打起来了~ 最小SOTA模型:Mistral 7B,各方面碾压LLaMA2 13B和LLaMA1 34B

深度学习自然语言处理 分享
Mistral AI团队自豪地发布了Mistral 7B,这是迄今为止尺寸最小的最强大的语言模型。
进NLP群—>加入NLP交流群
Mistral 7B简介
Mistral 7B是一个73亿参数的模型,具有以下特点:
在所有基准测试上优于Llama 2 13B
在许多基准测试上优于Llama 1 34B
在代码方面接近CodeLlama 7B的性能,同时在英语任务上表现良好
使用分组查询注意力(GQA)以加快推断速度
使用滑动窗口注意力(SWA)以更小的成本处理更长的序列
我们以Apache 2.0许可证发布Mistral 7B,可以无限制地使用。
通过我们的参考实现[1],下载[2]并在任何地方(包括本地)使用它
使用vLLM推理服务器[3]和skypilot在任何云上部署它(AWS/GCP/Azure)
在HuggingFace[4]上使用它
Mistral 7B易于在任何任务上进行微调。作为演示,我们提供了一个针对聊天进行微调的模型,其性能优于Llama 2 13B聊天模型。
性能详细信息
我们将Mistral 7B与Llama 2系列进行了比较,并重新运行了所有模型的评估,以进行公平比较。

Mistral 7B和不同的Llama模型在各种基准测试上的性能。为了进行准确比较,所有模型的所有指标都经过我们的评估流程重新评估。Mistral 7B在所有指标上明显优于Llama 2 13B,并与Llama 34B相当(由于Llama 2 34B未发布,我们报告了Llama 34B的结果)。在代码和推理基准测试方面,它也远远超越了其他模型。
这些基准测试按主题分类如下:
常识推理:Hellaswag、Winogrande、PIQA、SIQA、OpenbookQA、ARC-Easy、ARC-Challenge和CommonsenseQA的0-shot。
世界知识:NaturalQuestions和TriviaQA的5-shot。
阅读理解:BoolQ和QuAC的0-shot。
数学:8-shot GSM8K with maj@8和4-shot MATH with maj@4
代码:Humaneval的0-shot和3-shot MBPP
热门汇总结果:5-shot MMLU,3-shot BBH以及3-5-shot AGI Eval(仅包含英语多项选择问题)

一个有趣的指标,用于比较模型在成本/性能平面上的表现,是计算“等效模型大小”。在推理、理解和STEM推理(MMLU)方面,Mistral 7B的性能相当于比它大3倍多的Llama 2。这意味着在内存节省和吞吐量增加方面获得了相当大的优势。
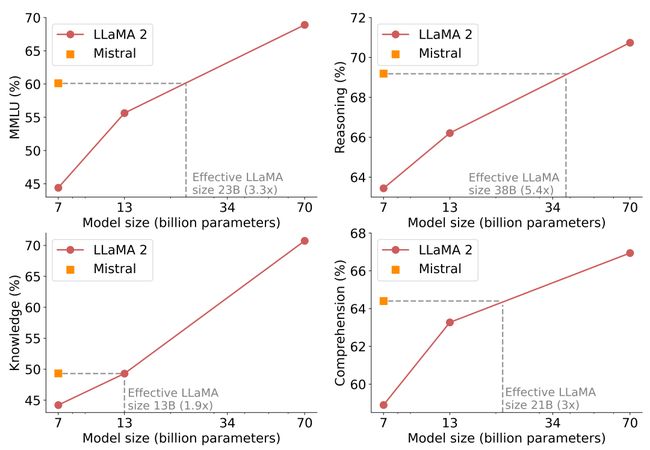
Mistral 7B和Llama 2(7B/13/70B)在MMLU、常识推理、世界知识和阅读理解方面的结果。Mistral 7B在所有评估中大部分都优于Llama 2 13B,只有在知识基准测试中表现相当(这可能是由于其有限的参数数量,限制了它可以压缩的知识量)。
注意:我们的评估与LLaMA2论文的评估之间存在重要差异:
对于MBPP,我们使用手动验证的子集
对于TriviaQA,我们没有提供维基百科的上下文信息
Flash and Furious: 注意力漂移
Mistral 7B使用滑动窗口注意力(SWA)机制(Child等,Beltagy等),其中每个层次关注前4,096个隐藏状态。主要的改进,也是最初进行研究的原因,是计算成本线性为O(sliding_window.seq_len)。在实际应用中,对FlashAttention和xFormers所做的更改使得在序列长度为16k且窗口为4k的情况下,速度提高了2倍。非常感谢Tri Dao和Daniel Haziza在紧张的时间表上帮助包括这些更改。
滑动窗口注意力利用了Transformer的堆叠层,以便在窗口大小之外的过去进行关注:第k层的tokens i关注第k-1层的tokens [i-sliding_window, i]。这些tokens关注tokens [i-2*sliding_window, i]。较高的层次具有比注意力模式所涉及的更远过去的信息。
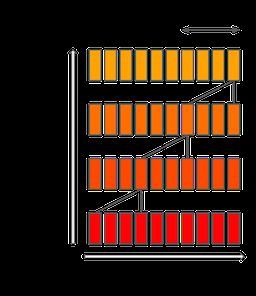
最后,固定的注意力跨度意味着我们可以将我们的缓存限制为sliding_window tokens的大小,使用旋转缓冲区(更多信息请阅读我们的参考实现存储库[5])。这在长度为8192的序列上进行推断时可以节省一半的缓存内存,而不会影响模型质量。
对Mistral 7B进行聊天微调
为了展示Mistral 7B的泛化能力,我们对其进行了微调,使用了HuggingFace上公开可用的指令数据集。没有花招,也没有专有数据。结果模型,Mistral 7B Instruct[6],在MT-Bench[7]上优于所有7B模型,并与13B聊天模型相媲美。
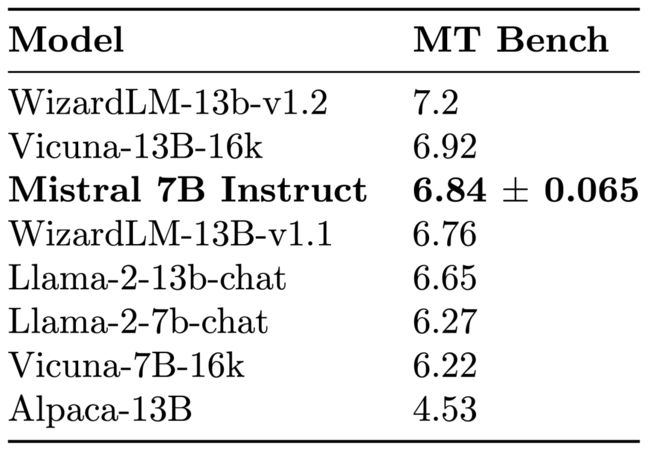
Mistral 7B Instruct模型是一个快速演示,它表明基础模型可以轻松进行微调,以实现引人入胜的性能。我们期待与社区合作,探讨使这些模型最终遵守监管框架的方法,以便在需要进行输出监管的环境中部署。
本文参考原文地址[8]。
参考资料
[1]
reference implementation: https://github.com/mistralai/mistral-src
[2]下载: https://files.mistral-7b-v0-1.mistral.ai/mistral-7B-v0.1.tar
[3]inference server and skypilot: https://docs.mistral.ai/cloud-deployment/skypilot
[4]HuggingFace: https://huggingface.co/mistralai
[5]reference implementation repo: https://github.com/mistralai/mistral-src
[6]Mistral 7B Instruct: https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.1
[7]MT-Bench: https://arxiv.org/abs/2306.05685
[8]原文地址: https://mistral.ai/news/announcing-mistral-7b/
进NLP群—>加入NLP交流群