RabbitMQ——内存调优(二)
在上一篇文章中简单介绍了erlang运行时系统中内存分配的相关概念。
那么在消息堆积的场景中,对这些参数调整,是怎样影响整体性能的呢?
要分析这个问题,首先我们得估算下在队列消息堆积的情况下进行生产消费,RabbitMQ的内存占用情况。
这里补充说明下我们的使用方式:
首先所有消息都是持久化的,队列也是持久化的,防止服务端意外宕机导致消息的丢失;
其次全局设置了lazy属性,为了防止某些程序异常不消费出现的消息大量堆积在队列,导致内存占用很高引起各种问题;
最后,设置了queue_index_embed_msgs_below的大小,保证消息都是包含在索引中一并存储的。
在队列堆积的情况下,rabbitmq的大部分内存占用是队列中的消息,这些消息占用的内存大概由这么几块组成:
1、生产者发送的消息在真正写入文件前会在内存中缓存,这个缓存的最大数量是根据配置queue_index_max_journal_entries来决定的。
2、受信用流控的影响,生产者发送的消息可能还会有一部分在队列进程的邮箱中未来得及被队列处理,而进程邮箱中的消息也全部是在内存中的。因此,在进程邮箱中缓存消息的上限值是配置参数credit_flow_default_credit中的两个值相加再乘以生产者的个数。
3、消费者从队列消费消息时,队列是按一整个segment来进行读取的,读取后的消息均在内存中缓存,而一个segment中最多包含16384条消息。
4、已经发送给消费者,但还没有被消费者ACK的消息也会在内存中缓存,通常上限就是消费者prefetch_count设置的值。
综上所述,在堆积的情况下同时生产消费,队列中最大可能缓存的消息数就是上面这四项相加得到的值,然后乘以每条消息的字节数以及整个rabbitmq中出现消息堆积的队列数,最终得到的值就是这种场景下rabbitmq占用的内存大小。
举个实际的例子
rabbitmq中总共有64个队列,每个队列都有一个对应的生产者与消费者;
消费者的prefetch_count设置为50;
queue_index_max_journal_entries的值配置为4096;
credit_flow_default_credit的值配置为{400, 200};
消息大小为4KB
那么在所有队列都有堆积的情况下,进行生产发送,其消息在内存中占用的最大值为:
(4096+400+200+16384+50)*64*4KB = 5282.5MB
当然除了缓存消息占用的内存,内存的占用还包括进程的堆、ets表等等,但这些相比消息在内存中占用的大小要小很多很多。
大概了解堆积情况下的内存占用后,我们再来看看RabbitMQ默认的内存分配参数,如下所示:
RABBITMQ_DEFAULT_ALLOC_ARGS="+MBas ageffcbf +MHas ageffcbf +MBlmbcs 512 +MHlmbcs 512 +MMmcs 30"
即对于Binary、heap类型,对应内存分配器实例中单个MBC的最大大小为512KB,最大缓存个数为30。
那么按12核来算的话,缓存MBC大小的最大值为:
512KB *30 *12 = 180MB
这远远不够消息缓存所需要的大小,因此,rabbitmq的虚拟机会不断的进行内存的申请与释放,这样一来,整体的性能自然也就不高了。
注意:
1、消息在rabbitmq中都是以binary的形式存在的,而MBlmbcs控制了binary数据类型MBC的最大大小。
2、上面计算出来的180MB仅仅是分配器实例中缓存的MBC的大小,并不是实际只能申请这么大小的空间。
调整binary分配器MBC大小的最大、最小值,以及MBC递增大小
例如
RABBITMQ_DEFAULT_ALLOC_ARGS="+MBas ageffcbf +MHas ageffcbf +MBsmbcs 2048 +MBlmbcs 131072 +MBmbcgs 50 +MHsmbcs 2048 +MHlmbcs 131072 +MHmbcgs 50 +MMmcs 30"
即对于Bianry、heap类型,对应内存分配器实例中MBC的最小大小为2048KB=2MB,最大大小设置为131072KB=128MB,增长幅度为50。
这种情况下,允许的缓存最大大小为 128MB*30*12 = 45GB,这样可以满足所有队列堆积时缓存消息所需的内存,那么从系统中申请释放内存的次数自然也就少了,整体的吞吐量自然也就上去了。
【实际测试对比】
测试场景
64个队列,每个队列一个生产者,一个消费者;生产者不间断发送消息,消费者的prefetch设置为50;先只开启生产者,当64个队列堆积累计达到一定程度后,开启消费者,然后观察此时的生产消费速度。
使用默认参数时的情况:
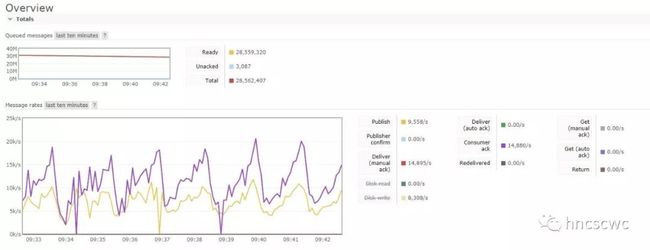
使用调整后参数的情况:

对比可以看出,堆积时,生产消费的速度有了明显的提升。
再看erlang虚拟机中binary分配器的对比数据:
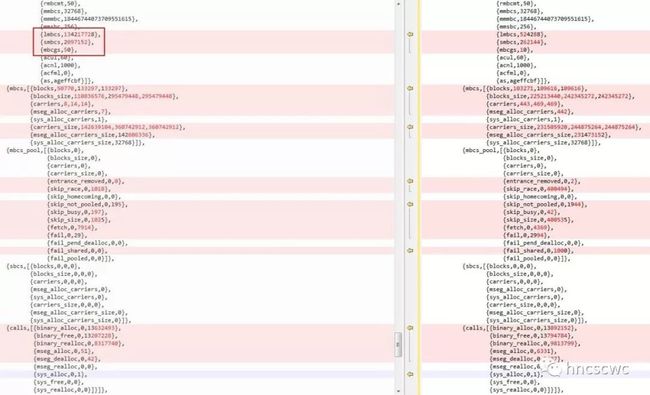
左边的数据是调整后binary分配器其中一个实例的情况,不管是分配的次数,还是内部分配的缓存命中次数都有了明显的改善。
【总结】
通过调整erlang运行时系统中内存分配的相关参数,特定场景的性能会有一定的提升。另外,erlang运行时系统中内存分配可调整的参数还有很多,比如内存分配算法,比如mbc池的策略等等。有兴趣的朋友也可以研究并实测调优下。