面经 - OpenStack(Docker、Django、K8S、SDN)知识点
文章目录
-
- 概述
- OpenStack
-
- 虚拟化
-
- kvm
-
- 网络虚拟化
- 基本技术
-
- Memcached
- Etcd
- 消息队列
-
- 概念
- 交换机类型
- 缺点
- 重复投递问题
- 顺序投递问题
- restful api
- Horizon
- Nova
-
- nova-api
- nova-scheduler
-
- 过滤器类型
- nova-compute
- 基本操作
- Keystone
- Glance
- Neutron
-
- 一些虚拟的网络设备
- 架构
-
- Neutron Server
- ML2 Plugin
- Linux Bridge实现
-
- local network
- flat network
- vlan network
- vxlan
- DHCP服务
- NameSpace
- Routing
-
- 底层实现
- router连接外网
- floating IP
- Fwaas
- OpenvSwitch
-
- local network
- flat network
- VLAN 网络
- Roting
- VxLAN
- Cinder
- Swift
- Zun
- Kuryr-libnetwork
- SDN
-
- OpenFlow
-
- OF 1.0
- OF 1.3
- Django
-
- 概述
-
- MVC和MTV
- 和Flask Tornado的区别
- Django请求生命周期
- 常见的web应用程序
-
- 框架组件
- RestFramework
- 缓存机制
- WSGI,uwsgi,uWSGI
- 请求的生命周期
- 中间件的作用和应用场景
- 默认的中间件
- django中的csrf实现机制
-
- 基于django的ajax发送请求给后端如何携带token
- ajax请求的csrf解决方法
- 为什么不使用django的runserver部署(runserver和uWSGI的区别)
- Kubernetes
-
-
- Pod
-
- Pod控制器
-
- Docker
-
-
- NameSpace
- Cgroups
- 驱动
-
- 启动一个容器的步骤
- 基础
-
- 什么是Docker
- Docker与虚拟机的不同
- Docker和普通进程的区别
- 镜像
-
- 什么是Docker镜像和Docker容器
- Docker镜像分层
- bootfs
- 容器分层、写时复制(copy-on-write)
- DockerFile常见指令
- build
- Dockerfile的COPY和ADD
- Docker容器的状态
- 网络
-
- Docker的网络类型
- docker常用命令
-
- 面经
-
- OpenStack
-
-
- 一些命令行
- OpenStack中计算节点上虚拟机默认保存路径在哪?
- OpenStack中Glance镜像的默认保存路径在哪?
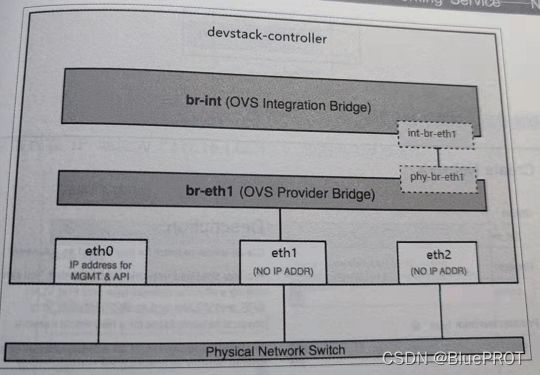
- OpenStack中计算节点的集成桥(br-int)的作用是什么?
- OpenStack中计算节点的隧道桥(br-tun)的作用是什么?
- OpenStack中外部OVS桥(br-ex)的作用是什么?
- OpenStack和Docker区别
- OpenStack和kvm的区别
- kvm和xen区别
- Neutron
-
- vlan和vxlan的区别
-
- Docker
-
-
- 命名空间
-
概述
云计算是一种采用按量付费的模式,基于虚拟化技术,将相应计算资源(如网络、存储等)池化后,提供便捷的、高可用的、高扩展性的、按需的服务(如计算、存储、应用程序和其他 IT 资源)。
云计算基本特征:
- 自主服务:可按需的获取云端的相应资源(主要指公有云);
- 网路访问:可随时随地使用任何联网终端设备接入云端从而使用相应资源。
- 资源池化:
- 快速弹性:可方便、快捷地按需获取和释放计算资源。
- 按量计费:
常见的部署模式
- 公有云
- 私有云
- 社区云
- 混合云
三种服务模式
- IaaS:云服务商将IT系统的基础设施(如计算资源、存储资源、网络资源)池化后作为服务进行售卖;
- PaaS:云服务商将IT系统的平台软件层(数据库、OS、中间件、运行库)作为服务进行售卖;
- SaaS:云服务商将IT系统的应用软件层作为服务进行售卖。
云计算和虚拟化
云计算:IT能力服务化,按需使用,按量计费,多租户隔离,是一个系统的轻量级管理控制面。
虚拟化:环境隔离,资源复用,降低隔离损耗,提升运行性能,提供高级虚拟化特性。
虚拟化是实现云计算的技术支撑之一,但并非云计算的核心关注点。
IT架构的三个发展阶段
- 物理机架构:如果需要部署一个系统,需要使用多个物理机组成一个集群,所有节点都使用物理机,资源利用率都非常低,可能就20%
- 虚拟化架构:在物理机上运行多个虚拟机,将系统的各个服务部署在虚拟机上,可以极大的提高物理机资源的利用效率,降低成本
- 云计算架构:虚拟化提高了单机的资源使用率,如何对环境中的所有虚拟机进行统一管理,就要使用到云计算了。云计算将计算、存储和网络等资源虚拟化为资源池,当需要创建虚拟机的时候,平台只需要按照规格需求自动分配相应的资源创建虚拟机,完成网络IP的配置等功能。用户不需要关心虚拟机是在哪里运行的、存储空间在哪里、IP地址怎么分配的,只需要关心如何部署具体的业务就好了。
OpenStack
一个开源云操作系统内核,用于构建云平台,主要实现以下五个主要特点:
- 资源抽象:OpenStack将各类硬件资源,通过虚拟化与软件定义的形式,抽象成虚拟的资源池;
- 资源调度:OpenStack根据管理员/用户的需求,将资源池中的资源分配给不同的用户,承载不同的应用;
- 应用生命周期管理:OpenStack可以提供初步的应用部署/撤销、自动规模调整等功能;
- 系统运维:OpenStack可以提供一定的系统监控能力;
- 人机交互:OpenStack提供人机接口,外界可通过API、CLI或图形界面的方式与OpenStack进行交互。
组件间交互是消息队列,组件内部交互是restful api。
虚拟化
Ⅰ型虚拟化是:hypervisor直接安装在物理机,就像是vmware的EXSi,底下是基于硬件层的
Ⅱ型虚拟化是:在物理机的正常操作系统,hypersivor作为一个程序模块运行管理虚拟机,如kvm,virtual box,vmware woerkstation。对硬件虚拟化特别优化,性能好,灵活性高。
kvm
基于linux内核实现的。有一个kvm.so,只需好管理虚拟cpu和内存等;IO外设交给linux内核和Qemu。
Libvirt是一个kvm管理工具,除了能管理kvm还可以xen,virtualBox,openstack底层也是libvirt。
libvirt:
- libvirtd:守护进程:接受处理API请求
- API库:提供API调用,然后开发一些高级工具,比如virt-manager,可视化管理工具
- virsh:命令行工具
kvm虚拟机是需要CPU硬件支持的,一个kvm虚拟机实质上就是一个qemu-kvm进程,一个vcpu对应一个进程里的一个线程。一个cpu可以调度进程里的多个线程,也就是cvpu数量实际上可以超过cpu,叫CPU超配。可以充分利用宿主机的资源。
通过内存虚拟化共享物理系统内存,动态分配给虚拟机。实现虚拟内存->物理内存->机器内存的映射。虚拟机系统只能实现虚拟内存到物理内存,最后一步无法真正访问机器内存,因此需要kvm进行一个映射。
存储虚拟化通过存储池和卷实现的,卷在虚拟机里就是一块硬盘。
网络虚拟化
Linex Bridge是Linux上的TCP/IP二层协议交换设备,二层交换机,多个网络设备连接到同一个bridge时,有数据包传来beidge会转发给其他设备。
br-ctl show查看当前网桥配置。
比如在eth0网卡上配置一个网桥br0,然后虚拟机的网卡可以选择br0,启动以后,br0底下会挂载一个inet0的设备,这就是虚拟机的虚拟网卡,但是在虚拟机内部来说虚拟网卡时eth0,inet0是在宿主机的时候标识的名称。
virbr0是kvm默认创建的一个Bridge,作用是给连接的虚拟网卡提供NAT访问外网的功能,默认192.168.122.1,如果网络选择默认,就会挂载在这个上面。
virbr和br的区别:
- virbr会NAT,发出去的数据包的源IP会被替换为宿主机的IP,只能发不能收
- br直接使用自己的IP通信,可收可发,不用NAT
VLAN
LAN是本地局域网,通产使用hub或者switch连接其中的主机。一个LAN是一个广播域,所有成员都能收到其他成员的广播包。
VLAN是Virtual LAN,一个带有VLAN功能的switch可以将端口划分出很多个LAN。可以将一个交换机划分为多个交换机,在二层进行隔离,隔离到不同VLAN中。
一般交换机端口有两种配置方式
- Access:端口被打上VLAN标签,表明该端口是属于哪个VLAN的,不同VLAN通过VLANID区分,范围是1~4096.Access口是直接和网卡相连接的。Access口只能属于一个VLAN,网卡流出的数据包经过这个端口后直接打上一个VLAN标签
- Trunk:一个端口可以同时传输转发多个VLAN标签的数据包,在传输的过程中数据包始终携带VLAN ID
总结:
- 物理交换机有多个VLAN,每个VLAN可以有多个端口。有交换和隔离两个二层功能,同一VLAN相互交换转发,不同VLAN相互隔离
- Linux的VLAN只能实现隔离,不能实现交换,因为比如一个VLAN母设备,比如物理机的网卡eth0,他不允许连接两个相同的ID的VLAN子设备,不存在同意VLAN交换转发的情况
- LinuxBridge,将同一VLAN的子设备挂载到一个Bridge上,就可以实现交换转发了。LinuxBridge+VLAN可以模拟现实世界的二层交换机
基本技术
Memcached
是一个高性能分布式内存对象缓存系统,在OpenStack中用于缓存认证系统的令牌,减少高并发下对于数据库的访问压力,提高访问速度。
将需要存取的数据或对象缓存在内存中,内存中缓存数据可以通过API进行操作,数据经过Hash操作以后存在一个Hash表中,是K-V形式存储。
memcached没有访问控制和安全管理,因此需要使用防火墙等安全功能进行相应防护
使用最近最少使用算法LRU对最近不活跃的数据进行清理,从而得到新的内存空间。
对于大规模数据缓存有着较为明显的优势而且通过开放API多种语言可以直接操作memcached。OpenStack的keystone就是用memcached缓存租户的身份等信息、从而在租户登录验证的时候无需重复访问数据库即可查询得到相应数据。Horizon和Swift也用到了这个来进行数据的缓存以提高客户端的访问请求速率。
操作的过程
- 检查数据是否存在memcached,如果有直接返回
- 如果数据不存在memcached,去数据库查询,同时将数据库缓存到memcached
- 每次更新数据库的时候同步更新memcached的数据保证一致性
- 如果分配的内存空间满了,使用LRU算法对失效的数据进行处理
功能特点
- 协议简单:基于文本行进行操作
- 基于libevent事件处理:将epoll等事件处理封装成一个接口,保证服务器端的连接数,使用这个库进行异步事件处理
- 内置的内存管理方式:有自己特有的一套内存管理方式,很高效;但是不考虑容灾,重启数据丢失
- 节点之间相互独立:各个服务器之间互不通信,独立存取数据不共享,通过客户端实现其分布式,支持海量缓存和大规模应用
缺点
- 单点故障:因为每个节点是独立存取数据的,服务器之间没有通信,即不会进行数据的同步和备份,如果一个节点down了,节点的数据全部丢失且无法恢复
- 存储空间限制:会受到寻址空间大小限制,32位系统可缓存2G,64位可缓存无限,只要物理内存足够大
- 存储单元限制:K-V的key最大250字节,value最大1MB
- 数据碎片:内存存储单元按照Chunk分配的,会造成内存碎片,因为不可能所有存储的value大小都是一个Chunk大小
- 不安全
Etcd
是一个go语言开发的开源的高可用的K-V存储系统,用于配置共享和服务的注册和发现。
集群部署一般使用奇数个服务器配置,因为Raft决策时候需要多节点投票。
有几个特点:
- 高可用:避免因为单点故障或者网络故障造成服务down
- 一致性:每次读取都会返回跨多个主机的最新写入
- 完全复制:每个节点都可以使用完整数据归档
- 安全:提供一个带有可选的客户端证书身份验证的自动化TLS
- 快速:每秒一万次写入的基准速度
- 可靠:使用Raft算法实现强一致、高可用的服务存储目录
应用场景
- 服务发现:同一个分布式集群中找到是否有进程在监听端口
- 配置中心:讲一些数据放在Etcd集中管理,比如在启动的时候主动从etcd获取配置信息,并且设置一个Watcher,有更新的时候etcd会主动通知订阅者获取最新配置信息
- 分布式锁:使用Raft实现数据的强一致性,某次操作存储必须是全局一致性的。有两种:保持独占(始终只有一个用户可以获得,实现了一套分布式原子操作CAS的API)、控制时序(所有想获得锁的用户都会被安排执行,获得锁的顺序也是全局唯一,决定了执行的顺序)
相比荣誉zookeeper和doozer,有如下特点:
- 简单:基于HTTP+JSON,提供API便于调用
- 安全:使用SSL客户认证机制
- 快速:实例每秒支持一万次写操作
- 可信:Raft算法实现分部署
消息队列
rabbitmq属于AMQP(高级消息队列协议)的一种实现,应用层的一个开放标准。
特点:
- 较高的灵活性
- 高可扩展性,多个rabbitmq可以组成集群
- 支持常见的编程语言
- 提供可视化界面便于管理
- 支持多种协议,不只是AMQP
- 提供了多种插件
AMQP的三大组件:
- Exchange交换机:把消息路由到队列
- Queue队列:存储消息等待消费,多个消费者可以订阅同一个队列
- Binding绑定:将交换机和队列进行绑定,告知交换机应该投递到哪个队列
优点:
- 异步:如果阻塞式的话,A给B发请求,B如果处理需要很长时间,那么A也需要等待很久,显然是不合理的,还会资源浪费,可以通过消息队列先发送一个请求命令给B ,然后A直接进行下一步,当B有结果时会通知A
- 解耦:如果每一个组件之间通过直接通信的话,都需要维护一套比如接口代码,会有很多重复冗余的代码,,而且还需要考虑比如对方是否接到消息,消息是否丢失之类的。使用消息队列就不需要考虑这些了,把消息投递进入就好了,剩下的消息队列做
- 削锋:如果短时间内有大量请求直接到服务器,可能会造成拥塞甚至崩溃。放入消息队列里,消费者可以依次取出消息进行消费,相当于一个缓冲,虽然会慢一点,但是会很高效稳定
概念
有几个概念关键词
- Exchange:消息交换机,它指定消息按什么规则,路由到哪个队列
- Queue:消息队列载体,每个消息都会被投入到一个或多个队列,多个消费者可以订阅同一个队列
- Binding:绑定,它的作用就是把exchange和queue按照路由规则绑定起来
- Routing Key:路由关键字, exchange根据这个关键字进行消息投递
- producer:消息生产者,就是投递消息的程序
- consumer:消息消费者,就是接受消息的程序
- channel:消息通道,在客户端的每个连接里,可建立多个channel,每个channel代表一个会话任务。
交换机类型
- Direct Exchange(直连交换机):交换机和队列一对一匹配
- Fanout Exchange(扇型交换机):消息会被发送至所有与该交换机绑定的队列,不会按照指定的路由键进行投递,类似广播
- Topic Exchange(主题交换机):交换机会将消息的路由键和绑定到自身的队列进行匹配,将消息投递到匹配上的队列中去。比如如果写成这样
log.#,那么可以匹配log.开头的routingkey - Headers Exchange:类似主题交换机,但是是使用消息头部的属性进行分发,而不是routingkey
缺点
系统可用性降低,rabbitmq挂了以后系统就崩了。
如何解决消息重复投递或者丢失的问题
如何解决消息按顺序发送的问题
重复投递问题
给每一个消息设置一个类似唯一标识的一个ID,接收者去除消息以后先在数据库中对比一下是否存在,如果不存在,就正常消费。
顺序投递问题
还是使用一个ID,一般这个会出现在比如说订单的场景,生成订单,制作订单,订单号都是一样的,把这些消息投递到一个订单队列里面,取出的时候就是顺序的了。
restful api
restful api是一种软件架构设计的风格,不是标准,提供了一组设计的原则和约束条件,是一套编写接口的协议,协议规定如何编写,返回值和状态码等,主要用于客户端和服务器端的交互。
最显著的特点就是一个url可以通过不同的HTTP方法实现不同的功能,而no rest则需要使用多个url分别实现多个功能。
- 还可以使用https
- 不同版本可以有不同接口
- 可以根据不同http方法执行不同操作
- 返回格式应该统一为json,还有状态码
django中的erest框架叫django rest framework
能够生成符合restful规范的api
- 在开发restful api的时候,虽然具体业务流程不一样,但是基本增删改查操作差不多,这部分代码可以简写复用
- 序列化和反序列化的时候代码流程也差不多,,也可以简写
传统的URL需要在链接里加上操作的动作等;
而restful api则用URI统一资源标识符唯一标识服务器的一个资源,并且使用HTTP方法对其进行操作
Horizon
提供一个Web前端控制台,从而实现通过web管理云平台,建云主机,分配网络,配安全组等。
Region(区域):地理上的概念可以理解为是两个不同区域的数据中心,是完全隔离的,但是可以共享同一套keystone和horizon了用户可以选择距离自己更近的域使用服务
Nova
端口
- nova-api:通过接口对外提供服务,接受请求处理操作调度资源等。接收传来的HTTP请求校验参数,然后调用其他子服务实现请求操作,之后处理结果返回
- nova-compute:Nova的核心服务,,负责管理虚拟机的整个生命周期如创建相应销毁等,通过调用Hypervisor API
- nova-scheduler:虚拟机调度服务,决定虚拟机应该创建在哪个节点。通过过滤器选择合适的计算节点,然后计算节点权重,选择最优的节点(默认权值是计算空闲内存量,内存越大权值越大)
- nova-conductor:负责数据库的访问控制,避免compute直接访问数据库。避免计算节点出现故障导致数据库出现问题,可以扩展配置多个conductor更好的应对更多计算节点对于数据库的访问
创建一个虚拟机大概的流程:
- 发送http请求,nova-api接受请求后,进行参数和身份校验
- 发送消息给nova-schedule调度计算节点
- 发送消息给nova-compute创建实例
- 在整个过程中通过nova-conductor与数据库进行访问交互
这里的消息发送全部都是通过消息队列实现的,进行异步调用,不会阻塞服务;解耦各个子模块功能;提高可扩展性;提高性能,可以处理多个请求,提高吞吐量
使用API的好处:
- 对外提供了一个统一的调用方法,隐藏实现细节
- 提供了restful风格的服务,便于和第三方集成
- 通过运行多个api进程实现高可用
OpenStack的开放性,一个重要方面就是基于Driver的框架。比如说nov-acompute中为hypervisor定义了统一的接口,支持多种Hypervisor,如Xen、VirtualBox、Hyper-V、Docker等
nova-api
对外暴露若干个Restful API,用户可以发送请求到指定Endpoint
- 收到HTTP请求后,会先进行参数校验
- 调用nova其他子服务开始执行相应操作
- 再返回执行的结果
和虚拟机生命周期的指定请求nova-api都可以收到并处理。
nova-scheduler
在创建虚拟机的时候需要指定一个flavor也就是规格,其中规定了vcpu、ram、disk等参数,随后将falvor信息传入到noca-scheduler中,会根据flavor选择一个合适的节点创建虚拟机。
Filer scheduler是默认调度器,过程分为两步,第一是通过过滤器计算出满足条件的计算节点,通过权重计算,在权重最大(最优)的节点创建虚拟机。
同样可以使用第三方的scheduler,只需要配置一个scheduler_driver即可,再次体现出OpenStack开放性。
过滤器类型
nova可以配置默认使用全部过滤器acheduler_availiable_filters,但是真正使用到的是这个参数scheduler_default_filters
- RetryFilter:如果AB节点通过了第一步过滤,然后A权重最大,但是在A创建失败了,那么下一次调度的时候,就会在第一步将A刷掉,避免再次失败
- AvailabilityZoneFilter:为了提高容灾和隔离,将计算节点可以划分到不同的AvailablittZone中,每个AZ都可能有着各自独立的电力系统、独立的网络和机柜等,为了应对故障的发生,一个Region可以有多个AZ,默认是nova。这里会判断将不属于指定AZ的计算节点删除
- RamFilter:将不满足flavor中内存规格的计算节点除去。OpenStack允许overcommit,可以在nova里面改这个参数
ram_allocation_ratio=1.5,如果某个计算节点有10G内存,OpenStack会认为其有15G内存 - DiskFilter:同上,同样允许overcommit,默认参数值为1
- CPUFilter:同上,允许overcommit,默认参数值为16.也就是如果一个计算节点有8vcpu,那么OpenStack会默认其有128vcpu。默认过滤器是不包含这个过滤器,需要手动添加
- ComputeFilter:保证工作正常的计算节点才会被筛选出来,是必须的一个过滤器
- ComputeCapabilitiesFilter:根据计算节点的特性筛选,如计算节点有x86_64和ARM架构,如果指定ARM架构,就需要这个过滤器,这个需要在flavor的Metadata中指定
- ImagePropertiesFilter:image同样具有metadata,根据这个元数据筛选出匹配的计算节点。比如可以选择
hypervisor_type=kvm,那么使用这个镜像过滤就只能筛选出kvm的节点 - ServerGroupAntiAffinityFilter:尽可能将实例分散到不同的节点上。需要创建一份server group,把实例添加进来才有用
- ServerGroupAffinityFilter:尽可能创建实例在一个计算节点上。
nova-compute
compute和hypervisor一起共同管理虚拟机生命周期。
定义了很多统一的接口,hypervisor实现这些接口就可以在openstack里面了。
一个计算节点只能指定一种虚拟类型。
主要有两种功能:
- 报告计算节点状态
- 实现虚拟机生命周期管理
需要实时报告计算节点可用内存、vcpu等数量,scheduler才可有进行过滤调度的依据,通过hypervisor api获取虚虚拟机的资源信息。
管理生命周期包括如下:
- 为实例准备资源
- 创建实例镜像文件
- 创建实例的.xml定定义文件
- 创建网络并启动实例
在下载镜像的时候,如果存在就直接使用,会很快,不存在会先下载。比如是qcow2格式的镜像,由qemu-img转为raw格式然后进行backing file,这个不能是qcow2格式。
基本操作
- 软硬重启其实就分别是reboot重启和关机再开机
- Pause/Resume:可以暂停虚拟机,并将状态保存到内存中,需要的时候再resume读取内存恢复虚拟机
- Suspend和Pause:前者可以暂停虚拟机并将状态保存在磁盘上,后者保存到内存中,相对较快;前者状态会变成shutdown,后者是paused;前者对应的恢复操作叫resume,后者其实是unpaused
- rescure/Unrecure:救援。当因为断电或者误操作导致操作系统出现故障不能启动实例了,一般会使用一张引导盘进入系统,然后试图恢复系统,比如忘记密码或者删除了某个文件。rescure可以将某个image作为启动盘,然就将原系统盘挂载到这个操作系统上,fdisk可以看到,新的image是vda,原系统盘就是vdb,修好以后unrescure恢复引导盘
- snapshot:快照的原理就是对实例的镜像文件进行全量备份,保存到glance。
- rebuild:当损坏严重的时候,可以使用快照恢复。rebuild会使用快照替换当前实例的系统盘,并且保持实例原有的网络、资源等信息
Keystone
常用的5000端口,以及没怎么用过的35357端口
为OpenStack其他服务提供身份验证、服务规则和服务令牌的功能,管理Domains、Projects、Users、Groups、Roles。
- User:代指任何使用gopenstack的实体,可以是真正的用户,也可以是一个系统服务,在访问openstack的时候,keystone会对User进行身份认证
- Credentials:User用来表明自己身份的凭证,可以是用户名密码、token或者API Key等
- Authentication:是keystone验证User身份的一个过程,User访问openstack的时候向keystone发送用户名密码等信息,keystone验证成功后返回一个token,作为用户的Credentials
- Token:是一串数字和字母组成的字符串,用户在keystone验证身份后会得到,在访问其他服务的时候会被用来验证身份有效性,一般默认24小时。
- Project:用于将OpenStack的资源进行分组和隔离,可以是一个客户或者部门。一个用户需要挂载到Project后才能访问其中的资源
- Service:Nova、Glance等就是OpenStack的服务,每个Service会提供若干个Endpoints供用户去访问资源和执行操作
- Endpoint:是一个可以访问的地址,通过Endpoint暴露自己的API,keystone维护
- Role:对用户进行鉴权,每个User会被分配一个或多个Role,该用户拥有Role指定的权限。如果修改权限需要修改
/etc{service_name}/policy.json
Glance
监听端口:
- glance-api:9292
- glance-registry:9191
传统的安装一个系统可能需要从CD或者ghost工具进行安装,非常繁琐。二运计算环境中有一个更高效地解决方案,就是Image。
每个Image中装有操作系统以及相应的配套软件环境,用户可以直接使用安装即可快速创建一个虚拟机。
比如云计算中可以有这么一个场景:当我们需要有一个新的系统需求的时候,我们可以先手动创建一个虚拟机然后安装好相应的操作系统和需要的软件环境,然后创建一个snapshot保存在云中,后续如果有用户需要使用可以直接使用这个snapshot快速创建虚拟机,这都是可以自动完成了。
为云主机提供不同系统镜像,支持多种虚拟机镜像格式(AKI、AMI、ARI、ISO、QCOW2、Raw、VDI、VHD、VMDK),有创建上传镜像、删除镜像、编辑镜像基本信息的功能。
glance-api对外提供restful api接口调用,当有请求来以后,api不会自己主动处理,而是会调用glance-registry处理有关元数据的操作,调用store backend处理有关镜像的操作。
Image默认存储在/var/lib/glance/images。
glance-registry负责处理有关metadata的操作,如存取。比如image的大小或者类型,支持多种格式:QCOW2、RAW、vmdk、ISO等,元数据默认保存到mysql
store-backend:glance自己不保存镜像,而是使用backend存储,glance支持多种backend,如默认的local filesystem本地文件系统、ceph、swift、cinder、EXSI等
Neutron
端口9292
提供云计算的网络虚拟化技术,为OpenStack其他服务提供网络连接服务。为用户提供接口,可以定义Network、Subnet、Router,配置DHCP、DNS、负载均衡、L3服务,网络支持GRE、VLAN。插件架构支持许多主流的网络厂家和技术,如OpenvSwitch。
根据网络类型的不同有以下几种网络:
- Flat network:基于不使用 VLAN 的物理网络实现的虚拟网络。每个物理网络最多只能实现一个虚拟网络。
- local network(本地网络):一个只允许在本服务器内通信的虚拟网络,不进行跨服务器的通信。主要用于单节点上测试。
- VLAN network(虚拟局域网) :基于物理 VLAN 网络实现的虚拟网络。共享同一个物理网络的多个 VLAN 网络是相互隔离的,甚至可以使用重叠的 IP 地址空间。每个支持 VLAN network 的物理网络可以被视为一个分离的 VLAN trunk,它使用一组独占的 VLAN ID。有效的 VLAN ID 范围是 1 到 4094。
- GRE network (通用路由封装网络):一个使用 GRE 封装网络包的虚拟网络。GRE 封装的数据包基于 IP 路由表来进行路由,因此 GRE network 不和具体的物理网络绑定。
- VXLAN network(虚拟可扩展网络):基于 VXLAN 实现的虚拟网络。同 GRE network 一样, VXLAN network 中 IP 包的路由也基于 IP 路由表,也不和具体的物理网络绑定。
网络转发
一般架构是控制节点、计算节点和网络节点。
网络节点就dhcp服务之类的,计算节点是各种agent,控制节点是neutron-server一个组件。
然后如果跨子网通信的话,流量需要从计算节点到网络节点,通过router路由一下,转发到对应的计算节点的实例上。而如果需要配置NAT的话是需要在router上面配置的,也就是网路节点,如果有需要流量转发出去的话,都需要通过网络节点。
但是这样的话网络节点的压力就比较大,一旦网络节点崩溃了,整个网络就崩了;还有一个就是即便两个实例在同一个计算节点上,如果不在一个网络中,还需要经过网络节点路由一下才能回来,很麻烦。
那么就有一个东西DVR(Distributed Virtual Routing),部署在计算节点,可以直接使用浮动IP访问外网,不需要经过网络节点了。是通过openflow规则进行判断的。
Neutron功能:
- 二层交换:实例通过虚拟交换机连接到虚拟二层网络,Nova支持多种交换机,Linux Bridge和OpenvSwitch(开源虚拟交换机)
- 三层路由:给实例配置不同网段的IP,router(虚拟路由器)可以实现跨网段通信,使用IP forwarding、iptables等实现路由和NAT
- 负载均衡
- 防火墙:一个是security group使用的iptables、另一个是firewall-as-a-service,也是基于iptables的
一些概念
- network:二层广播域,支持多种类型网络:local、flat、vlan、vxlan、gre
-
- local:这个网络与其他网络节点隔离,只能和同一节点的同一网络实例通信
-
- flat:没有vlan tag的网络,网络中的实例可以和其他实例通信
-
- vlan:802.1q标签的网络,一个二层广播域,同一个vlan中的实例可以相互通信,不同vlan只能通过router通信。vlan可以跨界点,标签数为1-4096
-
- vxlan:基于隧道技术的overlay网络,VxLAN网络使用唯一的段ID与其他VxLAN进行隔离。会通过VNI封装为UDP数据包传输,二层包通过封装可以在三层传输,因此克服了物理网络基础设施的限制
-
- gre:是和VxLAN类似的overlay网络,区别在于使用IP包封装而不是UDP
一些虚拟的网络设备
Veth pair
Veth是linux系统虚拟出来的一个网络设备,总是成对出现的,功能类似虚拟网线的功能,在创建两个Veth设备,假设放在两个namespace里面,那么通过这个Veth设备可以实现相互通信,默认情况下是不通的。
通常链接网络的namespace,也链接linuxbridge,一般用于连接两个linuxbridge或者一个linuxbridge和ovs,两个ovs一般不太用这个,一般用patch连接两个ovs bridge,效率更好。
实际操作
在这里创建一个新的namespace,然后创建一对Veth pair试一下,单纯记录,我没有操作过。
#创建namespace
ip netns add tns(tempnamespace)
#创建Veth设备
ip link add tns-0 type veth peer name tns-1
#生效网卡
ipconfig tns-0 up或者ip link setet tns-0 up
ipconfig tns-1 up
#将一段veth pair 1放入namespace,并重命名为eth0,添加新的网络网卡接口
ip linhk set tns-1 netns tns
ip netns exec tns-1 name eth0
#生效一下网卡
ip netns exec tns ip link set eth0 up
ip netns exec tns ip link set lo up
#设置一下新的Veth网卡设备的IP地址,随便写吧
ip netns tns ip addt add 10.254.1.1/24 dev eth0
ip addr add 10.254.1.2/24 dev tns-0
#现在可以验证连通性了验证
ip netns exec tns ping 10.254.1.1
TUN、TAP
Veth是两端都一样的虚拟网线,而这个就是两端都不一样的虚拟网先,相当于一边是水晶头,另一端是USB接口,是用户空间和内核空间传输报文使用到的“网线”,一边是普通的网卡比如eth0,另一端是文件描述符,用户空间使用的。
实例的本质是qemu进程,因此TUN、TAP网线一般是给VM用的,所以这个文件描述符一般是VM,另一端则是虚拟出来的TAP设备,这也就是为什么Neutron几种网络模型里面的VM或者linuxbridge连接router的时候都是通过TAP设备的
Bridge
是一种虚拟集线器的实现方式,多个网卡连接到这个上面,一个发送报文其他都能接收到。
把TUN/TAP或者Veth pair放在Bridge上面,就可以实现相互通信。Docker就是用linuxbridge将所有的容器连接在一起,bridge模式,就是docekr0网卡
架构
Neutron主要有以下几个部分:
- Neutron Server:对外提供API,接收请求,调用Plugins处理请求
- Plugin:处理来自Server的请求,并且转发调用Agent处理请求
- Agent:处理来自Plugin的请求,并且在network provider上具体实现每个网络功能
- network provider:提供网络服务的虚拟网络设备或物理网络设备,比如Linux Bridge或者OpenvSwitch或者其他支持Neutron的物理交换机
- Queue:组件之间交互的消息队列
- Database:存放网络状态信息
架构这么多层次有两个原因
- 为了支持现有或者未来出现的网络技术
- 为了支持分布式的灵活扩展性
plugin有一个功能时需要维护数据库中的网络状态信息,如果有多个插件的话,每一个provider的plugin都要写一套类似的数据库操作代码,会很繁琐,因此现有版本使用了ML2 plugin,对plugin进行了抽象。只需要实现响应driver就行了,不需要具体实现plugin了。
plugin主要分为两种(均有对应的agent):
- core plugin:比如linux bridge或者openvswitch
- service plugin:比如routing、firewall、load balance等
物理架构
有两种。
第一种:控制节点+计算节点
控制节点配置neutron server、core plugin、service plugin和两个对应的agent
计算节点配置core plugin的agrnt,负责二层网络功能。
通过agent实现控制节点和计算节点之间的二层网络通信,可以部署多个控制节点和计算节点
第二种:控制节点+网络节点+计算节点
控制节点配置neutron server
网络节点配置core plugin、service plugin和对应的agent
计算节点配置core plugin,负责二层网络功能
- 将agent从控制节点分离出来,控制节点只通过neutron server处理分发api请求
- 可以通过增加网络节点的个数提高负载
- 使用独立的节点实现数据交换,并且可以配置路由、负载均衡等高级功能
- 适合大规模环境
Neutron Server
由上而下分别是
- Core API:对内提供restful api,如管理子网网络端口等
- Extension API:对外提供restful api,如管理router、firewall-as-a-service、负载均衡等
- Common Service:认证校验API
- Core Plugin API:定义个Core Plugin抽象功能,通过API调用对应plugin
- Neutron Core:Neutron的核心处理程序,调用相应Plugin处理
- Extension Plugin API:定义。。。
- Service Plugin:维护管理router、负载均衡等资源状态信息,调用agent在network privider上实现相应功能
但是提出了两个问题
- 只能使用一种core plugin,多个无法共存
- 不同plugin之间复用的代码太多了,维护工作量大
ML2 Plugin
主要解决上面说的两个问题
允许网络中使用多种二层网络技术,不同节点直接按可以使用不同的网络实现机制。
可以在不同节点上使用不同的agent了,而且不用重新开发core plugin,实现mechanism driver就可以了。
ML2对二层网络进行了抽象解耦,type driver和mechanism driver使得其具有非常好的弹性,能够灵活支持多种agent(type或者mechanism)
每一种网络都有这么两种driver
Type Driver
负责管理网络状态、创建网络等。
有这么集中网络类型:local、flat、vlan、vxlan、gre
mechanism driver
获取由type维护的网络状态,并且确保其在物理或者虚拟设备上的实现
比如创建一个VLAN100,VLAN的type driver负责将数据保存在数据库里,然后linux bridge的mechanism driver负责在各个节点上调用agent创建相应的vlan设备和bridge。
Mechanism Driver有三种:
- Agent-based:就是基于agent的,比如linux bridge和openvswitch
- Controller-based:基于控制器的,如opendaylight,就是sdn
- 基于物理交换机:如思科的设备
Linux Bridge实现
local network
local网络不会和任何物理网卡连接,也不会有VLAN ID。
对于每一个local网络都会创建一个网桥,将实例的tap设备绑定到网桥上。
同一网桥上的实例可以相互通信。每个local网络都有自己的网桥,互不影响,因此同一个节点上不同往前的实例不能通信。
其实只有admin创建网络可以选择type driver,普通用户在自己租户里创建网络的时候默认使用/etc/neutron/plugins/mk2/ml2_conf.ini里面的一个参数tenant_networks_type=local,默认是local,需要修改一下,可以指定多个,如vxlan,local,会从左到右按照顺序依次创建,如果vxlan的id用完了,就会创建local。
命名
brqxxxxxx对应的是网络,表明这是网络id为xxxxx创建的一个网桥
tapyyyyy,其实就是虚拟机的一个虚拟网卡,对应的是port,说明这是id为yyyy的port的tap接口设备,tap将连接到brq上
在创建实例的时候,neutron-linubgridge-agent根据port信息创建一个tap设备,连接到local网络所在的bridge网桥上。这个tap设备就会映射为实例的虚拟网卡。
flat network
不带tag的,要求和物理网卡连接,所以需要在ml2的配置文件里写physical_interface_mappings=default:thh0,前面式一个label,用来标识flat,可以是任意字符粗汉,就是表明和物理网卡的对应关系,因为可能每个节点使用的物理网卡不一样,因此这里的default就映射为配置好的物理网卡。
如果不同节点的实例连接到同一个网络,他们所处的网桥名称一致,通过provider network通信。
vlan network
vlan是带tag的网络。
如下所示,多个tap连接到brq网桥上。eth1网卡上创建了一个eth1.100的vlan interface接口,可以连接到这个brq上,然后通过eth1.100到eth1的数据包就会被标记一个100的vlan tag。
如果有多个eth1.xxx接口连载eth1网卡上,就可以通过这个tag标签相互隔离不同的vlan。

如果需要这么设置的话,物理机连接的交换机端口需要设置为trunk,不能是access,因为需要流过多个tag数据包
vxlan
OpenStack支持VxLAN和GRE这两种overlay网络,overlay网络指建立在其他网络之上的网络。
linuxbridge只支持vxlan,ovs两个都支持。
优点
- VLAN使用12bit标记tag,最多4096个,而VxLAN支持24bit,最多16777216个二层网段
- 能够很好利用已有路径,封装UDP通过三层传输和转发,可以使用所有路径。(VLAN用了Spanning Tree Protocol避免环路,有一半路径用不成)
- 避免物理交换机MAC表耗尽,因为用了隧道技术,不需要再MAC表里记录虚拟机信息
缺点
其实也是有一些缺点的
- 比如强制在三层传输数据包可能路径不是最优传输速度慢
- 虽然避免了物理交换机记录大量的虚拟机MAC,但是可能会造成路由器的ARP表有较多的记录,影响正常的性能
- 而且标准规定VxLAN不能分片,要求物理链路层的MTU足够大才行
VxLAN是将二层建立在三层上的网络,把二层数据封装在UDP数据包里扩展二层网络。IP+UDP
DHCP服务
通过DHCP agent实现DHCP服务。运行在网络节点,dnsmasq
当 创建一个网络的子网开启dhcp功能后,agent会启动一个dnsmasq进程提供服务,其实dnsmasq和network是对应的,一个进程可以给所有的子网提供dhcp服务。
通过dnsmasq获取IP信息。
在创建实例的时候,实例会绑定一个port,有MAC和IP信息,dnsmasq会把这个记录在一个host文件里。
实例启动以后,会发送DHCPDISCOVER广播,然后广播消息会在flat网络里传播,通过veth paur到达另一个namesapce里面,dhsmasq监听到了,然后返回对应的IP信息,DHCPOFFER,包含IP地址、租期时间等给实例
最后实例返回一个DHCPREQUEST消息接收DNSOFFER。
NameSpace
二层网络上可以通过VLAN将物理交换机分割为多个虚拟交换机。
而namespace可以将物理的三层网络划分为多个隔离的虚拟三层网络,有这几个字的网络栈、防火墙规则、路由表等。
Neutron就是通过namespace为每个network提供DHCP服务和路由,让租户之间的网络可以重叠不冲突,提高了灵活性。
每个namesapce里有各自的dnsmasq,ip nets list可以查看。
管理员可以将brq或者tap添加到某个namesapce里面。
如何让两个namespace相互通信呢
默认是不能通信的,Neutron里面使用了 veth pair,相当于虚拟网线,连接两个namespace,这边输入另一边接收。
Routing
路由提供了跨子网的通信。这里有两个实例
vm1 - 172.16.100.3 - vlan100
vm3 - 172.16.101.3 - vlan101
这两个实例是两个不同vlan的,他们之间不能通过二层交换进行通信,必须借助router。
虚拟router由L3 Agent在控制节点或者网络节点运行。
底层实现
通过配置一个router,vm1和vm3就可以进行通信了。
首先vlan101的bridge网桥上多了一个tap设备,这个设备就是路由器的interface接口
同样vlan100所在的网桥也有这么个接口设备。
L3 Agent会给每个router配置一个namespace,使用veth pair和tap设备连起来。对应的gateway ip在namesapce内的veth interface上。叫qr-…
其中namespace里的qr-xxxx和tap-xxxx组成veth pair进行通信。
如下图所示

引入namespace而不直接使用网关的作用
为了使得租户之间的网络可以重叠提高灵活性。
不然如果A和B都有相同子网,只用网关的话需要在控制节点的路由表上加两项,而且目的IP可能一致,无法区分了。
router连接外网
给router配置好一个外部网络(一般是flat或者vlan类型)的网关以后,router多一个接口,通过这个接口可以连接到外网,ip比如是10.10.10.2。
然后连接外部网络的bridge的tap-xxxx设备,通过veth pair和路由器namesapce内的qg-xxxx接口连接
冷知识,router的内部网络的接口叫qr-xxxxx,外部网络叫qg-yyyyy
此时看ip nets exec qrouter-xxxx route,会看到10.10.10.1有一个qg的接口。说明如果是外网流量的话,router会通过这个接口将流量转发到这个网关,然后到linuxbrige的brq网桥上转发到网卡上。。
从qg-xxxxx出去的话会进行一个SNAT的转换,将源IP修改为router的源IP 10.10.10.2,以便回来的时候可以找到路由器

floating IP
SNAT可以让实例访问外网,但是还不能让外网访问实例,使用浮动IP可以解决这个。
floating ip可以提供一个一对一映射的静态NAT。
创建好一个floating ip以后,会配置到router的外网的qg接口,然后iptables会添加两个规则
- 如果是内网IP到达路由器,转换为对应的floating ip发送出去
- 如果是floating ip对应的数据包到达路由器,会修改为对应的内网IP
Fwaas
让用户可以创建和管理防火墙,在子网的边界进行流量过滤。传统的防火墙是在网关上的,隔离子网,而这个是在router上配置的,控制租户网络进出的流量。
分为:
- Firewall:必须关联某个Policy
- Firewall Policy:是Rule的集合,会按照Policy中的顺序依次过滤
- Firewall Rule:访问控制规则,包括源IP和端口、目的IP和端口,协议类型以及操作
安全组的对象是虚拟网卡,L2 Agent实现,对通过iptables实现对实例虚拟网卡流量的过滤。而fwaas是配置在虚拟路由器上的,在到达安全组之前可以先过滤一下,但是同一个subnet内部的虚拟网卡间不会过滤,因为不通过router。
fwaas没有单独的agent,是在L3 Agent中配置的,driver为IP tables,要在service plugins启用fwaas。
FWaaS v2
上面说的是v1,Stein版本以后,v1废弃了,是v2了。
Firewall概念变为Firewall Group了,而且不像v1是唯一绑定一个路由器,v2需要指定路由器的某个接口。
可以同时管理ingress和egress进口和出口两种流量。v1则不区分,对双向流量进行过滤,安全组区分流量。
OpenvSwitch
ovs是除了linuxbridge外的另一种虚拟化交换机技术。
安装ovs agent,修改ml2的mechanism_drivers。
初始状态有三个网桥:
br-int:连接所有虚拟机的虚拟网卡或和其他虚拟网络设备br-ex:连接外部网络的网桥br-tun:隧道技术用这个,比如VxLAN或者GRE
计算节点没有br-ex,因为计算节点的外网流量是通过网络节点的虚拟路由器转发的,所以br-ex在网络节点上。
local network
同样的local网络不会和网卡连接,流量被限制在宿主机内,只有同一个网桥上的才可以通信。
创建了一个local网络以后,br-int网桥上有一个tap设备,是dhcp的接口,tap设备是在这个命名空间里的。
创建一个实例以后,Neutron在子网subnet中创建一个port,分配IP和MAC,绑定在实例上,会创建一个tap-xxxx设备作为实例的虚拟网卡。
然后在linuxbridge上创建一个qbr-xxxx网桥,和tap设备相连。
然后通过veth pair连接到br-int,即qvb-xxxx与qvo-xxxx。
为什么需要使用一个linuxbridge中转不能直接使用tap设备连接到br-int呢
因为ovs不支持将iptables规则放在与其相连的tap设备上,因此为了实现security group安全组的功能,需要引入linuxbridge作为一个中转
如下图所示
一个实例的网络设备连接情况如下(以次连接):
- tap-xxxx:虚拟网卡
- qbr-xxxx:tap连接到linuxbridge的qbr,为了使用security group功能
- qbr通过一对veth pair(qvb-xxxx和qvo-xxxx)连接到br-int网桥
在linuxbridge里面用veth pair连接br-int和linuxbridge,而这里使用patch连接br-int和br-eth1。
veth pair 和 patch
两者都可以作为一个类似虚拟网线的功能连接网桥。- patch port是连接两个ovs bridge的专属,而且性能更好
- veth pair只能用于连接两个linuxbridge或者linuxbridge与ovs连接
底层实现
创建一个flat网络与后,会创建一个dhcp的接口,tap-xxxx连接到br-int网桥。
创建一个虚拟机后,同样的,先创建一个tap设备作为虚拟机的虚拟网卡,然后连接到linuxbridge的qbr网桥上,然后qbr通过一对veth pair连接到br-int网桥。VLAN 网络
ovs中是所有虚拟网卡都连接到br-int网桥,而linuxbridge里面则是不同VLAN连接到不同网卡的VLAN网桥。因此物理交换机连接eth1的口也要设置为trunk。
ovs通过flow rule对流过br-int的数据包进行转发处理,比如打上tag或者去掉tag等。
ovs-ofctl dump-flow查看流规则。
比如br-eth1网桥的流规则如下,这里的in_port编号可以在ovs-ofctl show查看到。
这里就是说从br-eth1网桥的phy-br-eth1(port=2)端口进来的vlan为1的数据包,修改vlan id为100然后发送出去

br-int网桥的规则同理
这里的tag和VLAN其实是不一样的,tag是ovs内部进行网络隔离使用的,在接收到数据包的时候,需要进行vlan的一个映射,Neutron维护VLAN ID的映射关系。Roting
两个子网之间的实例通信需要使用路由器进行通信。
创建一个路由器以后,将 子网可以添加到路由器的接口上,接口的IP分别为子网的网关。
br-int网桥上多了两个接口port,叫qr-xxxx。router也是运行在自己的namesapce里面。
如果路由器需要连接外网,需要绑定一个外部网关,然后router就多了一个接口10.10.10.2,用于连接外网。也就是路由器的qg-xxxx接口。VxLAN
可以设置VxLAN 的vni也就是tag,需要在配置文件的
[ovs]配置tunnel_bridge。
br-int和br-tun是通过patch port连接的,其中patch-tun在br-int上,patch-int在br-tun上。
底层实现
创建网络以后,dhcp也会通过tap设备连接到br-int上。
实例的虚拟网卡tap设备还是连接到linuxbridge的网桥qbr上,通过veth pair(qvb和qvo)连接到br-int上。
而br-tun上则多了一个vxlan-xxxx的东西,比如用于连接控制节点和计算节点的,制定了VTEP的IP。
此时br-int充当了一个二层交换机,查看flow rule以后可以看到是通过vlan和mac转发数据包的。
而br-tun的flow-rule才是进行真正转发数据包的。Cinder
为运行实例提供稳定持久化的数据块存储服务,如创建卷、删除卷,在实例上挂载和卸载卷。
cinder-api:接收http请求调用cinder-volume
cinder-volume:管理volume服务,管理卷的生命周期
cinder-schedule:通过算法为卷调度一个合适的节点Swift
Zun
openstack租户管理_OpenStack容器服务Zun初探与原理分析
Keystone、Neutron以及Kuryr-libnetwork是运行Zun必备的服务。分别提供了身份认证以及网络的功能支持。
zun-api负责接收api请求进行处理。
zun-compute服务调用container driver进行docker的创建,目前只实现了Docker Driver。
流程步骤
zun/api/controllers/v1/containers.py
进行参数校验,如用户是否具有policy权限,网络、安全组、配额等是否符合。
zun/compute/api.py
先schedule调度一个合适的计算节点,返回host对象,这个功能集成在zun-api里面了。
检查镜像是否存在,远程调用zun-compute的image search方法,其实就是调用了docker search,为了实现快速失败,避免到计算节点才发现错误。
然后远程调用zun-compute进行后续工作
zun/compute/manager.py
创建卷或者挂载硬盘,然后下载镜像,创建端口,调用docker启动容器。
其中调用docker启动容器的操作的代码位于zun/container/docker/driver.py,这个部分其实就是对于Docker SDK for python的一个封装。
如import dockerKuryr-libnetwork
这个项目的目的是将容器网络与neutron进行融合,提供接口南向连接neutron,北向连接容器网络。
开始目的是为了提供Docker与Neutron的连接。将Neutron的网络服务带给Docker。随着容器的发展,容器网络的发展也出现了分歧。主要分为两派,一个是Docker原生的CNM(Container Network Model),另一个是兼容性更好的CNI(Container Network Interface)。Kuryr相应的也出现了两个分支,一个是kuryr-libnetwork(CNM),另一个是kuryr-kubernetes(CNI)。kuryr-libnetwork是运行在Libnetwork框架下的一个plugin,替换了原有的docker engine,成为一个kuryr就是libnetwork的一个remote-driver,现在是docker的推荐remote-driver。
其实实际上kuryr起了一个http服务,23750端口,提供了libnetwork的所有接口,docker找到以后通过这个与kuryr通信。
kuryr借用了neutron的subnetpool,保证了子网间ip的不重复
实现原理
在上面zun调用docker模块创建容器的时候,也会进行网络的配置,就在这里。
先检查docker网络是否存在,不存在就创建,创建的docker网络name就是neutron的uuid,会调用neutron创建一个port,即容器的port是zun创建的,不是kuryr创建的。
然后对于虚拟网卡,会虚拟出一个tap设备,其中容器内部命名空间有一个t_cxxxx的设备,两个通过veth pair连接起来。然后tap设备会连接到qbr的linuxbridge网桥,随后网桥通过qvb和qvo的veth连接到br-int集成网桥。
其实哦在那个接一下kuryr的作用就是把neutron的port绑定在容器上。SDN
软件定义网络,是网络虚拟化的一种实现方式。
主要体现在如下三个方面:- 转发与控制分离:SDN具有转发与控制分离的特点,采用SDN控制器实现网络拓扑的收集、路由的计算、流表的生成及下发、网络的管理与控制等功能;而网络层设备仅负责流量的转发及策略的执行。通过这种方式可使得网络系统的转发面和控制面独立发展,转发面向通用化、简单化发展,成本可逐步降低;控制面可向集中化、统一化发展,具有更强的性能和容量。
- 控制逻辑集中:转发与控制分离之后,使得控制面向集中化发展。控制面的集中化,使得SDN控制器拥有网络的全局静态拓扑,全网的动态转发表信息,全网络的资源利用率,故障状态等。因此,SDN控制器可实现基于网络级别的统一管理、控制和优化,更可依托全局的拓扑的动态转发信息帮助实现快速的故障定位和排除,提高运营效率。
- 网络能力开放化:SDN还有一个重要特征是支持网络能力开放化。通过集中的SDN控制器实现网络资源的统一管理、整合以及虚拟化后,采用规范化的北向接口为上层应用提供按需分配的网络资源及服务,进而实现网络能力开放。这样的方式打破了现有网络对业务封闭的问题,是一种突破性的创新。
OpenFlow
OpenFlow是一种网上通信协议,属于数据链路层,允许控制器直接访问和操作网络设备的转发平面,借此改变数据包的走向。这些设备可以是物理设备也可以是虚拟交换机。
转发平面基于流的方式转发。
网络设备会维护若干个流表,数据流只按照流表进行转发,而流表的生成与维护都是控制器做的事。
这里的流表不仅仅是IP五元组,而是还有这一些关键词和执行动作等。在实际使用中可以根据需要的粒度进行一个限制,比如如果想要粗粒度,只需要设置IP就好了,不需要设置其他的参数比如端口之类的。OF 1.0
一个流表包含一个流表项的集合(包头域)、活动计数器以及一个操作集。
所有流过交换机的数据包都需要进行流表的匹配,如果匹配成功,执行相应的操作,如果没有匹配上,将其转发到控制器,由控制器决定如何处理这个数据包。
这个包头域会根据数据包的信息进行相应的匹配,使用的是12元组- 入口:交换机端口
- 以太网源端口
- 以太网源IP
- 以太网类型:VLAN是0x8100,ARP是0x0806、IP是0x0800
- VLAN ID
- VLAN优先级
- 源IP
- 目的IP
- IP协议:TCP6、UDP7、ICMP1
- IP ToS位
- 源端口
- 目的端口
活动计数器包含有多个计数器,会根据匹配的数据包进行一个更新。
- 流表:流表的匹配数据包数
- 流表项flow:每一项接收的数据包字节数、数据包个数、延迟等
- 端口:每个端口接收到的数据包数、字节数、转发的数据包数、字节数等
- 队列:转发的数据包数
操作集规定了对匹配成功数据包进行什么操作,可以有0到多个操作,如果没有相应操作,丢弃数据包。
一些基本的操作有:- ALL:给除了入口的所有接口发出数据包
- Controller:发给控制器
- INN PORT:往入口发送数据包
- DROP:丢弃
还有一些可选的
- NORMAL:传统交换机的正常转发
- FLOOD:泛洪至除了入口以外的所有出口
- 修改域:这个功能比较厉害,它可以对数据包里面的信息进行修改随后转发,比如可以修改VLAN ID、VLAN优先级、源IP和目的IP、源端口和目的端口等信息
OF 1.3
主要添加了多级流表(流水线),增加了一些多控制器的支持,增加了对数据包处理的动作
一个流表项的组成- 匹配域
- 优先级
- 计数器
- 超时时间
- 指令
- cookie
将原来的动作变更为指令,然后允许数据包在流表之间跳转。
不同于1.0的十二元组,这里其实有四十多个字段,但是一般大多数用不到,主要也就是那么些。
有一个指令是go-to-table:转向另一个流表
如果没有这个,会有以下几个动作- output:指定端口转发出去
- drop:丢弃
- push-tag或者pop-tag:对VLAN等ID进行处理
- setField:识别匹配的字段,并且可以修改
- change-TTL:修改数据包的TTL值
同时 还需要支持table-miss,就是说如果没有匹配成功,进行什么样的动作,转给控制器还是丢弃。
Django
概述
Django是一个开放源代码的web应用框架,使用python写成。本身是基于MVC模型的,实际采用了MTV的框架模式,即模型(Model)、模(Templates)板和视图(Views)。其中:
- 模型:数据存取曾,处理所有与数据有关的事务,比如如何存取数据、验证有效性等
- 模板:表现层,比如如何在页面或者其他类型文档中显示
- 视图:业务逻辑层,处理数据存储以及调用模板的逻辑
简单流程:
用户通过浏览器向我们的服务器发起一个请求(request),这个请求会去访问视图函数:
a.如果不涉及到数据调用,那么这个时候视图函数直接返回一个模板也就是一个网页给用户。
b.如果涉及到数据调用,那么视图函数调用模型,模型去数据库查找数据,然后逐级返回。
视图函数把返回的数据填充到模板中空格中,最后返回网页给用户。Django的主要目的是简单快捷的开发数据驱动的网站,强调代码复用,多个组件可以很方便的以插件形式服务与整个框架。
有以下几个特点:- 对象关系映射(ORM):通过定义映射类构建数据结构,并且将模型与数据库连接起来,使用ORM框架内置的接口即可方便快捷操作数据库
- URL设计:可以设计匹配任意地URL.(支持正则表达式)
- 模板系统:提供可扩展的模板,模板还可以继承
- Auth认真那个系统,提供有一个后台管理界面,可以进行用户认证以权限认证
- 国际化:内置国际化,开发出多语言的网站
- Cache系统:完善的缓存系统:支持多种缓存方式
- 表单处理:生成各种表单,还可以对数据进行验证
MVC和MTV
MVC:
核心思想是解耦- model:对数据库的底层封装
- view:向用户展示结果
- controller:核心,处理请求、获取数据、返回结果

MVT:- model:与数据库进行交互
- views:核心,接受请求,获取处理数据,返回结果
- template:呈现内容到浏览器上
views里处理业务逻辑比如登录验证、数据处理等
model里面不需要编写一句sql,ORM会自动转为sql去执行。
数据库里每一行数据就是一个对象,每一个表是一个集合,python用列表表示这个集合
template呈现页面,用css和js渲染html等
还需要一个 URL 分发器,它的作用是将一个个 URL 的页面请求分发给不同的 View 处理,View 再调用相应的 Model 和 Template,MTV 的响应模式如下所示
和Flask Tornado的区别
Django提供了更多的组件支持,让开发变得更加方便。
比如- ORM对象关系映射,对数据库进行操作,不需要编写sql语句
- Admin管理后台
- 模板
- 表单
- 认证权限
- 缓存
- session机制
Flask轻量级轻在它本身是一个内核,其他功能都需要扩展实现。比如可以引入其他模块实现ORM,也没有默认数据库,但是可以自行配置使用mysq或者nosql,性能比Django好。依赖于Werkzurg WSGI路由模块和jinja2模板。
对于路由的匹配- Django使用过urls.py种对路由进行字符串的匹配,选择匹配的views.py函数进行业务处理
- Flask则是使用装饰器给一个函数配置一个路由,然后进行处理
Tornado
功能少而精,非阻塞式异步设计方式。- iostream:对非阻塞式socket进行封装
- ioloop:对IO多路复用进行封装,实现单例
Tornado是一个使用python开发的全栈式的web框架和一部网络库,使用非阻塞式IO,可以处理数以万计的开放链接,常用于long polling、web sockets和其他需要维护长连接应用的选择。
主要分为四个部分- Web框架(RequestHandler,用于创建Web的基类支持各种类)
- 实现HTTP的客户端和服务器端(HTTPServer、AsyncHTTPClient)
- 异步网络库(IOLoop、IOStream)
- 协程库(tornado.gen),使得异步调用代码可以更好编写
tornado的性能比django和flask好就是因为其底层io处理机制是根本不同。
- tornado、gevent、syncio、aiohttp:事件循环+协程
- django、flask:
Django请求生命周期
浏览器输入网址,发送请求到服务器
匹配路由
url经过uWSGI->WSGI,然后经过中间件的处理,在urls.py路由映射中找到一个匹配的路由,从上到下依次匹配,匹配一个就可以停了
视图处理
匹配到url以后,跳转到对应的视图函数进行相应的业务处理,比如操作数据库等
返回响应
先经过中间件对返回的数据再进行处理,然后返回相应的页面文件,由浏览器渲染以后显示给用户,同时将模板内容填充到html空白处。一些额外的
在匹配路由的时候,有两种方式,是CBV、FBV- FBV(function base views):一个url对应一个视图函数
- CBV(class base views):一个url对应一个类,会根据请求的方法调用对应的函数
CBV,url匹配成功后会自动去找dispatch方法,然后Django会通过dispatch反射的方式找到类中对应的方法并执行,类方法执行完成以后,返回的结果回传给dispatch()
对应类的话如下所示#urls.py urlpatterns = [ url(r'^fbv/',views.fbv), url(r'^cbv/',views.CBV.as_view()), ] #views.py form django.views import Views class CBV(Views): def get(self,request): return render(request,'cbv/xx/html',context) def post(self,request): return HttpResponse('...')常见的web应用程序
框架组件
- 序列化组件:进行序列化并且对数据格式进行验证
- 路由组件:对请求进行路由分发
- 视图组件:对请求进行业务处理
- 认证组件:写一个类并注册到认证类(authentication_classes),在类的的authticate方法中编写认证逻
- 权限组件:写一个类并注册到权限类(permission_classes),在类的的has_permission方法中编写认证逻辑。
- 频率:写一个类并注册到频率类(throttle_classes),在类的的allow_request/wait 方法中编写认证逻辑
- 解释器:选择对数据解析的类,在解析器类中注册(parser_classes)
- 渲染器:定义数据如何渲染到到页面上,在渲染器类中注册(renderer_classes)
- 分页:对获取到的数据进行分页处理, pagination_class
- 版本:用来控制不同版本客户端的不同行为
RestFramework
面向资源是REST最明显的特征,资源是一种看待服务器的方式,将服务器看作是由很多离散的资源组成。每个资源是服务器上一个可命名的抽象概念。因为资源是一个抽象的概念,所以它不仅仅能代表服务器文件系统中的一个文件、数据库中的一张表等等具体的东西,可以将资源设计的要多抽象有多抽象,只要想象力允许而且客户端应用开发者能够理解。
可以使用URI统一资源标识符标记一个服务器的资源,通过不同的http方法对资源进行相应的操作。这里的资源可以是一个文本文件、视频、图片等。
符合REST架构设计的API就是restful api。继承
APIView
@api_view([‘POST’],[‘GET’])
在这个类中,传入的参数是rest framework的request实例,不是django的httprequest。
可以返回rest framework的resonse,而不是HttpResponse。
传入的请求可以进行一些认证
可以指定解析器Parser对传入的数据进行解析,如JSON、Form等解析。一些功能模块
认证、权限和频率
dispatch()方法中进行一个判定。
认证和权限需要检查request.user和request.auth是否合法,是否允许请求。缓存机制
网站访问量过大的时候,响应速度可能会大大降低,出现卡死的状况,可以使用缓存解决这类问题。
缓存是将一个请求的响应内容保存到内存、数据库、文件或者高速缓存系统(memcached),如果接下来一段时间再次来同一个请求,就不需要执行相应过程,只需要读取内存或者高速缓存系统就可以了。
Django提供5种缓存方式:- Memcached:一个高性能的分布式内存对象缓存系统,用于动态网站,减轻数据库负载。适合在内存中缓存数据和对象减少读取数据库的次数,适合超大型网站
- 数据库缓存:将缓存的信息存储在网站数据库的缓存表中,适合中型网站
- 文件系统缓存:缓存的信息以文本文件的格式保存下来,适合中小型网站
- 本地内存缓存:默认保存缓存的方式,缓存存放于内存中,仅用于测试
- 虚拟缓存:Django内置的虚拟缓存,实际上只是提供一个接口,不实际缓存数据,用于测试
WSGI,uwsgi,uWSGI
WSGI
是python定义实现的一个web服务器和web应用程序之间交互的一个接口,是一种规范,描述定义了服务器和应用程序之间通信的规范。
WSGI包括server和applicatioon两部分。
其中server负责接收客户端请求,把request转发给application,接收application的response返回给客户端。
WSGI其实是一种server和application解耦的规范,有多个实现server的服务器,也有多个可以实现WSGI application的框架,可以自由组合。比如uWSGI、Gunicorn就是实现了WSGI server,而Django和Flask则实现了WSGI application的框架,可以自由组合,比如uWSGI+Django。WSGI除了监听端口进行解析http,还有流量转发和管理application进程。一般WSGI内置的WSGI server都是单进程,一次只能处理一个请求,而通用的比如gunicorn或者uwsgi都是pre fork模型,会有一个master进行监听,启动多个slave(一个slave就是一个WSGI application)处理请求。
uwsgi
也是一种协议,用于定义传输信息的类型,可以和nginx等代理服务器通信
uWSGI
是一个web服务器,实现了WSGI协议、uwsgi和HTTP协议,把接收到的HTTP协议转为支持的网络协议,比如可以转为WSGI协议,然后python可以直接使用。比如可以使用nginx处理静态内容,使用uWSGI处理动态内容。
对于Django和Flask其实自己本身带有一个简单的WSGI server,一般用于服务器调试,生产环境下建议使用其他的,比如manage.py runserver就是启动一个WSGI,只用于本地开发,生产环境建议nginx+uwsgi+django请求的生命周期
- wsgi接收请求:发给后端框架(flask或者django等)
- 中间件处理:对请求进行校验或者进一步处理(如csrf、request.session)
- 路由匹配:根据用户请求的url匹配不同的视图函数
- 视图函数:在views.py里面处理业务逻辑
- 中间件:对响应的数据进行处理
- wsgi:返回响应给浏览器
中间件的作用和应用场景
介于request和response中间对数据处理的一个流程,用于全局范围改变django的输入和输出,中间件就是在视图函数执行之前或者之后可以执行额外的操作。
比如- csrf保护,默认开启,会检查请求的csrf token是否匹配
- 通过中间件可以判断用户请求是否登陆等,进行身份验证功能
- 可以检查用户是否处于请求白名单或者黑名单等
中间件的五个方法:
process_request:请求进来,进行认证等process_view:路由匹配后得到视图函数process_exception:异常的时候执行process_template_responseprocess:渲染模板的时候执行process_response:请求有响应的时候执行
这五个方法分别大概以下功能
中间件process_request(request):收到request以后,按照settings.py文件中的中间件顺序依次执行,如果返回None,则继续,如果返回HttpResponse,就返回不继续了,也就是报错了process_view(request, view_func, view_args, view_kwargs):执行完上一步的方法以后,在url里面找到对应的视图函数,然后获取到相应参数,在执行视图函数之前执行这一步。如果返回为None,则继续执行这个方法剩下的操作,如果返回HttpResponse,不执行这个方法和视图函数,继续后面的函数process_exception(request, exception):如果执行视图函数出错,按照settings.py中的中间件顺序,倒序执行这个方法,如果返回None,就继续上一个方法的process_exception方法,如果返回HttpResponse,则不会被调用。也就是说,如果没有响应,就说明报错,倒序一级一级报错,如果有返回值说明还是正常的,就继续往下执行后面两个函数process_template_response(request, response):response是视图或者某一中间件的返回,只有response实现了render才能执行,所有中间件的这个函数执行完了,调用render()方法process_response(request, response):在视图函数执行完以后执行,必须有响应HttpResponse
默认的中间件
有几个默认配置的中间件,主要功能如下
django.middleware.security.SecurityMiddleware:防止xss脚本过滤的安全改进django.contrib.sessions.middleware.SessionMiddleware:开始session会话支持,可以使用session,不开启就不能session保存数据django.contrib.messages.middleware.MessageMiddleware:提供cookie的功能支持django.middleware.common.CommonMiddleware:用来重写URL。如果APPEND_SLASH为True,那么URL末尾没有斜杠或者没有找到对应匹配的时候,会自动添加末尾斜杠;PREPEND_WWW为True则会将没有www.开头的URL重定向到同样的www.开头的URL路由django.middleware.csrf.CsrfViewMiddleware:跨站请求伪造就不说了django.contrib.auth.middleware.AuthenticationMiddleware:收到request后,可以对user对象添加相应的HttpRequest属性,表示当前用户身份呢
django中的csrf实现机制
- django第一次接收到客户端的请求时,随机生成一个随机数,保存在session中,同时放在cookie里面返回给客户端
- 在前端需要发送请求到后端时,需要将token加入到请求数据或者头部数据中
- 后端会校验传来的token和session里面的token是否一致
基于django的ajax发送请求给后端如何携带token
CSRF跨站请求伪造,是一种对网站的恶意利用、窃取网站用户信息制造恶意请求。
为了防护这类攻击,在用户提交表单的时候,表单中会自动加入一个叫csrfmiddlewaretoken的隐藏控件,后台也保存有这个控件的值,当请求到达后端时,服务器会检查这个值,如果匹配则进行后续处理,否则不处理。
原理:- 用户访问网页的时候,django会在表单中添加一个叫
csrfmiddlewaretoken的隐藏控件,并设置一个值,然后同时保存在后台,这是一个随机生成的 - 当用户提交表单的时候,服务器会对比用户表单里的这个token和自己的token,判断是否合法
- 如果请求是从其他地方发过来的,那他不会知道这个token,因此后台会校验失败,请求就不会被处理
但是XSRF防护一般只适用于POST请求,不能防护GET,因为GET一般是制度性是访问网页资源,不会涉及资源的更新和修改等操作。
在前端的form表单中添加{% csrf_token %}即可- 使用模板填充
data:{ csrfmiddlewaretoken:'{{csrf_token}}' }- 在form中设置一个隐藏控件,如标签,填充内容为token,然后获取控件的值
- 从cookie中获取token,放入头部。
headers:{ “X-CSRFtoken”.cookie(“csrftoken”)}
如果不想使用csrf防护,前端取消这个模板语法,后端在对应视图函数签名添加一个装饰器
@csrf_execpt即可。如果只删除前者不修改后者,访问会报错403未授权。
如果需要对整个网站取消CSRF,settings.py里面删除这个中间件即可。ajax请求的csrf解决方法
在POST请求中设置请求参数
csrfmiddlewaretoken,否则会认为是恶意请求,需要获取这个控件的值。
如下function submitForm(){ var csrf=$('input[name="csrfmiddlewaretoken"]').val(); ... $.ajax({ ... data:{ 'csrfmiddlewaretoken':csrf, ... } ... }) }为什么不使用django的runserver部署(runserver和uWSGI的区别)
- runserver方法是调试 Django 时经常用到的运行方式,它使用Django自带的
WSGI Server 运行,主要在测试和开发中使用,并且 runserver 开启的方式也是单进程 。 - uWSGI是一个Web服务器,它实现了WSGI协议、uwsgi、http 等协议。注意uwsgi是一种通信协议,而uWSGI是实现uwsgi协议和WSGI协议的 Web 服务器。uWSGI具有超快的性能、低内存占用和多app管理等优点,并且搭配着Nginx就是一个生产环境了,能够将用户访问请求与应用 app 隔离开,实现真正的部署 。相比来讲,支持的并发量更高,方便管理多进程,发挥多核的优势,提升性能。
Kubernetes
k8s是为容器而生的一个可以指容器的编排管理工具,主要应用于云原生领域。
主要提供了以下几种功能:- 服务发现与调度
- 负载均衡
- 服务自愈
- 服务弹性扩容
- 横向扩容
- 存储卷挂载
集群主要由Master节点和Node节点组成。
Master节点是集群控制节点,接收控制命令进行具体执行,主要包括kube-controller-manager和kube-scheduler和etcd,前者负责管理所有资源对象、维护集群状态(故障检测和自动扩展等);后者负责资源调度,按照相应策略将Pod调度到对应的机器上,主要包括kube-proxy代理pod网络定期从etcd获取service信息相应执行、kubelet作为agent接受分配pods任务和管理容器定期获取容器数据传给kube-apiserver;etcd则负责保存整个集群的状态。
是自动化容器操作的开源平台,主要包括:部署、调度和节点集群间扩展
具体功能:- 自动化容器部署和复制
- 实时弹性收缩容器规模
- 容器编排成组并提供负载均衡
- 调度,决定容器在哪个节点运行
什么是容器编排
可以使用某种工具配置完成一组容器以及相应的资源如网络、CPU等资源的定义、配置、创建、删除等管理工作。服务配置
Master节点部署- controller manager:负责容器编排,可以通过restful api给api server发起请求,获取集群内所有对象的信息,当检测到一些故障的时候可以进行相应的干预。Controller一般包括:Namespace Controller、Node Controller、Service Controller、Token Controller等
- api server:对外提供api,接受请求
- scheduler:接收来自api-server发来的请求,准备床创建Pod任务,之后会检索出符合这个Pod的Node节点,中选择一个合适的进行调度创建
- etcd:k8s没有使用单独的数据库,而是使用etcd作为数据存储。因为k8s中数据是随时会变化的,比如用户提交了一个任务、创建新Node、节点宕机等都需要对数据库进行操作,然后同时新的变化也需要让各个服务能够感知到。etcd的其中一个特性就是可以调用api监听到相应的数据i需改情况,有修改etcd会自动推送到客户端,有什么通知scheduler和controller manager只需要把消息放在etcd里面就行了不需要挨个通知
Node节点部署
- kubelet:相当于agent,负责维护容器的生命周期、卷和网络的管理。通过api-server监听scheduler是否有pod绑定事件,有的话就从etcd获取相应信息创建Pod。同时进行Pod的监视,定期将状态或发生的事件告知给其他各个组件
- kube-proxy:负责微Service提供集群内的服务发现和负载均衡。是一个守护进程,以Watcher的方式不断监控Pod,如果有什么变动比如IP变了,就会修改相应的规则策略,比如IP变了会修改相应的iptables。之后负载均衡的时候就会根据proxy制定下发的策略进行实现了。
- Networking
- Volume Plugin
- Container Runtime:负责运行容器的软件,支持多个Docker、Container等任何实现接口的
Pod
Pod是k8s最基本的操作单元,包含一个或多个相关的容器,是最小部署单元,其实代表一个集群中运行的一个进程。
一个Pod可以被一个容器化的环境看成应用层的逻辑宿主机,一个Pod内的多个容器通常紧密耦合,在Node上被创建、启动或者销毁,每个Pod还运行一个特殊的Volume挂载卷,使得容器间数据通信比较方便。
同一个Pod的使用localhost就可以通信,共享一下五种资源:- 进程号命名空间:Pod中不同应用程序可以看到其他应用程序的进程ID
- 网络命名空间:多个容器访问同一个IP和端口范围,每个Pod共享一个IP
- UTS命名空间:共享一个主机名。使用Pod名作为主机名
- 进程间通信命名空间:可以使用SystemV IC和POSIX消息队列通信
- Volume:共享存储卷,各个容器可以访问
Pod控制器
kubernetes的控制器
称为工作负载,用于实现管理Pod的中间层,确保Pod的运行时符合预期的,以及出现故障后应该采取什么策略措施,比如重启或者重建。
Controller在集群上运行和管理各个Pod
Pod控制器实现Pod的运维,伸缩等
控制器类型- ReplicaSet(RS):保证一定数量的Pod运行,并且监控Pod的状态,当出现故障的时候,会进行重启,如果重启失败则会重新创建。(也就是自愈机制)
- Deployment:工作在ReplicaSet之上,管理无状态应用,是最好用的控制器,提供有滚动更新和回滚的功
- DaemonSet:确保集群中的每一个节点只运行特定的Pod副本,常用于实现系统级后台任务;服务是无特性的,必须要守护进程
- StatefulSet:管理有应用
- Job:一旦完成任务就会立刻退出,不需要重启或者中间(一次性)
- CronJob:周期任务,不需要手动执行,自动定期运行
Replica Set和Replica Controller的区别
功能都差不多,都是保证一定数量的Pod的运行,不同之处在于两者对于Pods的复制策略不同。
前者使用基于集合的选择器,后者使用基于权限的选择器。
后者允许通过标签键值进行选择。
Set是更好的,可以对多个标签进行选择匹配云控制器的理解
最初目的是使得云服务商的代码和k8s的核心代码独立解耦,使得云控制器可以和k8s的组件(controller manager或者api等)一起使用,也可以作为插件在k8s中使用。其设计是基于插件机制的,所以很容易和k8s集成- 节点控制器:从云服务提供商获取到集群中运行的节点信息,并且对节点初始化。
-
- 以云服务特定区域/低于标签初始化
-
- 以云服务特定的实例详细信息(如类型和规格等)初始化
-
- 获取节点的网络地址和hostname
-
- 检查状态,看节点是否还存在于云服务中,如果不存在在k8s中也将其删除
- 卷控制器:在创建卷比如AWS的卷的时候,添加相应的标签,用户不需要手动添加标签了。因为只有处于同一个区域地区才有用,用标签保证吧
- 路由控制器:负责在云服务中配置相应的路由,使得k8s中的容器可以相互之间进行通信,只适用于谷歌计算引擎集群
- 服务控制器:监听服务的创建、删除和修改事件。比如说基于当前的k8s状态配置云负载均衡服务,可以保证服务后端始终是最新状态
支持四种服务类型
- Cluster IP(集群IP):启动多个集群内的Pod通信服务,相当于是一个内部通信,可以进行内部调试之类的
- Node Port(节点端口):将主机上的随机端口流量准发到路由器的随机端口去。有些缺点:外部不能用locahhost、每次Pod启动IP都会变,无法设置DNS
- LoadBalancer(负载均衡):
- Ingress:是一个规则集合,作为集群的入口点,主要负责将入站链接配置为可达的URL,负载平衡流量以及基于名称的对外提供虚拟服务器功能。其实像一个API服务,对外提供API进行调用
什么是Headless Service
又叫无头服务,是一种特殊的服务类型。
ClusterIP是None,运行时不会给分配IP,可以通过查询Server的DNS获得所有Server和Pod的地址信息,可以根据自己的需求决定使用哪个Server
一般结合StatefulSet来部署有状态的应用,比如kafka集群,mysql集群,zk集群等
服务发现
k8s使用两种方式进行服务发现:- 环境变量:创建一个Pod以后,kubelet会在Pod中注入集群内所有Service相关环境变量,要求Service先于Pod创建
- DNS:通过claster add-on方式创建kubeDNS对集群Service进行服务发现
CNI
Container Network Interface,容器网络接口式Linux容器网络配置的一组标准和库,可以根据这些开发自己的容器网络插件。只专注于容器网络连接和容器销毁时的资源释放,支持大量不同的网络模式。
kuryr-libnetwork
四层、七层负载均衡- 二层负载均衡:基于MAC地址
- 三层负载均衡:基于IP地址
- 四层负载均衡:基于IP+端口号
- 七层负载均衡:基于URL等应用层信息
网络模型
每个Pod都有一个独立IP,不管是否运行在一个Node上的容器都可以通过IP直接访问
由docker0实际分配IP;内部看到的IP与端口和外部一致;同一个Pod内不同容器共享网络可以通过localhost通信,相当于一个虚拟机中的多个进程。Docker
一些参考
Docker 核心技术与实现原理
Docker进阶之Cgroup介绍
CSDN的云原生入门技能树/容器(docker)/安装dockerNameSpace
这个在linux知识点章节有
当一个容器运行时,会创建一系列namespace,使用命名空间将容器间进行隔离。- IPC命名空间(进程间通信):将消息队列分离出来
- 进程命名空间:命名空间内的虚拟PID可能会和外面的pid重复,会映射到哇面的另一个pid
- 网络命名空间:用来隔离网络资源,可以虚拟出网卡,而且后台进程可以运行在不同的命名空间的相同端口
- 挂载命名空间:可以将挂载点与系统分离
- UTS命名空间:独立出主机名和网络信息服务
- 用户命名空间:不同空间可以存在相同ID的用户
命名空间的缺点:
隔离不彻底,因为还是共享宿主机的操作系统和内核,有可能通过容器的某些操作可以直接影响到宿主机(给应用暴露的攻击面太大)
有的资源没法进行命名空间隔离,比如修改容器的时间宿主机的时间也会修改。Cgroups
可以对程序使用的资源进行限制。可以限制CPU、内存、磁盘读写速率、网络带宽等系统资源。Linux使用文件系统来实现Cgroups,cgroup是内核提供的分组化管理的功能和接口。
有如下几个特点:- API以伪文件系统的方式实现,用户态程序可以通过操作文件实现Cgroups的组织管理
- 单元细粒度可以精确到线程级别,可以创建销毁Cgroup,实现资源再分配和管理
- 所有的资源管理以子系统的方式实现,接口统一
- 子任务刚创建的时候和父任务的Cgroups一致
cgroups是内核附加在程序上的一系列钩子,通过程序运行时对资源的调度触发相应的钩子以达到资源追踪和限制的目的。
提供以下几个功能:- 资源限制,对任务使用的资源进行限制,比如限制了内存以后,超过内存限制会报错OOM
- 优先级分配,通过分配CPU时间片和IO带宽大小,相当于控制了任务运行优先级。
- 资源统计:可以统计资源使用情况,比如CPU使用时间,内存使用量
- 任务控制:可以对任务挂起、恢复
有几个概念:
- task:任务,指一个进程或者线程
- cgroup:控制组,按照某种资源控制情况划分的任务组,包含有一个或者多个子系统,一个任务可以加入某个cgroup,也可以从一个cgroup迁移到另一个cgroup
- subsystem(子系统):每个子系统就是一个资源控制器,比如CPU子系统控制CPU使用的时间
- hierarchy(层级):层级由一系列cgroup以树状结构排列,每层绑定对应子系统实现资源控制
有几个规则关系:
- 同一个层级可以附加多个子系统,比如一个cgroup可以有CPU和Memory子系统
- 一个子系统可以附加到多个层级,当且仅当目标层级只有唯一一个子系统,比如如果B层级有内存子系统,不能附加CPU子系统了
- 每次新建一个层级的时候,所有任务默认加入到这个初始cgroup
- frok、clone自身创建的子任务默认与原任务在一个cgroup里,子任务允许被移动到不同的cgroups
子系统
有如下- blkio:为块设备设置输入、输出限制,比如物理驱动设备(磁盘、USB等)
- cpu:设置CPU使用时间,用于调度程序
- cpuset:多处理器系统可以为任务分配相应的处理器和内存
- cpuset:对cpu资源的使用情况生成报告
- memory:对任务的任务使用量进行限制,同时生成内存使用情况的报告
- devices:开启或者管理cgroup里任务对设备的访问
- freezer:挂起或者恢复cgroup的任务
- perf_event:使得cgroup里的任务可以进行性能测试
- net_cls:标记网络数据包,允许流量控制程序识别cgroup里生成的数据包
比如对于cpu子系统,
/sys/fs/cgroup/cpu里面有一些控制组的文件,创建一个控制组文件夹以后,会出现一些文件。
限制一个指定进程的cpu使用配额
先添加进程PID,然后添加具体配置echo 18828 >> /sys/fs/cgroup/cpu/cg1/tasks //设置使用20%cpu echo 20000 >> /sys/fs/cgroup/cpu/cg1/cpu.cfs_quato_us在创建容器时,daemon会在单独挂载的子系统控制目录下创建一个对应的docker控制组,然后再创建一个容器控制组名为Docker ID,容器的所有进程好都会写在这个的tasks里面,在对应的控制文件里写相应的资源配额信息。
对于内存如果超过cgroup最大限制以后,如果设置了OOM Control(内存超限控制),进程就会收到OOM信号然后结束,否则会一直挂起,直到其他进程释放对应的内存资源。
cgroup.procs可以对线程进行配置,写入线程组中的第一个进程的PID,也就是把相关线程都加到cgroup里面驱动
docker的daemon进程通过接收相应的API请求,然后将去转为使用相应的系统调用,从而创建和管理容器。docker将这些系统调用抽象为了一些操作接口方便调用,包括:容器执行驱动、volume存储驱动以及镜像存储驱动三种。
execdriver
对namesapce、cgroups等进行了二次封装,是默认的libcontainer库
volumedriver
负责volume的增删改查,屏蔽不同驱动带来的差异,为上层提供一个统一的接口调用。
graphdriver
和镜像有关,维护一个一组与镜像曾对应的目录,以及相应的元数据,用户对镜像的操作会对应位对这些目录文件以及元数据的增删改查,屏蔽不同文件存储实现带来的差异。docker daemon的主要启动步骤如下三步
- 启动API Server,工作在宿主机的HOST上
- 使用NewDaemon方法创建daemon对象,保存信息和处理业务逻辑
- 将API Server和daemon绑定起来,接受处理client的请求
启动一个容器的步骤
从client 到 daemon,
docker run举例- docker run进入client模式
- 初始化一个client,反射找到cmdRun方法,解析参数,然后发送POST请求创建并启动容器
- Daemon解析用户提交的这个POST表单信息,创建一个container对象,包含有Name、Path、ID、Created时间等,信息会返回给client,然后client发送启动命令
- API Server接收到指令以后,调用daemon启动。创建相应的容器。
- 最后daemon向execdriver发送指令创建容器,信息包括:容器给i所需的所有配置集合、pipes将容器的输入输出重定向到daemon以及一个回调方法
最后创建容器的时候会使用到libcontainer。
在准备好配置文件以后,会创建一个container对象,这里面存储的是配置信息的对象,然后才是有Container逻辑容器对象,libcontainer会根据信息创建相应的namespace,以及cgroups,然后创建docker。基础
什么是Docker
Docker是一个容器化平台,以容器的形式将应用程序和其环境依赖打包,可以在任何Docker环境中无缝衔接运行
Docker与虚拟机的不同
Docker不是虚拟化,依赖于实际实现基于容器的虚拟话或者操作系统级虚拟化的其他工具,最初使用LXC驱动,后来移动到libcontainer重命名为runc。
专注于应用程序容器内自动部署应用程序,应用程序指打包和运行一个应用程序,操作系统容器则设计为运行多个进程,如虚拟机。
特点:- 不需要引导操作系统内核,启动创建非常快,不到1s
- 基于容器的虚拟化对主机性能开销增加很小甚至没有,具有接近本机的性能
- 对于基于容器的虚拟化不需要其他软件就可以运行
- 主机所有容器共享主机的调度,节约资源成本
- 镜像体积很小,适合分发
资源管理通过cgroup实现,不允许容器消耗比cgroup规定还多的资源
虚拟机底层是需要使用hypervisor来模拟硬件虚拟化的,可以虚拟出一个操作系统所需的各种硬件资源比如cpu、ram、disk,在其上安装目标操作系统。
Docker和普通进程的区别
当一个程序代码被编译为二进制文件,然后这个文件被加载到内存然后得到cpu的使用权时,这个程序就变成了一个正在运行的进程,会去对寄存器进行操作,对堆栈进行操作以实现相应功能。
而容器则是通过约束和修改进程的动态表现,给其创造一个边界。cgroups主要用来进行约束,而namespace则主要用来创造边界镜像
什么是Docker镜像和Docker容器
镜像就是容器的源代码,用于创建容器。
Docker容器包含了应用程序和其所需的以来,作为操作系统的一个独立进程运行的。
镜像保存在/var/lib/docker/Docker镜像分层
是基于UnionFs(联合文件系统),这是一种分层的、轻量级的而且高性能的文件系统,支持对文件系统的修改作为一次提交来一层一层提交,而且可以把不同目录挂载到同一个虚拟文件系统下。
实际上一次会加载多个文件系统,但是使用上只能看到一个文件系统,联合加载会把每层文件系统叠加起来,最终的文件系统就会包含所有的底层文件和目录。
实质上就是一层一层的文件系统。所有docker都初始于一个基础镜像层,增加或者修改内容的时候,会在这个基础上新增一层。
举个例子
如果需要基于ubuntu18.04配置新镜像,第一层就是ubuntu18.04
我们需要安装python,第二层就是python包
我们需要安装一个安全补丁,这个补丁就是第三层
Docker镜像是只读的,在启动容器的时候,会把一个可写层加到镜像顶部,就是容器层,容器层。下面都是镜像层。bootfs
boot file system。有一个bootloader和kernel,loader负责加载kernel,linux刚系统的时候就会加载bootfs,docker的底层就是bootfs,bootfs加载完成以后,内核就在内存里了,内存的使用权就由bootfs交给内核了,然后就可以卸载bootfs了。
rootfs,root file system在bootfs之上,包含有linux中的/dev、/proc、/bin、/etc等标准目录和文件,这个其实就是各种linux发行版。
对于精简os,rootfs只需要包含最基本的命令、工具和程序库,因为可以直接使用底层kernel,所以只需要rootfs,而对于不同的发行版,bootfs都是差不多的,所以可以公用容器分层、写时复制(copy-on-write)
容器和镜像的区别其实就是容器会在最顶层有一个可写层,对于容器的所有写操作都会记录在这里面,容器删除的话这个可写层就删除了。
每个容器都有着自己的可写层,所以多个容器可以共享一个镜像
对于多个镜像来说,镜像的分层会出现公用的情况,所以不能单纯看docker images列出来的大小。
多个容器之间可以共享镜像,在启动容器的时候不必单独复制一份,而是把所有镜像层以只读的形式挂载到一个挂载点上,在最上层加一个可读写的容器层,在没有更改的时候所有容器共享一份数据,只有对文件系统进行修改的时候,会把相应的内容写到可读写层里,并且隐藏只读层里的老版本文件,用心的覆盖,减少了镜像对磁盘空间的占用和容器的启动时间。DockerFile常见指令
Dockerfile 是一个用来构建镜像的文本文件,文本内容包含了一条条构建镜像所需的指令和说明。
FROM:指定基础镜像,基于什么镜像LABEL:指定镜像的标签RUN:运行指定命令CMD:启动容器的时候执行什么命令,类似自启动,如果有多个指令,只执行最后一条ENTRYPOINT:类似于CMD指令,但是不会被覆盖掉,
build
docker build -t {name}:{tag} .
最后的点就表示上下文路径。
docker在构造的时候会使用到本机文件,比如复制进去,他会在这个上下文路径中去寻找,把里面的文件都打包进去,不写就默认Dockerfile所在的目录。步骤时:
- 发送请求个Server端,然后创建临时目录读取Dockerfile
- 根据解析的结果遍历命令,将其分发给不同模块进行执行。
- parser会给每个指令创建一个临时容器,在临时容器中执行当前指令,然后使用commit生成一个镜像层
- 所有指令对应的层的集合,就是build的而结果。最后一次commit生成的镜像ID就是最后的镜像ID
Dockerfile的COPY和ADD
COPY指的是从上下文目录中复制文件到容器里的指定路径。
ADD也是复制文件。
COPY的SRC只能是本地文件。
而且ADD会自动解压一些格式的文件gzip等,不解压的时候tar就不能复制进去,会使得构建失败。
ADD还可以给容器里添加远程文件。但是建议用curl或者wget命令下载文件,因为ADD的话会给镜像加一层,导致体积变大臃肿。Docker容器的状态
运行、退出、已暂停、重新启动
网络
docker的网络部分已经被独立为libnetwork了。使用的CNM(容器网络芈姓)提供了多种网络接口可以使用。
daemon通过调用libnetwork对外提供的API完成网络的创建和管理,libcontainer则使用CNM。libcontainer里面提供了五种网络驱动可以使用,有三个核心组件。- 沙盒:包含一个容器网络栈信息,可以对容器接口、路由和DNS等进行管理,具体实现可以是namespace
- 端点:一个端点可以加入一个沙盒和一个网络,具体实现有veth pair、ovs内部端口等
- 网络:是一组可以互联互通的端点,具体实现可以是lunexbridge、vlan,一个网络可以有多个端点
驱动:
- bridge:默认配置,会将创建出来的容器连接到docker0网桥上,和外界通信使用NAT,复杂场景下使用会有不少限制
- host:不会为容器创建网络协议栈,不会有独立的namespace,处于宿主机的网络环境中,共用宿主机的namesapace,如IP、网卡端口等信息。较好的解决了与外界通信的地址转换问题,但是降低了容器和宿主机或者容器之间的网络隔离问题,网络资源的使用可能会出现竞争冲突。
- overlay:vxlan比如大型云计算虚拟化环境里的SDN Controller模式
- remote:这个欸有实现真正的网络服务,而是会调用用户所提供的网络驱动插件,比如Kuryr-libnetwork。根据libnetwork提供的标准实现相应的接口就可以找daemon进行注册使用
- null:容器有自己的namespace,只有lo网卡,需要用户自己配置网卡IP等信息,优点时配置使用非常自由,缺点就是 不配置不能使用,使用要求高。
docker0本质上就是网桥,而且这里的网桥概念可以相当于时交换机,可以为连接在其上的设备进行数据帧的转发,容器的网卡eth0通过veth连接到docker0网桥上,不需要配置IP地址就可以进行数据帧的转发。
Docker的网络类型
有4种类型,bridge、host、container以及none
bridge:默认情况创建容器是使用网桥bridge去连接,docker0,容器之间通过网桥通信。对外通信的话网桥会与宿主机进行一个IP转换。这里的虚拟连接也是使用类似与虚拟网线的那样,就虚拟机里面的eth0连接到网桥对应的veth。如果需要外部访问进来,得通过端口映射,然后使用宿主机的端口和这个映射的端口进行访问
host:会默认使用宿主机的网络,不会有自己的命名空间虚拟机网卡之类的,在网络上是没办法隔离的。使用了host就只能指定端口了,访问进来的话用宿主机的IP和这个映射的端口
container:指定新创建的容器和已有的容器共享namespace,同样不会自己创建网卡和IP地址,和这个特定容器一起共享,进程间通过lo通信。
none:会创建一个命名空间 ,但是ip、虚拟网卡之类的都得自己配置,很不好用不方便。但是隔离安全性非常好docker常用命令
docker images:查看镜像docker rm / rmi:删除容器/镜像docker pull / push:拉取/上传镜像docker ps -a:列出所有镜像,不带参数只列出开机镜像docker cp {path} {docker_id}:{docker_path}:复制文件到指定容器的路径下,也可以返回来复制出文件docker run -d --name container cirros -p 5000:5050:启动容器
面经
OpenStack
一些命令行
- 命令启动虚拟机:
openstack server create --flaver {name} --nic net-id={network-id} --security-group {id} {name}
命令上传下载镜像:opensatck image create --disk-format qcow2 --container-format bare --public --file {local-path} {name}
glance image-download --file {id} {local-path} - 修改实例状态为活动状态:比如有时候实例会卡住,比如删除的时候因为某些故障卡住了,处于
deleting状态一直卡住,这个操作可以使其变为活动状态,然后他大概会进入error,然后就可以正常删除了。nova restet-state --active {server-id} - 指定集群和节点:
–availiable-zone {region}:{host},指定在哪个集群的哪个节点创建 - 查看实例的日志和控制台url:
openstack console log {id}和openstack console url show {id}
OpenStack中计算节点上虚拟机默认保存路径在哪?
在计算节点的/var/lib/nova/instances目录。
OpenStack中Glance镜像的默认保存路径在哪?
控制节点的/var/lib/glance/images目录。
OpenStack中计算节点的集成桥(br-int)的作用是什么?
对通过实例的流量进行标记和取消标记的操作,VLAN网络。
OpenStack中计算节点的隧道桥(br-tun)的作用是什么?
隧道桥(br-tun)根据 OpenFlow 规则将 VLAN 标记的流量从集成网桥转换为隧道 ID。
隧道桥允许不同网络的实例彼此进行通信。隧道有利于封装在非安全网络上传输的流量,它支持两层网络,即 GRE 和 VXLAN。OpenStack中外部OVS桥(br-ex)的作用是什么?
用于转发来往的网络流量,允许实例与外部网络进行通信
OpenStack和Docker区别
OpenStack是一个成熟的完整的云资源管理的平台。可以统一管理平台中的计算、存储以及网络等资源,提供对于虚拟机的调度管理。底层默认使用kvm和qemu去管理虚拟机,但是同样可以管理容器。
而docker则是负责管理计算机中需要与其他进程相互隔离的容器,容器的开销相比于虚拟机更少,本质上就是一个操作系统进程,可以将自己的环境或者应用程序部署在容器里,然后打包分发之类的,可以实现快速部署。
docker应该和虚拟机是一个类别的。OpenStack和kvm的区别
OpenStack本质只是一个云管理平台,不具备比如虚拟化这种功能。虚拟化是通过系统底层实现的hypervisior(kvm、qemu和Xen、virtual box等)实现的。
如果没有OpenStack同样可以使用其他工具来管理kvm,比如libvirt提供的vish-manager。kvm和xen区别
kvm是一个内核提供的轻量级虚拟化管理解决方案,需要虚拟化支持(Intel-VT或者AMD-V)。
Xen是运行支持的Xen内核,可以在系统上使用qemu模拟多个虚拟机。
kvm可以使用通常的linux调度和内存管理
Xen更新以后需要重新编译内核,而kvm只需要重新安装模块即可,更加精简,避免出错的几率。Neutron
vlan和vxlan的区别
vlan的vni是12位:1-4096,vxlan是24位,最大可以一一千六百多万个vni。
vxlan是基于隧道技术在屋里三层网络中模拟二层网络,对二层数据包的一个封装,使用UDP在三层网络进行一个转发。
vlan只能用于广播域的隔离,但是解决不了IP地址和MAC的重叠问题,vxlan可以做到不同租户独立组网,通信地址分配以及多租户的地址冲突问题可以解决。
交换机一个端口对应一个物理设备以及一个MAC地址,但是现在虽然一个端口还是连接一个物理机,但是可能会连接到多个虚拟机,传统交换机收到一个数据帧以后,根据vlan和目的MAC找到相应端口,将数据包转发出去。同时交换机会记住学习这个MAC记录,但是交换机内存是有限的,随着虚拟化的实现,网络中的MAC地址非常多的,交换机如果不足以支持的话,可能会移除,然后就不能正常工作,如果找不到MAC会进行flood,增加其他网络设备的负担和网络拥塞。
使用VxLAN,以太帧会被VTEP封装在UDP里面,一个VTEP可以被一个物理及的所有虚拟机使用,对于交换机,他看到的只是VTEP之间传递信息,并看不到实际虚拟机传递信息。所以交换机只需要记录VTEP的信息即主机信息即可。Docker
命名空间
- 网络命名空间:网络设备端口等
- 进程命名空间:进程编号
- 用户命名空间:用户和用户组
- 挂载命名空间:挂载点、文件系统
- UTS命名空间:主机名和域名
- IPC命名空间:信号量、消息队列共享内存