macbook m1 本地部署llama2模型
前言
本文将对在macbook m1笔记本上使用llama.cpp本地部署量化版的llama2的过程进行记录。

测试环境:
- 芯片:Apple M1
- 内存:8G
-
llama-cpp-python == 0.1.79
Llama 2
Llama2是Meta AI开发的Llama大语言模型的迭代版本,提供了7B,13B,70B参数的规格。Llama2和Llama相比在对话场景中有进一步的能力提升,且Llama2具有开源商用许可,因此个人和组织能够更方便地构建自己的大模型应用。官方的Llama2可在Meta AI的官网Llama 2 - Meta AI上申请下载。
llama.cpp
LLMs的一大问题是参数量大,对GPU的现存要求搞。llama.cpp是ggml这个机器学习库的衍生项目,专门用于Llama系列模型的推理。llama.cpp和ggml均为纯C/C++实现,饼针对Apple Silicon芯片进行优化和硬件加速,支持模型的整型量化 (Integer Quantization): 4-bit, 5-bit, 8-bit等。当LLM与langchain等框架结合进行应用开发时我们仍然需要调用python,我们可以使用llama-cpp-python,由此使用python的API进行llama的调用。
部署记录
下载模型
在Meta AI的官网Llama 2 - Meta AI上申请下载Llama的官方模型,填写包括邮箱,国家等信息。
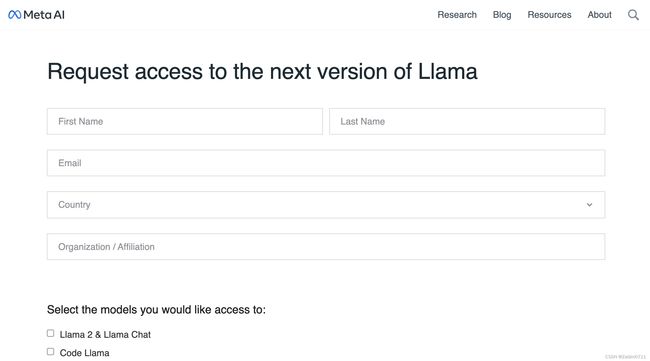 填写完邮件等信息后Meta会秒回信息所填邮箱中。
填写完邮件等信息后Meta会秒回信息所填邮箱中。
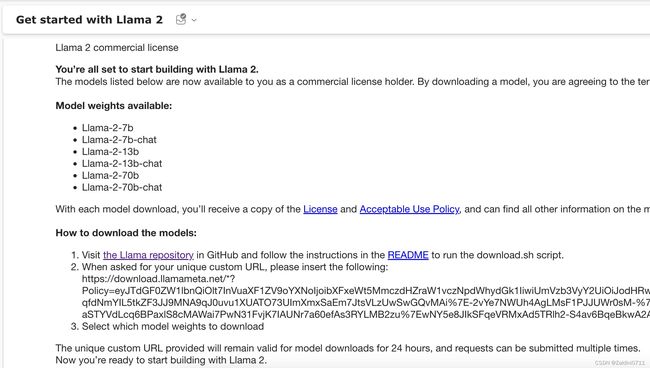
根据邮件的指引,到llama2的repo下先clone一下代码
git clone [email protected]:facebookresearch/llama.git之后运行download.sh的脚本,输入上面第2点当中"https://download.llamameta.net"开头的一大串URL字符串,并选择需要下载的模型,由于我的macbook只有8G内存,我们下载7B-chat的模型
cd llama
sh download.sh 过程中出现了一个未查找到md5sum指令的错误,github中的README中也提到了这一点,使用brew安装一下再重新下载就好了
过程中出现了一个未查找到md5sum指令的错误,github中的README中也提到了这一点,使用brew安装一下再重新下载就好了
brew install --build-from-source md5sha1sum下载成功后,文件包括tokenizer的两个文件和一个模型的pytorch权重文件夹
tokenizer的两个文件如下
-
tokenizer.model
-
tokenizer_checklist.chk
模型权重文件会存储在llama-2-7b-chat文件夹下,里面有三个文件
-
checklist.chk
-
consolidated.00.pth
-
params.json
转换模型
我们使用llama.cpp对刚刚下载的pytorch模型进行转换,将模型转换成gguf格式。
首先,拉取一下llama.cpp的repo
git clone https://github.com/ggerganov/llama.cpp.git安装相关的依赖后,使用llama.cpp目录下的convert.py脚本对前面下载的pth模型进行转换,其中convert.py的相关参数说明如下

cd llama.cpp
pip install -r requirements.txt
python convert.py ../llama/llama-2-7b-chat // 换成自己下载的llama-2模型的pth文件所在的文件夹路径运行完将在llama-2-7b-chat路径(即pth文件的统计目录)下生成一个ggml-model-f16.gguf文件。
该文件为一个与原始pth模型相同精度的文件,跟原本的pth文件一样大小都是13.48GB,由于我的环境只有8G内存,我们还需要对模型进行量化。
量化模型
量化以及运行gguf模型需要使用llama.cpp编译后的可执行文件。编译llama.cpp需要3.8版本以上的cmake,可以先安装或者更新一下cmake
brew install --build-from-source cmake之后编译llama.cpp,由于M1支持METAL加速,将cmake的相关配置设置为ON
cd llama.cpp
mkdir build-metal
cd build-metal
cmake -DLLAMA_METAL=ON ..
cmake --build . --config Release编译后可执行文件会在build-metal目录的bin文件夹下,包括main,quantize等一系列可执行文件

之后使用可执行文件quantize进行量化
./bin/quantize 这里有一个小陷阱,如果是使用了conda的环境进行编译的话,编译后的可执行二进制文件可能会是x86_64架构的,这会造成执行quantize时出现“Illegal instruction: 4”的报错。 github中的参考ISSUE为Illegal hardware instruction in quantize step,原因是编译后的可执行文件使用的是x86_64架构,而M1芯片没有相关的指令集。用"file quantize"指令可以查看编译的quantize文件时什么架构的,里面说这种情况下需要退出conda环境,然后重新进行编译。
conda deactivate
make clean
make但是我试了下这样编译出来的quantize文件仍然是x86_64架构的,可能是CMake的时候还需要额外的配置。
![]() 我又试了下官方的另一种编译方式,直接在llama.cpp的目录下进行make编译,试了下这样编译后的可执行文件都是arm64架构的,
我又试了下官方的另一种编译方式,直接在llama.cpp的目录下进行make编译,试了下这样编译后的可执行文件都是arm64架构的,
# 在llama.cpp的目录下执行
LLAMA_METAL=1 make重新编译后查看quantize文件,文件是arm架构的了
file quantize
![]()
之后重新执行前面的quantize指令对模型进行量化就不会报错了。结果如下:
运行模型
运行模型使用编译后的可执行文件main。其中main的参数说明如下,详细版可以查看github中的文档https://github.com/ggerganov/llama.cpp/blob/master/examples/main/README.md
常用选项
-m FNAME, --model FNAME:指定 LLaMA 模型文件的路径(例如models/7B/ggml-model.bin)。-i, --interactive:以交互模式运行程序,允许您直接提供输入并接收实时响应。-ins, --instruct:以指令模式运行程序,这在处理Alpaca模型时特别有用。-n N, --n-predict N:设置生成文本时预测的标记数量。调整此值可以影响生成文本的长度。-c N, --ctx-size N:设置提示上下文的大小。默认值为 512,但 LLaMA 模型是在 2048 的上下文中构建的,这将为较长的输入/推理提供更好的结果。
输入提示
--prompt PROMPT:直接提供提示作为命令行选项。--file FNAME:提供包含一个或多个提示的文件。--interactive-first:以交互模式运行程序并立即等待输入。(下面有更多相关内容。)--random-prompt:从随机提示开始。
交互模式
-i, --interactive:以交互模式运行程序,允许用户进行实时对话或向模型提供特定指令。--interactive-first:以交互模式运行程序并立即等待用户输入,然后开始文本生成。-ins, --instruct:在指令模式下运行程序,该模式专门设计用于羊驼模型,这些模型擅长根据用户指令完成任务。--color:启用彩色输出以在视觉上区分提示、用户输入和生成的文本。
其他选项
-h, --help:显示帮助消息,其中显示所有可用选项及其默认值。这对于检查最新选项和默认值特别有用,因为它们可能会经常更改,并且本文档中的信息可能会过时。--verbose-prompt:在生成文本之前打印提示。--mtest:通过运行一系列测试来测试模型的功能,以确保其正常工作。-ngl N, --n-gpu-layers N:当使用适当的支持(当前是 CLBlast 或 cuBLAS)进行编译时,此选项允许将某些层卸载到 GPU 进行计算。通常会提高性能。-mg i, --main-gpu i:当使用多个 GPU 时,此选项控制将哪个 GPU 用于小张量,对于小张量,在所有 GPU 上分割计算的开销是不值得的。相关 GPU 将使用稍多的 VRAM 来存储临时结果的暂存缓冲区。默认情况下使用 GPU 0。需要 cuBLAS。-ts SPLIT, --tensor-split SPLIT:当使用多个 GPU 时,此选项控制应在所有 GPU 上分割的张量大小。SPLIT是一个以逗号分隔的非负值列表,指定每个 GPU 应按顺序获取的数据比例。例如,“3,2”会将 60% 的数据分配给 GPU 0,将 40% 的数据分配给 GPU 1。默认情况下,数据按 VRAM 的比例进行分割,但这可能不是最佳性能。需要 cuBLAS。-lv, --low-vram:不要分配 VRAM 暂存缓冲区来保存临时结果。以牺牲性能(尤其是即时处理速度)为代价来减少 VRAM 使用。需要 cuBLAS。--lora FNAME:将 LoRA(低阶适应)适配器应用于模型(意味着 --no-mmap)。这使您可以使预训练模型适应特定任务或领域。--lora-base FNAME:可选模型,用作 LoRA 适配器修改的层的基础。该标志与 标志结合使用--lora,并指定适应的基本模型。
测试一下是否可以运行此模型,执行的命令参考llama.cpp目下的examples下的chat.sh
./main -m ../llama/llama-2-7b-chat/ggml-model-q4.gguf -c 512 -b 1024 -n 256 \
--keep 48 --repeat_penalty 1.0 --color -i \
-r "User:" -f prompts/chat-with-bob.txt -ngl 1运行结果如下,记得加上结尾的-ngl 1,这样可以开启gpu加速(不加的话每个词吐出来得非常慢)

延伸应用
llama-cpp-python
llama.cpp是c++库,用于开发llm的应用往往还需要使用Python调用C++的接口。我们将使用llama-cpp-python,这是LLaMA .cpp的Python Binding,它在纯C/ c++中充当LLaMA模型的推理。
首先使用pip安装llama-cpp-python。需要注意的一点是,mac安装时要使用支持arm的python版本,若没有可以使用conda先创建一个环境,如果使用的是x86_64架构的python,则在之后运行服务器的时候又会出现Illegal instructions的问题
CONDA_SUBDIR=osx-arm64 conda create -n python-arm python==3.10 -c conda-forge
conda activate python-arm如果包含GPU加速的话就加上相关的配置,METAL以外的其他加速可以查看github中的介绍https://github.com/abetlen/llama-cpp-python。另外安装llama-cpp-python[server],以启动一个服务器提供HTTP的API
CMAKE_ARGS="-DLLAMA_METAL=on" FORCE_CMAKE=1 pip install -U llama-cpp-python --no-cache-dir
pip install 'llama-cpp-python[server]'之后运行服务器
python -m llama_cpp.server --model llama-2-7b-chat/ggml-model-q4.gguf --n_gpu_layers 1运行后服务默认在本机的8000端口
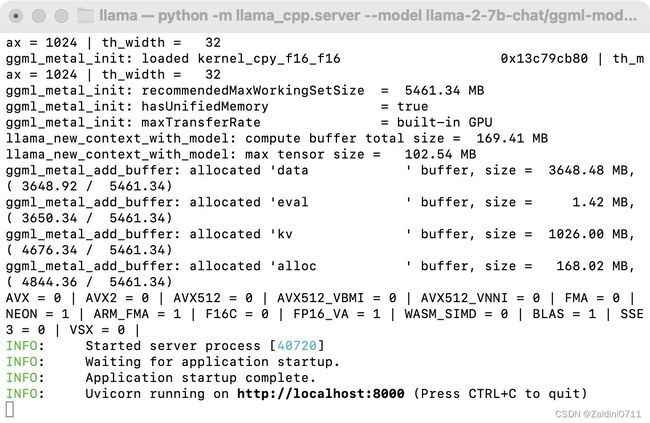 可以通过http://127.0.0.1:8000/docs 查看相关的api文档
可以通过http://127.0.0.1:8000/docs 查看相关的api文档
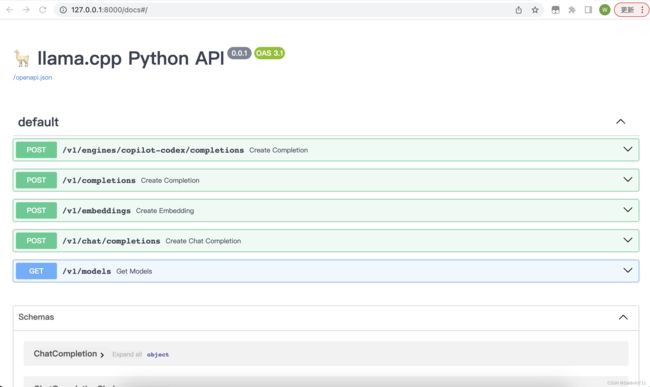
服务器起来后,API的调用跟OpenAI的基本一致
import requests
url = "http://localhost:8000/v1/chat/completions"
headers = {
"accept": "application/json",
"Content-Type": "application/json"
}
data = {
"messages": [
{
"content": "You are a helpful assistant to answer questions related to football.",
"role": "system"
},
{
"content': "Who is Messi?",
"role": "user"
}
]
}
response = requests.post(url, headers=headers, json=data)
print(response.json())
print(response.json()['choices'][0]['message']['content'])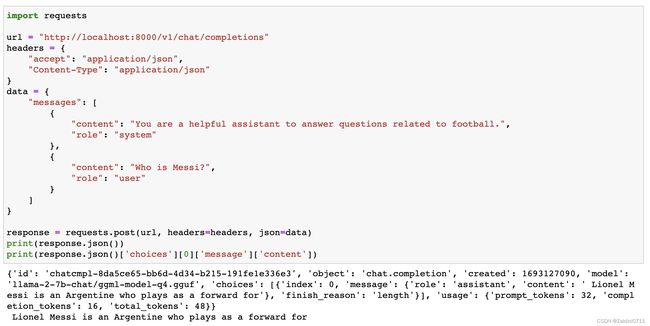 另外也可以用openai的库进行调用,将api_base设置成本地即可
另外也可以用openai的库进行调用,将api_base设置成本地即可
import openai
openai.api_key = ""
openai.api_base = "http://localhost:8000/v1"
response = openai.ChatCompletion.create(
model='chat',
messages=[
{"role": "user", "content": "Who is Trump?"},
],
max_tokens=256,
)
print(response.choices[0]["message"]["content"].strip())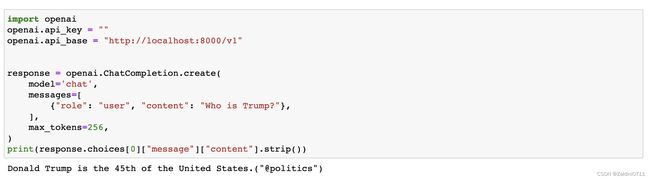
同理也可以用langchain等框架来进行调用
from langchain.chat_models import ChatOpenAI
from langchain.schema import AIMessage, HumanMessage, SystemMessage
llm = ChatOpenAI(openai_api_key = "EMPTY", openai_api_base = "http://localhost:8000/v1", max_tokens=256)
messages = [SystemMessage(content="You are a helpful assistant."),
HumanMessage(content="Which city is the capital of France?")
]
llm(messages)
此外,使用llama-cpp-python部署了服务器之后其也支持embeddings的api
import requests
url = "http://localhost:8000/v1/embeddings"
headers = {
'accept': 'application/json',
'Content-Type': 'application/json'
}
data = {
"input": "The Great Wall is in Beijing."
}
response = requests.post(url, headers=headers, json=data)
print(len(response.json()['data'][0]['embedding']))
print(response.json()['data'][0]['embedding'])text-generation-webui
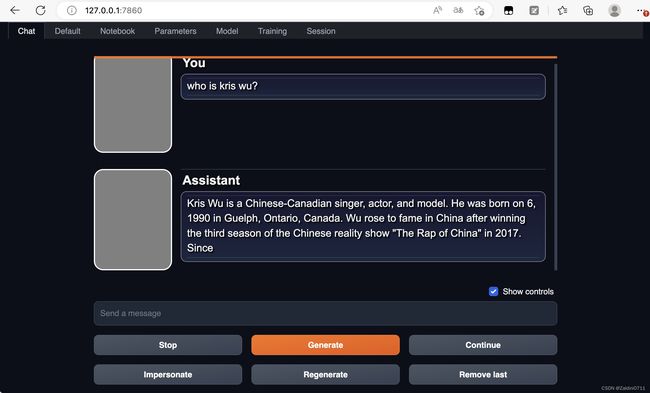
text-generation-webui是一个用于运行类似Chatglm、RWKV-Raven、Vicuna、MOSS、LLaMA、llama.cpp、GPT-J、Pythia、OPT和GALACTICA等大型语言模型的Gradio Web用户界面。
首先拉取github中的repo
git clone https://github.com/oobabooga/text-generation-webui.git安装环境依赖
cd text-generation-webui
pip install -r requirements.txt之后将前面的gguf模型放在text-generation-webui目录的models文件夹下,然后运行服务器
mv ../llama/llama-2-7b-chat/ggml-model-q4.gguf models/
python server.py在Model的Tab页面下选择模型,选择后模型下有相关的参数可以进行选择,选择好后点击load按钮加载模型

之后就可以在Chat的Tab页面下进行问答对话了