Elasticsearch(一)---介绍
简介
Elasticsearch是一个基于Lucene的实际的分布式搜索和分析引擎。设计用于云计算中,能够达到近实时搜索,稳定,可靠,快速,安装使用方便。基于RESTful接口。
官网地址:Elasticsearch 平台 — 大规模查找实时答案 | Elastic
ES与solr的对比:
接口
类似webservice的接口 solr
REST风格的访问接口 es
分布式存储
solrCloud solr4.x才支持
es是为分布式而生的
支持的格式
solr xml json
es json

倒排索引
lucene
例如:我们有两个文档:
The quick brown fox jumped over the lazy dog
Quick brown foxed leap over lazy dogs in summer
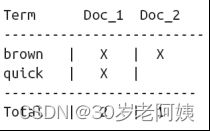
我们首先将每个文档进行分词,创建一个对唯一词语有序的列表,
对每个词在哪些文档中出现过的文档列表。

如右图所示:
Doc_1:
The quick brown fox jumped over the lazy dog
Doc_2:
Quick brown foxed leap over lazy dogs in summer
现在我们查询quick brown,我们只需要知道这个词在哪些文档出现过:
如果我们使用简单的相似性算法,比如说将每个文档匹配的词语数相加,我们就能看出来第一个文档更加匹配,比第二个文档更加符合我们的查询条件:quick brown。
优化:
1、Quick可以全小写,则和quick一样
2、foxes转换为原型fox。dogs变为dog
3、jumped和leap是同义词,都看成jump
倒排索引变为:
此时,如果我们在将查询条件使用相同的流程进行转换则两个文档都能匹配上了。
进行分词和同义词等操作称为“分析”。

倒排索引
关键字 对应的文档 每个文档的tf-idf的值(相关度得分) 每个文档中关键字出现的位置以及偏移量(为了做高亮)
Hello doc1:10:56~60,doc2:11:56~60,doc3:9:56~60,doc4:4:56~60
word doc1:10:56~60,doc2:11:56~60,doc3:9:56~60,doc4:4:56~60
tom doc1:10:56~60,doc2:11:56~60,doc3:9:56~60,doc4:4:56~60
hadoop doc1:10:56~60,doc2:11:56~60,doc3:9:56~60,doc4:4:56~60
一个HTML页面
lucene的倒排索引占文档的20%~30%
100GB 20G~30G
索引的过程
获取文档,并将文档进行分词
计算每个词的相关程度
计算每个词在词条中的位置和偏移量
。。。
搜索的过程
获取用户的输入
分词
到倒排索引中对词语进行查找,并按照词语相关度做倒序排列
将结果返回给用户。
ES优点:(了解)
- 分布式:ES的自动发现机制会识别新增的节点并重新平衡分配数据。
- 全文检索:ES后台使用Lucene提供全文检索,自带多语言支持、强大的查询语言、地理位置支持、上下文感知的建议、自动完成和搜索片段
- 近实时搜索和分析:数据从进入ES到能够搜索到是近实时的。除了搜索,ES也可以进行聚合分析操作。
- 高可用:ES会自动发现新的或失败的节点,重组和重新平衡数据,确保数据是安全的和可访问的。
- 模式自由:ES的动态Mapping机制可以自动检测数据的结构和类型,创建索引,并使数据可搜索。
- RESTful API:几乎任何操作都可以使用一个简单的RESTful API,JSON基于HTTP请求来实现,客户端也可以使用多种编程语言。
应用场景(了解)
- 站内搜索:京东、淘宝、论坛等的站内搜索
- NoSQL数据库:ES读写性能优于MongoDB,同时也支持地理位置查询
- 日志分析:日志分析由实时日志分析平台ELK完成,能够对日志进行集中的收集、存储、搜索、分析、监控以及可视化。
如何索引文档(理解)
为新增的文档创建倒排索引
默认情况下,当索引一篇文档的时候,系统首先根据文档ID的散列值选择一个主分片,并将文档发送到该主分片。这份主分片可能位于另一个节点。然后文档被发送到该主分片的所有副本分片进行索引,副本分片和主分片之间保持数据的同步。
如何检索文档(理解)
在默认情况下,搜索请求通过round-robin轮询机制选中主分片和副本分片,其假设集群中所有的节点是同样快的。
接收客户端请求的分片节点会创建一个空的优先级队列并且配置好分页参数from与size。
该节点将检索请求发送给该索引中个每一个shard(无论是primary还是replica,可以构成一个完整的索引数据)。每个shard在本地执行检索,并将结果添加到本地优先级队列中。
每个shard返回本地优先级序列中所记录的_id与sort值,并发送给接收客户端请求的节点,该节点将这些值合并到自己的本地的优先级队列中,并做全局的排序,返回给客户端。
脑裂问题(理解)
1. 网络:由于是内网通信,网络通信问题造成某些节点认为master死掉,而另选master的可能性较小
2. 节点负载:由于master节点与data节点都是混合在一起的,所以当工作节点的负载较大时,导致对应的ES实例停止响应,而这台服务器如果正充当着master节点的身份,那么一部分节点就会认为这个master节点失效了,故重新选举新的节点,这时就出现了脑裂;同时由于data节点上ES进程占用的内存较大,较大规模的内存回收操作也能造成ES进程失去响应。fullGC stop the world
解决方式:
主节点
node.master: true
node.data: false
从节点
node.master: false
node.data: true
所有节点
discovery.zen.ping.multicast.enabled: false
discovery.zen.ping.unicast.hosts: [“master”, “slave1”, “slave2"]
discovery.zen.minimum_master_nodes: 2
单播:点对点通信,不是吼一嗓子,而是悄悄的问,谁是我兄弟
多播:吼一嗓子,谁是我兄弟,大家可以同时听到