立体匹配--中值滤波
立体匹配
文章目录
一. 课题说明
二. 概要设计
三. 算法设计
四. 源程序及注释
五. 运行及调试分析
六. 课程设计总结
一、课题说明
立体匹配是立体视觉从图像生成三维点云的常规手段。立体匹配算法主要是通过建立一个能量代价函数,通过此能量代价函数最小化来估计像素点视差值。立体匹配算法的实质就是一个最优化求解问题,通过建立合理的能量函数,增加一些约束,采用最优化理论的方法进行方程求解,这也是所有的病态问题求解方法。
二、概要设计
双目立体匹配可划分为四个步骤:匹配代价计算、代价聚合、视差计算和视差优化。
匹配代价计算的目的是衡量待匹配像素与候选像素之间的相关性。两个像素无论是否为同名点,都可以通过匹配代价函数计算匹配代价,代价越小则说明相关性越大,是同名点的概率也越大。匹配代价计算的方法有很多,本课设使用灰度绝对值差(AD,Absolute Differences)。
代价聚合的根本目的是让代价值能够准确的反映像素之间的相关性。上一步匹配代价的计算往往只会考虑局部信息,通过两个像素邻域内一定大小的窗口内的像素信息来计算代价值,这很容易受到影像噪声的影响,而且当影像处于弱纹理或重复纹理区域,这个代价值极有可能无法准确的反映像素之间的相关性,直接表现就是真实同名点的代价值非最小。
视差计算即通过代价聚合之后的代价矩阵S来确定每个像素的最优视差值,通常使用赢家通吃算法(WTA,Winner-Takes-All)来计算。这一步非常简单,这意味着聚合代价矩阵S的值必须能够准确的反映像素之间的相关性,也表明上一步代价聚合步骤是立体匹配中极为关键的步骤,直接决定了算法的准确性。
视差优化的目的是对上一步得到的视差图进行进一步优化,改善视差图的质量,包括剔除错误视差、适当平滑以及子像素精度优化等步骤.本课设采用中值滤波(Median Filter)平滑算法对视差图进行平滑。
三、算法设计
1)匹配代价计算:反映像素点的灰度变化,在纹理丰富区域具有良好的匹配效果,是一种简单、易实现的代价衡量的方法。本程序使用的代价计算方法:绝对差AD。假设左像待匹配像素为P,视差为d,右影像对应像素为p-d,则算法公式如下:

2)视差计算:在SGM算法中,视差计算采用赢家通吃(WTA)算法,每个像素选择最小聚合代价值所对应的视差值作为最终视差,视差计算的结果是和左影像相同尺寸的视差图,存储每个像素的视差值,在影像内外参数已知的情况下,视差图可以转换为深度图,表示每个像素在空间中的位置。
3)中值滤波:中值滤波法是一种非线性平滑技术,将图像的每个像素用邻域 (以当前像素为中心的正方形区域)像素的中值代替 ,常用于消除图像中的椒盐噪声。主要是用来剔除视差图中的一些孤立的离群外点,同时还能起到填补小洞的作用。算法方式为:将像素值依次取出,进行排序,取出最中间位置的值。
中值滤波原理如下:将其邻域设置为3×3大小,对其3×3邻域内像素点的像素值进行排序(升序降序均可),按升序排序后得到序列值为:[66,78,90,91,93,94,95,97,101]。在该序列中,处于中心位置(也叫中心点或中值点)的值是“93”,因此用该值替换原来的像素值 78,作为当前点的新像素值。

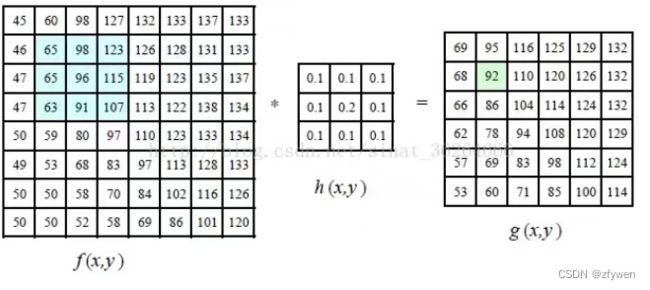
4)盒式滤波:盒式滤波(方框滤波)是一种线性滤波技术,它的实现借鉴了积分图像的原理思想,在快速积分图像求解中,将计算某个矩阵像素间的和值运算,转化为求矩阵对应边角点的求和差值运算。
盒式滤波最关键的步骤就是初始化数组S,数组S的每个值是存放像素邻域内的像素和值,在求解某矩形块中的像素和时,只需要索引对应区域的位置存放的和值就可以完成计算。
四、源程序及注释
#include “opencv2/opencv.hpp”
#include
#include “cuda_runtime.h”
#include
using namespace cv;
using namespace std;
const int dpMax = 20;
//device GPU可以调用GPU函数;global CPU命令GPU
//代价函数
device int ad(int channels, uchar* left, uchar* right) {
int sum = 0;
for (int i = 0; i < channels; i++) {
sum += abs(left[i] - right[i]);
}
return sum / channels;
}
//threadIdx是一个uint3类型,表示一个线程的索引;blockIdx是一个uint3类型,表示一个线程块的索引,一个线程块中通常有多个线程。
//blockDim是一个dim3类型,表示线程块的大小;gridDim是一个dim3类型,表示网格的大小,一个网格中通常有多个线程块。
//代价聚合
global void kernel_ad(int d, int rows, int cols, int channels, uchar* left, uchar* right, uchar* out) {
//将threadIdx/BlockIdx(线程和线程块的索引)映射到像素位置(图像坐标)
int x = threadIdx.x + blockIdx.x * blockDim.x;
int y = threadIdx.y + blockIdx.y * blockDim.y;
int offset = x + y * cols;
if (x
out[offset] = ad(channels, &left[offset * channels], &right[offset * channels - d * channels]);
}
//视差
global void kernel_wta(int rows, int cols, uchar* dsi, uchar* out) {
int x = threadIdx.x + blockIdx.x * blockDim.x;
int y = threadIdx.y + blockIdx.y * blockDim.y;
int offset = x + y * cols;
int k = 0;
for (int i = 0; i < dpMax; i++) {
if (dsi[i * rows * cols + offset] < dsi[k * rows * cols + offset]) k = i;
}
out[offset] = k;
}
//中值滤波
global void MedianFilter(int rows, int cols, int patSize, uchar* img, uchar* out) {
int x = threadIdx.x + blockIdx.x * blockDim.x;
int y = threadIdx.y + blockIdx.y * blockDim.y;
int offset = x + y * cols;
int pat[9];
int k = patSize / 2;
int n = 0;
for (int row = 0; row < patSize; row++) {
for (int col = 0; col < patSize; col++) {
if(n
pat[n]= img[offset + (row - k) * cols + (col - k)];
n++;
}
}
}
//冒泡排序
for (int i = 0; i < patSize * patSize - 1; i++) {
for (int j = 0; j < patSize * patSize - 1 - i; j++) {
if (pat[j] > pat[j + 1]) {
int tmp = pat[j];
pat[j] = pat[j + 1];
pat[j + 1] = tmp;
}
}
}
//窗口大小为偶数个
if (patSize * patSize % 2 == 0)
{
out[offset]=(pat[patSize * patSize / 2] + pat[patSize * patSize / 2 - 1]) / 2.0f;
}
//窗口大小为奇数个
else
{
out[offset]=pat[(patSize * patSize - 1) / 2];
}
}
int main() {
//查找图片路径
Mat left = imread(“E:/venus/Pictures/cones/im2.ppm”);
Mat right = imread(“E:/venus/Pictures/cones/im3.ppm”);
//找不到图片则返回-1
if (left.empty() == 1 && right.empty() == 1) return -1;
//输出左图像大小后换行
cout << left.size() << endl;
//显示图片
imshow(“LEFT”, left);
imshow(“RIGHT”, right);
//定义左图像的行rows、列cols、通道数channels
int rows = left.rows;
int cols = left.cols;
int channels = left.channels();
//在GPU上分配内存
uchar dev_left, * dev_right, * dev_out, * dev_dsi;
cudaMalloc(&dev_left, rows * cols * channels);
cudaMalloc(&dev_right, rows * cols * channels);
cudaMalloc(&dev_out, rows * cols * channels);
cudaMalloc(&dev_dsi, rows * cols * dpMax);
//将left.data和right.data复制到GPU上
cudaMemcpy(dev_left, left.data, rows * cols * channels, cudaMemcpyHostToDevice);
cudaMemcpy(dev_right, right.data, rows * cols * channels, cudaMemcpyHostToDevice);
uchar* dev_tmp; cudaMalloc(&dev_tmp, rows * cols * channels);
//生成一张位图
dim3 grid((cols + 31) / 32, (rows + 31) / 32);
dim3 block(32, 32);
for (int i = 0; i < dpMax; i++)
{
kernel_ad <<
MedianFilter <<
}
kernel_wta <<
Mat img(left.size(), CV_8U);
//将图片从GPU复制回到CPU以显示
cudaMemcpy(img.data, dev_out, rows * cols, cudaMemcpyDeviceToHost);
//显示最后结果
imshow(“DISPARITY”, img * 15);
waitKey(0);
}
五、运行及调试分析
程序输入图像如下:

程序输出图像如下:

ad+中值滤波+wta运行结果

ad+盒式滤波+wta运行结果
六、课程设计总结
比较总结:中值滤波较盒式滤波相比噪点较多,也可以很好保留物体的边缘信息。对于本课设中值滤波如何把像素点取值出来一直理解不透彻,以至于大部分时间都在走弯路。在课程的学习中,明白中值滤波的原理,简单的来说就是取9个像素点将中值与中间数值进行替换。以后会先对课程进行透彻的理论理解,再去进行代码实战。