出“邮件发送成功”,否则输出“邮件发送失败”
2.报表数据监控与验证
1)常用数据验证逻辑
根据业务流程,验证数据条数:合同笔数<=订单数<=客户数;
根据业务逻辑,验证字段逻辑:审批通过的订单才有合同号,合同生成必须有还款计划;还款记录符合销账逻辑(横销、竖销)
进件——>>审批——>>放款——>>还款
1.客户填写完进件要素后提交订单(客户信息表、订单信息表);
2.提交的订单进入审批流程(审批记录表);
3.审批通过的订单生成放款合同(合同信息表、还款计划表);
4.放款合同应按期还款直到合同终结(还款计划表、催收记录表);
2)数据库监控与预警
SET FOREIGN_KEY_CHECKS=0;在Mysql中取消外键约束
监控连接数:
show variables like "max_connections";
show status like "Treads_connected";
show status like "Treads_running";
监控数据更新时间:
select table_name,update_time from information_schema.tables
where table_schema="risk_test" and table_name
in ('credit_loan','customer_info','repaying_plan_detail');
case when 使用方法
四、资产组合管理体系搭建
1.资产组合管理在生命周期中的应用
拓展客户期
1)目标用户:适用于拨备segment的风险分级或用户画像支持
2)目标产品:风险分级对应期数、利率支持
3)资产配置有效性分析
审批客户期
主要由贷前策略实施,可提供盈利性测算支持,并做好监控、预测、预警系统,当准入用户风险状况超阈值,需提出干预。
管理客户期
1)指标方面:新增/存量&风险/规模指标
vintage,FPD,GMV;迁徙率,coincident dpd,lagging dpd,坏账率,在贷余额。
2)策略方面:主要有贷中,贷后策略实施,可提供盈利性测算支持,并做好监控、预测、预警系统,风险状况超阈值,需提出干预。
资产组合管理三大法宝:
1.拨备(准备金)
2.风险分级(用户画像)
3.监控、预测、预警系统
2.风险管理
a.常用风险指标
风险:损失的概率和在损失发生时其数额的大小
1.根据风险的成因:市场风险/作业风险/信用风险/欺诈风险
2.从资产组合管理的角度
实际风险/名义风险/拨备
风险分析五要素:下单月、观察月、放款额(GMV)、在贷余额(Balance)、逾期天数(DPD)
实际风险:
Month end:月底结算
Cycle end:期末结算
| 逾期天数 | 逾期阶段 | 描述 |
|---|---|---|
| 0 | M0/C | 正常 |
| 1~29 | M1 | 早期逾期 |
| 30~59 | M2 | 中期逾期 |
| 60~89 | M3 | 中期逾期 |
| 90~119 | M4 | 不良 |
| 120~149 | M5 | 不良 |
| 150~179 | M6 | 不良 |
| 180+ | M7/M6+/WO | 坏账 |
总结:新增常用风险指标
1. V i n t a g e \color{red}Vintage Vintage
用于分析各时期的进件后续质量
延展:全生命周期坏账
2. F P D 7 / 30 \color{red}FPD7/30 FPD7/30
首次逾期7天/30天的用户数占比
延展:通常被反欺诈模型定义作为Y
不良率%:在存量指标中,在贷余额一般都不包含180+,即Balance=M0+M1+M2+M3+M4+M5+M6
不良金额=M4+M5+M6
不良率= 不良金额/在贷余额
DPD延展——坏账率(通常会转为年化)
WO%=近12个月新增WO/AVG(当月Balance+12月前Balance)
总结:存量风险常用指标
1. 迁 徙 率 \color{red}1.迁徙率 1.迁徙率
用于观察前期逾期金额经过催收之后,仍未还款,且于本期继续落入下一个逾期状态的概率。
应用:预测常用过程指标
2. C o i n c i d e n t D P D \color{red}2.Coincident DPD 2.CoincidentDPD
观察月资产分布状况;业务扩张时低估风险,业务萎缩时高估风险
3. l a g g i n g D P D \color{red}3.lagging DPD 3.laggingDPD
能追溯风险产生时刻的状况,不会因业务扩张或萎缩而高估或低估风险,但计算复杂。
4. 坏 账 率 \color{red}4.坏账率 4.坏账率
一般要转为年化坏账率
b.拨备的计算及应用
拨备是对企业经营中可能已经构成的风险和损失作出准备,反映企业承担的风险和成本,直接冲减净资产,更真实地反应企业的经营水平和资产质量。拨备是直接和利润挂钩。一般来说,对于一个成熟企业,获客成本、运营成本、资金成本都较为稳定,只有风险成本需要模型单独预测;可以说拨备决定了一个企业最终盈利。拨备模型的合理应用,可以量化策略调整在内的一切行为,故可以直接把拨备率当做KPI指标。
拨 备 对 于 资 产 组 合 管 理 来 说 至 关 重 要 \color{red}拨备对于资产组合管理来说至关重要 拨备对于资产组合管理来说至关重要
c.KPI设计
基于拨备设计KPI
1.通常来说,拨备模型的segment需要作为风险分级的管理工具,并且每个segment对应
的风险(迁徙率)是稳定的,可借助模型实现;
2.财务反馈未来半年每月新增放款时,必须说明风险分级对应的体量;
3.可根据新增放款推算出未来半年的资产分布(预测方法论见第三部分);
4.资产分布可直接算出拨备额以及拨备率。
直接将拨备额/拨备率作为业务部门的KPI,包含了M0-M6每个阶段的风险
基于资产分布设计KPI
企业通常会将不良率设为KPI进行考察,资产分布预测框架作为重点内容在第三部分展开讨论
总结:
1.风险管理从实际风险和名义风险展开讨论
2.实际风险分新增风险 vintage/FPD, 以及存量风险 迁徙率/不良率/坏账率
3.名义风险主要指拨备(准备金)
4.为量化部门贡献,常用拨备率/拨备额作为KPI指标,又由于上报监管或财报披露要
求,不良率也是KPI的重要指标;它们都需要用到资产分布预测模型。
3.监控、预测、预警的搭建
a.监控报表设计
b.常用指标的预测方法
c.预警板块
d.综合应用