一文弄懂 Spring WebFlux 的来龙去脉
概述
本文将通过对 Reactive 以及相关概念的解释引出 Spring-WebFlux,并通过一些示例向读者解释 基于 Spring-WebFlux 如何进行反应式编程实践,同时会讨论相关技术的优缺点及技术原理。
什么是 Reactive
在计算机编程领域,Reactive 一般指的是 Reactive programming。指的是一种面向数据流并传播事件的异步编程范式(asynchronous programming paradigm)
响应式编程最初是为了简化交互式用户界面的创建和实时系统动画的绘制而提出来的一种方法,但它本质上是一种通用的编程范式。
举个例子
在 Excel 里,C 单元格上设置函数 Sum(A+B),当你改变单元格 A 或者单元格 B 的数值时,单元格 C 的值同时也会发生变化。这种行为就是 Reactive
下面的例子我们用了 https://projectreactor.io/ 的 reactor 库,通过这个例子找找感觉:
FluxProcessor publisher = UnicastProcessor.create();
publisher.doOnNext(event -> System.out.println("receive event: " + event)).subscribe();
publisher.onNext(1);
publisher.onNext(2);
// 输出
// receive event: 1
// receive event: 2
追根溯源,说到 Reactive ,就不得不提到 大名鼎鼎的响应式宣言/The Reactive Manifesto(https://www.reactivemanifesto.org),它于 2014 年发表,响应式宣言是一份构建现代云扩展架构的处方。
We believe that a coherent approach to systems architecture is needed, and we believe that all necessary aspects are already recognised individually: we want systems that are Responsive, Resilient, Elastic and Message Driven. We call these Reactive Systems.
这个框架主要使用消息驱动的方法来构建系统,在形式上可以达到弹性和韧性,最后可以产生响应性的价值。
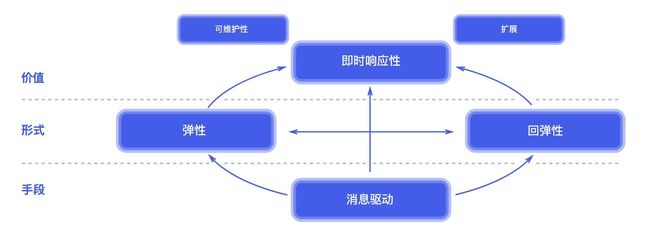
所谓弹性和韧性,通俗来说就像是橡皮筋,弹性是指橡皮筋可以拉长,而韧性指在拉长后可以缩回原样。
解释下上面的关键词:
- 响应性 快速/一致的响应时间。假设在有 500 个并发操作时,响应时间为 1s,那么并发操作增长至 5 万时,响应时间也应控制在 1s 左右。快速一致的响应时间才能给予用户信心,是系统设计的追求。
- 韧性 复制/遏制/隔绝/委托。当某个模块出现问题时,需要将这个问题控制在一定范围内,这便需要使用隔绝的技术,避免连锁性问题的发生。或是将出现故障部分的任务委托给其他模块。韧性主要是系统对错误的容忍。
- 弹性 无竞争点或中心瓶颈/分片/扩展。如果没有状态的话,就进行水平扩展,如果存在状态,就使用分片技术,将数据分至不同的机器上。
- 消息驱动 异步/松耦合/隔绝/地址透明/错误作为消息/背压/无阻塞。消息驱动是实现上述三项的技术支撑。
- 地址透明有很多方法。例如 DNS 提供的一串人类能读懂的地址,而不是 IP,这是一种不依赖于实现,而依赖于声明的设计。再例如 k8s 每个 service 后会有多个 Pod,依赖一个虚拟的服务而不是某一个真实的实例,从何实现调用 1 个或调用 n 个服务实例对于对调用方无感知,这是为分片或扩展做了准备。
- 错误作为消息,这在 Java 中是不太常见的,Java 中通常将错误直接作为异常抛出,而在响应式中,错误也是一种消息,和普通消息地位一致,这和 JavaScript 中的 Promise 类似。
- 背压是指当上游向下游推送数据时,可能下游承受能力不足导致问题,一个经典的比喻是就像用消防水龙头解渴。因此下游需要向上游声明每次只能接受大约多少量的数据,当接受完毕再次向上游申请数据传输。这便转换成是下游向上游申请数据,而不是上游向下游推送数据。
- 无阻塞是通过 no-blocking IO 提供更高的多线程切换效率。
Reactive Programming
响应式编程是一种声明式编程范型
int a, b, sum;
a = 3;
b = 4;
sum = a + b;
a = 6;
b = 7;
System.out.println(sum);
上面是一个命令式编程的例子,先声明两个变量,然后进行赋值,让两个变量相加,得到相加的结果。但接着当修改了最早声明的两个变量的值后,sum 的值不会因此产生变化。
在 Java 9 Flow 中,按相同的思路实现上述处理流程,当初始变量的值变化,最后结果的值也同步发生变化,这就是响应式编程。这相当于声明了一个公式,输出值会随着输入值而同步变化。
SubmissionPublisher publisher = new SubmissionPublisher<>();
publisher.subscribe(new Flow.Subscriber() {
private Integer sum = 0;
Flow.Subscription subscription = null;
@Override
public void onSubscribe(Flow.Subscription subscription) {
this.subscription = subscription;
subscription.request(1);
}
@Override
public void onNext(Integer item) {
subscription.request(1);
sum += item;
}
@Override
public void onError(Throwable throwable) {
}
@Override
public void onComplete() {
System.out.println(sum);
}
});
Arrays.asList(3, 4).stream().forEach(publisher::submit);
publisher.close();
之前有提及消息驱动,消息驱动(Message-driven)和事件驱动(Event-driven)有什么区别呢。
1) 消息驱动有确定的目标,一定会有消息的接受者,而事件驱动是一件事情希望被观察到,观察者是谁无关紧要。消息驱动系统关注消息的接受者,事件驱动系统关注事件源。
2) 在一个使用响应式编程实现的响应式系统中,消息擅长于通讯,事件擅长于反应事实。
Reactive Streams
Reactive Streams(https://www.reactive-streams.org) 提供了一套非阻塞背压的异步流处理标准,主要应用在 JVM、JavaScript 和网络协议工作中。通俗来说,它定义了一套响应式编程的标准。
有了标准,各 Reactor 库的厂商就有了规范,不再各自为战,并且对于上层应用开发者来说可以根据自己的需要选择同一个规范下的各种不同实现库。
The purpose of Reactive Streams is to provide a standard for asynchronous stream processing with non-blocking backpressure.
在 Java 中,有 4 个 Reactive Streams API,在 JUC 的 Flow 类中可以看到:

- Publisher 即事件的发生源,它只有一个 subscribe 方法。其中的 Subscriber 就是订阅消息的对象。
- Subscriber 作为订阅者,有四个方法。onSubscribe 会在每次接收消息时调用,得到的数据都会经过 onNext 方法。onError 方法会在出现问题时调用,Throwable 即是出现的错误消息。在结束时调用 onComplete 方法。
- Subscription 接口用来描述每个订阅的消息。request 方法用来向上游索要指定个数的消息,cancel 方法用于取消上游的数据推送,不再接受消息。
- Processor 接口继承了 Subscriber 和 Publisher,它既是消息的发生者也是消息的订阅者。这是发生者和订阅者间的过渡桥梁,负责一些中间转换的处理。
Thinking in Streams
反应式流所带来的编程思维模式的改变是转为以流为中心。这是从以逻辑为中心到以数据为中心的转换,也是命令式到声明式的转换。
- 传统的命令式编程范式以控制流为核心,通过顺序、分支和循环三种控制结构来完成不同的行为。开发人员在程序中编写的是执行的步骤
- 以数据为中心侧重的是数据在不同组件的流动。开发人员在程序中编写的是对数据变化的声明式反应。
Reactor 库
Reactor Library 从开始到现在已经历经多代。早期如 java.util.Observable 、 rx.NET 、 Reactive4Java ,后来的 Rxjava 、Akka-Streams以及 Project Reactor。
- RxJava 对于开发 Android 应用的同学应该不陌生,比较常用,这种比较著名的库发展了好几个大版本,比如 RxJava1 RxJava2 和 RxJava3
- Project Reactor(Spring 母公司 Pivotal 的项目),实现了完全非阻塞,并且基于网络 HTTP/TCP/UDP 等的背压,即数据传输上游为网络层协议时,通过远程调用也可以实现背压。同时,它还实现了 Reactive Streams API 和 Reactive Extensions,以及支持 Java 8 functional API/Completable Future/Stream /Duration 等各新特性。它也是 Spring 官方反应式编程的默认实现。
从 Reactive 宣言、到 Reactive Streams 规范,再到各种 Reactive 库是很自然的一个脉络,但现实的顺序是:
- 先有了宣言(思想)
- 然后有了根据思想开发的各种库(实现)
- 为了各个库之间的统一性、可操作性,大家一起协商出了 Reactive Streams 规范。继而这些已经存在的 Reactive 库便改进自己的 API 设计,向 Reactive Streams 规范靠拢并提供各种转化 API 让用户在原生 API 和 Reactive Streams 接口直接转换。
来看个例子:
List words = Arrays.asList(
"the", "quick", "brown", "fox",
"jumped", "over", "the", "lazy", "dog");
Flux.fromIterable(words)
.flatMap(word -> Flux.fromArray(word.split("")))
.concatWith(Mono.just("s")).distinct().sort()
.zipWith(Flux.range(1, Integer.MAX_VALUE),
(string, count) ->
String.format("%2d. %s", count, string)
)
.subscribe(System.out::println);
首先定义了一个 words 的数组,然后使用 flatMap 做映射,再将每个词和 s 做连接,得出的结果和另一个等长的序列进行一个 zipWith 操作,最后打印结果。这和 Java 8 Stream 非常类似,但仍存在一些区别:
1) Stream 是 pull-based,下游从上游拉数据的过程,它会有中间操作例如 map 和 reduce,和终止操作例如 collect 等,只有在终止操作时才会真正的拉取数据。Reactive 是 push-based,可以先将整个处理数据量构造完成,然后向其中填充数据,在出口处可以取出转换结果。
2) Stream 只能使用一次,因为它是 pull-based 操作,拉取一次之后源头不能更改。但 Reactive 可以使用多次,因为 push-based 操作像是一个数据加工厂,只要填充数据就可以一直产出。
3) Stream#parallel() 使用 fork-join 并发,就是将每一个大任务一直拆分至指定大小颗粒的小任务,每个小任务可以在不同的线程中执行,这种多线程模型符合了它的多核特性。Reactive 使用 Event loop,用一个单线程不停的做循环,每个循环处理有限的数据直至处理完成。
这里有个网站,一共 12 节,每一节都有讲解和代码示例,是基于 Reactor 3 的,可以用来练习 Reactive Programing :https://tech.io/playgrounds/929/reactive-programming-with-reactor-3/Intro
Backpressure
上面我们提到了 BackPressure,即背压或回压。Backpressure 是一种现象:当数据流从上游生产者向下游消费者传输的过程中,上游生产速度大于下游消费速度,导致下游的 Buffer 溢出,这种现象就叫做 Backpressure。
上游生产数据,生产完成后通过管道将数据传到下游,下游消费数据,当下游消费速度小于上游数据生产速度时,数据在管道中积压会对上游形成一个压力,这就是 BackpressureBackpressure 会出现在有 Buffer 上限的系统中,当出现 Buffer 溢出的时候,就会有 Backpressure,对于 Backpressure,它的应对措施只有一个:丢弃新事件。那么什么是 Buffer 溢出呢?例如我的服务器可以同时处理 2000 个用户请求,那么我就把请求上限设置为 2000,这个 2000 就是我的 Buffer,当超出 2000 的时候,就产生了 Backpressure。
Backpressure 问题在 Flow API 中得到了很好的解决。
Subscriber 会将 Publisher 发布的数据缓存在 Subscription 中,其长度默认为 256,一旦超出这个数据量,publisher 就会降低数据发送速度。通过一个例子了解一下:
public static void backPressureTest() {
SubmissionPublisher publisher = new SubmissionPublisher<>();
Flow.Subscriber subscriber = new Flow.Subscriber() {
private Flow.Subscription subscription;
@Override
public void onSubscribe(Flow.Subscription subscription) {
this.subscription = subscription;
//向数据发布者请求一个数据
this.subscription.request(1);
}
@Override
public void onNext(String item) {
System.out.println("接收到 publisher 发来的消息了:" + item);
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
this.subscription.request(1);
}
@Override
public void onError(Throwable throwable) {
//出现异常,就会来到这个方法,此时直接取消订阅即可
this.subscription.cancel();
}
@Override
public void onComplete() {
//发布者的所有数据都被接收,并且发布者已经关闭
System.out.println("数据接收完毕");
}
};
publisher.subscribe(subscriber);
for (int i = 0; i < 500; i++) {
System.out.println("i--------->" + i);
publisher.submit("hello:" + i);
}
//关闭发布者
publisher.close();
}
这里我们发布 500 条数据,由于 Flow 的缓存大小是 256 ,所以前 256 条数据很快就生产出来进入缓存队列了:
static final int DEFAULT_BUFFER_SIZE = 256;
由于消费的比较慢(我们手动 Sleep 了 2 秒) this.subscription.request(1) 只能一条一条消费,所以效果就是一条一条消费,消费一条,生产一条。
最好自己在本地跑一下代码,感受一下 backpressure
R2DBC
Reactive 本来不支持 JDBC。最根本的原因是,JDBC 不是 non-blocking 设计。不过这个事情也正在推进和发展过程中,比如 r2dbc ( https://r2dbc.io/) 项目。
R2DBC 是 Reactive Relational Database Connectivity 的首字母缩写词。 R2DBC 是一个 API 规范倡议,它声明了一个响应式 API,由驱动程序供应商实现,并以响应式编程的方式访问他们的关系数据库。
R2DBC基于Reactive Streams反应流规范,它是一个开放的规范,为驱动程序供应商和使用方提供接口(r2dbc-spi),与JDBC的阻塞特性不同,它提供了完全反应式的非阻塞API与 [关系型数据库] 交互。
目前 R2DBC 支持的数据库如下:
- cloud-spanner-r2dbc - driver for Google Cloud Spanner.
- jasync-sql - R2DBC wrapper for Java & Kotlin Async Database Driver for MySQL and PostgreSQL (written in Kotlin).
- oracle-r2dbc - native driver implemented for Oracle.
- r2dbc-h2 - native driver implemented for H2 as a test database.
- r2dbc-mariadb - native driver implemented for MariaDB.
- r2dbc-mssql - native driver implemented for Microsoft SQL Server.
- r2dbc-mysql - native driver implemented for MySQL.
- r2dbc-postgresql - native driver implemented for PostgreSQL.
很多同学可能会关心事务的事儿,R2DBC 也是支持事务的
什么是 Spring-WebFlux
相信有了前文对 Reactive 的铺垫,了解 Spring-WebFlux 会比较容易了。
Spring 5.0 添加了 Spring-WebFlux 模块将默认的 web 服务器改为 Netty,支持 Reactive 应用,它的特点是:
- 完全非阻塞式的(non-blocking)
- 支持 Reactive Stream 背压(Reactive Streams back pressure)
- 运行在 Netty, Undertow, and Servlet 3.1+ 容器
对比 Spring MVC
Spring MVC 构建于 Servlet API 之上,使用的是同步阻塞式 I/O 模型,什么是同步阻塞式 I/O 模型呢?就是说,每一个请求对应一个线程去处理。
Spring WebFlux 是一个异步非阻塞式 IO 模型,通过少量的容器线程就可以支撑大量的并发访问,所以 Spring WebFlux 可以有效提升系统的吞吐量和伸缩性,特别是在一些 IO 密集型应用中,Spring WebFlux 的优势明显。例如微服务网关 Spring Cloud Gateway 就使用了 WebFlux,这样可以有效提升网管对下游服务的吞吐量。
Spring WebFlux 与 Spring MVC 的关系如下图
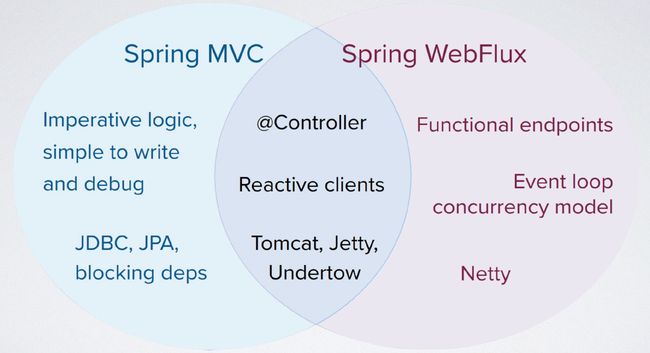
可见,Spring WebFlux 并不是为了替代 Spring MVC 的,它与 Spring MVC 一起形成了两套 WEB 框架。两套框架有交集比如对 @Controller 注解的使用,以及均可使用 Tomcat、Jetty、Undertow 作为 Web 容器。
Spring MVC 还是 WebFlux?
针对这个问题,官方认为两者并不是二元对立的,他们可以并排使用,两者一起工作以扩大可用选项的范围。
我们来看看官方给的具体建议:
- 如果已经有了一个运行良好的 SpringMVC 应用程序,则无需更改。命令式编程是编写、理解和调试代码的最简单方法,我们可以选择最多的库,因为从历史上看,大多数都是阻塞的。
- 如果是个新应用且决定使用 非阻塞 Web 技术栈,那么 WebFlux 是个不错的选择。
- 对于使用 Java8 Lambda 或者 Kotlin 且 要求不那么复杂的小型应用程序或微服务来说,WebFlux 也是一个不错的选择
- 在微服务架构中,可以混合使用 SpringMVC 和 Spring WebFlux,两个都支持基于注解的编程模型
- 评估应用程序的一种简单方法是检查其依赖关系。如果要使用阻塞持久性 API(JPA、JDBC)或网络 API,那么 Spring MVC 至少是常见架构的最佳选择
- 如果有一个调用远程服务的 Spring MVC 应用程序,请尝试响应式
WebClient - 对于一个大型团队,向非阻塞、函数式和声明式编程转变的学习曲线是陡峭的。在没有全局开关的情况下,想启动 WebFlux,可以先使用 reactive
WebClient。此外,从小处着手并衡量收益。我们预计,对于广泛的应用,这种转变是不必要的。
这里最后一点的意思是要仔细通过技术原理(非阻塞 IO、并发性能、吞吐量…)来评估 WebFlux 究竟能为我们带来多少益处,同时评估为了获得这些好处所要付出的学习和改造成本,然后衡量收益,如果收益大值得一试,否则不建议动。
个人认为对于日常用 SpringMVC 开发的业务应用不用换 Spring-WebFlux,因为 SpringMVC 是同步阻塞式模型,对于应用的开发、调试、测试都比较友好,反过来这些点在非阻塞模型的 WebFlux 中就变成了缺点。
为什么要用 WebFlux
为什么要用 WebFlux ?或者换句话说 WebFlux 有什么优点?
首先是吞吐量
随着每个请求的被处理时间越长、并发请求的量级越大,WebFlux 相比 SpringMVC 的整体吞吐量高的越多,平均的请求响应时间越短。如下图所示
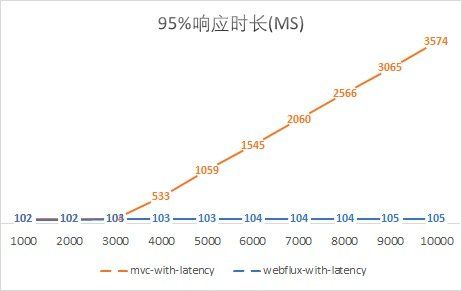
吞吐量大了,意味着单位时间内可以处理的请求数变多了,比如原来 1w 个请求 10 秒处理完,现在 10w 个请求也是 10 秒处理完,就代表吞吐上去了。注意,是吞吐上去了,不代表单次请求快了,单次请求的速度和原来一样。
非阻塞
传统阻塞 IO 模型的不足包括
- 每个连接都需要独立线程处理,当并发数大时,创建线程数多,占用资源
- 采用阻塞 IO 模型,连接建立后,若当前线程没有数据可读,线程会阻塞在读操作上,造成资源浪费
针对传统阻塞 IO 模型的两个问题,可以采用如下的方案
- 基于池化思想,避免为每个连接创建线程,连接完成后将业务处理交给线程池处理
- 基于 IO 复用模型,多个连接共用同一个阻塞对象,不用等待所有的连接。遍历到有新数据可以处理时,操作系统会通知程序,线程跳出阻塞状态,进行业务逻辑处理
Netty 所用的 Reactor 线程模型,就解决了阻塞 IO 的问题,具体来讲,它使用的是主从 Reactor 多线程模型
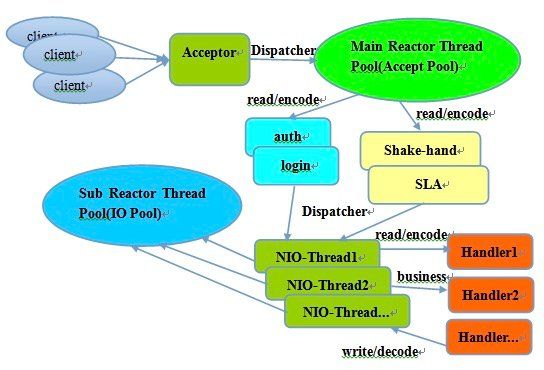
同时 Netty 自身也很好地利用了 IO 多路复用、epoll 优化、零拷贝等技术,极大程度上优化了 IO 的性能。我们知道 SpringWebFlux 底层也依赖了 Netty ,所以也获得了 Netty 带来的优势。这一点可以概括为应用的弹性或伸缩性。根据实际请求量的大小进行资源的伸缩。
Mono Flux
前提:这里的例子使用的框架是 SpringBoot ,版本为 2.3.12.RELEASE 相应的 Spring 的大版本是 5,JDK 11
我们用两个最简单的例子,演示下用 Spring WebFlux 怎么写 Web 的 controller
当然首先要添加相关依赖
org.springframework.boot
spring-boot-starter-webflux
@RestController
@RequestMapping("/webflux")
public class HelloController {
@GetMapping("/hello")
public Mono hello() {
return Mono.just("Hello Spring Webflux");
}
}
> curl http://localhost:8080/webflux/hello
Hello Spring Webflux
我们再来一个返回对象列表的例子:
@GetMapping("/posts")
public Flux posts() {
WebClient webClient = WebClient.create();
Flux postFlux = webClient.get().uri("http://jsonplaceholder.typicode.com/posts").retrieve().bodyToFlux(Post.class);
return postFlux;
}
@NoArgsConstructor
@Data
public class Post {
private Integer userId;
private Integer id;
private String title;
private String body;
}
浏览器请求 http://localhost:8080/webflux/posts ,得到

解释一下这个例子,WebClient 是 Spring5 以后提供的,可以替代 RestTemplate,我们利用 WebClient 请求 jsonplaceholder 提供的 json 对象数组,将返回的结果映射成为 Post 对象,然后直接将 Post 对象列表返回给客户端。
有关 WebClient 的具体 API 这里先不做过多解释,我们看一下 Mono 和 Flux 这两个陌生的类。在 WebFlux 中 他们均能充当响应式编程中发布者的角色,不同的是:
Mono:返回 0 或 1 个元素,即单个对象。Flux:返回 N 个元素,即 List 列表对象。
此外,在应用启动后,通过 IDEA 的控制台可以明显看到 Server 已经不是 Tomcat 了,而是 Netty
![]()
如果你没有看到 Netty 还是 Tomcat 的话,可能是你的pom.xml 中同时包含了以下两个依赖:
org.springframework.boot
spring-boot-starter-web
org.springframework.boot
spring-boot-starter-webflux
解决的方案是去掉 spring-boot-starter-web 依赖,这样 Server 就切换到了 Netty。
Stream
既然叫 Reactive Stream 我们就用下面一个例子 找一找流的感觉:
@GetMapping(value = "/flux", produces = MediaType.TEXT_EVENT_STREAM_VALUE)
public Flux flux() {
Flux flux = Flux.fromArray(new String[]{"a", "b", "c", "d"}).map(s -> {
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
return "";
});
return flux;
}
看下效果:

浏览器每隔一秒显示下一条数据,这正是流的效果,是不是有点儿像 WebSocket ?其实并不完全一样。奥妙在这里 text/event-stream,这其实也是服务器向浏览器推送消息的一种方案。感兴趣的同学可以搜索一下 WebSocket 和 SSE 的区别。
请求分发
Spring MVC 的前端控制器是 DispatcherServlet, 而 WebFlux 是 DispatcherHandler,它实现了 WebHandler 接口,主要看 handle 方法
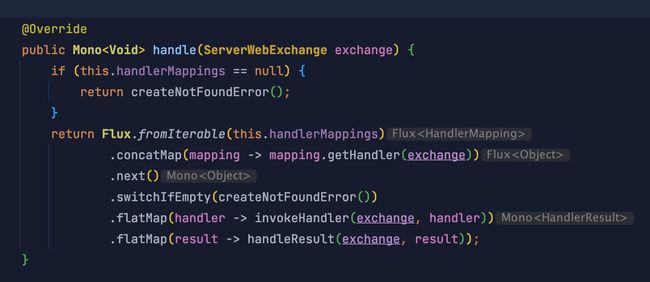
DB
有文章说,WebFlux 还不支持 MySQL ,可能是文章发布的较早,当时 R2DBC 没来得及支持那么多的数据库,只支持了 MongoDB 和 PostgreSQL 等几个。现在这个时间点 R2DBC 支持的数据库就比较多了,也包含了 MySQL(参数上文)
Spring Data R2DBC 可以与 Spring Data JPA 结合使用,其实 R2DBC 与原来的 JPA 使用方式差别不大,使用非常简单。
只是 Spring Data JPA 中方法返回的是真实的值,而 R2DBC 中,返回的是数据流Mono,Flux。
更多 R2DBC 的介绍,可以参考 Spring 的官方文档:https://docs.spring.io/spring-data/r2dbc/docs/1.3.2/reference/html/#r2dbc.core
有兴趣的同学可以用 Spring WebFlux + R2DBC+MySQL ,实现一下 CRUD 操作。就是一个从头到尾彻彻底底的响应式非阻塞应用。
WebClient
Spring 5 引入了新的 WebClientAPI,取代了现有的 RestTemplate 客户端。使用 WebClient 您可以使用功能流畅的 API 发出同步或异步 HTTP 请求,该 API 可以直接集成到您现有的 Spring 配置和 WebFlux 反应式框架中。
一个例子:
private static void testWebClient() {
WebClient webClient = WebClient.create();
monoTest(webClient, "http://jsonplaceholder.typicode.com/posts/1");
}
/**
* 从 API 获取单个帖子
*/
private static void monoTest(WebClient webClient, String uri) {
//要注意此时实际上还没有发送任何请求!作为一个反应式 API,在某些尝试读取或等待响应之前,不会实际发送请求。
Mono postMono = webClient.get().uri(uri).retrieve().bodyToMono(Post.class);
Post post1 = postMono.blockOptional().get();
log.info(post1.getTitle());
}
上面的是 Mono 的,再来一个 Flux 的(获得 post list 并将 id 求和):
/**
* 获取 post 列表 ,使用 Flux 因为是多值 , 要是获取一个对象比如 `posts/1` 就可以用 Mono
*
* @param webClient
* @param uri
*/
private static void fluxTest(WebClient webClient, String uri) {
// retrieve() 方法是获取响应主体并对其进行解码
Flux postFlux = webClient.get().uri(uri).retrieve().bodyToFlux(Post.class);
List posts = postFlux.collectList().block();
Integer idSum = posts.stream().mapToInt(post -> post.getId()).reduce(0, (a, b) -> a + b);
log.info(idSum);
}
总结
Reactive Programming 作为观察者模式(Observer) 的延伸,不同于传统的命令编程方式( Imperative programming)同步拉取数据的方式,如迭代器模式(Iterator) 。而是采用数据发布者同步或异步地推送到数据流(Data Streams)的方案。
当该数据流(Data Steams)订阅者监听到传播变化时,立即作出响应动作。在实现层面上,Reactive Programming 可结合函数式编程简化面向对象语言语法的臃肿性,屏蔽并发实现的复杂细节,提供数据流的有序操作,从而达到提升代码的可读性,以及减少 Bugs 出现的目的。同时,Reactive Programming 结合背压(Backpressure)的技术解决发布端生成数据的速率高于订阅端消费的问题。
如果说 Spring Cloud 是从【宏观系统层面的开发】角度在实践健壮的高可用系统+系统运维,K8S 在【DEV OPS】层面实践更好的系统运维,Service Mesh 在【基础设施层(infra)】实践健壮的高可用系统+系统运维,那么 WebFlux(包括整个 Reactive Stack 体系的其他成员)就是从【微观项目层面的开发】角度在实践健壮的高可用系统+系统运维。或多或少,它们都从各个维度在朝着“更少的人治”角度去努力。
GitHub 地址
代码示例我放到了 github 上 :https://github.com/xiaobox/Spring-WebFlux-Demo
参考
- https://juejin.cn/post/6844903552905641991
- https://www.jianshu.com/p/15d0a2bed6da
- https://www.jdon.com/56547
- https://segmentfault.com/a/1190000017548728
- https://www.reactivemanifesto.org/
- https://www.yisu.com/zixun/96685.html
- https://mp.weixin.qq.com/s/BfgQ760h_WeUOBRrgx1ubA
- https://docs.spring.io/spring-data/r2dbc/docs/1.3.2/reference/html/#r2dbc.core
- https://tech.io/playgrounds/929/reactive-programming-with-reactor-3/Intro