c++实现哈希表算法(算法基础)
目录
1.模拟散列表
1.1 拉链法
1.2 开放寻址发
2.字符串哈希
学完本章,你会对一般的哈希算法有一定的了解
1.模拟散列表
什么是模拟散列表? 模拟散列表又和哈希算法有什么关系呢? 模拟散列表就是一个很大范围的数以某种方式映射到较小范围上.比如数的范围是-
~
左右个数字,那我们在取的时候就需要从 -
接下来思考这样一道题
解决过程就是将要处理的数与任意一个数(这个数也是有讲究的,最好取成大于映射范围的最小质数)进行取模处理.在这些数取模的时候,避免不了有一些数取模后是同一个数,这样就出现了冲突,解决这种冲突方法就是拉链法和开放寻址法.具体过程如下

1.1 拉链法
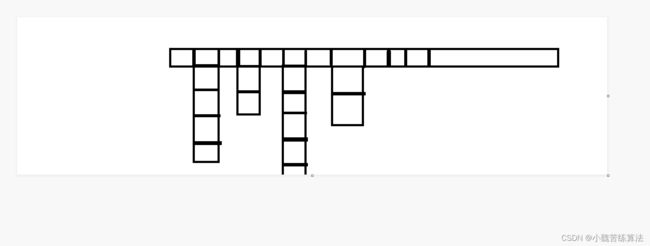
拉链法,顾名思义,就是其储存的结构很像一条条拉链,其储存结构如下图.
处理冲突的方法:当出现两个及以上的数其余数相同时,将这些数都用一个单链表进行储存,其头结点的位置就是余数对应的位置,所就出现了一道道的拉链.
#include
#include
using namespace std;
const int N=1e5+3;
int h[N],e[N],ne[N],idx;//用数组模拟单链表,这是算法中经常用的一种(h为头节点,e为储存对应数字,ne内储存的为下标的下一个数)
void insert(int x)
{
int k=(x%N+N)%N;//这样写的原因是再C++中,负数的余为负数,为了将所有数都映射到对应的正数范围,采取取模加上N再对这个数进行取模,这样就避免了出现复数的情况
e[idx]=x;
ne[idx]=h[k];
h[k]=idx++;//这三步就是用数组模拟单链表,并将x存储到以k为头节点的单链表中
}
bool find(int x)
{
int k=(x%N+N)%N;
for(int i=h[k];i!=-1;i=ne[i])//遍历以k为头结点的单链表,如果有要找的数,就返回true,如果没有就返回false
{
if(e[i]==x)
return true;
}
return false;
}
int main()
{
int number,x;
cin>>number;
char a[2];
memset(h,-1,sizeof h);
while(number--)
{
cin>>a>>x;
if(a[0]=='I') insert(x);
else{
if(find(x)) puts("Yes");
else puts("No");
}
}
return 0;
} 1.2 开放寻址发
开放寻址发解决冲突就是,如果遇见余数相同者,就往下一个位置寻找,如果下一个位置没有被占,那就将这个数放着这个位置,如果已经被占了,就继续寻找下下一个,以此类推

//开放寻址发
#include
#include
using namespace std;
const int N=2e5+3;
const int null=0x3f3f3f3f;
int h[N];
int find(int x){
int k=(x%N+N)%N;//x有可能为负数,再c++的算法原则里,负数的余数仍为负数,所以这样写,能保证所有数都为正数
while(h[k]!=null&&h[k]!=x)
{
k++;
if(k==N) k=0;
}
return k;
}
int main()
{
char a[2];
int number;
scanf("%d",&number);
//对这个h进行初始化,如果这个地方没有人就定义为无穷大
memset(h,0x3f,sizeof h);
while(number--)
{
int x;
scanf("%s%d",a,&x);
if(a[0]=='I'){
h[find(x)]=x;
}else{
if(h[find(x)]==null) puts("No");
else puts("Yes");
}
}
return 0;
}
2.字符串哈希
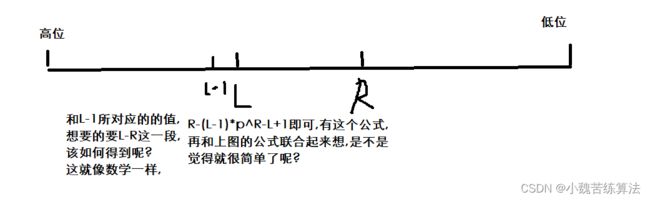
什么是字符串哈希呢? 字符串哈希就是将一个字符串分解成如图这种形式再将字符串看成一个p进制的数,这样就能够对字符串进行相加减.假如我们想到得到BD这个字符串,我们只需要得到AC和ACBD即可,用ACBD-AC*p^2就可以了.
听完这个你可能还不是很理解,那就再画一个图
还有一点需要注意的是我们是对同一个字符串进行处理的
接下来我们看一道字符串哈希的题目:
如何判断这两个子字符串完全相同呢?只需要让这两个子字符串对应的值一样即可.这种字符串哈希的方式在很多情况都比KMP算法好用,所以尽量掌握


接下来就是这道题的解法
#include
using namespace std;
typedef unsigned long long ULL;//如果这个字符串非常长,就会导致数字溢出,这样就相当于是对2^32取模了,这里也算是巧妙之处
const int N=1e5+10;
const int k=103;//为什么要对103取模?这是一个经验值,当然其他数也可以,但用103重复的概率比较小
ULL h[N],p[N];
ULL query(int l,int r)
{
return h[r]-h[l-1]*p[r-l+1];
}
int main()
{
int m,n;
cin>>m>>n;
char a[m];
cin>>a+1;
p[0]=1;
for(int i=1;i<=m;i++)
{
//对字符串进行预处理
p[i]=p[i-1]*k;
h[i]=h[i-1]*k+a[i];//将其看成k进制的数
}
//开始进行询问
while(n--)
{
int l1,l2,r1,r2;
cin>>l1>>r1>>l2>>r2;
if(query(l1,r1)==query(l2,r2))
puts("Yes");
else
puts("No");
}
return 0;
}