Apache Doris 行列转换可以这样玩
行列转换在做报表分析时还是经常会遇到的,今天就说一下如何实现行列转换吧。
行列转换就是如下图所示两种展示形式的互相转换
1. 行转列
我们来看一个简单的例子,我们要把下面这个表的数据,转换成图二的样式

image-20230914151818953.png
要转换的结果数据展示
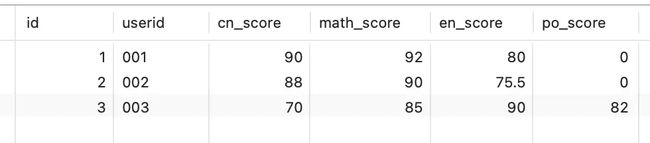
image-20230914152642915.png
先看看建表语句:
CREATE TABLE tb_score_01(
id INT(11) NOT NULL,
userid VARCHAR(20) NOT NULL COMMENT '用户id',
subject VARCHAR(20) COMMENT '科目',
score DOUBLE COMMENT '成绩'
)
DUPLICATE KEY(`id`)
COMMENT 'OLAP'
DISTRIBUTED BY HASH(`id`) BUCKETS 1
PROPERTIES (
"replication_allocation" = "tag.location.default: 1",
"in_memory" = "false",
"storage_format" = "V2",
"light_schema_change" = "true",
"disable_auto_compaction" = "false"
);
INSERT INTO tb_score_01 VALUES (1,'001','语文',90);
INSERT INTO tb_score_01 VALUES (2,'001','数学',92);
INSERT INTO tb_score_01 VALUES (3,'001','英语',80);
INSERT INTO tb_score_01 VALUES (4,'002','语文',88);
INSERT INTO tb_score_01 VALUES (5,'002','数学',90);
INSERT INTO tb_score_01 VALUES (6,'002','英语',75.5);
INSERT INTO tb_score_01 VALUES (7,'003','语文',70);
INSERT INTO tb_score_01 VALUES (8,'003','数学',85);
INSERT INTO tb_score_01 VALUES (9,'003','英语',90);
INSERT INTO tb_score_01 VALUES (10,'003','政治',82);
传统的做法我们大概是这样实现,一般是通过 case when 语句
SELECT userid,
SUM(CASE `subject` WHEN '语文' THEN score ELSE 0 END) as '语文',
SUM(CASE `subject` WHEN '数学' THEN score ELSE 0 END) as '数学',
SUM(CASE `subject` WHEN '英语' THEN score ELSE 0 END) as '英语',
SUM(CASE `subject` WHEN '政治' THEN score ELSE 0 END) as '政治'
FROM tb_score
GROUP BY userid;
或者
SELECT userid,
SUM(IF(`subject`='语文',score,0)) as '语文',
SUM(IF(`subject`='数学',score,0)) as '数学',
SUM(IF(`subject`='英语',score,0)) as '英语',
SUM(IF(`subject`='政治',score,0)) as '政治'
FROM tb_score
GROUP BY userid;
我们来看看 Doris 怎么实现这个行转列呢,有没有更简单、性能更好的一种方式
-
我们是不是可以首先将这个科目、成绩组成一个Map
-
然后在外层对这个 Map 进行遍历展开
-
从而完成这样一个行列转换呢
我们来看看实现
select
userid,
IFNULL(map['语文'],0) as '语文',
IFNULL(map['英语'],0) as '英语',
IFNULL(map['数学'],0) as '数学',
IFNULL(map['政治'],0) as '政治'
from (
select userid ,map_agg(subject,score) as map from tb_score group by userid
) t ;
这样实现上性能更好,我们来看一下效果
select
-> userid,
-> IFNULL(map['语文'],0) as '语文',
-> IFNULL(map['英语'],0) as '英语',
-> IFNULL(map['数学'],0) as '数学',
-> IFNULL(map['政治'],0) as '政治'
-> from (
-> select userid ,map_agg(subject,score) as map from tb_score group by userid
-> ) t ;
+--------+--------+--------+--------+--------+
| userid | 语文 | 英语 | 数学 | 政治 |
+--------+--------+--------+--------+--------+
| 001 | 90 | 80 | 92 | 0 |
| 002 | 88 | 75.5 | 90 | 0 |
| 003 | 70 | 90 | 85 | 82 |
+--------+--------+--------+--------+--------+
3 rows in set (0.02 sec)
2. 列转行
实际使用中我们还有很多场景要把数据冲列转成行,下面我们来看一个例子,这个例子中每行是一个学生的,语文、数学、英语、政治的成绩,
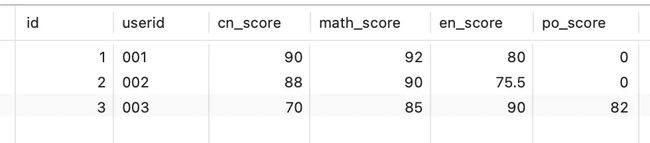
image-20230914152642915.png
我们想转换成每门成绩都是独立的一行,转出的效果如下:
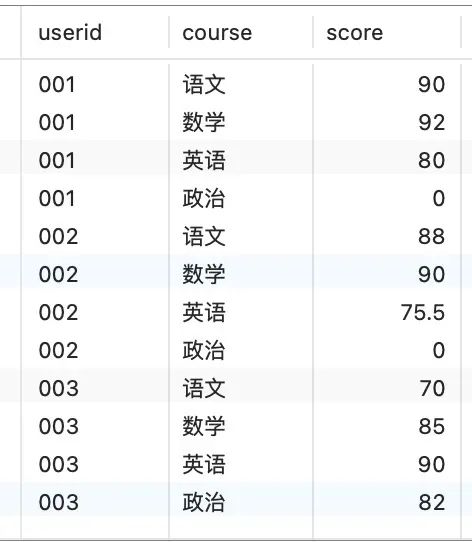
image-20230914152846996.png
我们来看看一个宽表转成高表我们之前的是怎么实现,一般我们是通过union all的方式,每科我们都是一个单独的SQL语句,然后将这些SQL Unoin all 在一起得到我们想要的结果。
SELECT userid,'语文' AS course,cn_score AS score FROM tb_score1
UNION ALL
SELECT userid,'数学' AS course,math_score AS score FROM tb_score1
UNION ALL
SELECT userid,'英语' AS course,en_score AS score FROM tb_score1
UNION ALL
SELECT userid,'政治' AS course,po_score AS score FROM tb_score1
ORDER BY userid;
这样做的缺点:
-
SQL 冗余
-
大量的union all 也会带来性能问题
我们来看看 Doris 怎么实现,首先 Doris 提供了 Lateral view,其实就是用来和像类似explode这种UDTF函数联用的,lateral view会将 UDTF 生成的结果放到一个虚拟表中,然后这个虚拟表会和输入行进行 join来达到连接 UDTF 外的 select 字段的目的
还是以上面的例子来看,Doris我怎么对这个宽表转成高表,实现就是借助Lateral view
CREATE TABLE `tb_score1` (
`id` int(11) NOT NULL,
`userid` varchar(20) NOT NULL COMMENT '用户id',
`cn_score` double NULL COMMENT '语文成绩',
`math_score` double NULL COMMENT '数学成绩',
`en_score` double NULL COMMENT '英语成绩',
`po_score` double NULL COMMENT '政治成绩'
) ENGINE=OLAP
UNIQUE KEY(`id`)
COMMENT 'OLAP'
DISTRIBUTED BY HASH(`id`) BUCKETS 1
PROPERTIES (
"replication_allocation" = "tag.location.default: 1",
"is_being_synced" = "false",
"storage_format" = "V2",
"light_schema_change" = "true",
"disable_auto_compaction" = "false",
"enable_single_replica_compaction" = "false"
);;
INSERT INTO `tb_score1` (`id`, `userid`, `cn_score`, `math_score`, `en_score`, `po_score`) VALUES (1, '001', 90, 92, 80, 0);
INSERT INTO `tb_score1` (`id`, `userid`, `cn_score`, `math_score`, `en_score`, `po_score`) VALUES (2, '002', 88, 90, 75.5, 0);
INSERT INTO `tb_score1` (`id`, `userid`, `cn_score`, `math_score`, `en_score`, `po_score`) VALUES (3, '003', 70, 85, 90, 82);
- 首先我借助Lateral view 形成一个 UserID、客户成绩组成一个字符(使用逗号连接),达到下面的效果
+--------+--------------------+
| userid | arr |
+--------+--------------------+
| 001 | ["语文", "90"] |
| 001 | ["数学", "92"] |
| 001 | ["英语", "80"] |
| 001 | ["政治", "0"] |
| 002 | ["语文", "88"] |
| 002 | ["数学", "90"] |
| 002 | ["英语", "75.5"] |
| 002 | ["政治", "0"] |
| 003 | ["语文", "70"] |
| 003 | ["数学", "85"] |
| 003 | ["英语", "90"] |
| 003 | ["政治", "82"] |
+--------+--------------------+
12 rows in set (0.02 sec)
-
然后对这个上面的 arr 字符串,借助于 Doris 提供的 SPLIT_BY_STRING 函数完成字符串转数组的动作
-
最后遍历数组
-
完成列转行的效果
SELECT
userid,
element_at ( arr, 1 ) AS SUBJECT,
element_at ( arr, 2 ) AS score
FROM
(
SELECT
userid,
SPLIT_BY_STRING ( sub, ',' ) arr
FROM
(
SELECT
userid,
array (
concat( '语文', ',', cn_score ),
concat( '数学', ',', math_score ),
concat( '英语', ',', en_score ),
concat( '政治', ',', po_score )) AS scores
FROM
tb_score1
) t LATERAL VIEW explode ( scores ) tbl1 AS sub
) aaa
最后的效果如下:
SELECT
-> userid,
-> element_at ( arr, 1 ) AS SUBJECT,
-> element_at ( arr, 2 ) AS score
-> FROM
-> (
-> SELECT
-> userid,
-> SPLIT_BY_STRING ( sub, ',' ) arr
-> FROM
-> (
-> SELECT
-> userid,
-> array (
-> concat( '语文', ',', cn_score ),
-> concat( '数学', ',', math_score ),
-> concat( '英语', ',', en_score ),
-> concat( '政治', ',', po_score )) AS scores
-> FROM
-> tb_score1
-> ) t LATERAL VIEW explode ( scores ) tbl1 AS sub
-> ) aaa;
+--------+---------+-------+
| userid | SUBJECT | score |
+--------+---------+-------+
| 001 | 语文 | 90 |
| 001 | 数学 | 92 |
| 001 | 英语 | 80 |
| 001 | 政治 | 0 |
| 002 | 语文 | 88 |
| 002 | 数学 | 90 |
| 002 | 英语 | 75.5 |
| 002 | 政治 | 0 |
| 003 | 语文 | 70 |
| 003 | 数学 | 85 |
| 003 | 英语 | 90 |
| 003 | 政治 | 82 |
+--------+---------+-------+
12 rows in set (0.02 sec)
日记本