superset安装使用说明
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
一、需求背景
1、大数据可视化面临的挑战
2、大数据数据可视化的目标架构
一、Apache Superset简介
1、Apache Superset是什么?
2、为什么选Apache Superset?
3、对比Metabase
三、快速上手
四、部署安装
1、部署方式及版本
2.配置需求
3、下载安装
4、安装注意及排错
5、启动与关闭
6、安装数据源
总结
一、需求背景
1、大数据可视化面临的挑战
大数据的兴起,关于数据的存储、计算技术层出不穷,但是最终的数据可视化呈现,数据的探索,也成为颇为重要的一环,这一块并没有像存储、计算技术栈那么百花齐放,大家在做大数据可视化时是否也曾有这些困惑呢?
传统的可视化对接传统数据库,对大数据组件的hive,spark,presto、elasticsearch、clickhouse等兼容性差,甚至不兼容,每次还需要多一道将大数据集群数据分发到传统数据库的冗余操作;
商用产品昂贵、甚至产品设置技术壁垒,很多甚至要求对接该商家的自己的大数据技术方可对接;群众基数大的Excel拖来拽习惯、SQL操作的方便性,排斥自成一派的新技术,网页版账号登录优于用户下载客户端登录;
公司开发人员配置紧张,没有多余的人力自研大数据可视化平台,但是决策层希望有一个统一的可视化平台。
诸如此类,确实令人头疼,现在就推荐一款解药Apache Superset——开源的大数据分析探索、可视化报表的神器。
2、大数据数据可视化的目标架构
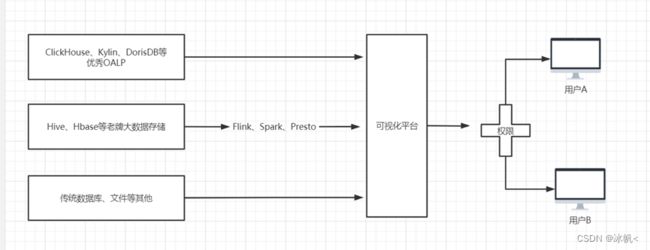
图1.2 大数据数据可视化架构
做事还是需要立一个目标架构,最后所有的事情都是围绕目标架构展开,才能越做越轻松,如图1.2,可是架构分为三个梯队;
第一梯队:ClickHouse、DorisDB、Kylin等优秀OLAP技术做存储,利用自带的连接引擎,快速响应,同时支持实时数据和离线数据的接入,外接可视化平台,通过权限管控后呈现给用户;
第二梯队:数据存在数据仓库Hive内或者NoSQL的Hbase,再通过较为优秀且高效的引擎Presto、Flink、Spark等接入可视化平台,通过权限管控后呈现给用户;
剩下就是一个特殊的,如MySQL,临时文件等文件的接入;
注意:常用的也还有其它技术架构,如ELK架构,ELK由ElasticSearch、Logstash和Kiabana三个开源工具组成。Elasticsearch是个开源分布式搜索引擎,它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful风格接口,多数据源,自动搜索负载等。 Logstash是一个完全开源的工具,他可以对你的日志进行收集、分析,并将其存储供以后使用(如,搜索)。 kibana 也是一个开源和免费的工具,他Kibana可以为 Logstash 和 ElasticSearch 提供的日志分析友好的 Web 界面,可以帮助您汇总、分析和搜索重要数据日志。这个后续再讲,这里书归正传,先讲讲Apache Superser。
一、Apache Superset简介
1、Apache Superset是什么?
Apache Superset是一款由Python语言为主开发的开源时髦数据探索分析以及可视化的报表平台;她支持丰富的数据源,且拥有多姿多彩的可视化图表选择。
官网 :https://superset.apache.org/
github :https://github.com/apache/superset
国内支持的镜像站 :
阿里云:http://mirrors.aliyun.com/pypi/simple/
豆瓣:https://pypi.douban.com/simple/ 等
开发语言:Python为主

2、为什么选Apache Superset?
支持丰富的数据库作为数据源,基本上平时用到的数据库都支持;如图2.2.0,支持的数据源有:
Amazon Athena
Amazon Redshift
Apache Drill
Apache Druid
Apache Hive
Apache Impala
Apache Kylin
Apache Pinot
Apache Solr
Apache Spark SQL
Ascend.io
Azure MS SQL
Big Query
ClickHouse
CockroachDB
Dremio
Elasticsearch
Exasol
Google Sheets
Hologres
IBM Db2
IBM Netezza Performance Server
MySQL
Oracle
PostgreSQL
Trino
Presto
SAP Hana
Snowflake
SQLite
SQL Server
Teradata
Vertica

图2.2.0 Apache Superset支持的数据源
多姿多彩的可视化图表,Apache Superset拥有非常丰富的图表,来实现不同的可视化需求,如图2.2.1。
轻量级和高度可扩展,利用现有数据基础模型的直接进行数据探索和可视化呈现,而不需要另一个摄取层,如图2.2.2,配置好数据库后,进入SQL Lab(SQL实验室),就可以对数据进行探索分析,SQL Lab更像是一个数据库连接查询客户端,当然要更好的数据可视化呈现,还必须结合图表和仪表盘功能。
图2.2.2 Apache Superset的SQL Lab
使用简单,如图2.3.3,Apache Superset使用层面主要分为以下个部分;
Data:主要功能是新增数据源和数据集Dataset(旧版本也叫Table),Dataset作为数据图表可视化的基础;
Charts:图表,就是针对准备好的Dataset数据集,选择一款合适的图表呈现;
Dashboards:仪表盘,其实就是报表、看板大屏展示,可以将多个Charts组合到一个仪表盘内一起展示。
SQL Lab:SQL实验室,其实就是一个类似DBeaver、Navicat、DataGrip等一样的多功能数据库连接客户端,但是只有查询功能,配置驱动和连接后可以进行数据库、表、字段等模型的SQL查询操作。
设置:语言选择,登录注销、人员权限,操作日志等设置;
图2.2.3 Apache Superset使用预览
3、对比Metabase
大数据可视化神器Metabase------开源的大数据分析探索、可视化报表神器的博客,那么对于与Metabase,Apache Superset有哪些优劣呢;
天生自带支持的数据源Apache Superset完胜Metabase;
数据图表形式Apache Superset完胜Metabase;
操作界面美观丝滑度Apache Superset稍逊Metabase;
托拉拽操作Apache Superset稍逊Metabase;
向来博主都是鱼与熊掌能兼得就兼得,毕竟小孩才做选择嘛,可以考虑两个都装,Metabase用于专注业务数据需求人员,Apache Superset用于懂SQL的数据需求人员,二者生成的通用仪表盘,则可以利用一个统一的网页超链接到一起,形成一个统一的报表平台。
三、快速上手
这里先快速上手带大家体验一把,细节后续章节细讲,首先配置好数据库连接(配置方法参考后续的5.1 新建Databases(数据库)),然后打开SQL Lab,选择好配置数据库,写SQL语句分析探索数据,如图3.1.0,然后运行语句,得到数据结果,可以点击保存将常用的探索SQL保存下来,然后点击查询结果上方的EXPLORE按钮,就可以跳转图表分析图3.1.1;
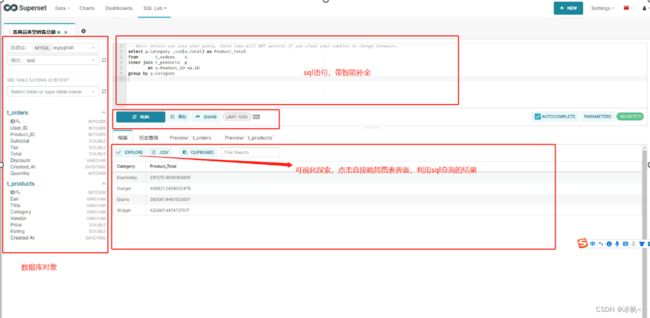
图3.1.0 Apache Superset在SQL Lab上探索数据
利用SQL Lab探索得到的数据集,选择合适需求的数据图表,选择合适的指标,度量值,点击上方的RUN就可以得到结果,非常的方便,可以直接点击上方的SAVE保存图表;
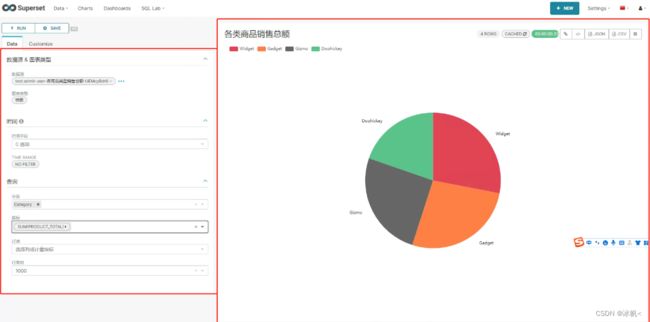
图3.1.1 Apache Superset数据可视化
新建Dashboard,然后编辑Dashboard,将之前生成好的Charts(图表)拖拽到Dashboard,就完成了数据仪表盘的最终呈现,然后就可以分享给需求方,也可以生成访问链接分享。
注意:拖拽时尽量往Dashboard的上面拖拽,会出现一条蓝色的分界线就可以松手,否则可能出现无法拖拽的情况,这个设计很坑。
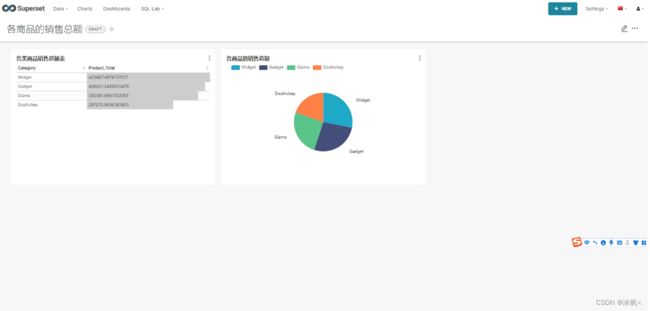
图3.1.1 Apache Superset数据仪表盘呈现
四、部署安装
1、部署方式及版本
支持Linux、Windows、Mac的Docker部署
支持Linux、Windows、Mac的Python环境代码部署
可以在github,官网、或者国内镜像网站查看版本,但是别先下载,因为Apache Superset依赖包很多,最好能在线安装;
图4.1.0 Apache Superset版本预览
博主选的是apache-superset-1.4.2.tar.gz在Linux上的Python环境代码部署。
2.配置需求
apache-superset-1.4.2.tar.gz
CentOS 7 16核 32G(非硬性,一般性能的服务器即可)
Python 3.9
要求服务器网,如果没有,可以使用能联网的代理服务器,依赖很多,采用在线安装的形式
3、下载安装
下载安装Python3.9,可以选择安装anaconda集成的python,可以参考博客Linux通过anaconda来安装python,对应的版本是Anaconda3-5.2.0-Linux-x86_64.sh,下载传送门:Anaconda Download;安装好以后,如果老的服务器上存在python2,默认的环境变量启动是python2,没关系,只需要设置一个新的环境变量确保 python3启动是刚刚安装的版本即可。
安装python3 有疑问可以参考 python3安装。
安装python虚拟机,并启动,然后安装Apache Superset。
# 切换到自己安装软件的目录,博主的是在/opt/servers/python39,并新建superset目录
cd /opt/servers/python39
pip install virtualenv
代码如下(示例):
# 配置命名虚拟机
python3 -m venv venv# 启动虚拟机,会在当前目录下自动创建venv目录. venv/bin/activate# 退出虚拟机指令,但是这里不需要退出deactivate# 安装更新一些依赖pip install --upgrade setuptools pip -i https://pypi.douban.com/simple/ yum install gcc gcc-c++ libffi-devel python-devel python-pip python-wheel openssl-devel libsasl2-devel openldap-devel mysql-devel gcc-devel此处注意: # 如果报错:GPG key retrieval failed: [Errno 14] curl#37 - "Couldn't open file /etc/pki/rpm-gpg/RPM-GPG-KEY-EPEL-7"
# 解决:
vi /etc/yum.repos.d/epel.repo
gpgcheck=0
# 然后wq!保存再试一次yum install gcc gcc-c++ libffi-devel python-devel python-pip python-wheel openssl-devel libsasl2-devel openldap-devel mysql-devel gcc-devel
# 先用官网下载,因为官网的会自动把依赖也给你一起安装了,实在不行再用其他网站的镜像
pip install apache-superset==1.4.2比较慢
# 安装superset,指定版本,不指定版本默认是最新版本
pip install apache-superset==1.4.2 -i https://pypi.douban.com/simple# 安装email_validator
pip3 install email_validator -i https://pypi.douban.com/simple/# 更新数据库
superset db upgrade# 创建admin的用户名,用户名随便写,bigdata,admin都行,写完用户名后会让你输入姓,名,邮箱,这三项可写可不写,不写就直接回车,然后是设置密码,一点要写。
export FLASK_APP=superset
superset fab create-admin
# 加载样例数据,考验网络,如果实在一致加载报错就放弃,不影响后续使用。
superset load_examples
下载 https://github.com/apache-superset/examples-data
解压后放到临时文件夹中:/opt/data/superset/examples-data
启动文件服务
python -m http.server

修改/opt/servers/python39/venv/lib/python3.9/site-packages/superset/examples/helper.py

我的ip地址是10.0.0.155
然后执行:superset load_examples
大部分都已经导入,一部分未导入,不影响使用。
# 初始化
superset init
# 启动,官网是superset run -p 8088 --with-threads --reload --debugger
# 建议用gunicorn启动,方便快速,先直接启动,确保打印在客户端的日志正常
pip install gunicorn
gunicorn -w 5 --timeout 120 -b 10.218.10.290:8088 "superset.app:create_app()"
# gunicorn 是一个Python WEB服务,可以理解为Tomcat
# -w WORKERS:指定线程数
# --timeout:worker进程超时时间,超过会自动重启
# -b BIND:绑定Superset访问地址
# --daemon:后台运行
我在/opt/servers/python39/目录下建一个启动与停止superset脚本
vi superset.sh
#内容开始
#!/bin/bash
superset_status(){
result=`ps -ef | awk '/gunicorn/ && !/awk/{print $2}' | wc -l`
if [[ $result -eq 0 ]]; then
return 0
else
return 1
fi
}
superset_start(){
#source ~/.bashrc
superset_status >/dev/null 2>&1
if [[ $? -eq 0 ]]; then
#. venv/bin/activate; gunicorn --workers 5 --timeout 120 --bind 59.42.255.239:8088 --daemon 'superset.app:create_app()'
. venv/bin/activate; gunicorn -c ./gunicorn_config.py --daemon 'superset.app:create_app()' > ./venv/logs/logs.log
else
echo "superset正在运行"
fi
}
superset_stop(){
superset_status >/dev/null 2>&1
if [[ $? -eq 0 ]]; then
echo "superset未在运行"
else
ps -ef | awk '/gunicorn/ && !/awk/{print $2}' | xargs kill -9
fi
}
case $1 in
start )
echo "启动Superset"
superset_start
;;
stop )
echo "停止Superset"
superset_stop
;;
restart )
echo "重启Superset"
superset_stop
superset_start
;;
status )
superset_status >/dev/null 2>&1
if [[ $? -eq 0 ]]; then
echo "superset未在运行"
else
echo "superset正在运行"
fi
esac
#内容结束
建gunicorn_config.py 配置文件
vi gunicorn_config.py
#内容开始
import multiprocessing
bind = '59.42.255.239:8088' #绑定ip和端口号
backlog = 512 #监听队列
timeout = 120 #超时
#worker_class = 'gevent'
workers = 5
worker_connections = 1000
#threads = 2 #指定每个进程开启的线程数
loglevel = 'info' # 日志级别
access_log_format = '%(t)s %(p)s %(h)s "%(r)s" %(s)s %(L)s %(b)s %(f)s" "%(a)s"' #设置gunicorn访问日志格式,错误日志无法设置
pidfile = '/opt/servers/python39/venv/logs/pidfile'
errorlog = '/opt/servers/python39/venv/logs/gunicorn_error.log'
accesslog = '/opt/servers/python39/venv/logs/gunicorn_access.log'
print("IP and PORT:"+bind)
print("pid_file:"+pidfile)
print("error_log:"+errorlog)
print("access_log:"+accesslog)
#内容结束
# 在能访问59.42.255.239:8088的服务器上打开浏览器,输入刚刚登录的用户名,密码即可。
# 如果没开启后台停止,直接ctrl+c关停
# 后台进程停止gunicorn
ps -ef | awk '/gunicorn/ && !/awk/{print $2}' | xargs kill -9
4、安装注意及排错
pip install superset步骤时出现关键字眼Successfully installed证明正确安装,如图4.3.0;
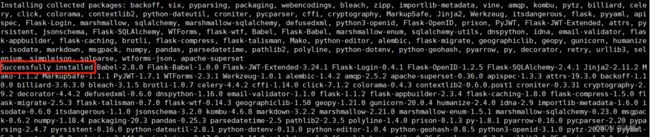
图4.3.0 成功安装的提示
superset fab create-admin配置用户名时提示如图4.3.1。

图4.3.1 配置用户名时提示
每个人的服务器环境,可能导致缺少的 依赖不同,途中如果遇到bug,可自己百度解决,基本都是python依赖包之类的问题,要耐心。
# 报错
ModuleNotFoundError: No module named 'dataclasses'
# 解决
pip install dataclasses
# 报错
No PIL installation found
# 解决
pip install pillow
一切解决后,网页登录如图4.3.2;
修改配置文件 /opt/servers/python39/venv/lib/python3.9/site-packages/flask/
flask cli.py
@click.option("--host", "-h", default="0.0.0.0", help="The interface to bind to.")
@click.option("--port", "-p", default=8088, help="The port to bind to.")
新建配置文件:/opt/servers/python39/venv/lib/python3.9/site-packages/superset
vi superset_config.py
# Superset specific config
ROW_LIMIT = 5000
SUPERSET_WEBSERVER_PORT = 8088
# Flask App Builder configuration
# Your App secret key will be used for securely signing the session cookie
# and encrypting sensitive information on the database
# Make sure you are changing this key for your deployment with a strong key.
# You can generate a strong key using `openssl rand -base64 42`
#SECRET_KEY = 'YOUR_OWN_RANDOM_GENERATED_SECRET_KEY'
SECRET_KEY = 'QZExp+Im/7kLEvhGky06PRlyvqPS1pvHjIgcFO2/WtPPM9/568xAfi9L'
# The SQLAlchemy connection string to your database backend
# This connection defines the path to the database that stores your
# superset metadata (slices, connections, tables, dashboards, ...).
# Note that the connection information to connect to the datasources
# you want to explore are managed directly in the web UI
#SQLALCHEMY_DATABASE_URI = 'sqlite:path/to/superset.db'
SQLALCHEMY_DATABASE_URI = 'mysql://superset:superset@hd-es-1/superset?charset=utf8'
# Flask-WTF flag for CSRF
WTF_CSRF_ENABLED = True
# Add endpoints that need to be exempt from CSRF protection
WTF_CSRF_EXEMPT_LIST = []
# A CSRF token that expires in 1 year
WTF_CSRF_TIME_LIMIT = 60 * 60 * 24 * 365
# Set this API key to enable Mapbox visualizations
MAPBOX_API_KEY = ''
SUPERSET_WEBSERVER_TIMEOUT = 3000
SQLLAB_TIMEOUT = 3000
图4.3.2 登录首页
5、启动与关闭
官网提供的直接启动的方法不是很好,博主推荐一个采用gunicorn的方法,先关停superset。
#安装好superset后会在venv生成很多文件,切换到venv
cd /opt/servers/python39/venv/
#新建日志文件夹
mkdir log
#切换到log目录,新权限 日志,错误日志和启动pid文件
cd log
touch gunicorn_access.log
touch gunicorn_error.log
touch pidfile
chmod 755 ./* #修改权限
#切换到/ opt/servers/python39/venv/bin,写一个gunicorn配置文件,python语言
cd ./ opt/servers/python39/venv/bin
vim gunicorn_config.py # 内容如下
#内容开始
import multiprocessing
bind = '59.42.255.239:8088' #绑定ip和端口号
backlog = 512 #监听队列
timeout = 120 #超时
#worker_class = 'gevent'
workers = 5
worker_connections = 1000
#threads = 2 #指定每个进程开启的线程数
loglevel = 'info' # 日志级别
access_log_format = '%(t)s %(p)s %(h)s "%(r)s" %(s)s %(L)s %(b)s %(f)s" "%(a)s"' #设置gunicorn访问日志格式,错误日志无法设置
pidfile = '/opt/servers/python39/venv/logs/pidfile'
errorlog = '/opt/servers/python39/venv/logs/gunicorn_error.log'
accesslog = '/opt/servers/python39/venv/logs/gunicorn_access.log'
print("IP and PORT:"+bind)
print("pid_file:"+pidfile)
print("error_log:"+errorlog)
print("access_log:"+accesslog)
#内容结束
#然后 wq! 保存退出
# gunicorn 启动 -c 配置文件启动;--daemon后台启动,日志可以去配置文件指定的路径查看
gunicorn -c ./gunicorn_config.py "superset.app:create_app()" --daemon
# 后台进程查看
ps -ef | grep gunicorn
# 或者通过端口查看
netstata -tunlp | grep 8088
# 或
ss -anp | grep 8088
# 如果没开启后台停止,直接ctrl+c关停
# 后台进程停止gunicorn
ps -ef | awk '/gunicorn/ && !/awk/{print $2}' | xargs kill -9
6、安装数据源
Hive,presto,spark:
pip install pyhs2
pip3 install pyhive
clickhouse:
pip3 install clickhouse-driver==0.2.0 && pip3 install clickhouse-sqlalchemy==0.1.6
elasticsearch:
pip3 install elasticsearch-dbapi
mysql:
pip3 install mysqlclient
oracle:
pip3 install cx_Oracle
sqlserver:
pip3 install pymssql
pip3 install sqlalchemy-drill
pip3 install pydruid
pip3 install impyla
pip3 install kylinpy
pip3 install sqlalchemy-solr
pip3 install psycopg2
总结
例如:以上就是superset安装的内容,本文仅仅简单介绍了superset的安装,而superset提供了大量图表,以及数据源的连接,后期若有时间,则介绍下superset的初级使用。