JVM调优(10)JVM的运行时数据区
一、概述
对于 C C++ 来说,在内存管理领域,JVM既拥有最高的权利,但是同时他们又是从事最基础工作的劳动人员,因为他们担负着每一个对象从开始到结束的维护责任。而对于Java来说,再虚拟机自动内存管理的帮助下,不再需要为每一个new操作去分配内存,不容易出现内存泄漏和内存溢出的情况,但是因为我们Java程序员 不用管理内存,所以一旦出现内存问题,很容易让我们手忙脚乱,所以呢我们必须要了解Java虚拟器的内存管理机制,以便我们能更好的处理各种各样的问题。
二、运行时数据区
Java虚拟机在执行程序的过程中会把所管理的内存划分为若干个不同的数据区域,这些区域都有各自的用途,以及创建和销毁时间。再Java 1.8中 从宏观上来说分为线程共享,和线程私有 主要是分为以下几个区域

三、程序计数器
特点:线程内存独享,占用内存小,生命周期与线程相同(随线程诞生而诞生,随线程消亡而消亡)
功能:当前线程所执行的字节码的行号指示器。在虚拟机的概念模型里字节码解释器工作时就是通过改变这个计数器的值来选取下一条需要执行的字节码指令,分支、循环、跳转、异常处理、线程恢复(cpu在不断轮询执行任务)等基础功能都需要依赖这个计数器来完成
异常:该区域没有定义异常
四、Java虚拟机栈
特点:先进后出,线程内存独享,生命周期与线程相同
单位:栈帧
功能:已先进后出执行方法体的方法,执行完成的栈帧出栈
4.1 运行原理
a. JVM直接对Java栈的操作只有两个,就是对栈帧的压栈和出栈,遵循“先进后出” / "后进先出”原则。
b. 在一条活动线程中,一个时间点上,只会有一个活动的栈帧。即只有当前正在执行的方法的栈帧(栈顶栈帧)是有效的,这个栈帧被称为当前栈帧(current Frame) ,与当前栈帧相对应的方法就是当前方法(currentMethod) ,定义这个方法的类就是当前类(current Class)。不同线程中所包含的栈帧是不允许存在相互引用的,即不可能在一个栈帧之中引用另外一个线程的栈。
c. 执行引擎运行的所有字节码指令只针对当前栈帧进行操作。
d. 如果在该方法中调用了其他方法,对应的新的栈帧会被创建出来,放在栈的顶端,成为新的当前帧.方法返回之际,当前栈帧会传回此方法的执行结果给前一个栈帧,接着,虚拟机会丢弃当前栈帧,使得前一个栈帧重新成为当前栈帧。
e. Java方法有两种返回函数的方式,一种是正常的函数返回,使用return指令;另外一种是方法执行中出现未捕获处理的异常,以抛出异常的方式结束。不管使用哪种方式,都会导致栈帧被弹出。
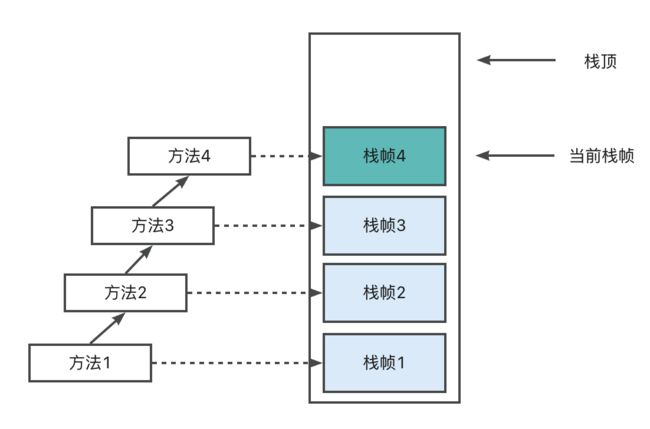
结论
● 一个线程 表示的是一个Java虚拟机栈
● 一个方法的执行,可以通过压栈的方式,也就是 方法对应的是栈帧
4.2 栈的基本单位栈帧
栈帧(每一个方法对应一个栈帧)
只有虚拟机栈顶的栈帧才是有效的,称为当前栈帧 (Current Stack Frame),这个栈帧所关联的方法称为当前方法(Current Method) 组成:
- 局部变量表
- 操作数栈
- 动态链接
- 方法出口信息
局部变量表:由基本数据类型和对象引用组成的
作用:用来存储方法中的局部变量
基本单位:slot
- 局部变量表的大小在编译器就可以确定其大小了,因此在程序执行期间局部变量表的大小是不会改变的。
- 如果存储的是基本数据类型那么直接存储值
- 如果存储的是对象引用那么存储对象的引用地址( reference)(堆中)
reference的两种实现方式
直接引用
reference直接指向对象,对象中指向对象类型数据
优点:速度快,节约指针开销。HotSpot采用的主要方式

使用句柄池
java堆中会维护一个句柄池,句柄池分别指向对象实例(堆)的和对象类型数据(方法区)
优点:对象移动后只需改变句柄池的指向地址,而不需要改变引用的指向地址。稳定
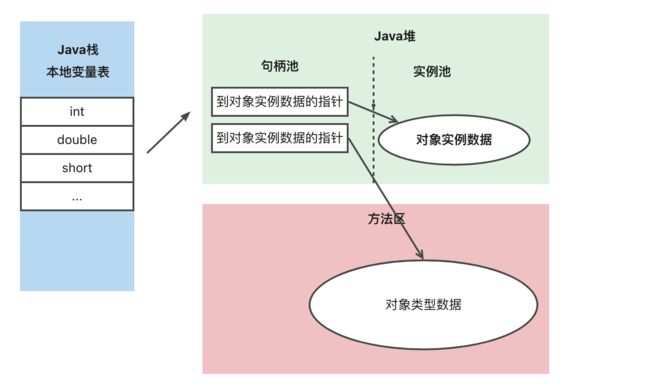
其实用白话来说 就是2个人是直接自己单线联系,还是通过一个第三方联系,自己并不知道自己要联系的是谁。
4.3 操作数栈
操作数栈的深度在编译器就可以确定其大小了,因此在程序执行期间局部变量表的大小是不会改变的。
功能:实现程序功能
4.4 动态连接
补充下直接引用与符号引用
● 直接引用:当类已经加载到虚拟机时,通过地址直接调用该类
● 符号引用(常量池中):在编译的时候还不知道类是否被加载,先用符号代替该类,等实际运行时再用直接引用替换间接引用。
静态解析:符号引用一部分会在类加载阶段或第一次使用的时候转化为直接引用
动态连接: 将在每一次的运行期期间转化为直接引用
4.5 方法出口信息
当一个方法执行完毕之后,要返回之前调用它的地方,因此在栈帧中必须保存一个方法返回地址。
本地方法栈
● 大体上都类似于虚拟机栈
● 不同点:栈执行的java方法服务
● 本地方法栈执行的是Native方法(不一定是用java开发的)服务
五、Java堆
特点:存储对象,线程间内存共享,占用大量内存,垃圾回收关注的重点区域
异常:OutOfMemoryError
每次都向堆中存放对象,方法结束后,销毁栈帧的局部变量表时同时销毁引用,该对象就成了可回收的垃圾。咋看起来没什么不对呀,可是仔细思考下还是存在两个问题 1.不断的来回增加删除对象,对于GC的工作量太大。 2.java使指针碰撞(堆中存入新对象的时候,指针根据对象大小移动到相应位置)来为对象分配内存。如果在多线程的环境下,就会出现两个对象同时移动当前前指针的情况,造成线程不安全的情况。
这里就要引入TLAB的概念了
TLAB的全称是Thread Local Allocation Buffer,这是一个线程专用的内存分配区域。每个线程都会从Eden分配一块空间,当线程销毁时,我们自然可以回收掉TLAB的内存。
使用TLAB指令 -XX:UseTLAB
优点:线程安全,减少垃圾回收的压力。
缺点:TLAB空间大小是固定的,面对大对象的时候不够灵活
六、方法区
特点:存储类,线程间内存共享
存放已被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据
异常:OutOfMemoryError
提到方法区不得不说的就是运行时常量池
补充:方法区不是永久代,只是Hotspot的实现方式而已。
远行时常量池
运行时常量池是方法区的一部分,Class文件除了有类的版本,字段,方法,还有常量池
Java虚拟机对class文件每一部分的格式都有严格规定,每一个字节用于存储哪种数据都必须符合规范才会被jvm认可。但对于运行时常量池,Java虚拟机规范没做任何细节要求。
运行时常量池有个重要特性是动态性,Java语言不要求常量一定只在编译期才能产生,也就是并非预置入class文件中常量池的内容才能进入方法区的运行时常量池,运行期间也有可能将新的常量放入池中,这种特性使用最多的是String类的intern()方法。
既然运行时常量池是方法区的一部分,自然受到方法区内存的限制。当常量池无法再申请到内存时会抛出outOfMemeryError异常。
七、对象的创建
当虚拟机遇到一条New指令时:会进行如下步骤
● 检查指令的参数(即工作中我们New的对象),能否在常量池中找到它的符号引用。
● 如果存在,检查符号引用代表的类是否被加载、解析、初始化过。(如果没有则执行类的加载-----相关加载过程参考我前面的文章类加载机制)。
● 加载通过后,虚拟机将为新生对象分配内存。(所需内存大小在类加载完成后便可确定)
7.1 两种内存分配的方式
● 指针碰撞:假设Java堆中的内存是绝对规整的,所有用过的内存都放在一边,空闲的内存放在另一边。中间放着一个指针作为分界点的指示器,分配内存就仅仅是把指针往空闲空间那边挪动一段与对象大小相等的距离。这种方式则属于指针碰撞。
● 空闲列表:如果堆中的内存并不是规整的,已使用的内存和空闲内存相互交错,显然无法使用指针碰撞。虚拟机就必须维护一个列表,记录哪些内存是可用的,在分配的时候从列表中找到一块足够大的空间划分给对象实例,并更新记录表上的数据。这种方式属于空闲列表。
具体选择哪种分配方式由Java堆决定,而Java堆是否规整,则有GC收集器决定。因此使用Serial、ParNew等带Compact过程的收集器时,系统采用的分配算法是指针碰撞。而使用CMS这种基于Mark-Sweep算法的收集器时,通常采用的空闲列表。
7.2 如何保证分配内存时线程的安全性
● 对分配内存的动作进行同步处理(实际上虚拟机采用CAS配上失败重试的机制保证了更新操作的原子性)
● 把分配内存的动作按照线程划分在不同的空间之中进行(即每个线程在Java堆中预先分配一小块内存(称为本地线程分配缓冲))。
7.3 对象的内存布局
在HotSpot虚拟机中,对象在内存中的布局可以分为3块区域:对象头,实例数据和对齐填充
对象头包括两部分信息:
● 存储对象自身的运行时数据(如:哈希码、GC分代年龄、锁 等)
● 类型指针(即对象指向他的类元数据的指针,虚拟机根据此指针来确认对象属于哪个类的实例)
● 如果是数据 记录数组的大小 实例数据:
● 实例数据才是对象真正存贮的有效信息(即程序中所定义的各种类型的字段内容)。
对齐填充:
● 不是必然存在的,仅仅起到占位符的作用,因为HotSpot虚拟机要求对象的起始地址必须是8个字节的整数倍。
来个例子把JVM的运行时的区域全部串起来
public class Kafka {
public static void main() {
ReplicaManager replicaManager = new ReplicaManager() ;
replicaManager.loadReplicasFromDisk();
}
}
public class ReplicaManager{
private long replicacount;
public void loadReplicasFromDisk(){
Boolean hasFinishedLoad = false;
if (isLocalDatacorrupt()) {}
}
public Boolean isLocalDatacorrupt(){
Boolean isCorrupt = false;
return iscorrupt;
}
}
其实我们把上面的那个图和下面的这个总的大图一起串起来看看,还有配合整体的代码,我们来捋一下整体的流程,就会觉得很清晰。
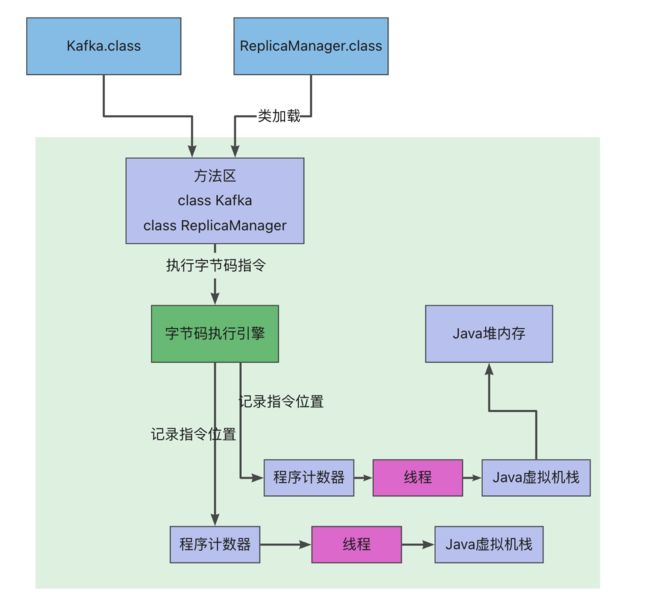
首先,你的JVM进程会启动,就会先加载你的Kafka类到内存里。然后有一个main线程,开始执行你的Kafka中的main0方法。
main线程是关联了一个程序计数器的,那么他执行到哪一行指令,就会记录在这里,如上图
其次,就是main线程在执行main方法的时候,会在main线程关联的Java虛拟机栈里,压入一个main方法的栈帧。接着会发现需要创建一个ReplicaManager类的实例对象,此时会加载ReplicaManager类到内存里来。然后会创建一个ReplicaManager的对象实例分配在Java堆内存里,并且在main方法的栈帧里的局部变量表引入-"replicaManager”变量,让他引用ReplicaManager对象在Java堆内存中的地址。接着,main线程开始执行ReplicaManager对象中的方法,会依次把自己执行到的方法对应的栈帧压入自己的Java虚拟机栈执行完方法之后再把方法对应的栈帧从Java虛拟机栈里出栈。