哈希算法从原理到实战
引言
将任意长度的二进制字符串映射为定长二进制字符串的映射规则我们称为散列(hash)算法,又叫哈希(hash)算法,而通过原始数据映射之后得到的二进制值称为哈希值。哈希表(hash表)结构是哈希算法的一种应用,也叫散列表。用的是数组支持按照下标随机访问数据的特性扩展、演化而来。可以说没有数组就没有散列表。
哈希
哈希(Hash)也称为散列,就是把任意长度的输入,通过散列算法,变换成固定长度的输出,这个输出值就是散列值。
哈希表
哈希表(Hash table,也叫散列表),根据关键码值(Key Value)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录。以加快查找的速度。这个是映射函数叫做散列函数,存放记录的数组叫做散列表。
散列表是算法在时间和空间上作出权衡的经典例子
如果没有内存限制,我们可以直接将键作为(可能是一个超大的)数组的索引,那么所有查找操作只需要访问内存一次即可完成。但这种理想情况不会经常出现,因为当键很多时需要的内存太大。另一方面,如果没有时间限制,我们可以使用无序数组并进行顺序查找,这样就只需要很少的内存。而散列表则使用了适度的空间和时间并在这两个极端之间找到了一种平衡。事实上,我们不必重写代码,只需要调整散列算法的参数就可以在空间和时间之间作出取舍。我们会使用概率论的经典结论来帮组我们选择适当的参数。
使用Hash的查询算法分为两步
1、用Hash函数将被查找的键转化为数组的一个索引。 理想情况下,不同的键都能转化为不同的索引值。当然这个只是理想情况,所以我们需要面对两个或者多个键都会散列到相同的索引值的情况。
2、处理碰撞冲突
哈希算法主要特点
哈希算法的核心应用
构造哈希函数的常规方法:数据分析法、直接寻址法、除留取取余法、折叠法、随机法、平方取中法;
Go语言Hash算法
- 正向快速:给定明文和hash算法 在有限时间和有限资源内能计算出hash值
- 逆向困难:给定hash值 几乎不可能推算出明文
- 输入敏感:原始输入信息修改一点点信息 产生的hash值看起来应该都有很大不同
- 冲突避免:很难找到两段内容不同的明文 使得他们的hash值一致(发生冲突)
- 不可逆:无法从一个哈希值恢复原始数据,哈希并不加密
- 唯一性:对于特定的数据 只能有一个哈希 并且这个哈希是唯一的
- 防篡改:改变输入数据中的一个字节 导致输出一个完全不同的哈希值
- 安全加密:对于敏感数据比如密码字段进行MD5或SHA加密传输
- 唯一表示:比如图片识别,可针对图像二进制进行摘后MD5,得到的哈希值作为图片唯一标识。
- 散列函数:是构造散列表的关键。它直接决定了散列表的性质。不过相对哈希算法的其他方面,散列函数对散列冲突要求较低,出现冲突时可以通过开放寻址法或链表法解决冲突。对散列值是否能够反向解密要求也不高。反而更加关注的是散列的均匀性,即是否散列值均匀落入槽中以及散列函数执行的快慢也会影响散列表性能。所以散列函数一般比较简单,追求均匀和高效。
- 负载均衡:常用的负载均衡算法有很多,比如轮询、随机、加权轮询。如何实现一个会话粘滞的负载均衡算法呢?可以通过哈希算法,对客户端IP地址或会话SessionID计算哈希值,将取得的哈希值与服务器列表大小进行取模运算,最终得到应该被路由到的服务器编号。这样就可以把同一IP的客户端请求发到同一个后端服务器上。
- 数据分片:比如统计1T的日志文件中“搜索关键词”出现次数该如何解决?我们可以先对日志进行分片,然后采用多机处理,来提高处理速度。从搜索的日志中依次读取搜索关键词,并通过哈希函数计算哈希值,然后再跟n(机器数)取模,最终得到的值就是应该被分到的机器编号。这样相同哈希值的关键词就被分到同一台机器进行处理。每台机器分别计算关键词出现的次数,再进行合并就是最终结果。这也是MapReduce的基本思想。再比如图片识别应用中给每个图片的摘要信息取唯一标识然后构建散列表,如果图库中有大量图片,单机的hash表会过大,超过单机内存容量。这时也可以使用分片思想,准备n台机器,每台机器负责散列表的一部分数据。每次从图库取一个图片,计算唯一标识,然后与机器个数n求余取模,得到的值就是被分配到的机器编号,然后将这个唯一标识和图片路径发往对应机器构建散列表。当进行图片查找时,使用相同的哈希函数对图片摘要信息取唯一标识并对n求余取模操作后,得到的值k,就是当前图片所存储的机器编号,在该机器的散列表中查找该图片即可。实际上海量数据的处理问题,都可以借助这种数据分片思想,突破单机内存、CPU等资源限制。
- 分布式存储:一致性哈希算法解决缓存等分布式系统的扩容、缩容导致大量数据搬移难题。
- 从哈希值不能反向推导原始数据,也叫单向哈希。
- 对输入数据敏感,哪怕只改了一个Bit,最后得到的哈希值也大不相同。
- 散列冲突的概率要小 。
- 哈希算法执行效率高,散列结果要尽量均衡。
哈希表的基本介绍
散列表(Hash table,也叫哈希表),是根据关键值(Key value)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置
来访问记录,以加快查找的速度。这个映射函数叫散列函数,存放记录的数组叫做散列表。
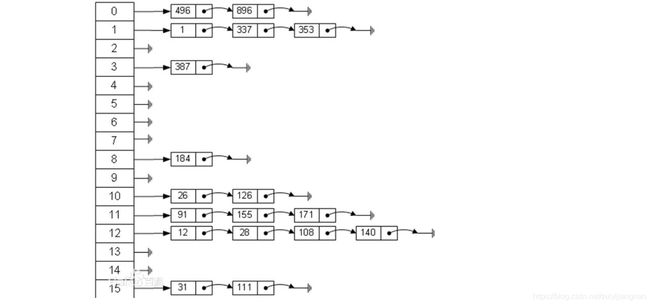
有一个公司,当有新的员工来报道时,要求将该员工的信息加入(ID、性别、年龄、住址…)当输入员工该员工的ID时,要求
查找到该员工的所有信息。
1)要求:
1、不使用数据库,尽量节省内存,速度越快越好===》哈希表(散列)
2、添加时,保证按照雇员的ID从低到高插入
package main
import (
"fmt"
)
//定义emp
type Emp struct {
Id int
Name string
Next *Emp
}
//方法待定
//定义EmpLink
//我们这里的Emplink不带表头,即第一个节点存放雇员
type EmpLink struct {
Head *Emp
}
//方法待定
//1、添加员工的方法,保证添加时,编号从小到大
func (this *EmpLink) Insert(emp *Emp) {
cur := this.Head //辅助指针
var pre *Emp = nil //这是一个辅助指针pre在cur 前面
//如果当前的EmpLink就是一个空链表
if cur == nil {
this.Head = emp //完成
return
}
//如果是一个空链表,给emp找到对应的位置并插入
//思路是让cur 和 emp 比较,然后让pre保持在cur 前面
for {
if cur != nil {
//比较
if cur.Id > emp.Id {
//找到位置
break
}
pre = cur //保证同步
cur = cur.Next
} else {
break
}
}
//退出时,我们看下是否将emp添加到链表最后
pre.Next = emp
emp.Next = cur
}
//显示链表的信息
func (this *EmpLink) ShowLink(no int) {
if this.Head == nil {
fmt.Printf("链表%d为空\n", no)
return
}
//变量当前的链表,并显示数据
cur := this.Head //辅助的指针
for {
if cur != nil {
fmt.Printf("链表%d 雇员id=%d 名字=%s->", no, cur.Id, cur.Name)
cur = cur.Next
} else {
break
}
}
fmt.Println() //行换处理
}
//定义hashtable,含有一个链表数组
type HashTable struct {
LinkArr [7]EmpLink
}
//给HashTable 编写Insert 雇员的方法
func (this *HashTable) Insert(emp *Emp) {
//使用散列函数,确定将该雇员添加到哪个链表
linkNo := this.HashFun(emp.Id)
//使用对应的链表添加
this.LinkArr[linkNo].Insert(emp)
}
//编写方法,显示hashtable的所有雇员
func (this *HashTable) ShowAll() {
for i := 0; i < len(this.LinkArr); i++ {
this.LinkArr[i].ShowLink(i)
}
}
//编写一个散列方法
func (this *HashTable) HashFun(id int) int {
return id % 7 //得到一个值,就是对于的链表下标
}
func main() {
key := ""
id := 0
name := ""
var hashTable HashTable
for {
fmt.Println("===========雇员系统菜单=========")
fmt.Println("input 表示添加雇员")
fmt.Println("show 表示显示雇员")
fmt.Println("find 表示查找雇员")
fmt.Println("exit 表示退出系统")
fmt.Println("请输入你的选择")
fmt.Scanln(&key)
switch key {
case "input":
fmt.Println("输入雇员 id")
fmt.Scanln(&id)
fmt.Println("输入雇员 Name")
fmt.Scanln(&name)
emp := &Emp{
Id: id,
Name: name,
}
hashTable.Insert(emp)
case "show":
hashTable.ShowAll()
case "exit":
default:
fmt.Println("输入错误")
}
}
}
输出结果:
===========雇员系统菜单=========
input 表示添加雇员
show 表示显示雇员
find 表示查找雇员
exit 表示退出系统
请输入你的选择
input
输入雇员 id
12
输入雇员 Name
Jack
===========雇员系统菜单=========
input 表示添加雇员
show 表示显示雇员
find 表示查找雇员
exit 表示退出系统
请输入你的选择
show
链表0为空
链表1为空
链表2为空
链表3为空
链表4为空
链表5 雇员id=12 名字=Jack->
链表6为空
===========雇员系统菜单=========
input 表示添加雇员
show 表示显示雇员
find 表示查找雇员
exit 表示退出系统
请输入你的选择