Linux多线程服务端编程:使用muduo C++网络库 学习笔记 第七章 muduo编程示例(上)
本章将介绍如何用muduo网络库完成常见的TCP网络编程任务。内容如下:
1.[UNP]中的五个简单协议,包括echo、daytime、time、discard、chargen等。
2.文件传输,示范非阻塞TCP网络程序中如何完整地发送数据。
3.Boost.Asio中的示例,包括timer2~6、chat等。chat实现了TCP封包与拆包(codec,coder-decoder的简称,编解码器)。
4.muduo Buffer class的设计与使用。
5.Protobuf(Protobuf(Protocol Buffers)是一种轻量级、高效、灵活的数据序列化格式,专门用于结构化数据序列化,通常用于数据存储、通信协议等领域)编码解码器(codec)与消息分发器(dispatcher)。
6.限制服务器的最大并发连接数。
7.Java Netty(Java Netty 是一个高性能异步事件驱动的网络通信框架,基于NIO( Non-blocking I/O(非阻塞式I/O),是Java 1.4版本中引入的一种新的I/O模型)实现)中的示例,包括discard、echo、uptime等,其中的discard和echo带流量统计功能。
8.用于测试两台机器的往返延迟的roundtrip。
9.用timing wheel踢掉空闲连接。
10.一个基于TCP的应用层广播hub(中心、枢纽)。
11.云风的串并转换连接服务器multiplexer(将多个网络连接合并成一个单一连接的工具),及其自动化测试。
12.socks4a(Socks4a是一种代理服务器协议,它在Socks4协议基础上增加了域名解析功能)代理服务器,包括简单的TCP中继(relay)。
13.一个提供短址服务的httpd服务器(指能够通过URL缩短服务来缩短链接长度的Web服务器,这种服务器可以通过将长URL(Uniform Resource Locator)转换成短URL,从而在转发网址时提供更简洁的链接)。
14.与其他库的集成,包括UDNS(Micro DNS library是一个非常轻量级和快速的DNS解析库,用于解析DNS域名和IP地址之间的映射关系,UDNS的设计目标是尽可能小巧、简单和高效,它只包含核心的DNS解析功能,不含任何与DNS相关的高级特性)、c-ares DNS(一个异步DNS解析库)、curl(C/C++语言编写的多协议文件传输库,主要用于向Web服务器发送HTTP/HTTPS请求,支持FTP、SMTP、POP3(Post Office Protocol version 3,是一种用于接收电子邮件的协议)、IMAP(一种用于接收和管理电子邮件的协议,IMAP协议主要用于在服务器和邮件客户端之间进行通信,为用户提供了更加灵活和强大的邮件管理和同步功能)等多种协议)等。
以上例子都比较简单,逻辑不复杂,代码也很短,适合摘取关键部分放到博客上。其中一些有一定的代表性和针对性,比如“如果传输完整的文件”估计是网络编程的初学者经常遇到的问题。请注意,muduo是设计来开发内网的网络程序,它没有做任何安全方面的加强措施,如果用在公网上可能会受到攻击,后面的例子会谈到这一点。
接下来介绍五个简单TCP网络服务程序,简介如下:
1.discard(RFC 863):丢弃所有收到的数据。
2.daytime(RFC 867):服务端accept连接之后,以字符串形式发送当前时间,然后主动断开连接。
3.time(RFC 868):服务端accep连接之后,以二进制形式发送当前时间(从Epoch到现在的秒数),然后主动断开连接;我们需要一个客户程序来把收到的时间转换为字符串。
4.echo(RFC 863):回显服务,把收到的数据发回客户端。
5.chargen(RFC 864):服务端accept连接之后,不停地发送测试数据。
以上五个协议使用不同的端口,可以放到同一个进程中实现,且不必使用多线程。完整代码见muduo/examples/simple。
discard恐怕是最简单的长连接TCP应用层协议,它只需要关注“三个半事件”中的“消息/数据到达”事件,事件处理函数如下:
void DiscardServer::onMessage(const TcpConnectionPtr &conn, Buffer *buf, Timestamp time)
{
string msg(buf->retrieveAllAsString()));
LOG_INFO << conn->name() << " discards " << msg.size() << " bytes received at " << time.toString();
}
与第六章中的echo服务相比,除了省略namespace外,关键的区别在于少了将收到的数据发回客户端。
剩下的都是例行公事的代码,此处从略,可对比参考第六章中的echo服务。
daytime是短连接协议,在发送完当前时间后,由服务端主动断开连接。它只需要关注“三个半事件”中的“连接已建立”事件,事件处理函数如下:
void DaytimeServer::onConnection(const TcpConnectionPtr &conn)
{
LOG_INFO << "DaytimeServer - " << conn->peerAddress().toIpPort() << " -> "
<< conn->localAddress().toIpPort() << " is "
<< (conn->connected() ? "UP" : "DOWN");
if (conn->connected())
{
// 发送时间字符串
conn->send(Timestamp::now().toFormattedString() + "\n");
// 主动断开连接
conn->shutdown();
}
}
剩下的都是例行公事的代码,为节省篇幅,此处从略。
用netcat扮演客户端,运行结果如下:
![]()
time协议与daytime极为类似,只不过它返回的不是日期时间字符串,而是一个32-bit整数,表示从1970-01-01 00:00:00Z(Z表示协调世界时(UTC)的时区,也称为格林威治标准时间(GMT))到现在的秒数。当然,这个协议有“2038年问题”。服务端只需要关注“三个半事件”中的“连接已建立”事件,事件处理函数如下:
void TimeServer::onConnection(const muduo::net::TcpConnectionPtr &conn)
{
LOG_INFO << "TimeServer - " << conn->peerAddress().toIpPort() << " -> "
<< conn->localAddress().toIpPort() << " is "
<< (conn->connected() ? "UP" : "DOWN");
if (conn->connected())
{
// time函数目前看没有被重新定义,可以不用加::前缀
// ::前缀的含义是指示全局作用域,即调用C标准库中的time函数
// 取当前时间
time_t now = ::time(NULL);
// 将当前时间转换为网络字节序(Big Endian)
int32_t be32 = sockets::hostToNetwork32(static_cast<int32_t>(now));
// 发送32-bit整数
conn->send(&be32, sizeof be32);
// 主动断开连接
conn->shutdown();
}
}
剩下的都是例行公事的代码,为节省篇幅,此处从略。
用netcat扮演客户端,并用hexdump命令(它将文件的内容以十六进制显示在终端上)来打印二进制数据,运行结果如下:
![]()
上图中,-C选项还会输出文件的ASCII码形式。
因为time服务端发送的是二进制数据,不便直接阅读,我们编写一个客户端来解析并打印收到的4个字节数据。这个程序只需要关注“三个半事件”中的“消息/数据到达”事件,客户的事件处理函数如下:
void onMessage(const TcpConnectionPtr &conn, Buffer *buf, Timestamp receiveTime)
{
if (buf->readableBytes() >= sizeof(int32_t))
{
const void *data = buf->peek();
int32_t be32 = *static_cast<const int32_t *>(data);
buf->retrieve(sizeof(int32_t));
time_t time = sockets::networkToHost32(be32);
Timestamp ts(time * TimeStamp::kMicroSecondsPerSecond);
LOG_INFO << "Server time = " << time << ", " << ts.toFormattedString();
}
else
{
LOG_INFO << conn->name() << " no enough data " << buf->readableBytes()
<< " at " << receiveTime.toFormattedString();
}
}
注意其中考虑到了如果数据没有一次性收全,已经收到的数据会累积在Buffer里(在else分支里没有调用Buffer::retrieve*系列函数),以等待后续数据到达,程序也不会阻塞。这样即便服务器一个字节一个字节地发送数据,代码还是能正常工作,这也是非阻塞网络编程必须在用户态使用接收缓冲的主要原因。
这是我们第一次用到TcpClient class,完整的代码如下:
class TimeClient : boost::noncopyable
{
public:
TimeClient(EventLoop *loop, const InetAddress &serverAddr) :
loop_(loop), client_(loop, serverAddr, "TimeClient")
{
client_.setConnectionCallback(boost::bind(&TimeClient::onConnection, this, _1));
client_.setMessageCallback(boost::bind(&TimeClient::onMessage, this, _1, _2, _3));
// client_.enableRetry();
}
void connect()
{
client_.connect();
}
private:
EventLoop *loop_;
TcpClient client_;
void onConnection(const TcpConnectionPtr &conn)
{
LOG_INFO << conn->localAddress().toIpPort() << " -> "
<< conn->peerAddress().toIpPort() << " is "
<< (conn->connected() ? "UP" : "DOWN");
if (!conn->connected())
{
// 如果连接断开,就退出事件循环,程序也就终止了
loop_->quit();
}
}
};
int main(int argc, char *argv[])
{
LOG_INFO << "pid = " << getpid();
if (argc > 1)
{
EventLoop loop;
InetAddress serverAddr(argv[1], 2037);
TimeClient timeClient(&loop, serverAddr);
timeClient.connect();
loop.loop();
}
else
{
printf("Usage: %s host_ip\n", argv[0]);
}
}
注意TcpConnection对象(指的可能是以上代码中,TcpConnectionPtr参数所指向的变量)表示“一次”TCP连接,连接断开之后不能重建。TcpClient重试之后新建的链接会是另一个TcpConnection对象。
程序的运行结果如下(有折行),假设time server运行在本机:
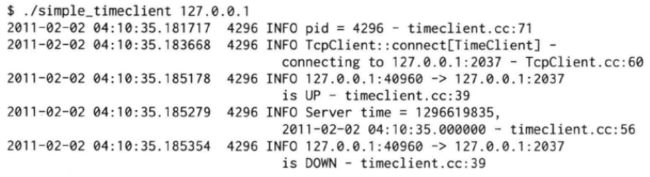
前面几个协议都是单向接收或发送数据,echo是我们遇到的第一个双向的协议:服务端把客户端发过来的数据原封不动地传回去。它只需要关注“三个半事件”中的“消息/数据到达”事件,事件处理函数已在第六章列出,这里复制一遍:
void EchoServer::onMessage(const muduo::net::TcpConnectionPtr &conn, muduo::net::Buffer *buf,
muduo::Timestamp time)
{
muduo::string msg(buf->retrieveAllAsString());
LOG_INFO << conn->name() << " echo " << msg.size() << " bytes, "
<< "data received at " << time.toString();
conn->send(msg);
}
这段代码实现的不是行回显(line echo)服务,而是有一点数据就发送一点数据。这样可以避免客户端恶意地不发送换行字符,而服务端又必须缓存已经收到的数据,导致服务器内存暴涨。但这个程序还是有一个安全漏洞,即如果客户端故意不断发送数据,但从不接收,那么服务端的发送缓冲区会一直堆积,导致内存暴涨。解决办法可以参考下面的chargen协议,或者在发送缓冲区累积到一定大小时主动断开连接。一般来说,非阻塞网络编程中正确处理数据发送比接收数据要困难,因为要应对对方接受缓慢的情况。
Chargen协议很特殊,它只发送数据,不接收数据。而且,它发送数据的速度不能快过客户端接收的速度,因此需要关注“三个半事件”中的半个“消息/数据发送完毕”事件(onWriteComplete),事件处理函数如下:
void ChargenServer::onConnection(const TcpConnectionPtr &conn)
{
LOG_INFO << "ChargenServer - " << conn->peerAddress().toIpPort() << " -> "
<< conn->localAddress().toIpPort() << " is "
<< (conn->connected() ? "UP" : "DOWN");
if (conn->connected())
{
conn->setTcpNoDelay(true);
// 连接建立时,发生第一次数据
conn->send(message_);
}
}
void ChargenServer::onMessage(const TcpConnectionPtr &conn, Buffer *buf, Timestamp time)
{
string msg(buf->retrieveAllAsString());
LOG_INFO << conn->name() << " discards " << msg.size()
<< " bytes received at " << time.toString();
}
void ChargenServer::onWriteComplete(const TcpConnectionPtr &conn)
{
transferred_ += message_.size();
// 继续发送数据
conn->send(message_);
}
剩下的都是例行公事的代码,为节省篇幅,此处从略。
完整的chargen服务端还带流量统计功能,用到了定时器,我们会在后面介绍定时器的使用,到时候再回头来看相关代码。
用netcat扮演客户端,运行结果如下:


前面五个程序都用到了EventLoop。这其实是个Reactor,用于注册和分发IO事件。muduo遵循one loop per thread模型,多个服务端(TcpServer)和客户端(TcpClient)可以共享同一个EventLoop,也可以分配到多个EventLoop上以发挥多核多线程的好处。这里我们把五个服务端用同一个EventLoop跑起来,程序还是单线程的,功能却强大了很多:
int main()
{
LOG_INFO << "pid = " << getpid();
EventLoop loop; // one loop shared by multiple servers
ChargenServer chargenServer(&loop, InetAddress(2019));
chargenServer.start();
DaytimeServer daytimeServer(&loop, InetAddress(2013));
daytimeServer.start();
DiscardServer discardServer(&loop, InetAddress(2009));
discardServer.start();
EchoServer echoServer(&loop, InetAddress(2007));
echoServer.start();
TimeServer timeServer(&loop, InetAddress(2037));
TimeServer.start();
loop.loop();
}
这个例子充分展示了Reactor模式复用线程的能力,让一个单线程程序同时具备多个网络服务功能。一个容易想到的例子是httpd同时侦听80端口(HTTP服务)和443端口(HTTPS服务,而端口8080通常用于HTTP代理服务器服务),另一个例子是程序中有多个TcpClient,分别和数据库、Redis、Sudoku Solver等后台服务打交道。对于初次接触这种编程模型的读者,值得跟踪代码运行的详细过程,弄清楚每个事件每个回调发生的时机与条件。
以上几个协议的消息格式都非常简单,没有涉及TCP网络编程中常见的分包处理,后文讲Boost.Asio的聊天服务器时我们再来讨论这个问题。
下面用发送文件的例子来说明TcpConnection::send()的使用。到目前为止,我们用到了TcpConnection::send()的两个重载,分别是send(const string &)和send(const void *message, size_t len)。
TcpConnection目前提供了三个send重载函数,原型如下:
///
/// TCP connection, for both client and server usage.
///
class TcpConnection : boost::noncopyable, pulic boost::enable_shared_from_this<TcpConnection>
{
public:
void send(const void *message, size_t len);
void send(const StringPiece &message);
void send(Buffer *message); // this one might swap data without copying
// void send(Buffer &&message); // C++11
// void send(string &&message); // C++11
};
在非阻塞网络编程中,发送消息通常是由网络库完成的,用户代码不会直接调用write(2)或send(2)等系统调用。原因见下文。在使用TcpConnection::send()时值得注意的有几点:
1.send()的返回类型是void,意味着用户不必关心调用send()时成功发送了多少字节,muduo库会保证把数据发送给对方。
2.send()是非阻塞的。意味着客户代码只管把一条消息准备好,调用send()来发送,即便TCP的发送窗口满了,也绝对不会阻塞当前调用线程。
3.send()是线程安全、原子的。多个线程可以同时调用send(),消息之间不会混叠或交织。但是多个线程同时发送的消息的先后顺序是不确定的,muduo只能保证每个消息本身的完整性(假设两个线程同时各自发送了一条任意长度的消息,那么这两条消息a、b的发送顺序要么是先a后b,要么是先b后a,不会出现“a的前一半,b,a的后一半”这种交织情况)。另外,send()在多线程下仍然是非阻塞的。
4.send(const void *message, size_t len)这个重载最平淡无奇,可以发送任意字节序列。
5.send(const StringPiec &message)这个重载可以发送std::string和const char *,其中String Piece是Google发明的专门用于传递字符串参数的class,这样程序里就不必为const char *和const std::string &提供两份重载了。
6.send(Buffer *)有点特殊,它以指针为参数,而不是常见的const引用,因为函数中可能用Buffer::swap()来高效地交换数据,避免内存拷贝(目前的代码没有照此办理),起到类似C++右值引用的效果。
7.如果将来支持C++11,那么可以增加对右值引用的重载,这样可以用move语义来避免内存拷贝。
下面实现一个发送文件的命令行小工具,这个工具的协议很简单,在启动时通过命令行参数指定要发送的文件,然后再2021端口侦听,每当有新连接进来,就把文件内容完整地发送给对方。
如果不考虑并发,那么这个功能用netcat加重定向就能实现。这里展示的版本更加健壮,比方说发送100MB的文件,支持上万个并发客户连接;内存消耗只与并发连接数有关,跟文件大小无关;任何连接可以在任何时候断开,不会有内存泄漏或崩溃。
作者一共写了三个版本,代码位于examples/filtransfer:
1.一次性把文件读入内存,一次性调用send(const string &)发送完毕。这个版本满足除了“内存消耗只与并发连接数有关,跟文件大小无关之外的健壮性要求”。
2.一块一块地发送文件,减少内存使用,用到了WriteCompleteCallback。这个版本满足了上述全部健壮性要求。
3.同2,但是采用shared_ptr来管理FILE*,避免手动调用::fclose(3)。
版本一:在建立好连接之后,把文件的全部内容读入一个string,一次性调用TcpConnection::send()发送。不用担心文件发送不完整。也不用担心send()之后立刻shutdown()(TcpConnection的shutdown成员函数,而非::shutdown())会有什么问题(见后文说明):
const char *g_file = NULL;
string readFile(const char *filename); // read file content to string
void onConnection(const TcpConnectionPtr &conn)
{
LOG_INFO << "FileServer - " << conn->peerAddress().toIpPort() << " -> "
<< conn->localAddress().toIpPort() << " is "
<< (conn->connected() ? "UP" : "DOWN");
if (conn->connected())
{
LOG_INFO << "FileServer - Sending file " << g_file
<< " to " << conn->peerAddress().toIpPort()
string fileContent = readFile(g_file);
conn->send(fileContent);
conn->shutdown();
LOG_INFO << "FileServer - done";
}
}
int main(int argc, char *argv[])
{
LOG_INFO << "pid = " << getpid();
if (argc > 1)
{
g_file = argv[1];
EventLoop loop;
InetAddress listenAddr(2021);
TcpServer server(&loop, listenAddr, "FileServer");
server.setConnectionCallback(onConnection);
server.start();
loop.loop()
}
else
{
fprintf(stderr, "Usage: %s file_for_downloading\n", argv[0]);
}
}
注意每次建立连接的时候我们都去重新读一遍文件,这是考虑到文件有可能被其他程序修改。如果文件是immutable的,整个程序就可以共享同一个fileContent对象。
这个版本有一个明显的缺陷,即内存消耗与(并发连接数×文件大小)成正比,文件越大内存消耗越多,如果文件大小上GB,那几乎就是灾难了。只需要建立少量并发连接就能把服务器内存耗尽,因此我们有了版本二。
版本二:为了解决版本一占用内存过多的问题,我们采用流水线的思路,当新建连接时,先发送文件的前64KiB数据,等这块数据发送完毕时再继续发送下64KiB数据,如此往复直到文件内容全部发送完毕。代码中使用了TcpConnection::setContext()和getContext()来保存TcpConnection的用户上下文(这里是FILE *),因此不必使用额外的std::map来记住每个连接的当前文件位置:
const int kBufSize = 64 * 1024;
const char *g_file = NULL;
void onConnection(const TcpConnectionPtr &conn)
{
LOG_INFO << "FileServer - " << conn->peerAddress().toIpPort() << " -> "
<< conn->localAddress().toIpPort() << " is "
<< (conn->connected() ? "UP" : "DOWN");
if (conn->connected())
{
LOG_INFO << "FileServer - Sending file " << g_file
<< " to " << conn->peerAddress().toIpPort();
conn->setHighWaterMarkCallback(onHighWaterMark, kBufSize + 1);
// 以二进制只读模式打开
FILE *fp = ::fopen(g_file, "rb");
if (fp)
{
conn->setContext(fp);
char buf[kBufSize];
// 每次从fp中读1个sizeof buf大小到buf
size_t nread = ::fread(buf, 1, sizeof buf, fp);
conn->send(buf, nread);
}
else
{
conn->shutdown();
LOG_INFO << "FileServer - no such file";
}
}
else
{
if (!conn->getContext().empty())
{
FILE *fp = boost::any_cast<FILE *>(conn->getContext());
if (fp)
{
::fclose(fp);
}
}
}
}
// 在onWriteComplete()回调函数中读取下一块文件数据,继续发送
void onWriteComplete(const TcpConnectionPtr &conn)
{
FILE *fp = boost::any_cast<FILE *>(conn->getContext());
char buf[kBufSize];
size_t nread = ::fread(buf, 1, sizeof buf, fp);
if (nread > 0)
{
conn->send(buf, nread);
}
else
{
::fclose(fp);
fp = NULL;
conn->setContext(fp);
conn->shutdown();
LOG_INFO << "FileServer - done";
}
}
注意每次建立连接的时候我们都去重新打开那个文件,使得程序中文件描述符的数量翻倍(每个连接占一个socket fd和一个file fd)(每个连接多2个文件描述符,为什么是翻倍?),这是考虑到文件有可能被其他程序修改。如果文件是immutable的,一种改进措施是:整个程序可以共享同一个文件描述符,然后每个连接记住自己当前的偏移量,在onWriteComplete()回调函数里用pread(2)函数来读数据。
这个版本也存在一个问题,如果客户端故意只发起连接,不接收数据,那么要么把服务器进程的文件描述符耗尽,要么占用很多服务端内存(因为每个连接有64KiB的发送缓冲区)。解决办法可参考后文“限制服务器的最大并发连接数”和“用timing wheel踢掉空闲连接”。必须说明的是,muduo并不是设计来编写面向公网的网络服务程序,这种服务程序需要在安全性方面下很多工夫,作者对此不在行,作者更关心实现内网(不一定是局域网)的高效服务程序。
版本三:用shared_ptr的custom deleter来减轻资源管理负担,使得FILE *的生命期和TcpConnection一样长,代码也更简单了:
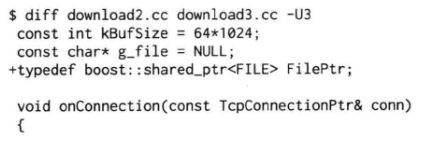

以上代码体现了现代C++的资源管理思路,即无须手动释放资源,而是通过将资源与对象生命期绑定,在对象析构的时候自动释放资源,从而把资源管理转换为对象生命期管理,而后者是早已解决了的问题。这正是C++最重要的编程技法:RAII。
作者曾收到一位网友的来信:“在simple的daytime示例中,服务端主动关闭时调用的是如下函数序列,这不是只是关闭了连接上的写操作吗,怎么是关闭了整个连接?”:
void DaytimeServer::onConnection(const muduo::net::TcpConnectionPtr &conn)
{
if (conn->connected())
{
conn->send(Timestamp::now().toFormattedString() + "\n");
conn->shutdown(); // 调用TcpConnection::shutdown()
}
}
void TcpConnection::shutdown()
{
if (state_ == kConnected)
{
setState(kDisconnecting);
// 调用TcpConnection::shuwdownInLoop()
loop_->runInLoop(boost::bind(&TcpConnection::shutdownInLoop, this));
}
}
void TcpConnection::shutdownInLoop()
{
loop_->assertInLopThread();
// 如果当前没有发送数据
if (!channel_->isWriting())
{
// we are not writing
socket_->shutdownWrite(); // 调用Socket::shutdownWrite()
}
}
void Socket::shutdownWrite()
{
sockets::shutdownWrite(sockfd_);
}
void sockets::shutdownWrite(int sockfd)
{
int ret = ::shutdown(sockfd, SHUT_WR);
// 检查错误
}
作者答复如下:muduo TcpConnection没有提供close(),而只提供shutdown(),这么做是为了收发数据的完整性。
TCP是一个全双工协议,同一个文件描述符既可读又可写,shutdownWrite()关闭了“写”方向的连接,保留了“读”方向,这称为TCP half-close。如果直接close(socket_fd),那么socket_fd就不能读或写了。
用shutdown而不用close的效果是,如果对方已经发送了数据,这些数据还“在路上”,那么muduo不会漏收这些数据。换句话说,muduo在TCP这一层解决了“当你打算关闭网络连接的时候,如何得知对方是否发了一些数据而你还没有收到?”这一问题。当然,这个问题也可以在上面的协议层解决,双方商量好不再互发数据,就可以直接断开连接。
也就是说muduo把“主动关闭连接”这件事情分成两步来做,如果要主动关闭连接,它会先关本地“写”端,等对方关闭之后,再关本地“读”端。
如果被动关闭,muduo会在read(2)返回0的时候回调connection callback,这样客户代码就知道对方断开连接了。
另外,如果当前output buffer里还有数据尚未发出的话,muduo也不会立刻调用shutdownWrite,而是等到数据发送完毕再shutdown,可以避免对方漏收数据。
void TcpConnection::handleWrite()
{
loop_->assertInLoopThread();
if (channel_->isWriting())
{
ssize_t n = sockets::write(channel_->fd(), outputBuffer_.peek(), outputBuffer_.readableBytes());
if (n > 0)
{
outputBuffer_.retrieve(n);
if (outputBuffer_.readableBytes() == 0)
{
if (writeCompleteCallback_)
{
loop_->queueInLoop(boost::bind(writeCompleteCallback_, shared_from_this()));
}
if (state_ == kDisconnecting)
{
shutdownInLoop();
}
}
}
}
}
muduo这种关闭连接的方式对对方也有要求,那就是对方read()到0字节后会主动关闭连接(无论是shutdownWrite()还是close()),一般的网络程序都会这样,不是什么问题。当然,这么做有一个潜在的安全漏洞,万一对方故意不关闭连接,那么muduo的连接就一直半开着,消耗系统资源。必要时可以调用TcpConnection::handleClose()来强行关闭连接,这需要将handleClose()改为public成员函数。
完整的流程如下图:
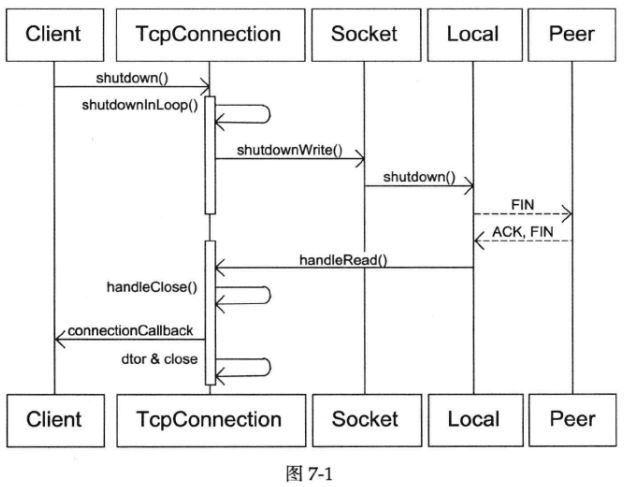
我们发完了数据,于是调用shutdownWrite,发送TCP FIN分节,对方会读到0字节,然后对方通常会关闭连接。这样muduo会读到0字节,然后muduo关闭连接。在shutdown()之后,muduo回调connection callback的时间间隔大约是一个round-trip time,因为需要和对端交换FIN和ACK。
如果有必要,对方可以在read()返回0之后继续发送数据,这是直接利用了half-close TCP连接。muduo不会漏收这些数据。
那么muduo什么时候真正close socket呢?在TcpConnection对象析构的时候。TcpConnection持有一个Socket对象,Socket是一个RAII handler,它的析构函数会close(sockfd_)。这样,如果发生TcpConnection对象泄漏,那么我们从/proc/pid/fd/就能找到没有关闭的文件描述符,便于差错。
muduo在read()返回0的时候会回调connection callback,TcpServer或TcpClient把TcpConnection的引用计数减1。如果引用计数降到0,则表明用户代码也不持有TcpConnection,它就会析构了。
在网络编程中,应用程序发送数据往往比接收数据简单(实现非阻塞网络库正相反,发送比接收难),后面再谈接收并解析消息的要领。
下面介绍一个与Boost.Asio的示例代码中的聊天服务器功能类似的网络服务程序,包括客户端与服务端的muduo实现。这个例子的主要目的是介绍如何处理分包,并初步涉及muduo的多线程功能。聊天服务器代码位于examples/asio/chat/。
上面“五个简单TCP示例”中处理的协议没有涉及分包,在TCP这种字节流协议上做应用层分包是网络编程的基本需求。分包指的是在发生一个消息(message)或一帧(frame)数据时,通过一定的处理,让接收方能从字节流中识别并截取(还原)出一个个消息。“粘包问题”是个伪问题。
对于短连接的TCP服务,分包不是一个问题,只要发送方主动关闭连接,就表示一条消息发送完毕,接收方read()返回0,从而知道消息的结尾。例如上面的daytime和time协议。
对于长连接的TCP服务,分包有四种方法:
1.消息长度固定,比如muduo的roundtrip示例就采用了固定的16字节消息。
2.使用特殊的字符或字符串作为消息的边界,例如HTTP协议的handers以“\r\n”为字符的分隔符。
3.在每条消息的头部加一个长度字段,这恐怕是最常见的做法,下面的聊天协议也采用这一办法。
4.利用消息本身的格式来分包,例如XML格式的消息中
在下面的代码讲解中还会仔细讨论用长度字段分包的常见陷阱。
下面实现的聊天服务非常简单,由服务端程序和客户端程序组成,协议如下:
1.服务端程序在某个端口侦听(listen)新的连接。
2.客户端向服务端发起连接。
3.连接建立之后,客户端碎石准备接收服务端的消息并在屏幕上显示出来。
4.客户端接受键盘输入,以回车为界,把消息发送给服务端。
5.服务端接收到消息之后,依次发送给每个连接到它的客户端;原来发送消息的客户端进程也会收到这条消息。
6.一个服务端进程可以同时服务多个客户端进程。当有消息到达服务端后,每个客户端进程都会收到同一条消息,服务端广播发送消息的顺序是任意的,不一定哪个客户端会先收到这条消息。
7.(可选)如果消息A先于消息B到达服务端,那么每个客户都会先收到A再收到B。
这实际上是一个简单的基于TCP的应用层广播协议,由服务端负责把消息发送给每个连接到它的客户端。参与“聊天”的既可以是人,也可以是程序。后面作者将介绍一个稍微复杂一点的例子hub,它有“聊天室”的功能,客户端可以注册特定的topics,并往某个topic发送消息,这样代码更有意思。
作者在“谈一谈网络编程学习经验”(附录A)中把聊天服务列为“最主要的三个例子”之一,其与前面的“五个简单TCP协议”不同,聊天服务的特点是“连接之间的数据有交流,从a连接收到的数据要发给b连接。这样对连接管理提出了更高的要求:如何用一个程序同时处理多个连接?fork()-per-connection似乎是不行的。如何防止串话?b有可能随时断开连接,而新建立的连接c可能恰好复用了b的文件描述符,那么a会不会错误地把消息发给c?”,muduo的这个例子充分展示了解决以上问题的手法。
本聊天服务的消息格式非常简单,“消息”本身是一个字符串,每条消息有一个4字节的头部,以网络序存放字符串的长度。消息之间没有间隙,字符串也不要求以’\0’结尾。比方说有两条消息“hello”和“chenshuo”,那么打包后的字节楼共有21字节:
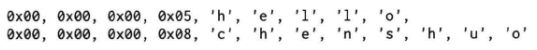
以下代码把string message打包为muduo::net::Buffer,并通过conn发送。由于这个codec的代码位于头文件中,因此反复出现了muduo::net namespace(头文件中不要using namespace,否则会影响到引用这个头文件的代码):
void send(muduo::net::TcpConnection *conn, const muduo::StringPiece &message)
{
muduo::net::Buffer buf;
buf.append(message.data(), message.size());
int32_t len = static_cast<int32_t>(message.size());
int32_t be32 = muduo::net::sockets::hostToNetwork32(len);
buf.prepend(&be32, sizeof be32);
conn->send(&buf);
}
muduo Buffer有一个很好的功能,它在头部预留了8字节的空间,这样以上代码中的prepend()操作就不需要移动已有的数据,效率较高。
解析数据往往比生成数据更复杂,分包、打包也不例外:
void onMessage(const muduo::net::TcpConnectionPtr &conn, muduo::net::Buffer *buf,
muduo::Timestamp receiveTime)
{
// 反复读取数据,直到Buffer中的数据不够一条完整的消息
// 如果换成if,那么一次数据到达只能读出一条消息,如果本次到达了2条消息,就读不到后面那条了
while (buf->readableBytes() >= kHeaderLen) // kHeaderLen == 4
{
// FIXME: use Buffer::peekInt32();
const void *data = buf->peek();
// 此处有潜在的问题,在某些不支持非对齐内存访问的体系结构上会造成SIGBUS core dump
// 总线错误信号是操作系统向进程发送的一种异常信号,用于指示进程在访问内存时出现了错误
// 特别是与系统总线有关的错误
// 此处读取消息长度应该改用Buffer::peekInt32()
int32_t be32 = *static_cast<const int32_t *>(data); // SIGBUS
const int32_t len = muduo::net::sockets::networkToHost32(be32);
if (len > 65536 || len < 0)
{
LOG_ERROR << "Invalid length " << len;
conn->shutdown(); // FIXME: disable reading
break;
}
else if (buf->readableBytes() >= len + kHeaderLen)
{
buf->retrieve(kHeaderLen);
// 构造完整的消息
muduo::string message(buf->peek(), len);
// 回调用户代码
messageCallback_(conn, message, receiveTime);
buf->retrieve(len);
}
else
{
break;
}
}
}
以前面提到的两条消息的字节流为例:

假设数据最终全部到达,onMessage()至少要能正确处理以下各种数据到达的次序,每种情况下messageCallback_都应该被调用两次:
1.每次收到一个字节的数据,onMessage()被调用21次。
2.数据分两次到达,第一次收到2个字节,不足消息的长度字段。
3.数据分两次到达,第一次收到4个字节,刚好够长度字段,但是没有body。
4.数据分两次到达,第一次收到8个字节,长度完整,但body不完整。
5.数据分两次到达,第一次收到9个字节,长度完整,body也完整。
6.数据分两次到达,第一次收到10个字节,第一条消息的长度完整、body也完整,第二条消息长度不完整。
7.请自行移动和增加分割点,验证各种情况;一共有超过100万种可能(2 21 − 1 ^{21-1} 21−1)。
8.数据一次就全部到达,这是必须用while循环来读出两条消息,否则消息会堆积在Buffer中。
这个例子充分说明了non-blocking read必须和input buffer一起使用。而且在写decoder的时候一定要在收到完整的消息之后再retrieve整条消息,除非接收方使用复杂的状态机来解码。
有人评论muduo的接收缓冲区不能设置回调函数的触发条件,确实如此。每当socket可读时,muduo的TcpConnection会读取数据并存入input buffer,然后回调用户的函数。不过,一个简单的间接层就能解决问题,让用户代码只关心“消息到达”而不是“数据到达”,如下例中的LengthHeaderCodec所展示的那样:
class LengthHeaderCodec : boost::noncopyable
{
public:
typedef boost::function<void (const muduo::net::TcpConnectionPtr &, const muduo::string &message,
muduo::Timestamp)> StringMessageCallback;
explicit LengthHeaderCodec(const StringMessageCallback &cb) : messageCallback_(cb)
{
}
// onMessage()和send()同前
private:
StringMessageCallback messageCallback_;
const static size_t kHeaderLen = sizeof(int32_t);
}
这段代码把以Buffer *为参数的MessageCallback(即前面的onMessage函数)转换成了以const string &为参数的StringMessageCallback,让用户代码不必关心分包操作(用户代码即StringMessageCallback函数,传给它的内容已经分好包了),具体的调用时序见后面的图7-29。如果编程语言相同,客户端和服务端可以(应该)共享同一个codec,这样既节省工作量,又避免因对协议理解不一致而导致的错误。
聊天服务器的服务端代码小于100行,不到asio的一半。
除了经常见到的EventLoop和TcpServer,ChatServer还定义了codec_和connections_作为成员,后者存放目前已建立的客户连接。在收到消息之后,服务器会遍历整个容器,把消息广播给其中的每一个TCP链接(这是onStringMessage函数中的操作):
class ChatServer : boost::noncopyable
{
private:
// 数据成员
typedef sed::set<TcpConnectionPtr> ConnectionList;
EventLoop *loop_;
TcpServer server_;
LengthHeaderCodec codec_;
ConnectionList connections_;
public:
ChatServer(EventLoop *loop, const InetAddress &listenAddr) : loop_(loop),
server_(loop, listenAddr, "ChatServer"),
codec_(boost::bind(&CharServer::onStringMessage, this, _1, _2, _3))
{
server_.setConnectionCallback(boost::bind(&ChatServer::onConnection, this, _1));
server_.setMessageCallback(boost::bind(&LengthHeaderCodec::onMessage, &codec_, _1, _2, _3));
}
void start()
{
server_.start();
}
这里有几点值得注意,在以往的代码里是直接把本class的onMessage注册给server_;这里我们把LengthHeaderCodec::onMessage()注册给server_,然后向codec_注册了ChatServer::onStringMessage(),等于说让codec_负责解析消息,然后把完整的消息回调给ChatServer。这正是作者前面提到的“一个简单的间接层”,在不增加muduo库的复杂度的前提下,提供了足够的灵活性让我们在用户代码里完成需要的工作。
另外,server_.start()绝对不能在构造函数里调用,这么做将来会有线程安全的问题,见第一章。(即server_在构造函数中使用时,本对象(ChatServer)还没有构造完毕,而已经把this指针传给了server_)
以下是处理连接的建立和断开的代码,注意它把新建的连接加入到connections_容器中,把已断开的连接从容器中删除。这么做是为了避免内存和资源泄露, TcpConnectionPtr是boost::shared_ptr,是muduo里唯一一个默认采用shared_ptr来管理生命期的对象,第四章谈了这么做的原因(避免串话,当线程池中的任务完成时,要发送结果给客户,如果不用shared_ptr,而使用文件描述符,可能这个文件描述符已经被关闭,或关闭后又被打开了,而如果使用shared_ptr,就可以判断socket连接在处理request期间是否已经被关闭):
private:
void onCoonnection(const TcpConnectionPtr &conn)
{
LOG_INFO << conn->localAddress().toIpPtr() << " -> "
<< conn->peerAddress().toIpPtr() << " is "
<< (conn->connnected() ? "UP" : "DOWN");
if (conn->connected())
{
connections_.insert(conn);
}
else
{
connections_.erase(conn);
}
}
以下是服务端处理消息的代码,它遍历整个connections_容器,把消息打包发送给各个客户连接:
private:
// 用bind后,可以访问到private方法
void onStringMessage(const TcpConnectionPtr &, const string &message, Timestamp)
{
for (ConnectionList::iterator it = connections_.begin(); it != connections_end(); ++it)
{
codec_.send(get_pointer(*it), message);
}
}
};
main函数是例行公事的代码:
int main(int argc, char *argv[])
{
LOG_INFO << "pid = " << getpid();
if (argc > 1)
{
EventLoop loop;
uint16_t port = static_cast<uint16_t>(atoi(argv[1]));
InetAddress serverAddr(port);
ChatServer server(&loop, serverAddr);
server.start();
loop.loop();
}
else
{
printf("Usage: %s port\n", argv[0]);
}
}
如果你读过asio的对应代码,会不会觉得Reactor往往比Proactor容易使用?
作者有时觉得服务端的程序常常比客户端的更容易写,聊天服务器再次验证了作者的看法。客户端的复杂性来自于它要读取键盘输入,而EventLoop是独占线程的,所以用了两个线程:main函数所在的线程负责读键盘,另外用一个EventLoopThread来处理网络(作者没有把标准输入和标准输出融入Reactor的想法,因为服务器程序很少用到stdin和stdout)。
现在来看代码,首先,在构造函数里注册回调,并使用了跟前面一样的LengthHeaderCodec作为中间层,负责打包、分包:
class ChatClient : boost::noncopyable
{
public:
ChatClient(EventLoop *loop, const InetAddress &serverAddr) : loop_(loop),
client_(loop, serverAddr, "ChatClient""),
codec_(boost::bind(&ChatClient::onStringMessage, this, _1, _2, _3))
{
client_.setConnectionCallback(boost::bind(&ChatClient::onConnection, this, _1));
client_.setMessageCallback(boost::bind(&LengthHeaderCodec::onMessage, &codec_, _1, _2, _3));
client_.enableRetry();
}
void connect()
{
client_.connect();
}
disconnect函数目前为空,客户端的连接由操作系统在进程终止时关闭:
public:
void disconnect()
{
// client_.disconnect();
}
wirte成员函数会由main线程调用,所以要加锁,这个锁不是为了保护TcpConnection,而是为了保护shared_ptr(除了main线程调用wirte会用到共享指针connection_,同时另一个负责处理网络的事件循环线程也会用到connection_):
public:
void write(const StringPiece &message)
{
MutexLockGuard lock(mutex_);
// 如果connection_指向的对象还存在
// shared_ptr重载了operator bool()(布尔转换操作符)
if (connection_)
{
codec_send(get_pointer(connection_), message);
}
}
onConnection函数会由EventLoop线程调用,所以要加锁以保护shared_ptr(应该是防止main线程调用disconnect的同时,连接也断开,这样两个线程都会用到共享指针connection_):
private:
void onConnection(const TcpConnectionPtr &conn)
{
LOG_INFO << conn->localAddress().toIpPort() << " -> "
<< conn->peerAddress().toIpPort() << " is "
<< (conn->connected() ? "UP" : "DOWN");
MutexLockGuard lock(mutex_);
if (conn->connected())
{
connection_ = conn;
}
else
{
connection_.reset();
}
}
把收到的消息打印到屏幕,这个函数由EventLoop线程调用,但是不用加锁,因为printf函数是线程安全的。注意这里不能用std::cout<<,它不是线程安全的:
private:
onStringMessage(const TcpConnectionPtr &, const string &message, Timestamp)
{
printf("<<< %s\n", message.c_str());
}
数据成员:
private:
// 数据成员
EventLoop *loop_;
TcpClient client_;
LengthHeaderCodec codec_;
MutexLock mutex_;
TcpConnectionPtr connection_;
};
main函数里处理例行公事,还要启动EventLoop线程和读取键盘输入:
int main(int argc, char *argv[])
{
LOG_INFO << "pid = " << getpid();
// 至少要有2个参数,指定ip和port
if (argc > 2)
{
EventLoopThread loopThread;
uint16_t port = static_cast<uint16_t>(atoi(argv[2]));
InetAddress serverAddr(argv[1], port);
// ChatClient使用EventLoopThread的EventLoop,而不是通常的主线程的EventLoop
ChatClient client(loopThread.startLoop(), serverAddr);
client.connect();
std::string line;
// std::getline函数用于从输入流中读取一行文本并存储在一个字符串中
// 第一个参数指定流,可以是std::cin(标准输入,通常是键盘输入)或std::ifstream(文件输入流)
// 或其他不同类型的输入流,取决于你的需要
while (std::getline(std::cin, line))
{
// 发送数据行
client.write(line);
}
client.disconnect();
}
else
{
printf("Usage: %s host_ip port\n", argv[0]);
}
}
简单测试:打开三个命令行窗口,在第一个窗口运行:
![]()
在第二个窗口运行:
![]()
在第三个窗口运行同样的命令:
![]()
这样就有两个客户端进程参与聊天。在第二个窗口里输入一些字符并回车,字符会出现在本窗口和第三个窗口中。
代码示例中还有另外三个server程序,都是多线程的,它们的详细介绍在后文:
1.server_threaded.cc使用多线程TcpServer,并用mutex来保护共享数据。
2.server_threaded_efficient.cc对共享数据以第二章中“借shared_ptr实现copy_on_write”的手法来降低锁竞争。
3.server_threaded_highperformance.cc采用thred local变量,实现多线程高效转发,这个例子值得仔细阅读理解。
后文会介绍muduo中的定时器,并实现Boost.Asio教程中的timer 2~5示例,以及带流量统计功能的discard和echo服务器(来自Java Netty)。流量等于单位时间内发送或接收的字节数,这要用到定时器功能。
下面介绍muduo中输入输出缓冲区的设计与实现。文中buffer指一般的应用层缓冲区,缓冲技术,Buffer特指muduo::net::Buffer class。
[UNP]6.2节总结了Unix/Linux上的五种IO模型:阻塞(blocking)、非阻塞(non-blocking)、IO复用(IO multiplexing)、信号驱动(signal-driven)、异步(asynchronous)。这些都是单线程下的IO模型。
C10k问题的页面(http://www.kegel.com/c10k.html)介绍了五种IO策略,把线程也纳入考量。(现在C10k已经不是什么问题,C100k也不是大问题,C1000k才算得上挑战)
在这个多核时代,线程是不可避免的。那么服务端网络编程该如何选择线程模型呢?作者赞同libev作者的观点:one loop per thread is usually a good model。之前作者也不止一次表述过这个观点,参见第三章“多线程服务器的常用编程模型”和第六章“详解muduo多线程模型”。
如果采用one loop per thread的模型,多线程服务端编程的问题就简化为如何设计一个高效且易于使用的event loop,然后每个线程run一个event loop就行了(当然,同步和互斥是不可或缺的)。在“高效”这方面已经有了很多成熟的范例(libev、libevent、memcached、redis、lighttpd、nginx),在“易于使用”方面作者希望muduo能有所作为。(muduo可算是用现代C++实现了Reactor模式,比起原始的Reactor来说要好用得多)
event loop是non-blocking网络编程的核心,在现实生活中,non-blocking几乎总是和IO multiplexing一起使用,原因有两点:
1.没有人真的会用轮询(busy-pooling)来检查某个non-blocking IO操作是否完成,这样太浪费CPU cycles。
2.IO multiplexing一般不能和blocking IO用在一起,因为blocking IO中read/write/accept/connect函数都有可能阻塞当前线程,这样线程就没办法处理其他socket上的IO事件了。见[UNP]16.6节“nonblocking accept”的例子。
所以,当作者提到non-blocking的时候,实际上指的是non-blocking+IO multiplexing,单用其中任何一个是不现实的。另外,本书所有的“连接”均指TCP连接,socket和connection在文中可互换使用。
当然,non-blocking编程比blocking难得多,见第六章“TCP网络编程本质论”列举的难点。基于event loop的网络编程跟直接用C/C++编写单线程Windows程序颇为相像:程序不能阻塞,否则窗口就失去响应了;在event handler中,程序要尽快交出控制权,返回窗口的事件循环。
7.4.2 为什么non-blocking网络编程中应用层buffer是必需的
non-blocking IO的核心思想是避免阻塞在read或write或其他IO系统调用上,这样可以最大限度地复用thread-of-control,让一个线程能服务于多个socket连接。IO线程只能阻塞在IO multiplexing函数上,如select/poll/epoll_wait函数。这样一来,应用层的缓冲是必需的,每个TCP socket都要有stateful的input buffer和output buffer。
TcpConnection必须要有output buffer。考虑一个常见场景:程序想通过TCP连接发送100kB的数据,但是在write函数中,操作系统只接受了80kB(受TCP advertised window的控制,细节见[TCPv1]。作者此处说系统只接受80kB是因为通告窗口,这里应该是取决于TCP的发送缓冲区,即使对方的通告窗口只有1kB,我们也可以把要发送的100kB都放到TCP的发送缓冲中,然后让TCP协议栈每次1kB发送完所有数据(理想情况下)),你肯定不想在原地等待,因为不知道会等多久(取决于对方什么时候接收数据,然后滑动TCP窗口。作者似乎认为write函数能写的数据量取决于TCP窗口,准确地说是“取决于对方什么时候接收数据,即对方进程读数据到用户空间,然后对方空出TCP接收缓冲区,从而发送窗口恢复通知,然后我方将TCP发送缓冲区中的内容发到对端,对端收到后会返回ACK,我方收到ACK后就可以腾出TCP发送缓冲区的空间,从而可以write更多数据到TCP发送缓冲区中”)。程序应该尽快交出控制权,返回event loop。在这种情况下,剩余的20kB数据怎么办?
对于应用程序而言,它只管生成数据,它不应该关心到底数据是一次性发送还是分成几次发送,这些应该由网络库来操心,应用只要调用TcpConnection::send()就行了,网络库会负责到底。网络库应该接管这剩余的20kB数据,把它保存在该TCPconnection的output buffer里,然后注册POLLOUT事件,一旦socket变得可写就立刻发送数据。当然这第二次write()也不一定能完全写入20kB,如果还有剩余,网络库应该继续关注POLLOUT事件;如果写完了20kB,网络库应该停止关注POLLOUT,以免造成busy loop。(muduo EventLoop采用的是epoll level trigger,原因见下文)
如果程序又写入了50kB,而这时候output buffer里还有待发送的20kB数据,那么网络库不应该直接调用write(),而应该把这50kB数据append在那20kB数据之后,等socket变得可写的时候再一并写入。
如果output buffer里还有待发送的数据,而程序又想关闭连接(对程序而言,调用TcpConnection::send()之后它就认为数据迟早会发出去),那么这时候网络库不能立刻关闭连接,而要等数据发送完毕,见上文“为什么TcpConnection::shutdown()没有直接关闭TCP连接”中的讲解。
综上,要让程序在write操作上不阻塞,网络库必须要给每个TCP connection配置output buffer。
TcpConnection必须要有input buffer。TCP是一个无边界的字节流协议,接收方必须要处理“收到的数据尚不构成一条完整的消息”和“一次收到两条消息的数据”等情况。一个常见的场景是,发送方send()了两条1kB的消息(共2kB),接收方收到数据的情况可能是:
1.一次性收到2kB数据。
2.分两次收到,第一次600B,第二次1400B。
3.分两次收到,第一次1400B,第二次600B。
4.分两次收到,第一次1kB,第二次1kB。
5.分三次收到,第一次600B,第二次800B,第三次600B。
6.其他任何可能。一般而言,长度为n字节的消息分块到达的可能性有2 n − 1 ^{n-1} n−1种。
网络库在处理“socket可读”事件的时候,必须一次性把socket里的数据读完(从操作系统buffer搬到应用层buffer),否则会反复触发POLLIN事件,造成busy-loop。那么网络库必然要应对“数据不完整”的情况,收到的数据先放到input buffer里,等构成一条完整的消息再通知程序的业务逻辑。这通常是codec的职责,见上文“Boos.Asio的聊天服务器”中的“TCP分包”的论述与代码。所以,在TCP网络编程中,网络库必须要给每个TCP connection配置input buffer。
muduo EventLoop采用的是epoll level trigger,而不是edge trigger。一是为了与传统的poll(2)函数兼容,因为在文件描述符数目较少,活动文件描述符比例较高时,epoll(4)函数不见得比poll(2)函数更高效,必要时可以在进程启动时切换Poller(即进行IO多路复用的那些函数)。二是level trigger编程更容易,以往select(2)/poll(2)函数的经验都可以继续用,不可能发生漏掉事件的bug。三是读写的时候不必等候出现EAGAIN,可以节省系统调用次数,降低延迟。
所有muduo中的IO都是带缓冲的IO(buffered IO),你不会自己去read()或write()某个socket,只会操作TcpConnection的input buffer和output buffer。更确切地说,是在onMessage()回调里读取input buffer;调用TcpConnection::send()来间接操作output buffer,一般不会直接操作output buffer。
另外,muduo的onMessage()的原型如下,它既可以是free function,也可以是member function,反正muduo TcpConnection只认boost::function<>:
![]()
对于网络程序来说,一个简单的验收测试是:输入数据每次收到一个字节(200字节的输入数据会分200次收到,每次间隔10ms),程序的功能不受影响。对于muduo程序,通常可以用codec来分离“消息接收”与“消息处理”,见后文7.6“在muduo中实现Protobuf编解码器与消息分发器”中对“编解码器codec”的介绍。
如果某个网络库只提供相当于char buf[8192]的缓冲,或者根本不提供缓冲区,而仅仅通知程序“某socket可读/某socket可写”,要程序自己操心IO buffering,这样的网络库用起来就很不方便了。
7.4.3 Buffer的功能需求
muduo Buffer的设计考虑了常见的网络编程需求,作者试图在易用性和性能之间找一个平衡点,目前这个平衡点更偏向于易用性。
muduo Buffer的设计要点:
1.对外表现为一块连续的内存(char *p, int len),以方便客户代码的编写。
2.其size()可以自动增长,以适应不同大小的消息。它不是一个fixed size array(例如char buf[8192])。
3.内部以std::vector来保存数据,并提供相应的访问函数。
Buffer其实像是一个queue,从末尾写入数据,从头部读出数据。
谁会用Buffer?谁写谁读?根据前文分析,TcpConnection会有两个Buffer成员,input buffer与output buffer:
1.input buffer,TcpConnection会从socket读取数据,然后写入input buffer(其实这一步是用Buffer::readFd()完成的);客户代码从input buffer读取数据。
2.output buffer,客户代码会把数据写入output buffer(其实这一步是用TcpConnection::send()完成的);TcpConnection从output buffer读取数据并写入socket。
其实,input和output是针对客户代码而言的,客户代码从input读,往output写。TcpConnection的读写正好相反。
下图是muduo::net::Buffer的类图。要注意,为了后面画图方便,这个类图跟实际代码略有出入,但不影响作者要表达的观点。代码位于muduo/net/Buffer.{h,cc}。

本节不介绍每个成员函数的使用,而会详细讲解readIndex和writeIndex的作用。
Buffer::readFd()。作者在第五章中写道:“在非阻塞网络编程中,如何设计并使用缓冲区?一方面我们希望减少系统调用,一次读的数据越多越划算,那么似乎应该准备一个大的缓冲区。另一方面希望减少内存占用。如果有10000个并发连接,每个连接一建立就分配各50kB的读写缓冲区的话,将占用1GB内存,而大多数时候这些缓冲区的使用率很低。muduo用readv(2)函数结合栈上空间巧妙地解决了这个问题。”
具体做法是,在栈上准备一个65535字节的extrabuf,然后利用readv()函数来读取数据,iovec有两块,第一块指向muduo Buffer中的writable字节,另一块指向栈上的extrabuf。这样如果读入的数据不多,那么全部都读到Buffer中去了;如果长度超过Buffer的writeable字节数,就会读到栈上的extrabuf里,然后程序再把extrabuf里的数据append()到Buffer中,代码见8.7.2。
这么做利用了临时栈上空间(readFd是最内层函数,其在每个IO线程的最大stack空间开销是固定的64kiB,与连接数目无关。如果stack空间紧张,也可以改用thread local的extrabuf,但是不能全局共享一个extrabuf,因为如果有多个事件循环,会写到同一个extrabuf中),避免每个连接的初始Buffer过大造成内存浪费,也避免反复调用read()的系统开销(由于缓冲区足够大,通常一次readv系统调用就能读完全部数据)。由于muduo的事件触发采用level trigger,因此这个函数并不会反复调用read直到其返回EAGAIN,从而可以降低消息处理的延迟。
这算是一个小小的创新吧。
线程安全?muduo::net::Buffer不是线程安全的(其安全性跟std::vector相同),这么设计的理由如下:
1.对于input buffer,onMessage()回调始终发生在该TcpConnection所属的那个IO线程,应用程序应该在onMessage()完成对input buffer的操作,并且不要把input buffer暴露给其他线程。这样所有对input buffer的操作都在同一个线程,Buffer class不必是线程安全的。
2.对于output buffer,应用程序不会直接操作它,而是调用TcpConnection::send()来发送数据,后者是线程安全的。
代码中用EventLoop::assertInLoopThread()保证以上假设成立。
如果TcpConnection::send()调用发生在该TcpConnection所属的那个IO线程,那么它会转而调用TcpConnection::sendInLoop(),sendInLoop()会在当前线程(也就是IO线程)操作output buffer;如果TcpConnection::send()调用发生在别的线程,它不会在当前线程调用sendInLoop(),而是通过EventLoop::runInLoop()把sendInLoop()函数调用转移到IO线程(听上去颇为神奇?),这样sendInLoop()还是会在IO线程操作output buffer,不会有线程安全问题。当然,跨线程的函数转移调用涉及函数参数的跨线程传递,一种简单的做法是把数据拷贝一份,绝对安全。
另一种更为高效的做法是用swap()。这就是为什么TcpConnection::send()的某个重载以Buffer *为参数,而不是const Buffer &,这样可以避免(深)拷贝,而用Buffer::swap()实现高效的线程间数据转移。(最后这点,仅为设想,暂未实现。目前仍然以数据拷贝方式在线程间传递,略微有些性能损失)
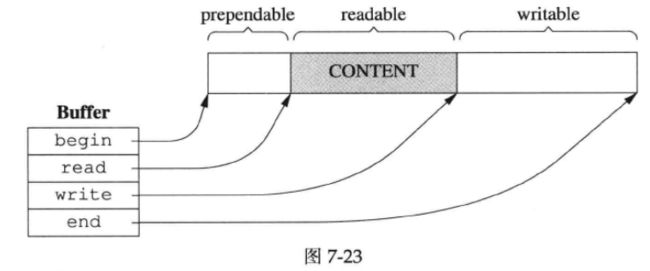
7.4.4 Buffer的数据结构
Buffer的内部是一个std::vector,它是一块连续的内存。此外,Buffer有两个data member,指向该vector中的元素。这两个index的类型是int,不是char *,目的是应对迭代器失效。muduo Buffer的设计参考了Netty的ChannelBuffer和libevent 1.4x的evbuffer。不过其prependable可算是一点“微创新”。
在介绍Buffer的数据结构之前,先简单说一下后面示意图中表示指针或下标的箭头所指位置的具体含义。对于长度为10的字符串“Chen Shuo\n”:
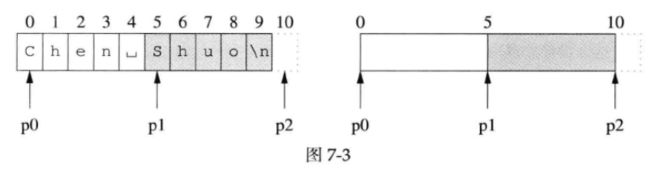
如果p0指向第0个字符(白色区域的开始),p1指向第5个字符(灰色区域的开始),p2指向’\n’之后的那个位置(通常是end()迭代器所指的位置),那么青雀的画法如上图的左图所示,简略的画法如上图的右图所示,后文都采用这种简略画法。
muduo Buffer的数据结构如下图所示:
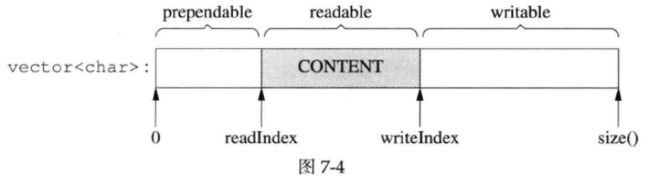
两个index把vector的内容分为三块:prependable、readable、writable,各块的大小见下式:

灰色部分是Buffer的有效载荷(payload),prependable的作用留到后面讨论。
readIndex和writeIndex满足以下不变式(invariant,在程序执行过程中保持不变的条件或属性):
![]()
muduo Buffer里有两个常数kCheapPrepend和kInitialSize,定义了prependable的初始大小和writable的初始大小,readable的初始大小为0。在初始化之后,Buffer的数据结构如下图所示,其中括号里的数字是该变量或常量的值:

根据公式7-1可算出各块的大小,刚刚初始化的Buffer里没有payload数据,所以readable==0。
7.4.5 Buffer的操作
基本的read-write cycle
Buffer初始化后的情况见图7-4。如果初始化后向Buffer写入200字节,那么其布局如下图所示:
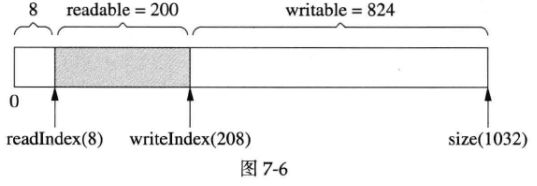
上图中writeIndex向后移动了200字节,readIndex保持不变,readable和writable的值也有变化。
如果从Buffer read()&retrieve()(下称“读入”)了50字节,结果如下图所示:
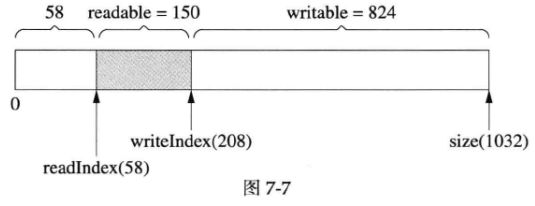
与图7-6相比,上图中readIndex向后移动50字节,writeIndex保持不变,readable和writable也有变化(这句话往后从略)。
然后又写入了200字节,writeIndex向后移动了200字节,readIndex保持不变,如下图所示:

接下来,一次性读入350字节,请注意,由于全部数据读完了,readIndex和writeIndex返回原位以备新一轮使用(见下图),这和图7-5是一样的:
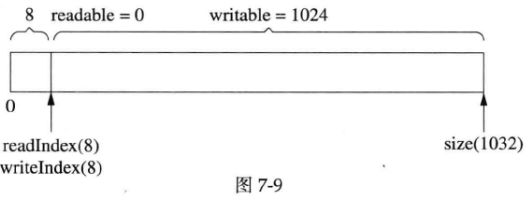
以上过程可以看作是发送方发送了两条消息,长度分别为50字节和350字节,接收方分两次收到数据,每次200字节,然后进行分包,再分两次回调客户代码。
自动增长
muduo Buffer不是固定长度的,它可以自动增长,这是使用vector的直接好处。假设当前的状态如下图所示(这和图7-8是一样的):
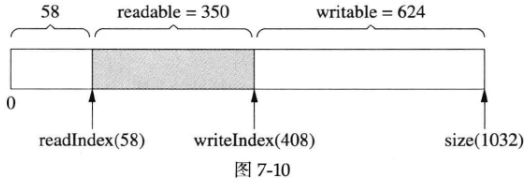
客户代码一次性写入1000字节,而当前可写的字节数只有624,那么buffer会自动增长以容纳全部数据,得到的结果如下图所示:
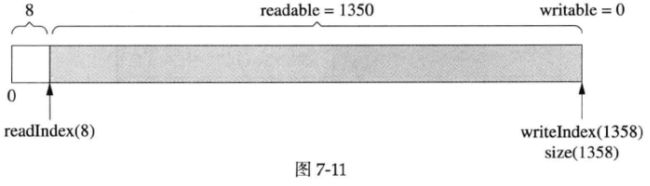
注意readIndex返回到了前面,以保持prependable等于kCheapPrependable。由于vector重新分配了内存,原来指向其元素的指针会失效,这就是为什么readIndex和writeIndex是整数下标而不是指针。(注意:在目前的实现中prependable会保持58字节,留待将来修正)
然后读入350字节,readIndex前移,如下图所示:
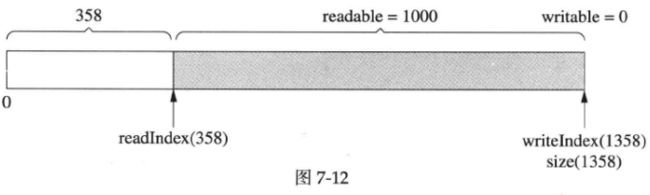
最后,读完剩下的1000字节,readIndex和writeIndex返回kCheapPrependable,如下图所示:
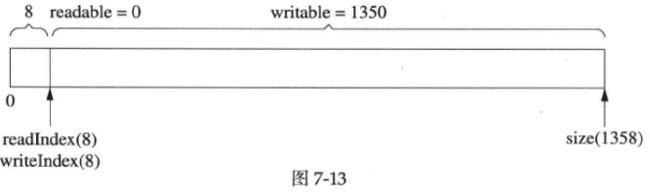
注意bufffer并没有缩小大小,下次写入1350字节就不会重新分配内存了。换句话说,muduo Buffer的size()是自适应的,它一开始的初始值是1kB多,如果程序中经常收发10kB的数据,那么用几次之后它的size()会自动增长到10kB,然后就保持不变。这样一方面避免浪费内存(Buffer的初始大小直接决定了高并发连接时的内存消耗),另一方面避免反复分配内存。当然,客户代码可以手动shrink() buffer size()。
size()与capacity()
使用vector的另一个好处是它的capcity()机制减少了内存分配次数。比方说程序反复写入1字节,muduo buffer不会每次都分配内存(每次都多分配1字节),vector的capacity()实现是以指数方式增长的,让push_back()的平均复杂度是常数。比方说经过第一次增长,size()刚好能满足写入的需求,如下图所示:
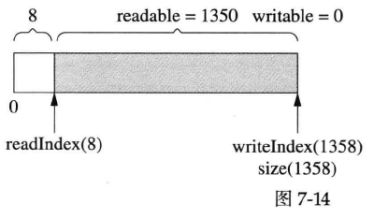
但这个时候vector的capacity()已经大于size(),在接下来写入capacity()-size()字节的数据时,都不会重新分配内存,如下图所示:
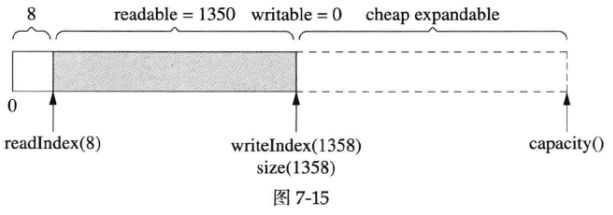
为什么我们不需要调用reserve()来预先分配空间?因为Buffer在构造函数里把初始size()设为1KiB,这样当size()超过1KiB的时候vector会把capacity()加倍,等于说resize()替我们做了reserve()的事。用一段简单的代码验证一下:

运行结果:

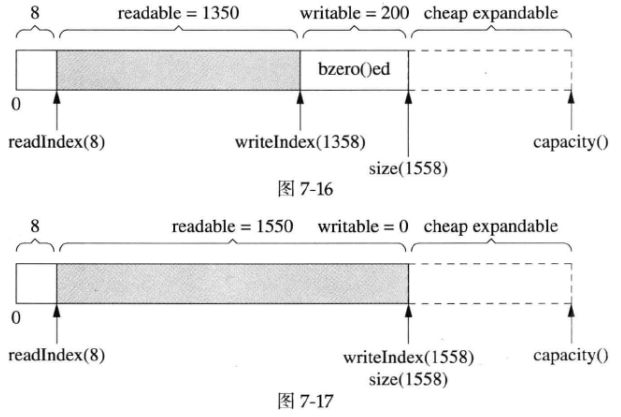
用capacity()也不是完美的,它有优化的余地。具体来说,vector::resize()会初始化(memset()/bzero())内存,而我们不需要它初始化,因为反正立刻就要填入数据。比如,在图7-15的基础上写入200字节,由于capacity()足够大,不会重新分配内存,这是好事;但是vector::resize()会先把那200字节memset()为0(见图7-16),然后muduo Buffer再填入数据(见图7-17)。这么做稍微有点浪费,但作者不打算优化它,除非它确实造成了性能瓶颈。(精通STL的读者可能会说用vec.insert(vec.end(), …)以避免浪费,但是writeIndex和size()不一定是对齐的,会有别的麻烦(这里怎样避免浪费,insert不也是在capacity预留的空间插入吗?insert的时候超过capacity不也会重新分配并初始化空间吗?难道是insert的时候如果扩大空间,会先insert我们要插入的数据,再memset()剩下的新分配的空间?))
Google Protobuf中有一个STLStringResizeUninitialized函数,干的就是这个事情(指只分配空间而不初始化它)。
内部腾挪
有时候,经过若干次读写,readIndex移到了比较靠后的位置,留下了巨大的prependable空间,如下图所示:
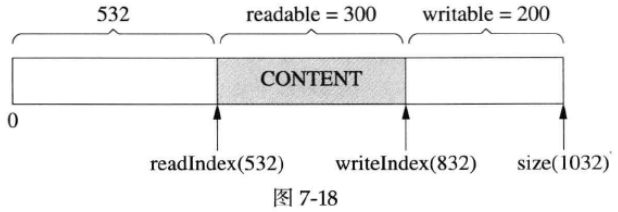
这时候,如果我们想写入300字节,而writable只有200字节,怎么办?muduo Buffer在这种情况下不会重新分配内存,而是先把已有的数据移到前面去,腾出writable空间,如下图所示:
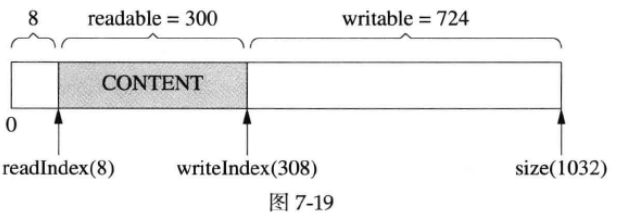
然后,就可以写入300字节了,如下图所示:
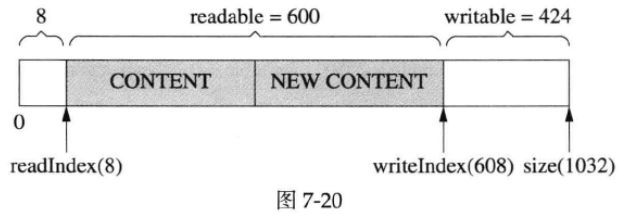
这么做的原因是,如果重新分配内存,反正也是要把数据拷贝到新分配的内存区域,代价只会更大。
前方添加(prepend)
前面说muduo buffer有个小小的创新(或许不是创新,作者记得在哪看到过类似的做法,忘了出处),即提供prependable空间,让程序能以很低的代价在数据前面添加几个字节。
比方说,程序以固定的4个字节表示消息的长度(上文“Boost.Asio的聊天服务器”中的LengthHeaderCodec),我要序列化一个消息,但是不知道它有多长,那么我可以一直append()直到序列化完成(图7-21,写入了200字节),然后再在序列化数据的前面添加消息的长度(图7-22,把200这个数prepend到首部)。
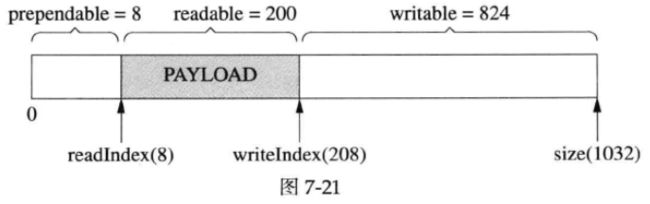

以上通过预留kCheapPrependable空间,可以简化客户代码,以空间换时间。
以上各种use case的单元测试见muduo/net/tests/Buffer_unittest.cc。
7.4.6 其他设计方案
这里简单谈谈其他可能的应用层buffer设计方案。
不用vector
如果有STL洁癖,那么可以自己管理内存,以4个指针为buffer的成员,数据结构如下图所示:
作者不觉得这种方案比std::vector好。代码变复杂了,性能也未见得有能察觉得到(noticeable)的改观。如果放弃“连续性”要求,可以用circular buffer,这样可以减少一点内存拷贝(没有“内部腾挪”)。
zero copy
如果对性能有极高要求,受不了copy()与resize(),那么可以考虑实现分段连续的zero copy buffer再配合gather scatter IO,数据结构由下图所示:
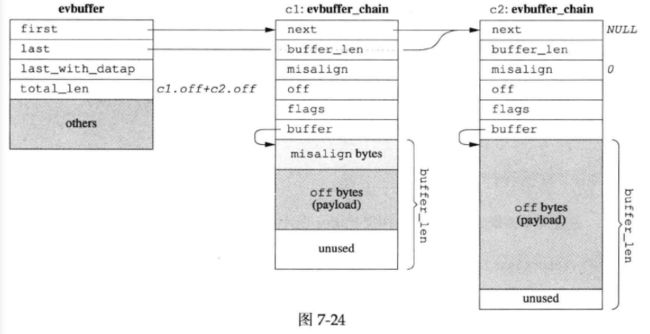
上图是libevent 2.0.x的设计方案。TCPv2介绍的BSD TCP/IP实现中的mbuf(Memory Buffer,是一种数据结构,通常用于在内核中管理网络数据包的缓冲区)也是类似的方案,Linux的sk_buff(它是Linux内核中的一个关键数据结构,用于表示网络数据包(包括TCP/IP数据包)的缓冲区)估计也差不多。细节有出入,但基本思路都是不要求数据在内存中连续,而是用链表把数据块链接到一起。
上图中绘制的是由两个evbuffer_chain构成的evbuffer,右边两个evbuffer_chain结构体中深灰色的部分是payload,可见evbuffer的缓冲区不是连续的,而是分块的。
当然,高性能的代价是代码变得晦涩难读,buffer不再是连续的,parse消息会稍微麻烦一些。如果你的程序只处理Protobuf Message(ProtoBuf是由Google开发的一种用于序列化结构化数据的二进制数据格式,用于在不同应用程序和语言之间进行数据交换),这不是问题,因为Protobuf有ZeroCopyInputStream接口(它是Protocol Buffers(ProtoBuf)库中的一个接口,用于支持零拷贝数据读取操作),只要实现这个接口(这句话是什么意思?ZeroCopyInputStream接口是库自带的,为什么又说要实现这个接口),parsing的事情就交给Protobuf Message去操心了(即如果程序只处理Protobuf Message,那么可以依赖Protobuf提供的一些高级接口(如ZeroCopyInputStream),这些接口可以帮助简化数据解析的任务,因为Protobuf负责处理数据的复杂性)。
7.4.7 性能是不是问题
看到这里,有的读者可能会嘀咕:muduo buffer有那么多可以优化的地方,其性能会不会太低?对此,作者的回应是“可以优化,不一定值得优化”。
muduo的设计目标是用于开发公司内部的分布式程序。换句话说,它是用来写专用的Sudoku server或者游戏服务器(游戏服务器不是要对外让玩家访问吗?),不是用来写通用的httpd或ftpd或Web proxy。前者通常有业务逻辑,后者更强调高并发与高吞吐量。
以Sudoku为例,假设求解一个Sudoku问题需要0.2ms,服务器有8个核,那么理想情况下每秒最多能求解40000个问题。每次Sudoku请求的数据大小低于100字节(一个9×9的数独只要81字节,加上header也可以控制在100字节以下),也就是说100×40000=4MB/s的吞吐量就足以让服务器的CPU饱和。在这种情况下,去优化Buffer的内存拷贝次数似乎没有意义。
再举一个例子,目前最常用的前兆以太网的裸吞吐量是125MB/s,扣除以太网header、IP header、TCP header之后,应用层的吞吐率大约在117MB/s上下(在不考虑jumbo frame(巨大帧,标准以太网帧的最大传输单元(Maximum Transmission Unit,MTU)通常为1500字节,而巨大帧的MTU可以达到更大的值,通常为9000字节)的情况下,计算过程是:对于千兆以太网,每秒能传输1000Mbit数据,即125000000B/s,每个以太网frame的固定开销有:preamble(8B,前导码)、MAC(12B,MAC地址是6字节,源MAC地址和目的MAC地址一共12B)、type(2B)、payload(46B~1500B)、CRC(4B)、gap(12B),因此最小的以太网帧是84B,每秒可发送约1488000帧最小帧(换言之,对于一问一答的RPC、其qps上限约是700k/s),最大的以太网帧是1538B,每秒可发送81274帧。再来算TCP有效载荷:一个TCP segment包含IP header(20B)和TCP header(20B),还有Timestamp option(12B),因此TCP的最大吞吐量是81274×(1500-52)=117MB/s,合112MiB/s,实测见7.8.5)。而现在服务器上最常用的DDR2/DDR3内存的带宽至少是4GB/s,比千兆以太网高40倍以上。也就是说,对于几kB或几十kB大小的数据,在内存中复制几次根本不是问题,因为受千兆以太网延迟和带宽的限制,跟这个程序通信的其他机器上的程序不会觉察到性能差异。
最后举一个例子,如果你实现的服务程序要跟数据库打交道,那么瓶颈常常在DB上,优化服务程序本身不见得能提高性能(从DB读一次数据往往就抵消了你做的全部low-level优化),这是不如把精力投入在DB调优上。
专用服务程序与通用服务程序的另外一点区别是benchmark的对象不同。如果你打算写一个httpd,自然有人会拿来和目前最好的Nginx对比,立马就能比出性能高低。然而,如果你写一个实现公司内部业务的服务程序(比如分布式存储、搜索、微博、短网址),由于市面上没有同等功能的开源实现,你不需要在优化上投入全部精力,只要一版做得比一版好就行。先正确实现所需的功能,投入生产应用,然后再根据真实的负载情况来做优化,这恐怕比在编码阶段就盲目调优要更effective一些。
muduo的设计目标之一是吞吐量能让千兆以太网饱和,也就是每秒收发120MB数据。这个很容易就达到,不用任何特别的努力。
如果确实在内存带块方面遇到问题,说明你做的应用太critical,或许应该考虑放到Linux kernel里边去,而不是在用户态尝试各种优化。毕竟只有把程序做到kernel里才能真正实现zero copy;否则,核心态和用户态之间始终是有一次内存拷贝的。如果放到kernel里还不能满足需求,那么要么自己写新的kernel,或者直接用FPGA(Field-Programmable Gate Array,现场可编程门阵列,该名字反映了这种芯片的特性,即用户可以在现场或实际应用环境中进行编程,以实现所需的数字电路功能)或ASIC(Application-Specific Integrated Circuit,特定应用集成电路,一种定制的集成电路,它根据特定应用的需求进行设计和制造,以执行特定的功能或任务)操作network adapter(网络接口卡)来实现你的“高性能服务器”。