SQLAlchemy
文章目录
- 基于SQLAlchemy连接mysql库(pymsql插件)
- 基于SQLAlchemy连接mysql库(mysqlclient插件)
- 基于SQLAlchemy连接oracle库(cx_oracle插件)
- 基于SQLAlchemy连接pgsql库(psycopg2插件)
- 基于SQLAlchemy连接sqlserver库(pymssql插件)
- 基于SQLAlchemy连接clickhouse库(clickhouse-sqlalchemy/clickhouse_driver 插件)
- 基于SQLAlchemy连接kingbase(人大金仓)库(cksycopg2插件)
- 基于SQLAlchemy连接kingbase(人大金仓)库(psycopg2插件)
- 基于SQLAlchemy连接(达梦数据)库(插件)
基于SQLAlchemy连接mysql库(pymsql插件)
# -*- coding:UTF -8-*-
import os
import pandas as pd
# 检查是否有pymysql这个包存在
import pymysql
# SQLAlchemy本身无法操作数据库,其必须以来pymsql等第三方插件。
from sqlalchemy import create_engine,Sequence,text
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String, ForeignKey, UniqueConstraint, Index
from sqlalchemy.orm import sessionmaker, relationship
# 设置工作路径
os.chdir('E: /data')
# 读取文件
sale = pd.read_csv('sale.csv',encoding = 'GB18030')
'''
sale.csv:
year market sale profit
2010 东 33912 2641
2010 南 32246 2699
2010 西 34792 2574
2010 北 31884 2673
2011 东 31651 2437
2011 南 30572 2853
2011 西 34175 2877
2011 北 30555 2749
2012 东 31619 2106
2012 南 32443 3124
2012 西 32103 2593
2012 北 31744 2962
'''
# 初始化数据连接数据库的信息
host = yourhost
user = yourid
password = yourpassword
db = yourdatbasename
port = 3306
charset = 'utf8'
# 20210622 针对1.4版本后,如果密码中含有特殊符号,如@,:等,需要先将密码编译才可以解析正确
import urllib.parse
password = urllib.parse.quote_plus(password)
# 连接数据库
# pool_recycle控制任何连接的最大连接时长(秒);pool_size连接池的最大连接数,默认5,设置0时为无限制连接数连接;
# 20210728 pool_pre_ping预连接,相当于发送“SELECT 1”到sql中在每次连接中检查连接池。尝试3次在放弃之前。
# 20210728 pool_recycle=-1,此设置会导致池在给定的秒数过后回收连接。它默认为 -1,或没有超时。例如,设置为 3600 表示连接将在 1 小时后回收。请注意,如果在八小时内未在连接上检测到任何活动,MySQL 特别会自动断开连接。
# 请注意,失效仅在检查期间发生(only occurs during checkout)。不会发生在任何处于检查状态的连接上(not on any connections that are held in a checked out state)。 pool_recycle是Pool本身的函数,与anEngine是否在使用中无关。
# 使用 FIFO 与 LIFO, pool_use_lifo=True
# 所述QueuePool类设有称为标志 QueuePool.use_lifo,其也可以从访问 create_engine()经由所述标志create_engine.pool_use_lifo。将此标志设置为True会导致池的“队列”行为改为“堆栈”行为,例如,返回到池的最后一个连接是下一个请求中使用的第一个连接。与池长期存在的先进先出行为相反,先进先出会产生串联使用池中每个连接的循环效应,lifo 模式允许池中多余的连接保持空闲,从而允许服务器-关闭这些连接的侧超时方案。FIFO 和 LIFO 之间的区别基本上在于池是否需要即使在空闲期间也能保持完整的连接集:
# 将连接池与 Multiprocessing 或 os.fork() 一起使用
# 使用NullPool. 这是最简单的一次性系统,可防止Engine多次使用任何连接:
# from sqlalchemy.pool import NullPool
# engine = create_engine("mysql://user:pass@host/dbname", poolclass=NullPool)
# 一旦有人在新流程中,就呼叫Engine.dispose()任何给定的Engine人。在 Python 多处理中,诸如multiprocessing.Pool包含“初始化程序”钩子之类的构造是可以执行此操作的地方;否则在对象开始子叉的位置os.fork()或位置的顶部 Process,单个调用Engine.dispose()将确保刷新任何剩余的连接。这是推荐的方法:
# engine = create_engine("mysql://user:pass@host/dbname")
#def run_in_process():
# process starts. ensure engine.dispose() is called just once
# at the beginning
#engine.dispose()
#with engine.connect() as conn:
#conn.execute(text("..."))
#p = Process(target=run_in_process)
#p.start()
# 20210808 connect_args – 一个选项字典,将connect()作为附加关键字参数直接传递给 DBAPI 的方法。
# https://docs.sqlalchemy.org/en/14/core/engines.html#custom-dbapi-args
# max_overflow溢出连接池的最大额外连接数,超过pool_size所设置的连接数的溢出连接数。实际上总的并行连接总数为pool_size
# +max_overflow,设置-1为不设置溢出最大限制,默认为10;pool_timeout等待返回信息时间,默认为30(秒)
# echo类似于python的logging(日志)功能,默认为False
# 'mysql+pymysql',mysql为数据库类型,pymysql为连接方式
engine = create_engine('mysql+pymysql://{user}:{password}@{host}:{port}/{db}?charset={charset}'
.format(user = user,
host = host,
password = password,
db = db,
port = port,
charset = charset),
pool_size = 30,max_overflow = 0
pool_pre_ping=True , pool_recycle=-1, isolation_level="AUTOCOMMIT",
connect_args={'connect_timeout': 30)
# 创建直接调用数据库属性
conn = engine.connect()
# 查询数据库版本号
# execute里面为原始sql语句;
# fetchone为返回第一行结果;fetchall()为返回所有结果;fetchmany(n)为返回第n行结果
databaseVersion = conn.execute("SELECT VERSION()").fetchone()
# ##################使用原始sql语句运行#####################
# 创建一个数据表
conn.execute('CREATE TABLE sale ('
'year CHAR(20) NOT NULL,'
'market CHAR(20),'
'sale INT ,'
'profit_from_sale INT )')
# 删除表
conn.execute('DROP TABLE sale')
# 将df存进数据表中且如果有同名数据表就把之前的删除后重新添加
sale.to_sql('sale',conn,if_exists='replace',index = False)
# 查询数据表语句
conn.execute('select * from sale').fetchall()
conn.execute('select DISTINCT year,market from sale').fetchall()
conn.execute("select * from sale where year=2012 and market=%s",'东').fetchall()
conn.execute('select year,market,sale,profit from sale order by sale').fetchall()
# 添加数据记录
conn.execute("insert into sale (year,market,sale) value (2010,'东',33912)")
# 删除数据记录
conn.execute("delete from sale")
# #########################ORM模式############################
##创建表
# 创建对象的基类
Base = declarative_base()
# 在本地内存创建单表(建立本地与sql的连接)
class Sale(Base):
__tablename__ = 'sale'
year = Column(String(20), primary_key=True, nullable=False)
market = Column(String(10))
sale = Column(Integer)
profit_from_sale = Column(Integer)
# 测试用
def __repr__(self):
return '%s(%s,%s,%s,%s)'%\
(self.__tablename__,self.year,self.market,self.sale,self.profit_from_sale)
# 创建属性,UniqueConstraint为unique key,Index为index
# __table_args__ = (
# UniqueConstraint('id', 'name', name='uix_id_name'),
# Index('ix_id_name', 'name', 'extra'),)
'''
sale表在sql的DDL
CREATE TABLE `sale` (
`year` varchar(20) NOT NULL,
`market` varchar(10) DEFAULT NULL,
`sale` int(11) DEFAULT NULL,
`profit_from_sale` int(11) DEFAULT NULL,
PRIMARY KEY (`year`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
'''
# 查询本地表的结构
Sale.__table__
# 创建一对多表(建立本地与sql的连接)
class Favor(Base):
__tablename__ = 'favor'
nid = Column(Integer, primary_key=True, autoincrement=True)
caption = Column(String(50), default='red', unique=True)
sale_year = Column(String(10), ForeignKey("sale.year"))
'''
favor表在sql的DDL
CREATE TABLE `favor` (
`nid` int(11) NOT NULL AUTO_INCREMENT,
`caption` varchar(50) DEFAULT NULL,
`sale_year` varchar(10) DEFAULT NULL,
PRIMARY KEY (`nid`),
UNIQUE KEY `caption` (`caption`),
KEY `sale_year` (`sale_year`),
CONSTRAINT `favor_ibfk_1` FOREIGN KEY (`sale_year`) REFERENCES `sale` (`year`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
'''
# 初始化数据库函数(全部)
Base.metadata.create_all(conn)
# 删除数据库(全部)
Base.metadata.drop_all(conn)
##操作表
# 创建session********************
Session = sessionmaker(bind=conn)
session = Session()
# 新增单条数据
new = Sale(year=2010, market='东', sale=33912)
session.add(new)
# 新增多条数据
session.add_all([
Sale(year=2011, market='东', sale=31651, profit_from_sale=2437),
Sale(year=2012, market='东', sale=31619),
])
try:
# 提交即保存到数据库
session.commit()
except:
# 回滚,返回session执行之前的状态
session.rollback()
# 查询表(Querying)
# 返回的是list格式
session.query(Sale.year, Sale.sale).all()
# order_by以什么为顺序(默认升序)
for i in session.query(Sale).order_by(Sale.sale):
print(i.year,i.sale)
#first()为第一行,all()为全部
for i in session.query(Sale,Sale.year).all():
print(i.Sale,i.year)# 测试用
# label为设置替换名
for i in session.query(Sale.year.label('test')).all():
print(i.test)
from sqlalchemy.orm import aliased# 替换功能
Sale_test = aliased(Sale, name='sale_test' )# name为table的名字
for i in session.query(Sale_test).all()[1:3]:
print(i)
# filter_by为匹配;filter也一样,用法为filter(Sale.year = 2012),
# filter与filter之间用.连接,代表and的意思
for i in session.query(Sale).filter_by(year = 2012).all():
print(i)
# 使用text来混合原始sql语句使用
session.query(Sale).filter(text('year>2010')).order_by(text('sale')).all()
session.query(Sale.sale).filter(text('year>2010')).group_by(Sale.sale).all()
session.query(Sale).filter(text('year=:year and market=:market'))\
.params(year = 2011,market ='东').order_by(Sale.sale).one()
session.query(Sale).from_statement(text('select * from sale where year={}'.format(2012))).all()
# Counting统计
session.query(Sale.profit_from_sale).count() # 统计行数,返回int
from sqlalchemy import func# func 后可以跟任意函数名,只要该数据库支持
session.query(func.count(Sale.profit_from_sale)).scalar()# 统计非nan值个数,返回int
session.query(func.count()).select_from(Sale).scalar()
session.query(Sale.profit_from_sale).distinct().count()# 统计不同的个数
# 删除数据
session.query(Sale).filter(Sale.year == 2012).delete()
session.commit()
# 修改数据(如果之前删除了数据,由于数据表发生变化,需要重新连接sql)
session.query(Sale).filter(Sale.year == 2010).update({"profit_from_sale":666})
session.query(Sale).filter(Sale.year == 2010).update({Sale.profit_from_sale:Sale.profit_from_sale+333})
session.commit()
# 关闭session****************
session.close()
# ###################pandas模式###################
# 将DataFrame/Series写入sql里面
# sale1为写入表的名称;conn为SQLAlchemy/DBAPI2连接sql的引擎;schema为设定模式默认为默认模式;
# if_exists:{'fail','replace','append'}为如果存在相同的表,fail不操作不添加,
# replace删除原表重新添加,append插入数据(列名要一致,尾端插入)。
# 三者在没有原表时都会创建新表,default ‘fail’;
# index:default True,将DataFrame的index作为一列写入sql里;
# index_label:{string or sequence}, default None,设置sql的索引所在的列(名);
# chunksize:{int}, default None,设置每次写入sql里的DF行数,若为空,则一次心写入全部;
# dtype:{dict of column name to SQL type}, default None,写入sql里面的列解释,必须是在
# SQLAlchemy模式下
sale.to_sql('sale1',conn,if_exists='append',index = 0,index_label='year',chunksize = None)
# 将sql里面的数据读取到DF
# schema为sql的模式;index_col为指定sql里的一列为DF的index;
# coerce_float将非数字非字符串自动转化为浮点数,默认为True;
# parse_dates解析列属性,输入List of column names将对应的列内容转化为时间日期格式。
# 输入Dict{column_name: format string}将列内容转化为对应的字符串格式.
# 输入Dict{column_name: arg dict}将列内容转化为pandas.to_datetime()格式,
# arg dict为pandas.to_datetime()参数;
# columns为需要查询sql的table的列内容所对应的列名,默认None为全查
readSqlTable1 = pd.read_sql_table('sale1',conn,parse_dates=('year'))
type(readSqlTable1['year'][0])#pandas._libs.tslib.Timestamp
readSqlTable2 = pd.read_sql_table('sale1',conn,parse_dates={'year':'%Y-%M-%D'},columns=['year','sale'])
type(readSqlTable2['year'][0])#datetime.date
readSqlTable3 = pd.read_sql_table('sale1',conn,parse_dates={'year':{'format':'%Y-%M-%D'}})
type(readSqlTable3['year'][0])#datetime.date
# 参数同上
readSqlQuery = pd.read_sql_query('select * from sale1',conn)
readSql1 = pd.read_sql('select * from sale1',conn)
readSql2 = pd.read_sql('sale1',conn)
# 关闭sql连接
conn.close()
# 20210511添加游标全表扫描千万级别数据方法
# https://docs.sqlalchemy.org/en/14/core/connections.html
# 流处理
with sql_engine.connect() as conn:
source = conn.execution_options(stream_results=True, max_row_buffer=100).execute(sql_str)
for row in source:
tmp = pd.DataFrame([row],columns=table_columns)
tmp.fillna("",inplace=True)
tmp = tmp.applymap(str)
tmp = tmp.applymap(lambda x: x.replace("'", '"'))
tmp = tmp.applymap(lambda x: None if x == '' else x)
json_str = str(tmp.to_dict(orient="records"))
# 模拟批处理
max_row_buffer = 1000
with engine.connect() as conn:
conn = conn.execution_options(stream_results=True, max_row_buffer=max_row_buffer)
source = conn.execute(sqlalchemy.text(sql_str))
c_n = 0
result = []
for row in source:
result.append(row)
c_n += 1
if c_n == max_row_buffer:
c_n = 0
result = pd.DataFrame(result, columns=table_columns)
yield result
result = []
else:
result = pd.DataFrame(result, columns=table_columns)
yield result
# 批处理-sqlalchemy 1.4.18
max_row_buffer = 1000
with engine.connect() as conn:
conn = conn.execution_options(stream_results=True)
source = conn.execute(sqlalchemy.text(sql_str))
# for row in source.yield_per(max_row_buffer):
for row in source.partitions(max_row_buffer):
tmp = pd.DataFrame(row, columns=table_columns)
yield tmp
# sqlalchemy.orm方式
from sqlalchemy.orm import sessionmaker
Session = sessionmaker()
Session.configure(bind=engine)
session = Session()
source = session.execute(sqlalchemy.text(sql_str).execution_options(stream_results=True))
for row in source.partitions(max_row_buffer):
tmp = pd.DataFrame(row, columns=table_columns)
yield tmp
session.close()
# 20210526添加sqlalchemy.text规范sql语句方法
# https://docs.sqlalchemy.org/en/14/core/sqlelement.html?highlight=text#sqlalchemy.sql.expression.text
from sqlalchemy import text
a = text('select * from db_test.table_A where lng_lat_GCJ02_md5= :lng_lat_GCJ02_md5 ').bindparams(lng_lat_GCJ02_md5="5deb95b66bb8fd1ac0ecd8a2cba3c92f")
with engine.connect() as conn:
b = pd.read_sql(a, conn)
a = text('select * from db_test.table_A where lng_lat_GCJ02_md5= :lng_lat_GCJ02_md5 ').bindparams(lng_lat_GCJ02_md5=None)
with engine.connect() as conn:
b = pd.read_sql(a, conn)
# 20210617添加insert ignore 写法
# https://stackoverflow.com/questions/2218304/sqlalchemy-insert-ignore
# https://docs.sqlalchemy.org/en/13/core/compiler.html#changing-the-default-compilation-of-existing-constructs
from sqlalchemy.ext.compiler import compiles,deregister
from sqlalchemy.sql.expression import Insert
# 全局修改
@compiles(Insert)
def _prefix_insert_with_ignore(insert, compiler, **kw):
return compiler.visit_insert(insert.prefix_with('OR IGNORE'), **kw)
# 伪-局部修改:仍然是一个全局更改,但是只要您不使用线程并确保在deregister调用之前正确提交所有内容,就可能没问题。
def _prefix_insert_with_ignore(insert, compiler, **kw): # 创建自定义前缀
return compiler.visit_insert(insert.prefix_with('IGNORE'), **kw)
compiles(Insert)(_prefix_insert_with_ignore) # 启用自定义前缀
with target_engine.connect() as conn:
source.to_sql(target_table,conn,schema=target_schema,if_exists="append",index=False)
deregister(Insert) # 删除自定义前缀
# 20210628添加replace into 写法
# https://stackoverflow.com/questions/6611563/sqlalchemy-on-duplicate-key-update
def _prefix_insert_with_repalce(insert, compiler, **kw):
s = compiler.visit_insert(insert, **kw)
s = s.replace("INSERT INTO", "REPLACE INTO")
return s
compiles(Insert)(_prefix_insert_with_repalce)
with target_engine.connect() as conn:
source.to_sql(target_table,conn,schema=target_schema,if_exists="append",index=False)
deregister(Insert) # 删除自定义前缀
# 20210628添加on duplicate key update 写法
def _prefix_insert_with_on_duplicate_key_update(insert, compiler, **kw):
s = compiler.visit_insert(insert, **kw)
fields = s[s.find("(") + 1:s.find(")")].replace(" ", "").split(",")
generated_directive = ["{0}=VALUES({0})".format(field) for field in fields]
# print(s + " ON DUPLICATE KEY UPDATE " + ",".join(generated_directive))
return s + " ON DUPLICATE KEY UPDATE " + ",".join(generated_directive)
compiles(Insert)(_prefix_insert_with_on_duplicate_key_update)
with target_engine.connect() as conn:
source.to_sql(target_table,conn,schema=target_schema,if_exists="append",index=False)
deregister(Insert) # 删除自定义前缀
# 20211124 添加引擎断线重连
def reconnecting_engine(engine, num_retries, retry_interval):
# https://docs.sqlalchemy.org/en/14/faq/connections.html?highlight=ransaction%20replay%20extension
def _run_with_retries(fn, context, cursor, statement, *arg, **kw):
retry = 0
while 1:
try:
fn(cursor, statement, context=context, *arg)
except engine.dialect.dbapi.Error as raw_dbapi_err:
if retry == 0:
e = traceback.format_exc()
ex = raw_dbapi_err
connection = context.root_connection
# 断线重连模块
if engine.dialect.is_disconnect(
raw_dbapi_err, connection, cursor
):
if num_retries == 0:
pass
else:
if retry > num_retries:
raise ValueError(e)
engine.logger.error(
"disconnection error, retrying operation. retry times: {}".format(retry),
exc_info=False,
)
# https://docs.sqlalchemy.org/en/14/core/connections.html#sqlalchemy.engine.Connection.invalidate
# 使与此关联的基础 DBAPI 连接无效Connection。
# 将尝试立即关闭底层 DBAPI 连接;但是,如果此操作失败,则会记录错误但不会引发错误。无论 close() 是否成功,连接都会被丢
connection.invalidate() #
# use SQLAlchemy 2.0 API if available
if hasattr(connection, "rollback"):
connection.rollback()
else:
trans = connection.get_transaction()
if trans:
trans.rollback()
time.sleep(retry_interval)
# context.cursor = cursor_obj = connection.connection.cursor() # 重新创建游标
while 1:
try:
context.cursor = cursor_obj = connection.connection.cursor() # 重新创建游标
cursor = context.cursor
break
except Exception as ex:
time.sleep(retry_interval)
print(ex)
# 锁表重连模块
elif _lock_table_error(raw_dbapi_err):
if num_retries == 0:
pass
else:
if retry > num_retries:
raise ValueError(raw_dbapi_err)
engine.logger.error(
"lock error, retrying operation. retry times: {}".format(retry),
exc_info=False,
)
time.sleep(retry_interval)
else:
raise
else:
return True
retry += 1
def _connect_with_retries(dialect, conn_rec, cargs, cparams):
retry = 0
while 1:
try:
connection = dialect.connect(*cargs, **cparams)
return connection
except engine.dialect.dbapi.Error as raw_dbapi_err:
if _lost_connect_error(raw_dbapi_err):
if num_retries == 0:
pass
else:
if retry > num_retries:
raise ValueError(raw_dbapi_err)
engine.logger.error(
"disconnection error, retrying operation. retry times: {}".format(retry),
exc_info=False,
)
time.sleep(retry_interval)
else:
raise
retry += 1
e = engine.execution_options(isolation_level="AUTOCOMMIT")
@event.listens_for(e, "do_execute_no_params")
def do_execute_no_params(cursor_obj, statement, context):
return _run_with_retries(
context.dialect.do_execute_no_params, context, cursor_obj, statement
)
@event.listens_for(e, "do_execute")
def do_execute(cursor_obj, statement, parameters, context):
return _run_with_retries(
context.dialect.do_execute, context, cursor_obj, statement, parameters
)
@event.listens_for(e, 'do_connect')
def do_connect(dialect, conn_rec, cargs, cparams):
return _connect_with_retries(dialect, conn_rec, cargs, cparams)
def _lock_table_error(raw_dbapi_err, db_model: str = "mysql"):
if db_model not in ["mysql", "oracle", "msssql", "pgsql"]:
raise ValueError(
'Argument {} must be in {}'.format("db_model", "[mysql, oracle, mssql, pgsql]")
)
lock_table_error_code_dict = {
"mysql": [1205, 1412]
}
error_code = raw_dbapi_err.args[0]
error_message = raw_dbapi_err.args[1]
if error_code in lock_table_error_code_dict[db_model]:
return 1
else:
return 0
def _lost_connect_error(raw_dbapi_err, db_model: str = "mysql"):
if db_model not in ["mysql", "oracle", "msssql", "pgsql"]:
raise ValueError(
'Argument {} must be in {}'.format("db_model", "[mysql, oracle, mssql, pgsql]")
)
lock_table_error_code_dict = {
"mysql": [2003, 2006]
}
error_code = raw_dbapi_err.args[0]
error_message = raw_dbapi_err.args[1]
if error_code in lock_table_error_code_dict[db_model]:
return 1
else:
return 0
return e
def do_a_thing(engine):
# with engine.connect() as conn:
# conn.execute("LOCK TABLES db_test.a_test_003 WRITE")
with engine.connect() as conn:
while True:
conn.execute('''set lock_wait_timeout = 1''')
# time.sleep(5)
print("ping: %s" % conn.execute("select * from db_test.a_test_003 limit 1").fetchone())
# print("ping: %s" % conn.execute("select 1").fetchone())
e = reconnecting_engine(
engine,
num_retries=5,
retry_interval=1,
)
do_a_thing(e)
基于SQLAlchemy连接mysql库(mysqlclient插件)
github网址:https://github.com/PyMySQL/mysqlclient
若直接使用github上的安装指令pip install mysqlclient会提示失败。github上有提示需要根据操作系统安装【MariaDB C连接器】
失败图
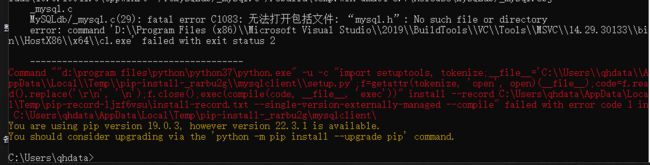
windows的
linux的

进入下载网页后根据自己的系统选择

win的安装界面

然后直接安装即可(本来官方也提示了不要更改安装路径,使用默认路径)。
然后再次使用安装指令即可。
如果遇到MySQLdb/_mysql.c(29): fatal error C1083: 无法打开包括文件: “mysql.h”: No such file or directory这个错误,我查到的是说尝试在64位环境中为python32安装mysqlclient时发生此错误。卸载python并重新安装64位版本。然后pip install mysqlclient将运行。
不过我直接使用https://www.lfd.uci.edu/~gohlke/pythonlibs/#mysqlclient来安装解决(实在不想折腾重新安装py的问题)
host = '123.11.11.11'
user = 'root'
password = '123456'
db = 'db_test'
port = 3308
charset = 'utf8mb4'
# mysqlclient (a maintained fork of MySQL-Python) 官网给的连接方法
# engine = create_engine("mysql+mysqldb://scott:tiger@localhost/foo")
engine = create_engine('mysql+mysqldb://{user}:{password}@{host}:{port}/{db}?charset={charset}'
.format(user = user,
host = host,
password = urllib.parse.quote_plus(password),
db = db,
port = port,
charset = charset),
pool_size = 30,max_overflow = 0,
pool_pre_ping=True , pool_recycle= 3600)
conn = engine .connect()
print(str(engine .engine))
print(conn.execute("SELECT VERSION()").fetchone())
在ubuntu上失败的问题。
一般都是apt-get太久没有更新,使用sudo apt-get update即可。
20230213补充
参考文章:https://blog.webmatrices.com/error-command-errored-out-with-exit-status-1-mysqlclient/
如果出现下面错误
qhdata@qhdata-dev:~/tmp$ sudo python3 -m pip install mysqlclient
Collecting mysqlclient
Using cached mysqlclient-2.1.1.tar.gz (88 kB)
ERROR: Command errored out with exit status 1:
command: /usr/bin/python3 -c 'import sys, setuptools, tokenize; sys.argv[0] = '"'"'/tmp/pip-install-zfhc_6m1/mysqlclient/setup.py'"'"'; __file__='"'"'/tmp/pip-install-zfhc_6m1/mysqlclient/setup.py'"'"';f=getattr(tokenize, '"'"'open'"'"', open)(__file__);code=f.read().replace('"'"'\r\n'"'"', '"'"'\n'"'"');f.close();exec(compile(code, __file__, '"'"'exec'"'"'))' egg_info --egg-base /tmp/pip-install-zfhc_6m1/mysqlclient/pip-egg-info
cwd: /tmp/pip-install-zfhc_6m1/mysqlclient/
Complete output (15 lines):
/bin/sh: 1: mysql_config: not found
/bin/sh: 1: mariadb_config: not found
/bin/sh: 1: mysql_config: not found
Traceback (most recent call last):
File "", line 1, in
File "/tmp/pip-install-zfhc_6m1/mysqlclient/setup.py", line 15, in
metadata, options = get_config()
File "/tmp/pip-install-zfhc_6m1/mysqlclient/setup_posix.py", line 70, in get_config
libs = mysql_config("libs")
File "/tmp/pip-install-zfhc_6m1/mysqlclient/setup_posix.py", line 31, in mysql_config
raise OSError("{} not found".format(_mysql_config_path))
OSError: mysql_config not found
mysql_config --version
mariadb_config --version
mysql_config --libs
----------------------------------------
ERROR: Command errored out with exit status 1: python setup.py egg_info Check the logs for full command output.
安装下面的程序
sudo apt-get install python3-dev
sudo apt-get install libmysqlclient-dev
然后重新安装即可。
基于SQLAlchemy连接oracle库(cx_oracle插件)
import pandas as pd,os
from sqlalchemy import create_engine
# oracla
os.environ['NLS_LANG'] = 'AMERICAN_AMERICA.ZHS16GBK'
host_2 = '10.210.128.130'
user_2 = 'resmg'
password_2 = 'zgbgt.db181'
db_2 = 'client'
port_2 = 1521
engine_2 = create_engine('oracle+cx_oracle://{user}:{password}@{host}:{port}/{db}'
.format(user = user_2,
host = host_2,
password = password_2,
db = db_2,
port = port_2),
pool_size = 30,max_overflow = 0, isolation_level="AUTOCOMMIT")
# 创建直接调用数据库属性
conn_2 = engine_2.connect()
如果遇到:sqlalchemy.exc.DatabaseError: (cx_Oracle.DatabaseError) DPI-1047: 64-bit Oracle Client library cannot be loaded: "The specified module could not be found". See https://oracle.github.io/odpi/doc/installation.html#windows for help (Background on this error at: http://sqlalche.me/e/4xp6)
这个错误,链接Oracle的客户端包添加到环境变量,然后重启电脑即可。或者在代码中添加
LOCATION = r"C:\Oracle\instantclient_18_5" # 你的oracle连接包的位置
# print("ARCH:", platform.architecture())
# print("FILES AT LOCATION:")
# for name in os.listdir(LOCATION):
# print(name)
os.environ["PATH"] = LOCATION + ";" + os.environ["PATH"]
如果遇到MSVCR120.dll文件异常,可以参考以下原文解决
https://blog.csdn.net/zengmingen/article/details/83780711
到微软官网下载 VC redist packages for x64。
微软官网地址:https://www.microsoft.com/en-us/download/details.aspx?id=40784
vcredist_x64.exe
如果是32位,则选vcredist_x32.exe
Oracle 的编码AMERICAN_AMERICA.ZHS16GBK可以通过
select userenv('language') from dual;
在Oracle中查询。
基于SQLAlchemy连接pgsql库(psycopg2插件)
from sqlalchemy import create_engine
host_1 = '10.210.202.153'
user_1 = 'qhtest'
password_1 = 'Qhdata12#$'
db_1 = 'sz_mppdb'
port_1 = 25308
charset_1 = 'utf8'
engine_1 = create_engine('postgresql+psycopg2://{user}:{password}@{host}:{port}/{db}'
.format(user = user_1,
host = host_1,
password = password_1,
db = db_1,
port = port_1),
pool_size = 30,max_overflow = 0,client_encoding='utf8', isolation_level="AUTOCOMMIT") # 开启自动提交
# 创建直接调用数据库属性
conn_1 = engine_1.connect()
基于SQLAlchemy连接sqlserver库(pymssql插件)
# -*- coding:UTF -8-*-
import os,re
# 检查是否有pymysql这个包存在
import pymysql,pymssql
from sqlalchemy import create_engine,Sequence,text
host = '123.11.11.11'
user = 'root'
password = '123456'
db1 = 'DC' # 记得使用不同的数据库,要修改
port = 1433
charset = 'utf8'
engine = create_engine('mssql+pymssql://{user}:{password}@{host}:{port}/{db}?charset={charset}'
.format(user=user,
host=host,
password=password,
db=db1,
port=port,
charset=charset),
pool_size=100, max_overflow=0, isolation_level="AUTOCOMMIT")
conn = engine.connect()
基于SQLAlchemy连接clickhouse库(clickhouse-sqlalchemy/clickhouse_driver 插件)
clickhouse-sqlalchemy的api网址:
https://github.com/xzkostyan/clickhouse-sqlalchemy
clickhouse-driver的api网址:
https://github.com/mymarilyn/clickhouse-driver
from sqlalchemy import create_engine
import urllib.parse
host = '1.1.1.1'
user = 'default'
password = 'default'
db = 'test'
port = 8123 # http连接端口
engine = create_engine('clickhouse://{user}:{password}@{host}:{port}/{db}'
.format(user = user,
host = host,
password = urllib.parse.quote_plus(password),
db = db,
port = port),
pool_size = 30,max_overflow = 0,
pool_pre_ping=True , pool_recycle= 3600)
port = 9000 # Tcp/Ip连接端口
engine1 = create_engine('clickhouse+native://{user}:{password}@{host}:{port}/{db}'
.format(user = user,
host = host,
password = urllib.parse.quote_plus(password),
db = db,
port = port),
pool_size = 30,max_overflow = 0,
pool_pre_ping=True , pool_recycle= 3600)
# 2021-12-21
# https://github.com/xzkostyan/clickhouse-sqlalchemy/issues/129
# 其中由于我使用的sqlalchemy是1.4版本,而clickhouse-sqlalchemy本身的最新版本是仅支持1.3的。所以需要使用他们的测试版本来,截止到发文日期,暂未发现测试版本使用中出现重大异常情况。其安装地址为
# pip install git+https://github.com/xzkostyan/[email protected]#egg=clickhouse-sqlalchemy==0.2.0
# 由于clickhouse-sqlalchemy并非sqlalchemy的默认引擎,导致对应的pandas也无法直接通过生成的engine来发送数据(其实是可以发送数据的,但是无法自动建表)。故做了一个仿pandas的发送数据功能
# 参考文档https://github.com/xzkostyan/clickhouse-sqlalchemy
class ClickhouseDf(object):
def __init__(self, **kwargs):
self.engines_dict = {
"MergeTree": engines.MergeTree,
"AggregatingMergeTree": engines.AggregatingMergeTree,
"GraphiteMergeTree": engines.GraphiteMergeTree,
"CollapsingMergeTree": engines.CollapsingMergeTree,
"VersionedCollapsingMergeTree": engines.VersionedCollapsingMergeTree,
"SummingMergeTree": engines.SummingMergeTree,
"ReplacingMergeTree": engines.ReplacingMergeTree,
"Distributed": engines.Distributed,
"ReplicatedMergeTree": engines.ReplicatedMergeTree,
"ReplicatedAggregatingMergeTree": engines.ReplicatedAggregatingMergeTree,
"ReplicatedCollapsingMergeTree": engines.ReplicatedCollapsingMergeTree,
"ReplicatedVersionedCollapsingMergeTree": engines.ReplicatedVersionedCollapsingMergeTree,
"ReplicatedReplacingMergeTree": engines.ReplicatedReplacingMergeTree,
"ReplicatedSummingMergeTree": engines.ReplicatedSummingMergeTree,
"View": engines.View,
"MaterializedView": engines.MaterializedView,
"Buffer": engines.Buffer,
"TinyLog": engines.TinyLog,
"Log": engines.Log,
"Memory": engines.Memory,
"Null": engines.Null,
"File": engines.File
}
self.table_engine = kwargs.get("table_engine", "MergeTree") # 默认引擎选择
if self.table_engine not in self.engines_dict.keys():
raise ValueError("No engine for this table")
def _createORMTable(self, df, name, con, schema, **kwargs):
col_dtype_dict = {
"object": sqlalchemy.Text,
"int64": sqlalchemy.Integer,
"int32": sqlalchemy.Integer,
"int16": sqlalchemy.Integer,
"int8": sqlalchemy.Integer,
"int": sqlalchemy.Integer,
"float64": sqlalchemy.Float,
"float32": sqlalchemy.Float,
"float16": sqlalchemy.Float,
"float8": sqlalchemy.Float,
"float": sqlalchemy.Float,
}
primary_key = kwargs.get("primary_key", [])
df_col = df.columns.tolist()
metadata = MetaData(bind=con, schema=schema)
_table_check_col = []
for col in df_col:
col_dtype = str(df.dtypes[col])
if col_dtype not in col_dtype_dict.keys():
if col in primary_key:
_table_check_col.append(Column(col, col_dtype_dict["object"], primary_key=True))
else:
_table_check_col.append(Column(col, col_dtype_dict["object"]))
else:
if col in primary_key:
_table_check_col.append(Column(col, col_dtype_dict[col_dtype], primary_key=True))
else:
_table_check_col.append(Column(col, col_dtype_dict[col_dtype]))
_table_check = Table(name, metadata,
*_table_check_col,
self.engines_dict[self.table_engine](primary_key=primary_key)
)
return _table_check
def _checkTable(self, name, con, schema):
sql_str = f"EXISTS {schema}.{name}"
if con.execute(sql_str).fetchall() == [(0,)]:
return 0
else:
return 1
def to_sql(self, df, name: str, con, schema=None, if_exists="fail",**kwargs):
'''
将DataFrame格式数据插入Clickhouse中
{'fail', 'replace', 'append'}, default 'fail'
'''
if self.table_engine in ["MergeTree"]: # 表格必须有主键的引擎列表-暂时只用这种,其他未测试
self.primary_key = kwargs.get("primary_key", [df.columns.tolist()[0]])
else:
self.primary_key = kwargs.get("primary_key", [])
orm_table = self._createORMTable(df, name, con, schema, primary_key=self.primary_key)
tanle_exeit = self._checkTable(name, con, schema)
# 创建表
if if_exists == "fail":
if tanle_exeit:
raise ValueError(f"table already exists :{name} ")
else:
orm_table.create()
if if_exists == "replace":
if tanle_exeit:
orm_table.drop()
orm_table.create()
else:
orm_table.create()
if if_exists == "append":
if not tanle_exeit:
orm_table.create()
# http连接下会自动将None填充为空字符串以入库,tcp/ip模式下则不会,会导致引擎报错,需要手动填充。
df_dict = df.to_dict(orient="records")
con.execute(orm_table.insert(), df_dict)
# df.to_sql(name, con, schema, index=False, if_exists="append")
# 使用方法
cdf = ClickhouseDf()
with engine.connect() as conn:
cdf.to_sql(df, table_name, conn, schema_name, if_exists="append")
基于SQLAlchemy连接kingbase(人大金仓)库(cksycopg2插件)
参考文章:https://blog.csdn.net/sxqinjh/article/details/109272042
注意:由于人大金仓的py连接器跟本身的金仓数据库与python版本是强关联的关系,所以如果本文中的更多是记录一种连接方式,具体的连接器建议找人大金仓的工程师要。
ps:不建议个人学习使用。
python版本:3.7.4 64位
SQLAlchemy版本:1.4.18
人大金仓版本:KingbaseES V008R006C006B0013PS003 on x86_64-pc-linux-gnu, compiled by gcc (GCC) 4.1.2 20080704 (Red Hat 4.1.2-46), 64-bit
驱动器版本:3.7.2 64位
官方网址:https://www.kingbase.com.cn/qd/index.htm
驱动下载地址:https://kingbase.oss-cn-beijing.aliyuncs.com/KES/07-jiekouqudong/Python.rar
下载完后解压得到如下文件(红框为我这次主要使用到的文件)
解压sqlalchemy.tar,将里面的kingbase文件夹的内容复制到

将ksycopg2-windows-amd64-MSVC2013-python3.7-64bit.zip中解压出的ksycopg2文件夹放到所在项目的根目录下。
ps:vcredist_msvc2017_x64.exe与vcredist_msvc2013_x64.exe看情况安装即可。
# -*- coding:UTF -8-*-
import os,re
import ksycopg2 # 检查ksycopg2 是否导入正常
from sqlalchemy import create_engine
host = '123.11.11.11'
user = 'root'
password = '123456'
db1 = 'DC' # 由于kingbase是基于pgsql上开发而来的,这里跟pgsql一样填写的是组名称
port = 54321
charset = 'utf8'
engine = create_engine('kingbase+ksycopg2://{user}:{password}@{host}:{port}/{db}'
.format(user = user,
host = host,
password = password,
db = db,
port = port))
conn = engine.connect()
基于SQLAlchemy连接kingbase(人大金仓)库(psycopg2插件)
python版本:3.10.11 64位
SQLAlchemy版本:2.0.19
人大金仓版本:KingbaseES V008R006C006B0013 on x86_64-pc-linux-gnu, compiled by gcc (GCC) 4.1.2 20080704 (Red Hat 4.1.2-46), 64-bit
psycopg2版本:2.9.6
首先,到
修改kingbase文件夹中的base.py中的_get_server_version_info函数
原始代码(大约在3315行)
def _get_server_version_info(self, connection):
v = connection.exec_driver_sql("select pg_catalog.version()").scalar()
m = re.match(
r".*(?:PostgreSQL|EnterpriseDB) "
r"(\d+)\.?(\d+)?(?:\.(\d+))?(?:\.\d+)?(?:devel|beta)?",
v,
)
if not m:
raise AssertionError(
"Could not determine version from string '%s'" % v
)
return tuple([int(x) for x in m.group(1, 2, 3) if x is not None])
修改成下面的代码
def _get_server_version_info(self, connection):
v = connection.exec_driver_sql("select pg_catalog.version()").scalar()
m = re.match(
r".*(?:Kingbase|KingbaseES)\s*"
r"V(\d+)\D?(\d+)\D?(?:(\d+))?",
v,
)
if not m:
raise AssertionError(
"Could not determine version from string '%s'" % v
)
return tuple([int(x) for x in m.group(1, 2, 3) if x is not None])
然后使用下面代码连接
host = '192.168.1.1'
user = 'system'
password = 'kingbase'
db = 'qh_zhtj'
port = 54321
charset = 'utf8'
engine = create_engine('kingbase+psycopg2://{user}:{password}@{host}:{port}/{db}'
.format(user=user,
host=host,
password=password,
db=db,
port=port),
pool_size=30, max_overflow=0, client_encoding=charset,
isolation_level="AUTOCOMMIT")
conn = engine.connect()
print(conn.execute(sqlalchemy.text("SELECT VERSION()")).fetchone())
基于SQLAlchemy连接(达梦数据)库(插件)
参考文章:https://eco.dameng.com/document/dm/zh-cn/app-dev/python-SQLAlchemy.html
注意:本文中的更多是记录一种连接方式。
ps:不建议个人学习使用。
python版本:3.10.11 64位
SQLAlchemy版本:2.0.17
sqlalchemy-dm版本:1.4.39
dmPython版本: 2.4.5
首先,需要先准备达梦数据库中的drivers文件整个拷贝出来,具体路径为
这些文件只有达梦数据库运行后才会自动生成。
然后使用pip安装2.4.5版本程序,安装指令如下:
pip install dmPython
安装完后修改复制出来的drivers文件中的base,具体路径为drivers/python/sqlalchemy1.4.6/sqlalchemy_dm/base.py
以下需改为适配sqlalchemy2.0.x而设置,若使用的是sqlalchemy1.4.x,则不需要修改以下代码。
修改1: 681行前后
修改前
def construct_params(
self,
params=None,
_group_number=None,
_check=True,
extracted_parameters=None,
escape_names=True,
):
self.dialect.trace_process('DMCompiler', 'construct_params', params, _group_number, _check, extracted_parameters, escape_names)
return super(DMCompiler, self).construct_params(params, _group_number, _check, extracted_parameters, escape_names)
修改后
def construct_params(
self,
params=None,
_group_number=None,
_check=True,
extracted_parameters=None,
escape_names=True,
):
self.dialect.trace_process('DMCompiler', 'construct_params', params, _group_number, _check, extracted_parameters, escape_names)
return super(DMCompiler, self).construct_params(params=params, _group_number=_group_number, _check=_check,
extracted_parameters=-extracted_parameters, escape_names=escape_names)
修改2: 668行前后
修改前
def bindparam_string(
self,
name,
positional_names=None,
post_compile=False,
expanding=False,
escaped_from=None,
**kw
):
self.dialect.trace_process('DMCompiler', 'bindparam_string', name, positional_names, post_compile, expanding, escaped_from, **kw)
return super(DMCompiler, self).bindparam_string(name, positional_names, post_compile, expanding, escaped_from, **kw)
修改后
def bindparam_string(
self,
name,
positional_names=None,
post_compile=False,
expanding=False,
escaped_from=None,
**kw
):
self.dialect.trace_process('DMCompiler', 'bindparam_string', name, positional_names, post_compile, expanding, escaped_from, **kw)
return super(DMCompiler, self).bindparam_string(name=name, positional_names=positional_names, post_compile=post_compile,
expanding=expanding, escaped_from=escaped_from, **kw)
修改3: 1854行前后
修改前
def has_table(self, connection, table_name, schema=None):
self.trace_process('DMDialect', 'has_table', connection, table_name, schema)
if not schema:
schema = self.default_schema_name
cursor = connection.execute(
sql.text("SELECT name FROM sysobjects "
"WHERE name = :name AND schid = SF_GET_SCHEMA_ID_BY_NAME(:schema_name)"),
name=self.denormalize_name(table_name),
schema_name=self.denormalize_name(schema))
return cursor.first() is not None
修改后
def has_table(self, connection, table_name, schema=None, **kw):
self.trace_process('DMDialect', 'has_table', connection, table_name, schema)
if not schema:
schema = self.default_schema_name
cursor = connection.execute(
sql.text("SELECT name FROM sysobjects "
"WHERE name = :name AND schid = SF_GET_SCHEMA_ID_BY_NAME(:schema_name)").
bindparams(name=self.denormalize_name(table_name), schema_name=self.denormalize_name(schema))
)
return cursor.first() is not None
修改4: 1916行前后
修改前
def _get_default_schema_name(self, connection):
self.trace_process('DMDialect', '_get_default_schema_name', connection)
return self.normalize_name(
connection.execute('SELECT USER FROM DUAL').scalar())
修改后
def _get_default_schema_name(self, connection):
self.trace_process('DMDialect', '_get_default_schema_name', connection)
return self.normalize_name(
connection.execute(sqlalchemy.text('SELECT USER FROM DUAL')).scalar())
同时在第2行添加
import sqlalchemy
修改5: 在开头添加下面语句
import sys
py2k = sys.version_info < (3, 0)
py3k = sys.version_info >= (3, 0)
if py3k:
text_type = str
else:
text_type = unicode # noqa
然后做全文替换:
- util.py2k全部替换成py2k,可能出现在1883,1908,2509行左右(由于不小心修改了位置,所以行数不太正确)
- util.text_type全部替换成text_type
修改drivers/python/sqlalchemy1.4.6/sqlalchemy_dm/types.py
修改1: 在开头添加下面语句
import sys
py2k = sys.version_info < (3, 0)
然后将全文中util.py2k全部替换成py2k,可能出现在149,274行左右
修改drivers/python/sqlalchemy1.4.6/sqlalchemy_dm/dmPython.py
修改1: 在开头添加下面语句
import sys
py2k = sys.version_info < (3, 0)
然后将全文中util.py2k全部替换成py2k,可能出现在404行左右
修改2: 修改将第7行
修改前
from sqlalchemy import types as sqltypes, util, exc , processors
修改后
from sqlalchemy import types as sqltypes, util, exc # , processors
然后使用官网的方法安装即可
cd drivers/python/sqlalchemy1.4.6
python setup.py install
或者将drivers/python/sqlalchemy1.4.6下的整个sqlalchemy_dm复制到
import os
DM_DB_BASE_HOME = ''
LOCATION = f'{DM_DB_BASE_HOME}/drivers/dpi'
os.environ["PATH"] = LOCATION + ";" + os.environ["PATH"]
import dmPython
import urllib.parse
from sqlalchemy import create_engine
host = '123.11.11.11'
user = 'root'
password = '123456'
port = 5236
engine = create_engine('dm+dmPython://{user}:{password}@{host}:{port}'
.format(user=user,
host=host,
password=urllib.parse.quote_plus(password),
port=port))
engine_1 = engine
import pandas as pd
print(pd.read_sql('select * from db_test.TABLE_1 ', conn))