WebMagic抓取医院科室,医生信息实战及踩坑
简介
WebMagic项目代码分为核心和扩展两部分。核心部分(webmagic-core)是一个精简的、模块化的爬虫实现,而扩展部分则包括一些便利的、实用性的功能。WebMagic的架构设计参照了Scrapy,目标是尽量的模块化,并体现爬虫的功能特点。
WebMagic概览
使用场景
我用WebMagic抓取公立医院的科室,科室详情,医生,医生详情信息,爬虫技术玩玩还可以,实际应用需谨慎。
实战
先放一篇参考博客WebMagic,我主要参考这篇博客进行的开发,在此基础上进行的修改,并且踩了不少坑,记录一下
集成
首先是pom.xml
<?xml version="1.0" encoding="UTF-8"?>
://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
>4.0.0 >
>
>org.springframework.boot >
>spring-boot-starter-parent >
>2.7.5 >
> <!-- lookup parent from repository -->
com.example
WebMagicDemo
0.0.1-SNAPSHOT
WebMagicDemo
WebMagicDemo
8
org.springframework.boot
spring-boot-starter
>
>org.springframework.boot >
>spring-boot-starter-test >
>test >
>
>
>org.projectlombok >
>lombok >
>
<!--WebMagic-->
us.codecraft
webmagic-core
0.8.0
>
>
>us.codecraft >
>webmagic-extension >
>0.8.0 >
>
>
>com.google.guava >
>guava >
>31.1-jre >
>
>
>com.alibaba >
>easyexcel >
>3.3.2 >
>
<!--测试组件-->
org.springframework.boot
spring-boot-starter-test
org.jsoup
jsoup
1.15.4
<!--selenium依赖-->
org.seleniumhq.selenium
selenium-java
4.8.1
guava
com.google.guava
okio
com.squareup.okio
>
>
>
>
>org.springframework.boot >
>spring-boot-maven-plugin >
>
>
>
>
其中easyexcel可选,不需要生成excel不需要集成
JdChromeDownloader
@Component
public class JdChromeDownloader implements Downloader
{
//声明驱动
private RemoteWebDriver driver;
public JdChromeDownloader() {
//第一个参数是使用哪种浏览器驱动
//第二个参数是浏览器驱动的地址
System.setProperty("webdriver.chrome.driver","C:\\Users\\Administrator\\AppData\\Local\\Google\\Chrome\\Application\\chromedriver.exe");
//创建浏览器参数对象
ChromeOptions chromeOptions = new ChromeOptions();
// 设置为 headless 模式,上课演示,或者学习不要打开
// chromeOptions.addArguments("--headless");
// 设置浏览器窗口打开大小
chromeOptions.addArguments("--window-size=1280,700");
//设置自动化启动时,不显示正在受到自动化软件控制的提示栏
chromeOptions.setExperimentalOption("excludeSwitches", new String[] {"enable-automation","load-extension"});
//针对反爬机制,把浏览器不标记为webdriver启动的浏览器。
chromeOptions.addArguments("--disable-blink-features=AutomationControlled");
chromeOptions.addArguments("no-sandbox");
chromeOptions.addArguments("disable-dev-shm-usage");
chromeOptions.addArguments("--remote-allow-origins=*");
//创建驱动
this.driver = new ChromeDriver(chromeOptions);
}
@Override
public Page download(Request request, Task task) {
try {
driver.get(request.getUrl());
Thread.sleep(2000);
//无论是搜索页还是详情页,都滚动到页面底部,所有该加载的资源都加载
//需要滚动到页面的底部,获取完整的商品数据
driver.executeScript("window.scrollTo(0, document.body.scrollHeight - 1000)");
Thread.sleep(2000l);
//获取页面对象
Page page = createPage(request.getUrl(), driver.getPageSource());
//判断是否是搜索页
if (request.getUrl().contains("search")) {
//如果请求url包含search,说明是搜索结果页
//在搜索结果页,需要获取下一页的链接地址
//点击下一页按钮,在下一页中获取当前页的url(就是下一页的url),放到任务队列中
WebElement next = driver.findElement(By.cssSelector("a.pn-next"));
//点击
next.click();
//获取当前页面(其实就是下一页)的url地址
String nextUrl = driver.getCurrentUrl();
//使用page对象,把下一页url放到任务列表中
page.addTargetRequest(nextUrl);
}
//关闭浏览器
//driver.close();
return page;
} catch (InterruptedException e) {
e.printStackTrace();
}
return null;
}
@Override
public void setThread(int threadNum) {
}
//构建page返回对象
private Page createPage(String url, String content) {
Page page = new Page();
page.setRawText(content);
page.setUrl(new PlainText(url));
page.setRequest(new Request(url));
page.setDownloadSuccess(true);
return page;
}
}
StartCrawler
@Component
public class StartCrawler
{
//@Resource
//private JdChromeDownloader downloader;
@Resource
private MyPipeline jpaPipeline;
@Resource
private DeptPipeline deptPipeline;
@Resource
private DoctorPipeline doctorPipeline;
//声明医院科室
String url = "http://xxxxxx/keshi/";
//声明医院专家
String doctorsUrl="http://xxxxxx/zhuanjia/";
@Scheduled(cron = "0/5 * * * * *")
public void run() {
Spider.create(new WxhsDoctorProcessor())
//.addUrl("https://www.jd.com/news.html?id=38673")
.addUrl(doctorsUrl)
//设置下载器
// .setDownloader(downloader)
// .addPipeline(new JsonFilePipeline("D:\\webmagic\\"))
.addPipeline(doctorPipeline)
.run();
}
}
这个文件的作用,是5秒钟调用一次爬虫
坑1 集成完毕,运行环境,报“An attempt was made to call a method that does not exist. The attempt was made from the following location”
这个是 maven 版本冲突问题,解决的办法很简单
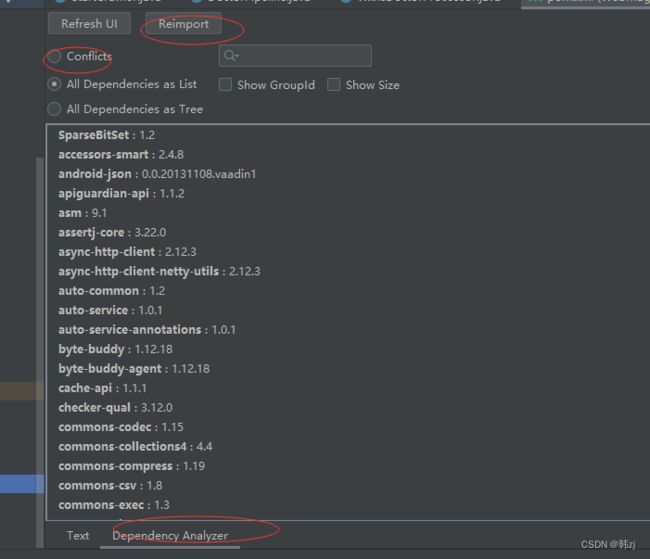
dea 安装 mavenhelper 插件,点开 pom.xml 文件 =》 左下角有 text 和 Dependency Analyzer , 点 Dependency Analyzer, 选中 Conflicts ,选中需要解决的冲突 ==》 鼠标右键,exclude; 如果不是根的话就,Jump left Tree 之后再 exclude,reimport 就好了
Selenium+headless浏览器实现动态爬虫
我们可以使用HttpClient模拟浏览器抓取静态html,但是对js的解析部分还是很薄弱。虽然我们可以读取js的运作机制并且找到相关数据,但是这样会耗费大量时间。为了解决这个问题我们可以使用工具来模拟浏览器的运行,直接获取解析结果。这就是使用Selenium+headless浏览器来实现动态爬虫。
Selenium
Selenium是一个用于Web应用程序测试的工具。Selenium可以使用代码控制浏览器,就像真正的用户在操作一样。而对于爬虫来说,使用Selenium操控浏览器来爬取网上的数据那么肯定是爬虫中的杀手武器。Selenium支持多种浏览器可以是chrome、Firefox、PhantomJS等使用WebDriver在Chrome浏览器上进行测试时或者做页面抓取,需要从http://chromedriver.storage.googleapis.com/index.html网址中下载与本机chrome浏览器对应的驱动程序,驱动程序名为chromedriver。chromedriver的版本需要和本机的chrome浏览器对应,才能正常使用,一般情况下下载最新版就可以了。
headless浏览器是一个基于webkit内核的无头浏览器,即没有UI界面,即它就是一个浏览器,只是其内的点击、翻页等人为相关操作需要程序设计实现
如果想要实现动态爬虫,需要安装chromedriver,可以在浏览器驱动官网网站和淘宝镜像网站下载,先查看浏览器版本,
然后下载对应的驱动chromedriver.exe,放到浏览器安装目录下,在Downloader文件中进行设置,然后设置Spider的下载器 .setDownloader(downloader),这样运行起来,会调起浏览器,模拟点击动作
坑2浏览器驱动相关问题
我浏览器版本是118,然后驱动最高是114,所以我只能卸载浏览器,然后重新安装的114的,但是会自动升级成最新版本,所以要关闭谷歌浏览器的自动更新功能。关闭方法在这谷歌浏览器自动更新怎么关闭
如果不想要这个功能,可以把代码中的JdChromeDownloader 的@Component去掉,然后把.setDownloader(downloader)去掉就可以了
item
科室信息
@Data
public class DeptItem
{
private String deptType;
private String title;
private String url;
private String deptDetails;
}
医生信息
@Data
public class DoctorItem
{
private String doctorType;
private String name;
private String url;
private String img;
private HashMap<String,String> doctorDetails;
}
pipeline
@Component
public class DoctorPipeline implements Pipeline
{
private final static Logger log = LoggerFactory.getLogger(DoctorPipeline.class);
@Override
public void process(ResultItems resultItems, Task task)
{
//获取医生数据
List<DeptItem> itemList = resultItems.get("itemList");
log.info("解析医生结果"+itemList);
}
}
@Component
public class DeptPipeline implements Pipeline
{
private final static Logger log = LoggerFactory.getLogger(DeptPipeline.class);
String filePath=TestFileUtil.getPath();
File templateFile = new File(filePath, "科室介绍临时表.xlsx");
File destFile = new File(filePath, "科室介绍.xlsx");
private List<DeptItem> results=new ArrayList();
@Override
public void process(ResultItems resultItems, Task task)
{
//获取科室数据
List<DeptItem> itemList = resultItems.get("itemList");
boolean deptDetail=resultItems.get("deptDetail");
if(!deptDetail){
//String fileName = TestFileUtil.getPath() + "科室" + System.currentTimeMillis() + ".xlsx";
//EasyExcel.write(fileName, DeptData.class).sheet("科室").doWrite(itemList);
log.info("解析科室结果"+itemList);
}else {
//先缓存到本地,实际可以写入数据库
// results.addAll(itemList);
log.info("解析科室介绍结果"+itemList);
}
}
}
重点是网页解析
通过继承PageProcessor来进行网页解析,先看一下科室信息

对应的样式是

这一段是比较好解析的,
//科室名称
Selectable selectable = page.getHtml()
.css("div.right_bottom");
List<Selectable> nodes = selectable.css("ul.ksxhul")
.nodes();
List<Selectable> deptTypes = selectable.xpath("//dl/dt/a/strong/text()")
.nodes();
//判断nodes是否有值
if (nodes != null && nodes.size() > 0)
{
List<DeptItem> itemList = new ArrayList<>();
for (int i = 0; i < nodes.size(); i++)
{
List<Selectable> ksList = nodes.get(i)
.css("li.keshili")
.nodes();
for (Selectable ks : ksList)
{
//创建对象
DeptItem item = new DeptItem();
if (i < deptTypes.size() && deptTypes.get(i) != null)
{
item.setDeptType(deptTypes.get(i)
.toString());
}
item.setUrl(ks.links()
.toString());
item.setTitle(ks.$("a", "text")
.toString());
//放到集合中
itemList.add(item);
//把商品详情页的url放到url任务队列中
page.addTargetRequest(item.getUrl());
}
}
//把需要持久化的数据放到ResultItems中
page.putField("itemList", itemList);
page.putField("deptDetail", false);
}
解析出来的结果是

点击科室,进入科室详情,这个比较复杂,有多种样式,粗略数了数,得十种样式,这样的话,还真不如粘贴复制来得快。我需要把页面里的内容分类

按照“【科室概况】”,“【科室特色】”,“【科研及教育概况】”,“【获得的荣誉称号】”等取出相应的内容,保存到数据库,这是一种样式,比较好解析。里边内容的html标签就筛选掉吧,如果再去解析,实在是太复杂了
//去除html标签
private String delHTMLTag(String htmlStr){
String regEx_script="]*?>[\\s\\S]*?<\\/script>" ; //定义script的正则表达式
String regEx_style="]*?>[\\s\\S]*?<\\/style>" ; //定义style的正则表达式
String regEx_html="<[^>]+>"; //定义HTML标签的正则表达式
Pattern p_script=Pattern.compile(regEx_script,Pattern.CASE_INSENSITIVE);
Matcher m_script=p_script.matcher(htmlStr);
htmlStr=m_script.replaceAll(""); //过滤script标签
Pattern p_style=Pattern.compile(regEx_style,Pattern.CASE_INSENSITIVE);
Matcher m_style=p_style.matcher(htmlStr);
htmlStr=m_style.replaceAll(""); //过滤style标签
Pattern p_html=Pattern.compile(regEx_html,Pattern.CASE_INSENSITIVE);
Matcher m_html=p_html.matcher(htmlStr);
htmlStr=m_html.replaceAll(""); //过滤html标签
return htmlStr.trim(); //返回文本字符串
}
Selectable trs = page.getHtml()
.xpath("//div[@class=contents]/table/tbody/tr");
HashMap<String, String> deptDetail = new HashMap<>();
if (trs != null && trs.nodes()
.size() > 0)
{
for (Selectable tr : trs.nodes())
{
List<String> all = tr.xpath("//td/p/span")
.all();
Selectable key = tr.xpath("//td/p/b/span/text()");
if (StringUtils.isNotBlank(key.toString()))
{
String detail = String.join("", all);
String detailNoHtml=delHTMLTag(detail);
Pattern pattern = Pattern.compile(" ");
Matcher matcher = pattern.matcher(detailNoHtml);
String result = matcher.replaceAll("");
deptDetail.put(key.toString(), result);
}
}
}
这样解析出来的数据就是
解析科室介绍结果[DeptItem(deptType=null, title=心血管内科, url=null, deptDetails={【科研及教育概况】=获国家和省市级科研课题资助30余项,包括国家自然科学基金课题资助项目12项,其中面上项目3项,青年基金9项;江苏省自然科学基金资助项目6项。获省、市科技进步奖及医学新技术引进奖29项,其中省级科技进步奖及医学新技术引进奖18项,包括江苏省科技进步三等奖1项,江苏省医学新技术引进一等奖3项,二等奖12项,江苏医学科技奖三等奖2项。近5年来,在SCI及中华系列杂志发表论文100余篇,其中I区和II区SCI论文20余篇,在《中华心血管病杂志》上发表论文30余篇。目前有博士研究生导师1人,硕士研究生导师5人,目前已培养博士和硕士研究生60余名。, 【科室特色】=有冠心病(心内一科)、起搏电生理(心内二科)和普通心脏病(心内三科)和心脏重症监护室(CCU)四个病区,135张床位,并有独立的心功能科和心血管病实验室。设有心血管专科、专家及高级专家门诊及冠心病、起搏和电生理等专病门诊。常规开展磁导航指导下复杂心律失常射频消融术、心脏再同步起搏技术(CRT及CRT-D)、自动复律除颤起搏器植入术(ICD)、希氏束起搏术、埋藏式心脏起搏器植入术、经皮冠状动脉介入(PCI)治疗和先天性心脏病介入治疗术。近年来开展的新技术有房颤冷冻球囊消融术、无导线心脏起搏器植入术、左心耳封堵术、皮下ICD植入术、经导管主动脉瓣置换术(TAVR)。, 【科室概况】=南京医科大学附属无锡人民医院心血管内科为江苏省重点学科建设单位、江苏省首批临床重点专科、南京医科大学重点学科、南京医科大学博士研究生培养点和博士后流动站、国家卫健委首批介入准入资格学科和中国医师协会介入培训基地。拥有无锡市“太湖人才计划”顶级医学专家团队,是无锡市心血管病临床医学中心。心血管内科现有医护人员95人,其中医生41人,护士54人,其中医生高级职称29人,医学博士17人、医学硕士22人,留学归国人员6人。拥有磁导航系统、双C臂DSA、杂交手术室、双源CT、三维电生理标测系统、冠状动脉内超声和食道超声等先进设备。, 【获得的荣誉称号】=2022年获批江苏省心血管内科重点学科建设单位2022年获批房颤中心示范基地2021年获批无锡市医学重点学科2021获批无锡市“太湖人次计划”顶级医学专家团队2019年王如兴获得无锡市“五一”劳动奖章})]
现在发现还有多种样式,比如

这样的样式看着都头大,如果还像之前那样解析,只能说很复杂,现在按最简单的做,就是把内容全部取出来,去掉html标签,然后后期根据业务需求,比如获取“【科研及教育概况】”的数据,可以通过字符串分割来获取
坑3.如何去掉java字符串里的html标签
首先想到的是通过正则表达式来删除,比如
private String delHTMLTag(String htmlStr)
{
String regEx_script = "]*?>[\\s\\S]*?<\\/script>" ; //定义script的正则表达式
String regEx_style = "]*?>[\\s\\S]*?<\\/style>" ; //定义style的正则表达式
String regEx_html = "<[^>]+>"; //定义HTML标签的正则表达式
Pattern p_script = Pattern.compile(regEx_script, Pattern.CASE_INSENSITIVE);
Matcher m_script = p_script.matcher(htmlStr);
htmlStr = m_script.replaceAll(""); //过滤script标签
Pattern p_style = Pattern.compile(regEx_style, Pattern.CASE_INSENSITIVE);
Matcher m_style = p_style.matcher(htmlStr);
htmlStr = m_style.replaceAll(""); //过滤style标签
Pattern p_html = Pattern.compile(regEx_html, Pattern.CASE_INSENSITIVE);
Matcher m_html = p_html.matcher(htmlStr);
htmlStr = m_html.replaceAll(""); //过滤html标签
return htmlStr.trim(); //返回文本字符串
}
然后这样使用
String detailNoHtml = delHTMLTag(detail);
Pattern pattern = Pattern.compile(" ");
Matcher matcher = pattern.matcher(detailNoHtml);
String result=matcher.replaceAll("");
结果,不理想,虽然标签去掉了,但是留下好多空白,这个时候,需要用到Jsoup
Jsoup.parse(detail).text().replace("科室专家)","");
因为我这个网页,最后都有"科室专家)”四个字,是另一个标签的,与内容无关,所以去掉
![]()
我把优化后的科室解析方法发一下
@Component
public class WuxiHospitalPageProcessor implements PageProcessor
{
private final static Logger log = LoggerFactory.getLogger(WuxiHospitalPageProcessor.class);
@Override
public void process(Page page)
{
Selectable top = page.getHtml()
.css("div.right_top", "text");
log.info("getHtml" + top);
//科室详情页
if (StringUtils.isNotBlank(top.toString()) && top.toString()
.contains("内容阅读"))
{
Selectable selectable = page.getHtml()
.css("div.right_bottom");
Selectable title = selectable.css("div.titleks", "text");
String result = null;
List<String> trsOthers = page.getHtml()
.xpath("//div[@class=contents]")
.all();//内容放在pre标签的
result = filterResult(trsOthers);
List<DeptItem> itemList = new ArrayList<>();
DeptItem item = new DeptItem();
item.setDeptDetails(result);
item.setTitle(title.toString());
//放到集合中
itemList.add(item);
//把需要持久化的数据放到ResultItems中
page.putField("itemList", itemList);
page.putField("deptDetail", true);
}
else
{
//科室名称
Selectable selectable = page.getHtml()
.css("div.right_bottom");
List<Selectable> nodes = selectable.css("ul.ksxhul")
.nodes();
List<Selectable> deptTypes = selectable.xpath("//dl/dt/a/strong/text()")
.nodes();
//判断nodes是否有值
if (nodes != null && nodes.size() > 0)
{
List<DeptItem> itemList = new ArrayList<>();
for (int i = 0; i < nodes.size(); i++)
{
List<Selectable> ksList = nodes.get(i)
.css("li.keshili")
.nodes();
for (Selectable ks : ksList)
{
//创建对象
DeptItem item = new DeptItem();
if (i < deptTypes.size() && deptTypes.get(i) != null)
{
item.setDeptType(deptTypes.get(i)
.toString());
}
item.setUrl(ks.links()
.toString());
item.setTitle(ks.$("a", "text")
.toString());
//放到集合中
itemList.add(item);
//把商品详情页的url放到url任务队列中
page.addTargetRequest(item.getUrl());
}
}
//把需要持久化的数据放到ResultItems中
page.putField("itemList", itemList);
page.putField("deptDetail", false);
}
}
}
private String filterResult(List<String> all)
{
String detail = String.join("", all);
//String detailNoHtml = delHTMLTag(detail);
//Pattern pattern = Pattern.compile(" ");
//Matcher matcher = pattern.matcher(detailNoHtml);
//String result=matcher.replaceAll("");
return Jsoup.parse(detail).text().replace("科室专家)","");
}
private String delHTMLTag(String htmlStr)
{
String regEx_script = "]*?>[\\s\\S]*?<\\/script>" ; //定义script的正则表达式
String regEx_style = "]*?>[\\s\\S]*?<\\/style>" ; //定义style的正则表达式
String regEx_html = "<[^>]+>"; //定义HTML标签的正则表达式
Pattern p_script = Pattern.compile(regEx_script, Pattern.CASE_INSENSITIVE);
Matcher m_script = p_script.matcher(htmlStr);
htmlStr = m_script.replaceAll(""); //过滤script标签
Pattern p_style = Pattern.compile(regEx_style, Pattern.CASE_INSENSITIVE);
Matcher m_style = p_style.matcher(htmlStr);
htmlStr = m_style.replaceAll(""); //过滤style标签
Pattern p_html = Pattern.compile(regEx_html, Pattern.CASE_INSENSITIVE);
Matcher m_html = p_html.matcher(htmlStr);
htmlStr = m_html.replaceAll(""); //过滤html标签
return htmlStr.trim(); //返回文本字符串
}
private Site site = Site.me()
.setTimeOut(2000);
@Override
public Site getSite()
{
return site;
}
}
医生的页面简单多了
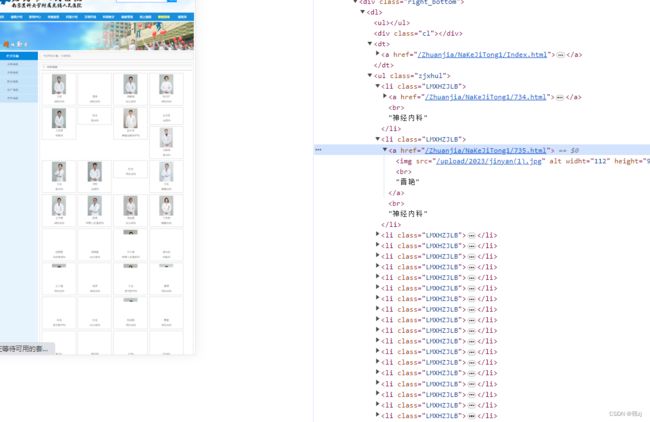
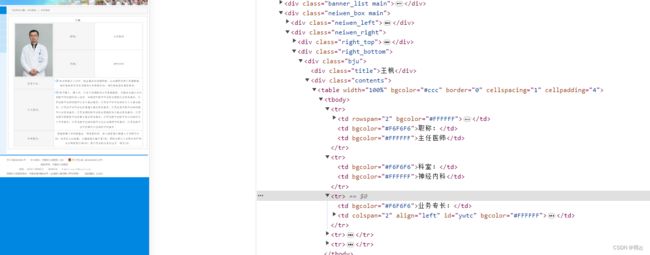
直接贴代码了
/**
* @author hzj 专家列表
* @date 2023/10/16 16:21
*/
public class WxhsDoctorProcessor implements PageProcessor
{
private final static Logger log = LoggerFactory.getLogger(WuxiHospitalPageProcessor.class);
@Override
public void process(Page page)
{
Selectable top = page.getHtml()
.css("div.right_top", "text");
log.info("getHtml" + top);
//医生详情页
if (StringUtils.isNotBlank(top.toString()) && top.toString()
.contains("内容阅读"))
{
Selectable selectable = page.getHtml()
.css("div.right_bottom");
Selectable title = selectable.css("div.title", "text");
Selectable trs = page.getHtml()
.xpath("//div[@class=contents]/table/tbody/tr");
HashMap<String, String> doctorDetail = new HashMap<>();
if (trs != null && trs.nodes()
.size() > 0)
{
for (Selectable tr : trs.nodes())
{
List<Selectable> doctor = tr.xpath("//td/text()").nodes().stream().filter(x->!"".equals(x.toString())).collect(Collectors.toList());
if(doctor.size()==2){
doctorDetail.put(doctor.get(0).toString(), doctor.get(1).toString());
}else{
doctorDetail.put(title.toString(), doctor.toString());
}
}
}
List<DoctorItem> itemList = new ArrayList<>();
DoctorItem item = new DoctorItem();
item.setName(title.toString());
item.setDoctorDetails(doctorDetail);
//放到集合中
itemList.add(item);
//把需要持久化的数据放到ResultItems中
page.putField("itemList", itemList);
}
else
{
//科室名称
Selectable selectable = page.getHtml()
.css("div.right_bottom");
List<Selectable> nodes = selectable.css("ul.zjxhul")
.nodes();
List<Selectable> doctorTypes = selectable.xpath("//dl/dt/a/strong/text()")
.nodes();
//判断nodes是否有值
if (nodes != null && nodes.size() > 0)
{
List<DoctorItem> itemList = new ArrayList<>();
for (int i = 0; i < nodes.size(); i++)
{
List<Selectable> dcList = nodes.get(i)
.css("li.LMXHZJLB")
.nodes();
for (Selectable dc : dcList)
{
//创建对象
DoctorItem item = new DoctorItem();
if (i < doctorTypes.size() && doctorTypes.get(i) != null)
{
item.setDoctorType(doctorTypes.get(i)
.toString());
}
item.setUrl(dc.links()
.toString());
item.setImg(dc.css("a > img", "src").toString());
item.setName(dc.$("a", "text")
.toString());
//放到集合中
itemList.add(item);
//把医生详情页的url放到url任务队列中
page.addTargetRequest(item.getUrl());
}
}
//把需要持久化的数据放到ResultItems中
page.putField("itemList", itemList);
}
}
}
private Site site = Site.me()
.setTimeOut(2000);
@Override
public Site getSite()
{
return site;
}
}
StartCrawler里切换一下医生相关配置就好了
public void run() {
Spider.create(new WxhsDoctorProcessor())
//.addUrl("https://www.jd.com/news.html?id=38673")
.addUrl(doctorsUrl)
//设置下载器
// .setDownloader(downloader)
// .addPipeline(new JsonFilePipeline("D:\\webmagic\\"))
.addPipeline(doctorPipeline)
.run();
}

医生详情
![]()
代码结构
