android面试题
2017.5补充:
线程和进程的区别
进程是资源分配的最小单位,线程是cpu调度的最小单位。
进程是具有一定独立功能的程序关于某个数据集合上的一次运行活动,进程是系统进行资源分配和调度的一个独立单位。线程是进程的一个实体,是CPU调度和分派的基本单位,它是比进程更小的能独立运行的基本单位。线程自己基本上不拥有系统资源,只拥有一点在运行中必不可少的资源(如程序计数器,一组寄存器和栈),但是它可与同属一个进程的其他的线程共享进程所拥有的全部资源。
线程如何切换,有哈性能问题?
object类的wait,notify,notifyAll
线程thread的join方法
在多任务处理系统中,作业(线程)数通常大于CPU数。为了让用户觉得这些任务在同时进行,CPU给每个任务分配一定时间,把当前任务状态保存下来,当前运行任务转为就绪(或者挂起、删除)状态,另一个被选定的就绪任务成为当前任务,之后CPU可以回过头再处理之前被挂起任务。每次线程切换都会有记录,读取的额外开销。
线程之间如何同步
1.同步方法
即有synchronized关键字修饰的方法。
由于java的每个对象都有一个内置锁,当用此关键字修饰方法时,
内置锁会保护整个方法。在调用该方法前,需要获得内置锁,否则就处于阻塞状态。
2.同步代码块
即有synchronized关键字修饰的语句块。
被该关键字修饰的语句块会自动被加上内置锁,从而实现同步
注:同步是一种高开销的操作,因此应该尽量减少同步的内容。
通常没有必要同步整个方法,使用synchronized代码块同步关键代码即可。
3.使用特殊域变量(volatile)实现线程同步
a.volatile关键字为域变量的访问提供了一种免锁机制,
b.使用volatile修饰域相当于告诉虚拟机该域可能会被其他线程更新,
c.因此每次使用该域就要重新计算,而不是使用寄存器中的值
d.volatile不会提供任何原子操作,它也不能用来修饰final类型的变量
//需要同步的变量加上volatile
private volatile int account = 100;4.使用重入锁实现线程同步
在JavaSE5.0中新增了一个java.util.concurrent包来支持同步。
ReentrantLock类是可重入、互斥、实现了Lock接口的锁,
它与使用synchronized方法和快具有相同的基本行为和语义,并且扩展了其能力
注:关于Lock对象和synchronized关键字的选择:
a.最好两个都不用,使用一种java.util.concurrent包提供的机制,能够帮助用户处理所有与锁相关的代码。
b.如果synchronized关键字能满足用户的需求,就用synchronized,因为它能简化代码
c.如果需要更高级的功能,就用ReentrantLock类,此时要注意及时释放锁,否则会出现死锁,通常在finally代码释放锁
5.使用局部变量实现线程同步
如果使用ThreadLocal管理变量,则每一个使用该变量的线程都获得该变量的副本,
副本之间相互独立,这样每一个线程都可以随意修改自己的变量副本,而不会对其他线程产生影响。
ThreadLocal 类的常用方法
ThreadLocal() : 创建一个线程本地变量
get() : 返回此线程局部变量的当前线程副本中的值
initialValue() : 返回此线程局部变量的当前线程的"初始值"
set(T value) : 将此线程局部变量的当前线程副本中的值设置为value注:ThreadLocal与同步机制
a.ThreadLocal与同步机制都是为了解决多线程中相同变量的访问冲突问题。
b.前者采用以”空间换时间”的方法,后者采用以”时间换空间”的方式
死锁时如何造成的,如何避免?
互斥条件:一个资源每次只能被一个进程使用,即在一段时间内某 资源仅为一个进程所占有。此时若有其他进程请求该资源,则请求进程只能等待。
请求与保持条件:进程已经保持了至少一个资源,但又提出了新的资源请求,而该资源 已被其他进程占有,此时请求进程被阻塞,但对自己已获得的资源保持不放。
不可剥夺条件:进程所获得的资源在未使用完毕之前,不能被其他进程强行夺走,即只能 由获得该资源的进程自己来释放(只能是主动释放)。
循环等待条件: 若干进程间形成首尾相接循环等待资源的关系
这四个条件是死锁的必要条件,只要系统发生死锁,这些条件必然成立,而只要上述条件之一不满足,就不会发生死锁。
避免锁或同步嵌套可以有效避免死锁。
进程间通信方式(android)
Bundle
文件共享
AIDL
Messager
ContentProvider
Socket
TCP UDP 的区别
TCP(Transmission Control Protocol,传输控制协议)是基于连接的协议,也就是说,在正式收发数据前,必须和对方建立可靠的连接。数据更安全,适合较大的数据。
UDP(User Data Protocol,用户数据报协议)是与TCP相对应的协议。它是面向非连接的协议,它不与对方建立连接,而是直接就把数据包发送过去!
TCP三次握手和四次挥手流程,为什么进行三次握手,为什么是四次挥手而不是三次
首先Client端发送连接请求报文,Server段接受连接后回复ACK报文,并为这次连接分配资源。Client端接收到ACK报文后也向Server段发生ACK报文,并分配资源,这样TCP连接就建立了。
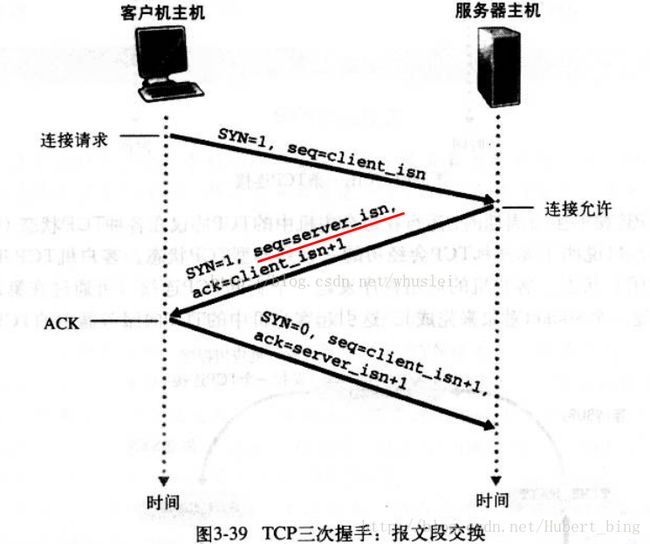
假设Client端发起中断连接请求,也就是发送FIN报文。Server端接到FIN报文后,意思是说”我Client端没有数据要发给你了”,但是如果你还有数据没有发送完成,则不必急着关闭Socket,可以继续发送数据。所以你先发送ACK,”告诉Client端,你的请求我收到了,但是我还没准备好,请继续你等我的消息”。这个时候Client端就进入FIN_WAIT状态,继续等待Server端的FIN报文。当Server端确定数据已发送完成,则向Client端发送FIN报文,”告诉Client端,好了,我这边数据发完了,准备好关闭连接了”。Client端收到FIN报文后,”就知道可以关闭连接了,但是他还是不相信网络,怕Server端不知道要关闭,所以发送ACK后进入TIME_WAIT状态,如果Server端没有收到ACK则可以重传。“,Server端收到ACK后,”就知道可以断开连接了”。Client端等待了2MSL后依然没有收到回复,则证明Server端已正常关闭,那好,我Client端也可以关闭连接了。Ok,TCP连接就这样关闭了!
因为当Server端收到Client端的SYN连接请求报文后,可以直接发送SYN+ACK报文。其中ACK报文是用来应答的,SYN报文是用来同步的。但是关闭连接时,当Server端收到FIN报文时,很可能并不会立即关闭SOCKET,所以只能先回复一个ACK报文,告诉Client端,”你发的FIN报文我收到了”。只有等到我Server端所有的报文都发送完了,我才能发送FIN报文,因此不能一起发送。故需要四步握手。
即使通信中为什么大多使用UDP?
UDP协议的网络开销相对TCP来说,更小。在十年前,拨号上网占主流的网络环境,可以减少网络压力,使传输更快。但随着近年来网络环境的优化,开销不是一个大问题时,从这个角度看TCP的安全性高显得更加适合。
再者即时聊天中每个客户端是和服务端交互,再由服务端转发给正在通行的客户端。如果采用TCP长链接,服务端就要与所有在线的客户端进行连接,这对服务端的负担很大,如采用UDP则可以减少这种负担。
TCP做心跳检测网络情况
如何及时有效地检测到一方的非正常断开,一直有两种技术可以运用。一种是由TCP协议层实现的Keepalive,另一种是由应用层自己实现的心跳包。
TCP默认并不开启Keepalive功能,因为开启Keepalive功能需要消耗额外的宽带和流量,尽管这微不足道,但在按流量计费的环境下增加了费用,另一方面,Keepalive设置不合理时可能会因为短暂的网络波动而断开健康的TCP连接。并且,默认的Keepalive超时需要7,200,000 milliseconds,即2小时,探测次数为5次。对于实用的程序来说,2小时的空闲时间太长。因此,我们需要手工开启Keepalive功能并设置合理的Keepalive参数。
另一种技术,由应用程序自己发送心跳包来检测连接的健康性。客户端可以在一个Timer中或低级别的线程中定时向发服务器发送一个短小精悍的包,并等待服务器的回应。客户端程序在一定时间内没有收到服务器回应即认为连接不可用,同样,服务器在一定时间内没有收到客户端的心跳包则认为客户端已经掉线。
HTTP的几种请求方式以及使用情况
GET:GET可以说是最常见的了,它本质就是发送一个请求来取得服务器上的某一资源。资源通过一组HTTP头和呈现数据(如HTML文本,或者图片或者视频等)返回给客户端。
HEAD:HEAD和GET本质是一样的,区别在于HEAD不含有呈现数据,而仅仅是HTTP头信息。有的人可能觉得这个方法没什么用,其实不是这样的。想象一个业务情景:欲判断某个资源是否存在,我们通常使用GET,但这里用HEAD则意义更加明确。
DELETE:删除某一个资源。基本上这个也很少见,不过还是有一些地方比如amazon的S3云服务里面就用的这个方法来删除资源。
POST:向服务器提交数据。这个方法用途广泛,几乎目前所有的提交操作都是靠这个完成。
PUT:这个方法比较少见。HTML表单也不支持这个。本质上来讲, PUT和POST极为相似,都是向服务器发送数据,但它们之间有一个重要区别,PUT通常指定了资源的存放位置,而POST则没有,POST的数据存放位置由服务器自己决定。举个例子:如一个用于提交博文的URL,/addBlog。如果用PUT,则提交的URL会是像这样的”/addBlog/abc123”,其中abc123就是这个博文的地址。而如果用POST,则这个地址会在提交后由服务器告知客户端。目前大部分博客都是这样的。显然,PUT和POST用途是不一样的。具体用哪个还取决于当前的业务场景。
OPTIONS:这个方法很有趣,但极少使用。它用于获取当前URL所支持的方法。若请求成功,则它会在HTTP头中包含一个名为“Allow”的头,值是所支持的方法,如“GET, POST”。
HTTPS建立连接的流程,证书有什么用,怎么解决中间人劫持攻击

证书是https里非常重要的主体,可用来识别对方是否可信,以及用其公钥做密钥交换。
https握手过程的证书校验环节就是为了识别证书的有效性唯一性等等,所以严格意义上来说https下不存在中间人攻击,存在中间人攻击的前提条件是没有严格的对证书进行校验,或者人为的信任伪造证书。做好严格的证书校验久可以防止中间人劫持。
浅析HTTPS中间人攻击与证书校验
HTTP如何做断点重传
HTTP断点续传(分块传输)
排序算法,快排
public class FastSort {
//快速排序在序列中元素很少时,效率将比较低,不如插入排序,因此一般在序列中元素很少时使用插入排序,这样可以提高整体效率。
public static void quick(int[] array, int lo, int hi) {
if (hi - lo + 1 < 10) {
insertSort(array);
} else {
quickSort(array, lo, hi);
}
}
public static void quickSort(int[] a, int l, int h) {
if (l > h) {
return;
}
int index = partition(a, l, h);
quickSort(a, 0, index - 1);
quickSort(a, index + 1, h);
}
private static int partition(int[] a, int l, int h) {
int tmp = getMiddle(a, l, h);
while (l < h) {
while (a[h] >= tmp && l < h) {
h--;
}
a[l] = a[h];
while (a[l] <= tmp && l < h) {
l++;
}
a[h] = a[l];
}
a[l] = tmp;
return l;
}
private static int getMiddle(int[] a, int l, int h) {
int m = l + (h - l) / 2;
if (a[m] > a[h]) {
swap(a, m, h);
}
if (a[l] > a[h]) {
swap(a, l, h);
}
if (a[l] < a[m]) {
swap(a, l, m);
}
return a[l];
}
private static void swap(int[] a, int x, int y) {
int tmp = a[x];
a[x] = a[y];
a[y] = tmp;
}
public static void insertSort(int[] array) {
int j, total = array.length;
for (int i = 1; i < total; i++) {
int tmp = array[i];
for (j = i; j > 0 && array[j - 1] > tmp; j--) {
array[j] = array[j - 1];
}
array[j] = tmp;
}
}
}链表相关,单向链表反转,如何检测链表成环
查找算法
贪心算法
volatile关键字的作用
当一个共享变量被volatile修饰时,它会保证修改的值会立即被更新到主存,当有其他线程需要读取时,它会去内存中读取新值。而普通的共享变量不能保证可见性,因为普通共享变量被修改之后,什么时候被写入主存是不确定的,当其他线程去读取时,此时内存中可能还是原来的旧值,因此无法保证可见性。
由 于内存访问速度远不及CPU处理速度,为提高机器整体性能。编译器优化常用的方法有:将内存变量缓存到寄存器;调整指令顺序充分利用CPU指 令流水线,常见的是重新排序读写指令。当要求使用volatile声明变量值的时候,系统总是重新从它所在的内存读取数据, 即使它前面的指令刚刚从该处读取过数据。精确地说就是,遇到这个关键字声明的变量,编译器对访问该变量的代码就不再进行优化,即不重新排序读写指令。
synchronize关键字的作用
synchronized 方法控制对类成员变量的访问:每个类实例对应一把锁,每个 synchronized 方法都必须获得调用该方法的类实例的锁方能执行,否则所属线程阻塞,方法一旦执行,就独占该锁,直到从该方法返回时才将锁释放,此后被阻塞的线程方能获得 该锁,重新进入可执行状态。这种机制确保了同一时刻对于每一个类实例,其所有声明为 synchronized 的成员函数中至多只有一个处于可执行状态(因为至多只有一个能够获得该类实例对应的锁),从而有效避免了类成员变量的访问冲突(只要所有可能访问类成员变 量的方法均被声明为 synchronized)。
使用synchronize修饰的对象,那么同一时间只能有一个执行线程访问,如果其他线程试图访问这个对象的其他方法,都将被挂起。
使用synchronize修饰的静态方法,那么同一时间只能有一个执行线程访问,但是其他线程可以访问这个对象的非静态方法。
HashMap,HashTable,ConcurrentHashMap的区别
HashMap是非线程安全的,HashTable、ConcurrentHashMap是线程安全的。
HashMap的键和值都允许有null存在,而HashTable、ConcurrentHashMap则都不行。
因为线程安全、哈希效率的问题,HashMap效率比HashTable、ConcurrentHashMap的都要高。
HashTable里使用的是synchronized关键字,这其实是对对象加锁,锁住的都是对象整体,当Hashtable的大小增加到一定的时候,性能会急剧下降,因为迭代时需要被锁定很长的时间。
ConcurrentHashMap引入了分割(Segment),上面代码中的最后一行其实就可以理解为把一个大的Map拆分成N个小的HashTable,在put方法中,会根据hash(paramK.hashCode())来决定具体存放进哪个Segment,如果查看Segment的put操作,我们会发现内部使用的同步机制是基于lock操作的,这样就可以对Map的一部分(Segment)进行上锁,这样影响的只是将要放入同一个Segment的元素的put操作,保证同步的时候,锁住的不是整个Map(HashTable就是这么做的),相对于HashTable提高了多线程环境下的性能,因此HashTable已经被淘汰了。
Java类加载机制
类从被加载到虚拟机内存中开始,到卸载出内存为止,它的整个生命周期包括:加载(Loading)、验证(Verification)、准备(Preparation)、解析(Resolution)、初始化(Initialization)、使用(Using)和卸载(Unloading)7个阶段。其中准备、验证、解析3个部分统称为连接(Linking)。如图所示。
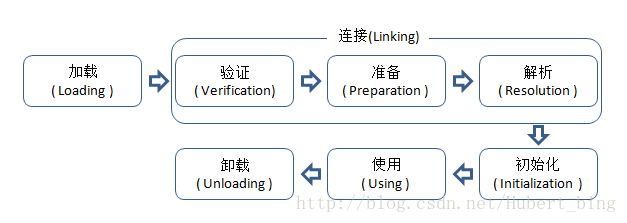
(1) 装载:查找和导入Class文件;
(2) 链接:把类的二进制数据合并到JRE中;
(a)校验:检查载入Class文件数据的正确性;
(b)准备:给类的静态变量分配存储空间;
(c)解析:将符号引用转成直接引用;
(3) 初始化:对类的静态变量,静态代码块执行初始化操作
类初始化
(1) 遇到new、getstatic、putstatic或invokestatic这4条字节码指令时,如果类没有进行过初始化,则需要先触发其初始化。生成这4条指令的最常见的Java代码场景是:使用new关键字实例化对象的时候,读取或设置一个类的静态字段(被final修饰、已在编译期把结果放入常量池的静态字段除外)的时候,以及调用一个类的静态方法的时候。
(2) 使用java.lang.reflect包的方法对类进行反射调用的时候,如果类没有进行过初始化,则需要先触发其初始化。
(3) 当初始化一个类的时候,如果发现其父类还没有进行过初始化,则需要先触发其父类的初始化。
(4)当虚拟机启动时,用户需要指定一个要执行的主类(包含main()方法的那个类),虚拟机会先初始化这个主类。
类加载器
(1) Bootstrap ClassLoader : 将存放于\lib目录中的,或者被-Xbootclasspath参数所指定的路径中的,并且是虚拟机识别的(仅按照文件名识别,如 rt.jar 名字不符合的类库即使放在lib目录中也不会被加载)类库加载到虚拟机内存中。启动类加载器无法被Java程序直接引用
(2) Extension ClassLoader : 将\lib\ext目录下的,或者被java.ext.dirs系统变量所指定的路径中的所有类库加载。开发者可以直接使用扩展类加载器。
(3) Application ClassLoader : 负责加载用户类路径(ClassPath)上所指定的类库,开发者可直接使用。
双亲委派模型:如果一个类加载器接收到了类加载的请求,它首先把这个请求委托给他的父类加载器去完成,每个层次的类加载器都是如此,因此所有的加载请求都应该传送到顶层的启动类加载器中,只有当父加载器反馈自己无法完成这个加载请求(它在搜索范围中没有找到所需的类)时,子加载器才会尝试自己去加载。
好处:java类随着它的类加载器一起具备了一种带有优先级的层次关系。例如类java.lang.Object,它存放在rt.jar中,无论哪个类加载器要加载这个类,最终都会委派给启动类加载器进行加载,因此Object类在程序的各种类加载器环境中都是同一个类。相反,如果用户自己写了一个名为java.lang.Object的类,并放在程序的Classpath中,那系统中将会出现多个不同的Object类,java类型体系中最基础的行为也无法保证,应用程序也会变得一片混乱。
面向对象编程的特点,多态性如何体现,java虚拟机中多态的执行机制
封装、继承、多态
子类的对象可以替代父类的对象使用
反射,那些地方用到了反射
通过反射,我们可以在运行时获得程序或程序集中每一个类型的成员和成员的信息。
程序中一般的对象的类型都是在编译期就确定下来的,而Java反射机制可以动态地创建对象并调用其属性,这样的对象的类型在编译期是未知的。所以我们可以通过反射机制直接创建对象,即使这个对象的类型在编译期是未知的。
反射的核心是JVM在运行时才动态加载类或调用方法/访问属性,它不需要事先(写代码的时候或编译期)知道运行对象是谁。
反射最重要的用途就是开发各种通用框架。
activity四种启动方式
Standard (默认模式):
每次会创建一个新的Activity并放到栈顶;
SingleTop
当要启动的Activity已经在栈顶时不再创建;
SingleTask
当要启动的Activity已经存在于栈内时,则弹出该Activity之上的所有Activity;
SingleInstance
在一个单独的栈中存放该Activity,并只会创建一个对象;
service和intentService的区别
Service默认是执行在主线程。
IntentService继承于Service,在IntentService内开启了一个子线程来处理耗时操作,启动IntentService的方式和启动传统的Service一样,同时,当任务执行完后,IntentService会自动停止,而不需要我们手动去控制或stopSelf()。另外,可以启动IntentService多次,而每一个耗时操作会以工作队列的方式在IntentService的onHandleIntent回调方法中执行,并且,每次只会执行一个工作线程,执行完第一个再执行第二个,以此类推。
自定义view 的几种方式
1.继承View重写onDraw方法,需要自己支持wrap_contant和padding属性。
2.继承ViewGroup派生特殊的Layout,需要处理ViewGroup及其子元素的测量和布局过程。
3.继承特定的View,如TextView,一般用于扩展某种已有view的功能。
4.继承特定的ViewGroup,如LinearLayout
android动画的几种方式
帧动画,补间动画,属性动画
序列化相关知识,怎么序列化,为啥序列化
Serializable是Java提供的一个序列化接口,是一个空接口,用于标示对象是否可以支持序列化,通过ObjectOutputStrean及ObjectInputStream实现序列化和反序列化的过程。注意可以为需要序列化的对象设置一个serialVersionUID,在反序列化的时候系统会检测文件中的serialVersionUID是否与当前类的值一致,如果不一致则说明类发生了修改,反序列化失败。因此对于可能会修改的类最好指定serialVersionUID的值。
Parcelable是Android特有的一个实现序列化的接口,在Parcel内部包装了可序列化的数据,可以在Binder中自由传输。序列化的功能由writeToParcel方法来完成,最终通过Parcel的一系列write方法完成。反序列化功能由CREAOR来完成,其内部标明了如何创建序列化对象和数组,冰通过Parcel的一系列read方法来完成反序列化的过程。
序列化的目的就是为了跨进程传递格式化数据。
触摸事件传递流程
http://www.jianshu.com/p/e99b5e8bd67b
如何设计缓存模块
三级缓存,内存缓存(LruCache)、磁盘缓存(DiskLruCache)、网络。
如何做持久化
存储到data/files目录
Data目录:/data/data/包名/files/文件名
特点:私有目录,适合存储私有的敏感的数据
缺点:实际是存储在手机内存(ROM)中,空间小,不适合存储过大的数据
使用:
1.调用openFileOutput(文件名)方法开启输出流
2.write()方法写出数据
3.close()关流
读取:openFileInput(文件名)
存储到SDcard目录
特点:空间大,适合存储较大数据
缺点:任何应用都可以访问,不安全
使用:
1.注册权限:
<uses-permission android:name="android.permission.READ_EXTERNAL_STORAGE"/>
<uses-permission android:name="android.permission.WRITE_EXTERNAL_STORAGE"/>2.获取SD卡的路径
Environment.getExternalStorageDirectory();3.用IO流操作读写
存储到SharedPreferences(SP)
特点:有专门的工具类,存储方便;适合用来保存零散的简单的数据(如:配置信息);
存储的文件是xml类型的,工具类没有删除文件的方法(只能清空文件内容);
缺点:无法存储结构复杂的内容以及数据过大的内容
存储目录:/data/data/包名/shared_prefs/文件名.xml
使用:
1.获取SharedPreferences对象
//参数1:文件名(不要后缀),参数2:操作模式(Context类中定义的常量)
SharedPreferences sp = (Activity.)getSharedPreferences(String name, mode);2.开始事务,添加数据,提交
sp.edit().putString(key, value).commit();读取:sp.getString(key);
存储到SQLite数据库
存储位置:/data/data/包名/databases/文件名(一般后缀命名为.db)
创建数据库会生成两个文件:
name.db就是我们的数据库文件;
person.db-journal是一个临时的日志文件,主要用于sqlite数据库的事务回滚操作;
1.创建数据库:继承SQLiteOpenhelper 重写onCreate()和onUpgrade()方法,new这个类;
2.创建数据库对象:调用SQLiteOpenhelper实现类对象的getWritableDatabase()或者getReadableDatabase()方法获取SQLiteDatabase对象;
Ps:getReadableDatabase()与getWritableDatabase()作用相同,区别是前者在磁盘满的情况下会返回一个只读的SQLitedatabase对象,而后者会报错;
SQLiteDatabase db = new MySQLiteOpenHelper(this,2)
.getWritableDatabase();3.对数据库进行操作:调用SQLitedatabase对象的方法
可以用sql语句操作:
db.execSQL(sql);
db.rawQuery(sql, selectionArgs);或者调用对应方法:
db.insert(table, nullColumnHack, values);使用insert和update方法时会用到一个ContentValues对象,本质是一个Map,存储键值对的数据;
使用query方法是会返回一个Cursor对象,使用while游标遍历取出数据:
while(cursor.moveToNext()){
Log.d("tag",cursor.getString(cursor.getColumnIndex(columnName)));
}
cursor.close();Cursor对象要及时关闭,避免内存泄露!
4.关闭资源(数据库)
db.close();数据库事务:
当需要一系列操作要求同时完成,即当一个失败时全部失败时,可以使用事务;
当需要大量操作时,可以使用事务提升效率;
db.beginTransaction();
try{
//任务
db.setTransactionSuccessful();
}catch(Exception e){
e.printStackTrace();
}finally{
db.endTransaction();
}存储到ContentProvider
是对本应用的数据(通常是数据库)的封装,并提供安全的访问方法,外部应用可以通过ContentResolver连接此ContentProvider,进而访问到本应用的数据;
其中用到UriMatcher详见类说明;
ContentResolver 内容解析器
用于操作指定应用ContentProvider的CRUD方法,进而访问到数据库数据;通过发送Uri连接到指定的ContentProvider;
获取:(ContentWrapper.)getContentResolver();
ContentObserver 内容监控者
ContentResolver对象可以调用registerContentObserver()方法注册监控者,当指定的数据库发生变化时就会回调ContentObserver 中的onChange()方法;
缓存Cache
存储位置:data/data/包名/cache/文件名
获取cache路径:
File cacheDir = getCacheDir();使用io流操作
获取可用空间
获取SD卡的状态,判断是否挂在SD卡
Environment.getExternalStorageState();方法一:
获取文件总容量(字节数)
long file.getTotalSpace();获取文件可用容量(字节数)
long file.getUsableSpace();方法二:
获取StatFs对象
StatFs sfs = new StatFs(String path);调用StatFs对象的方法获取容量
格式化容量
Formatter.formatFileSize(Context context, long sizeBytes);ART模式
Android 4.4 新特性
优点:ART模式通过在安装应用程序时,自动对程序进行代码预读取编译,让程序直接编译成机器语言,免去了Dalvik模式要时时转换代码,实现高效率、省电、占用更低的系统内存、手机运行流畅。
缺点:会占用略高一些的存储空间、安装程序时要相比普通Dalvik模式要长一些时间来实现预编译。
2017.4补充:
apk打包流程:
Android应用程序(APK)的编译打包过程
Android 名企面试题及涉及知识点整理
http://www.jianshu.com/p/735be5ece9e8
http://mp.weixin.qq.com/s?__biz=MzI0MjE3OTYwMg==&mid=2649548612&idx=1&sn=8e46b6dd47bd8577a5f7098aa0889098&chksm=f1180c39c66f852fd955a29a9cb4ffa9dc4d528cab524059bcabaf37954fa3f04bc52c41dae8&scene=21#wechat_redirect
1.问onStart(),与onResume()有什么区别?
onStart()是activity界面被显示出来的时候执行的,但不能与它交互;
onResume()是当该activity与用户能进行交互时被执行,用户可以获得activity的焦点,能够与用户交互。
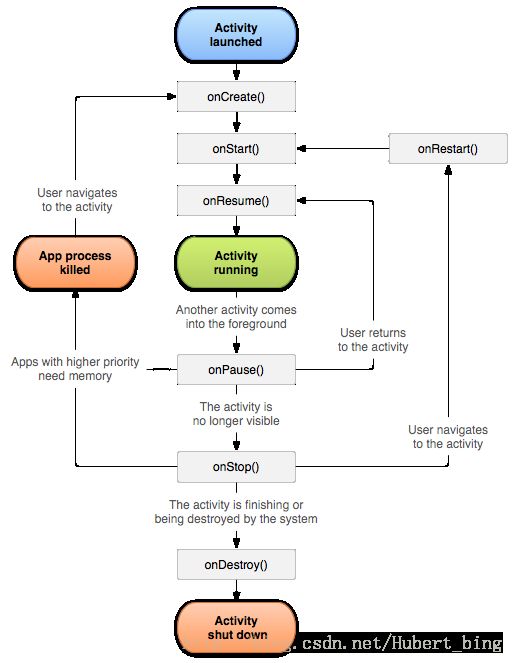
2.什么情况下Activity走了onCreat(),而不走onStart()?
在onCreate()方法中直接finish或者出现为捕获的异常时。

3.彻底明白Context
[干货]让你彻底搞懂Context到底是什么,如果没弄明白,还怎么做Android开发?
4.请描述安卓四大组建之间的关系,并说下安卓MVC的设计模式。
Activity: 处理与UI相关的事件,呈现界面给用户并响应用户的请求
Service: 后台服务,一般用于耗时操作,在后台和长时间运行
BoadcastReceiver: 接收广播事件并对事伯点击进行处理,如当收到短信时系统会发现短信到来的广播,能够处理该广播的BoadcastReceiver就会根据自己需要进进处理
ContentProvider: 存储、处理数据并提供给外界一致的处理接口
MVC全名是Model View Controller,是模型(model)-视图(view)-控制器(controller)的缩写,一种软件设计典范。用户与视图交互,视图接爱并反馈用户的动作,同时把用户的请求传给控制器,由控制器调用模型进行加工处理,模型把处理后的数据返回给控制器,由控制器调用视图格式化和渲染返回的数据。android中的activity是一个controller,对应的layout.xml则是视图,具体的功能则是model。
5.线程中sleep()和wait()有和却别,各有什么含义
sleep()是Thread类的方法,必须传一个long类型的时间,在到指定时间前让出cpu给其他线程,但不释放锁,指定的时间到了又会自动恢复运行状态。
wait()是Object类的方法,可以不传参,当在线程中调用wait()方法时,线程会放弃对象锁进入等待,直到此对象调用notify()、notifyAll()方法或到指定时间,本线程才进入准备阶段,进而获取对象锁进入运行状态。
6.abstract和interface的区别?
都不能被实例化。
interface需要实现,要用implements,而abstract class需要继承,要用extend。
一个类可以实现多个interface,但一个类只能继承一个abstract class。
interface强调特定功能的实现,而abstract class强调所属关系。
abstract的成员修饰符可以自定义,可以有方法体,抽象方法需要用abstract修饰。
interface的成员修饰符只能是public,不能定义方法体和声明实例变量,可以声明常量变量。
7.array,arrayList, List ,三者有何区别?
array是数组,大小固定,不可增删。
arrayList是集合,大小不固定,可以增删。
list是接口,定义list集合框架的通用方法。
8.hashtable和hashmap的区别,并简述Hashmap的实现原理?
hashTable是线程安全的,hashMap是线程不安全的
HashTable不允许null值的存在,HashMap允许null值的存在
HashTable是直接使用对象的哈希值,HashMap是使用处理过的哈希值
hashMap是数组+链表的数据结构。
put()的工作原理:
a、先获取key对象的hashcode值进行处理。
static int secondaryHash(Object key) {
int hash = key.hashCode();
hash ^= (hash >>> 20) ^ (hash >>> 12);
hash ^= (hash >>> 7) ^ (hash >>> 4);
return hash;
}b、将处理后的hashcode对table的length-1进行取余获得index即在数组中的索引位置。
c、然后对该位置的Entry进行判断,若该位置为空,那么插入新的Entry。
d、若当前Entry不为空,那么根据key.equals()对该链表进行遍历,若是该key对象存在,则用新值代替旧值,否则在链表尾端插入新的Entry。
public V put(K key, V value) {
if (key == null) {
return putValueForNullKey(value);
}
int hash = secondaryHash(key);
HashMapEntry[] tab = table;
int index = hash & (tab.length - 1);
for (HashMapEntry e = tab[index]; e != null; e = e.next) {
if (e.hash == hash && key.equals(e.key)) {
preModify(e);
V oldValue = e.value;
e.value = value;
return oldValue;
}
}
// No entry for (non-null) key is present; create one
modCount++;
if (size++ > threshold) {
tab = doubleCapacity();
index = hash & (tab.length - 1);
}
addNewEntry(key, value, hash, index);
return null;
} get(key)的工作原理
跟put()里面的原理大致相同,根据key.hashcode()值找到相应的index,再根据key.equals()遍历该Index中的Entry链表,找到则返回对应的value,否则返回null。
public V get(Object key) {
if (key == null) {
HashMapEntry e = entryForNullKey;
return e == null ? null : e.value;
}
int hash = key.hashCode();
hash ^= (hash >>> 20) ^ (hash >>> 12);
hash ^= (hash >>> 7) ^ (hash >>> 4);
HashMapEntry[] tab = table;
for (HashMapEntry e = tab[hash & (tab.length - 1)];
e != null; e = e.next) {
K eKey = e.key;
if (eKey == key || (e.hash == hash && key.equals(eKey))) {
return e.value;
}
}
return null;
} 其他方法也是类似的。
9.StringBuilder和String ,subString方法的细微差别
StringBuilder是“外人”所以他使用的是copy的方法,而String内部的方法则调用了一个本地的构造函数,它返回的依然是它自己,只是修改了offset!
因此Stringbuilder中的subString在高并发系统里性能会差一些因为他会多分配对象,特别是当你反复使用subString方法的时候一定要记得使用String对象。
10.请写出四种以上你知道的设计模式,并介绍下实现原理
单例
减少创建Java实例所带来的系统开销
11.安卓子线程是否能更新UI,如果能请说明具体细节。
Android子线程真的不能更新UI么
12.ANR产生的原因和解决步骤
ANR的全称是application not responding,意思就是程序未响应。出现ANR的三种情况:
a.主线程对输入事件5秒内没有处理完毕
b.主线程在执行BroadcastReceiver的onReceive()函数时10秒内没有处理完毕
c.主线程在Service的各个生命周期函数时20秒内没有处理完毕。
那么导致ANR的根本原因是什么呢?简单的总结有以下两点:
1.主线程执行了耗时操作,比如数据库操作或网络编程
2.其他进程(就是其他程序)占用CPU导致本进程得不到CPU时间片,比如其他进程的频繁读写操作可能会导致这个问题。
解决方案:
1.避免在主线程执行耗时操作,所有耗时操作应新开一个子线程完成,然后再在主线程更新UI。
2.BroadcastReceiver要执行耗时操作时应启动一个service,将耗时操作交给service来完成。
3.避免在Intent Receiver里启动一个Activity,因为它会创建一个新的画面,并从当前用户正在运行的程序上抢夺焦点。如果你的应用程序在响应Intent广 播时需要向用户展示什么,你应该使用Notification Manager来实现。
13.JavaGC机制的原理和内存泄露
搜索算法:
1.引用计数算法(废弃)
实现简单,效率高,但不能解决循环引用问题,同时计数器的增加和减少带来额外开销,JDK1.1以后废弃了。
2.根搜索算法
根搜索算法是通过一些“GC Roots”对象作为起点,从这些节点开始往下搜索,搜索通过的路径成为引用链(Reference Chain),当一个对象没有被GC Roots 的引用链连接的时候,说明这个对象是不可用的。
回收算法:
1.标记—清除算法(Mark-Sweep)
在标记阶段,确定所有要回收的对象,并做标记。清除阶段紧随标记阶段,将标记阶段确定不可用的对象清除。标记—清除算法是基础的收集算法,标记和清除阶段的效率不高,而且清除后回产生大量的不连续空间,这样当程序需要分配大内存对象时,可能无法找到足够的连续空间。
2.复制算法(Copying):
复制算法是把内存分成大小相等的两块,每次使用其中一块,当垃圾回收的时候,把存活的对象复制到另一块上,然后把这块内存整个清理掉。复制算法实现简单,运行效率高,但是由于每次只能使用其中的一半,造成内存的利用率不高。现在的JVM 用复制方法收集新生代,由于新生代中大部分对象(98%)都是朝生夕死的,所以两块内存的比例不是1:1(大概是8:1)。
3.标记—整理算法(Mark-Compact)
标记—整理算法和复制算法一样,但是标记—整理算法不是把存活对象复制到另一块内存,而是把存活对象往内存的一端移动,然后直接回收边界以外的内存。标记—整理算法提高了内存的利用率,并且它适合在收集对象存活时间较长的老年代。
4.分代收集(Generational Collection)
分代收集是根据对象的存活时间把内存分为新生代和老年代,根据各个代对象的存活特点,每个代采用不同的垃圾回收算法。新生代采用复制算法,老年代采用标记—整理算法。垃圾算法的实现涉及大量的程序细节,而且不同的虚拟机平台实现的方法也各不相同。
16.Handler机制,请写出一种更新UI的方法和代码
1.主线程是android系统创建并维护的,在创建的时候执行了Looper.prepare(),该方法先是new了一个Looper对象,在私有的构造方法中又创建了MessageQueue作为此Looper对象的成员变量,Looper对象通过ThreadLocal绑定MainThread中;
2.当我们创建Handler子类对象时,在构造方法中通过ThreadLocal获取绑定的Looper对象,并获取此Looper对象的成员变量MessageQueue作为该Handler对象的成员变量;
3.在子线程中调用上一步创建的Handler子类对象的sendMesage(msg)方法时,在该方法中将msg的target属性设置为自己本身,同时调用成员变量MessageQueue对象的enqueueMessag()方法将msg放入MessageQueue中;
4.主线程创建好之后,会执行Looper.loop()方法,该方法中获取与线程绑定的Looper对象,继而获取该Looper对象的成员变量MessageQueue对象,并开启一个会阻塞(不占用资源)的死循环,只要MessageQueue中有msg,就会获取该msg,并执行msg.target.dispatchMessage(msg)方法(msg.target即上一步引用的handler对象),此方法中调用了我们第二步创建handler子类对象时覆写的handleMessage()方法,之后将该msg对象存入回收池;
ps:每个线程只能有一个Looper对象。
ThreadLocal为每个使用该变量的线程提供独立的变量副本,所以每一个线程都可以独立地改变自己的副本,而不会影响其它线程所对应的副本。从线程的角度看,目标变量就象是线程的本地变量,这也是类名中“Local”所要表达的意思。ThreadLocal是如何做到为每一个线程维护变量的副本的呢?其实实现的思路很简单:在ThreadLocal类中有一个Map,用于存储每一个线程的变量副本,Map中元素的键为线程对象,而值对应线程的变量副本。
handler.post(Runnable r)
handler.postDelay(Runnable r)
handler.sendMessage(Message msg)
handler.sendMessageDelayed(Message msg, long delayMillis)
最终都会调用sendMessageDelayed方法,post方法中会把Runnable对象通过getPostMessage()方法变成message对象:
private final Message getPostMessage(Runnable r) {
Message m = Message.obtain();
m.callback = r;
return m;
}handler所有发送message的方法:

17.请解释安卓为啥要加签名机制。
1) 发送者的身份认证
由于开发商可能通过使用相同的 Package Name 来混淆替换已经安装的程序,以此保证签名不同的包不被替换
2) 保证信息传输的完整性
签名对于包中的每个文件进行处理,以此确保包中内容不被替换
3) 防止交易中的抵赖发生, Market 对软件的要求
给apk签名可以带来以下好处:
1. 应用程序升级:如果你希望用户无缝升级到新的版本,那么你必须用同一个证书进行签名。这是由于只有以同一个证书签名,系统才会允许安装升级的应用程序。如果你采用了不同的证书,那么系统会要求你的应用程序采用不同的包名称,在这种情况下相当于安装了一个全新的应用程序。如果想升级应用程序,签名证书要相同,包名称要相同!
2.应用程序模块化:Android系统可以允许同一个证书签名的多个应用程序在一个进程里运行,系统实际把他们作为一个单个的应用程序,此时就可以把我们的应用程序以模块的方式进行部署,而用户可以独立的升级其中的一个模块
3.代码或者数据共享:Android提供了基于签名的权限机制,那么一个应用程序就可以为另一个以相同证书签名的应用程序公开自己的功能。以同一个证书对多个应用程序进行签名,利用基于签名的权限检查,你就可以在应用程序间以安全的方式共享代码和数据了。
不同的应用程序之间,想共享数据,或者共享代码,那么要让他们运行在同一个进程中,而且要让他们用相同的证书签名。
十六进制数据怎么和十进制和二进制之间转换
System.out.println("十进制10转16进制为"+Integer.toHexString(10));
System.out.println("十进制10转二进制为"+Integer.toBinaryString(10));怎么让自己的进程不被第三方应用杀掉,系统杀掉之后怎么能启动起来。
一、onStartCommand方法,返回START_STICKY
在运行onStartCommand后service进程被kill后,那将保留在开始状态,但是不保留那些传入的intent。不久后service就会再次尝试重新创建,因为保留在开始状态,在创建 service后将保证调用onstartCommand。如果没有传递任何开始命令给service,那将获取到null的intent。
【结论】 手动返回START_STICKY,亲测当service因内存不足被kill,当内存又有的时候,service又被重新创建,比较不错,但是不能保证任何情况下都被重建,比如进程被干掉了….
二、提升service优先级
在AndroidManifest.xml文件中对于intent-filter可以通过android:priority = “1000”这个属性设置最高优先级,1000是最高值,如果数字越小则优先级越低,同时适用于广播。
三、提升service进程优先级
Android中的进程是托管的,当系统进程空间紧张的时候,会依照优先级自动进行进程的回收。Android将进程分为6个等级,它们按优先级顺序由高到低依次是: 1.前台进程( FOREGROUND_APP) 2.可视进程(VISIBLE_APP ) 3. 次要服务进程(SECONDARY_SERVER ) 4.后台进程 (HIDDEN_APP) 5.内容供应节点(CONTENT_PROVIDER) 6.空进程(EMPTY_APP) 当service运行在低内存的环境时,将会kill掉一些存在的进程。因此进程的优先级将会很重要,可以使用startForeground 将service放到前台状态。这样在低内存时被kill的几率会低一些。
在onStartCommand方法内添加如下代码:
Notification notification = new Notification(R.drawable.ic_launcher,
getString(R.string.app_name), System.currentTimeMillis());
PendingIntent pendingintent = PendingIntent.getActivity(this, 0,
new Intent(this, AppMain.class), 0);
notification.setLatestEventInfo(this, "uploadservice", "请保持程序在后台运行",
pendingintent);
startForeground(0x111, notification);注意在onDestroy里还需要stopForeground(true),运行时在下拉列表会看到自己的APP在: 【结论】如果在极度极度低内存的压力下,该service还是会被kill掉,并且不一定会restart
四、onDestroy方法里重启service
直接在onDestroy()里startService 或 service +broadcast 方式,就是当service走ondestory的时候,发送一个自定义的广播,当收到广播的时候,重新启动service;
【结论】当使用类似口口管家等第三方应用或是在setting里-应用-强制停止时,APP进程可能就直接被干掉了,onDestroy方法都进不来,所以还是无法保证~.~
五、监听系统广播判断Service状态
通过系统的一些广播,比如:手机重启、界面唤醒、应用状态改变等等监听并捕获到,然后判断我们的Service是否还存活,别忘记加权限啊。
六、将APK安装到/system/app,变身系统级应用
大招: 放一个像素在前台(手机QQ)
说下平时开发中比较注意的一些问题
可以熟说下svn和git的细节,和代码规范问题,和一些安全信息的问题等
自定义view效率高于xml定义吗?说明理由。
xml定义应该指的是组合已有的控件达到某种效果。自定义view效率更高。
自定义View 减少了ViewGroup与View之间的测量,包括父量子,子量自身,子在父中位置摆放,当子view变化时,父的某些属性都会跟着变化.
效率差别在自定义View只有一个view的 onMeasure,onLayout,onDraw,而xml则会使多个View的.
广播注册一般有几种,各有什么优缺点
静态注册:在AndroidManifest.xml文件中进行注册,当App退出后,Receiver仍然可以接收到广播并且进行相应的处理,但是会耗费cpu、电量等资源。
动态注册:在代码中动态注册,当App退出后,也就没办法再接受广播了,优先级高于静态注册。
服务启动一般有几种,服务和activty之间怎么通信,服务和服务之间怎么通信
Service有两种启动方法
1.在Context中通过public boolean bindService(Intent service,ServiceConnection conn,int flags) 方法来进行Service与Context的关联并启动,并且Service的生命周期依附于Context。
2.通过public ComponentName startService(Intent service)方法去启动一个Service,此时Service的生命周期与启动它的Context无关。

onStartCommand()方法必须返回一个整数。这个整数是描述系统在杀死服务之后应该如何继续运行。onStartCommand()的返回值必须是以下常量之一:
START_NOT_STICKY 如果系统在onStartCommand()返回后杀死了服务,则不会重建服务了,除非还存在未发送的intent。 当服务不再是必需的,并且应用程序能够简单地重启那些未完成的工作时,这是避免服务运行的最安全的选项。
START_STICKY 如果系统在onStartCommand()返回后杀死了服务,则将重建服务并调用onStartCommand(),但不会再次送入上一个intent, 而是用null intent来调用onStartCommand() 。除非还有启动服务的intent未发送完,那么这些剩下的intent会继续发送。 这适用于媒体播放器(或类似服务),它们不执行命令,但需要一直运行并随时待命。
START_REDELIVER_INTENT 如果系统在onStartCommand()返回后杀死了服务,则将重建服务并用上一个已送过的intent调用onStartCommand()。任何未发送完的intent也都会依次送入。这适用于那些需要立即恢复工作的活跃服务,比如下载文件。
安卓view绘制机制和加载过程,请详细说下整个流程
view的绘制从ViewRoot的performTraversals方法开始,依次调用performMeasure、performLayout、和performDraw三个方法,其中performMeasure方法会调用measure方法,measure方法会调用onMeasure方法,在onMeasure方法中则会对所有的子元素进行measure,这个时候measure就从父容器传递到了子元素中,完成了依次measure过程,子元素会重复父容器的measure过程,完成整个view树的遍历。performLayout和performDraw与measure过程类似,唯一不同是performDraw的传递过程是在draw方法中通过dispatchDraw来实现。
MeasureSpec代表一个32位int值,高2位代表SpecMode,低30位代表SpecSize,用于决定一个view的尺寸规格。
SpecMode有三种:
UNSPECIFIED 父容器不对view有任何限制。
EXACTLY 父容器已经检测出view所需的精确大小,这时候view的最终大小SpecSize所指定的值,相当于match_parent或指定具体数值。
AT_MOST 父容器指定一个可用大小即SpecSize,view的大小不能大于这个值,具体多大要看view的具体实现,相当于wrap_content。
给view设置的LayoutParams会在父容器的约束下转换成对应MeasureSpec,然后根据这个MeasureSpec来确定view测量后的尺寸
activty的加载过程 请详细介绍下(不是生命周期切记)
无论是startactivity还是launcher启动activity,最终都是调用startActivityForResult;
通过binder进程间通信进入到ActivityManagerService进程,中调用startActivity方法(启动Activity的真正实现是由ActivityManagerNative.getDefault()的startActivity方法实现,而ActivityManagerService继承了ActivityManagerNative, ActivityManagerNative继承自Binder实现了IActivityManager这个Binder接口,所以AMS是IActivityManager的Binder实现类。)
经过在ActivityStackSupervisor和ActivityStack中一连串的方法调用最终执行ActivityThread的内部类ApplicationThread的scheduleLaunchActivity方法,该方法发送一个启动Activity的消息给Handler处理,Handler中又调用ActivityThread的handleLaunchActivity实现启动。
过程:1.从ActivityClientRecord中获取启动Activity组件信息;
2.通过Instrumentation的newActivity方法使用类加载器穿件Activity对象;
3.通过LoadApk的newApplication方法获取Application对象;
4.穿件ContextImpl对象并通过Activity的attach方法完成一些重要数据的初始化;
5.调用Activity的onCreate方法。
4 安卓采用自动垃圾回收机制,请说下安卓内存管理的原理
GC_CONCURRENT 内存将满时触发的并发垃圾回收,paused time基本在10ms以内
GC_FOR_ALLOC 内存已满时尝试分配内存失败时触发,系统会较长时间暂停应用进行内存回收,paused time都在50ms以上,经常为100ms左右
GC_HPROF_DUMP_HEAP 创建HPROF内存分析文件时触发
GC_EXPLICIT 显示调用的垃圾收集,比如调用gc()
17 android 5.0 6.0 以及7.0新特性
https://github.com/helen-x/AndroidInterview/blob/master/android/Android5.0%E3%80%816.0%E3%80%817.0%E6%96%B0%E7%89%B9%E6%80%A7.md
hybrid混合开发,响应式编程等
android中调用webview中的js脚本非常方便,只需要调用webview的loadUrl方法即可(注意开启js支持)
// 启用javascript
contentWebView.getSettings().setJavaScriptEnabled(true);
// 从assets目录下面的加载html
contentWebView.loadUrl("file:///android_asset/wst.html");
// 无参数调用
contentWebView.loadUrl("javascript:javacalljs()"); webview中js调用本地java方法,这个功能实现起来稍微有点麻烦,不过也不怎么复杂,首先要对webview绑定javascriptInterface,js脚本通过这个接口来调用java代码。
contentWebView.addJavascriptInterface(this, "wst"); javainterface实际就是一个普通的java类,里面是我们本地实现的java代码, 将object 传递给webview,并指定别名,这样js脚本就可以通过我们给的这个别名来调用我们的方法,在上面的代码中,this是实例化的对象,wst是这个对象在js中的别名。
java代码调用js并传递参数
只需要在待用js函数的时候加入参数即可,下面是传递一个参数的情况,需要多个参数的时候自己拼接及行了,注意str类型在传递的时候参数要用单引号括起来
mWebView.loadUrl("javascript:test('" + aa+ "')"); //aa是js的函数test()的参数 js调用java函数并传参,java函数正常书写,在js脚本中调用的时候稍加注意
然后在html页面中,利用如下代码,即可实现调用
<div id='b'><a onclick="window.wst.clickOnAndroid(2)">b.ca>div> webView优化
缓存机制(优化二次启动)
Web Storage存储机制
优点:有较大存储空间,使用简单
使用场景:临时,简单数据的缓存,Cookies的扩展webView.getSettings.setDomStorageEnabled(true);
IndexedDB 数据库的存储机制,android4.4开始加入对IndexedDB的支持
webView.getSettings().setJavaScriptEnabled(true);常用资源预加载
H5加载过程会有许多处外部依赖的JS、CSS、图片等资源需要下载,提前加载这些内容可以优化首次启动。
WebView mWebView = (WebView) findViewById(R.id.webview);
mWebView.setWebViewClient(new WebViewClient() {
@Override
public WebResourceResponse shouldInterceptRequest(WebView webView, final String url) {
WebResourceResponse response = null;
// 检查该资源是否已经提前下载完成。我采用的策略是在应用启动时,用户在 wifi 的网络环境下 // 提前下载 H5 页面需要的资源。
boolean resDown = JSHelper.isURLDownValid(url);
if (resDown) {
jsStr = JsjjJSHelper.getResInputStream(url);
if (url.endsWith(".png")) {
response = getWebResourceResponse(url, "image/png", ".png");
} else if (url.endsWith(".gif")) {
response = getWebResourceResponse(url, "image/gif", ".gif");
} else if (url.endsWith(".jpg")) {
response = getWebResourceResponse(url, "image/jepg", ".jpg");
} else if (url.endsWith(".jepg")) {
response = getWebResourceResponse(url, "image/jepg", ".jepg");
} else if (url.endsWith(".js") && jsStr != null) {
response = getWebResourceResponse("text/javascript", "UTF-8", ".js");
} else if (url.endsWith(".css") && jsStr != null) {
response = getWebResourceResponse("text/css", "UTF-8", ".css");
} else if (url.endsWith(".html") && jsStr != null) {
response = getWebResourceResponse("text/html", "UTF-8", ".html");
}
}
// 若 response 返回为 null , WebView 会自行请求网络加载资源。
return response;
}
});
private WebResourceResponse getWebResourceResponse(String url, String mime, String style) {
WebResourceResponse response = null;
try {
response = new WebResourceResponse(mime, "UTF-8", new FileInputStream(new File(getJSPath() + TPMD5.md5String(url) + style)));
} catch (FileNotFoundException e) {
e.printStackTrace();
}
return response;
}
public String getJsjjJSPath() {
String splashTargetPath = JarEnv.sApplicationContext.getFilesDir().getPath() + "/JS";
if (!TPFileSysUtil.isDirFileExist(splashTargetPath)) {
TPFileSysUtil.createDir(splashTargetPath);
}
return splashTargetPath + "/";
}JS 本地化
比预加载更粗暴的优化方法是直接将常用的 JS 脚本本地化,直接打包放入 apk 中。比如 H5 页面获取用户信息,设置标题等通用方法,就可以直接写入一个 JS 文件,放入 asserts 文件夹,在 WebView 调用了onPageFinished() 方法后进行加载。需要注意的是,在该 JS 文件中需要写入一个 JS 文件载入完毕的事件,这样前端才能接受都爱 JS 文件已经种植完毕,可以调用 JS 中的方法了。
JS 延迟加载
默认情况html代码下载到WebView后,webkit开始解析网页各个节点,发现有外部样式文件或者外部脚本文件时,会异步发起网络请求下载文件, 但如果在这之前也有解析到image节点,那势必也会发起网络请求下载相应的图片。在网络情况较差的情况下,过多的网络请求就会造成带宽紧张,影响到 css或js文件加载完成的时间,造成页面空白loading过久。解决的方法就是告诉WebView先不要自动加载图片,等页面finish后再发起图 片加载。
故在WebView初始化时设置如下代码:
public void int () {
if(Build.VERSION.SDK_INT >= 19) {
webView.getSettings().setLoadsImagesAutomatically(true);
} else {
webView.getSettings().setLoadsImagesAutomatically(false);
}
}同时在WebView的WebViewClient实例中的onPageFinished()方法添加如下代码:
@Override
public void onPageFinished(WebView view, String url) {
if(!webView.getSettings().getLoadsImagesAutomatically()) {
webView.getSettings().setLoadsImagesAutomatically(true);
}
}Android 的 OnPageFinished 事件会在 Javascript 脚本执行完成之后才会触发。如果在页面中使 用JQuery,会在处理完 DOM 对象,执行完 $(document).ready(function() {}); 事件自会后才会渲染并显示页面。而同样的页面在 iPhone 上却是载入相当的快,因为 iPhone 是显示完页面才会触发脚本的执行。所以我们这边的解决方案延迟 JS 脚本的载入,这个方面的问题是需要Web前端工程师帮忙优化的。
说下OPP 和AOP的思想
OOP是面向对象编程,核心思想是将客观存在的不同事物抽象成相互独立的类,然后把与事物相关的属性和行为封装到类里,并通过继承和多态来定义类彼此间的关系,最后通过操作类的实例来完成实际业务逻辑的功能求。
AOP是面向切面编程,核心思想是将业务逻辑中与类不相关的通用功能切面式的提取分离出来,让多个类共享一个行为,一旦这个行为发生改变,不必修改类,而只需要修改这个行为即可。
OOP与AOP的区别:
1、面向目标不同:简单来说OOP是面向名词领域,AOP面向动词领域。
2、思想结构不同:OOP是纵向结构,AOP是横向结构。
3、注重方面不同:OOP注重业务逻辑单元的划分,AOP偏重业务处理过程的某个步骤或阶段。
OOP与AOP联系:
两者之间是一个相互补充和完善的关系。
AOP的优点:
利用AOP可以对业务逻辑的各个部分进行隔离,从而使得业务逻辑各部分之间的耦合度降低,提高程序的可重用性,同时提高了开发的效率。
OPP六大原则
1.单一职责原则 Single Responsibility Principle
2.开闭原则 Open Close Principle
软件中的对象对于扩展是开放,对于修改时封闭的。
3.里氏替换原则 Liskov Substitution Principle
所有引用基类的地方必须能够透明地使用其子类的对象。
4.依赖倒置原则 Dependence Inversion Principle
高层模块不应该依赖低层模块,两种都应该依赖器抽象。
抽象不应该依赖细节,细节应该依赖抽象。
java语言中的表现:模块间的依赖通过抽象发生,实现类之间不发生直接的依赖关系,其依赖关系是通过接口或者抽象类产生的。
5.接口隔离原则 Interface Segregation Principle
类间的依赖关系应该建立在最小的接口上。
接口隔离的目的是系统解开耦合,从而容易重构。更改和重新部署。
6.迪米特原则 Low of Demeter
一个类应该对自己需要耦合或者调用的类知道地最少,类的内部如何实现与调用者或者依赖者没关系,调用者或者依赖者只需要知道它需要的方法即可。
8 你知道的一些开源框架和原理
9 不同语言是否可以互相调用
10 安卓适配和性能调优问题
11 对于非立项(KPI)项目,怎么推进
11 你还要什么了解和要问的吗
你可以问下项目团队多少人,主要以什么方向为主,一年内的目标怎样,团队气氛怎样,等内容着手。
Butterknite原理
可能很多人都觉得ButterKnife在bind(this)方法执行的时候通过反射获取带有@Bind注解的属性并且获得注解中的R.id.xxx值,最后还是通过反射拿到Activity.findViewById()方法获取View,并赋值给对应的属性 。这是一个注解库的实现方式,比较原始,一个很大的缺点就是在Activity运行时大量使用反射会影响App的运行性能,造成卡顿以及生成很多临时Java对象更容易触发GC 。
ButterKnife没有使用这种原始方式,它用了Java Annotation Processing技术,就是在Java代码编译成Java字节码的时候就已经处理了@Bind、@OnClick之类的注解。
Annotation processing 是javac中用于编译时扫描和解析Java注解的工具。这个工具可以让你定义注解,并且自己定义解析器来处理它们。Annotation processing是在编译阶段执行的,它的原理就是读入Java源代码,解析注解,然后生成新的Java代码。
当你编译你的Android工程时,ButterKnife工程中ButterKnifeProcessor类的process()方法会执行以下操作:
开始它会扫描Java代码中所有的ButterKnife注解@Bind、@OnClick、@OnItemClicked等 。
当它发现一个类中含有任何一个注解时,ButterKnifeProcessor会帮你生成一个Java类,名字类似$$ViewBinder,这个新生成的类实现了ViewBinder接口 。
这个ViewBinder类中包含了所有对应的代码,比如@Bind注解对应findViewById(), @OnClick对应了view.setOnClickListener()等等
最后当Activity启动ButterKnife.bind(this)执行时,ButterKnife会去加载对应的ViewBinder类调用它们的bind()方法
glide 图片处理框架
Glide 缓存的图片和 ImageView 的尺寸相同,假如在第一个页面有一个200x200的ImageView,在第二个页面有一个100x100的ImageView,这两个ImageView本来是要显示同一张图片,却需要下载两次,有两个尺寸的缓存;
Glide默认的图片质量是RGB_565,节约内存;
Glide 不仅是一个图片缓存,它支持 Gif、WebP、缩略图。甚至是 Video,所以也可以叫做一个媒体缓存。
Glide和Activity/Fragment的生命周期是一致的,with(context)会创建RequestManager 用于监控Activity/Fragment的生命周期,从而可以控制Request的pause、resume、clear。
Glide 默认通过 UrlConnection 获取数据,也可以配合 okhttp 或是 Volley 使用。
Glide库的资源复用
Android的内存申请几乎都在new的时候发生,而new较大对象(比如Bitmap时),更加容易触发GC_FOR_ALLOW。所以Glide尽量的复用资源来防止不必要的GC_FOR_ALLOC引起卡顿。
最显著的内存复用就是内存LruResourceCache(第一次从网络或者磁盘上读取到Resource时,并不会保存到LruCache当中,当Resource被release时,也就是View不在需要此Resource时,才会进入LruCache当中)
还有BitmapPool(Glide会尽量用图片池来获取到可以复用的图片,获取不到才会new,而当LruCache触发Evicted时会把从LruCache中淘汰下来的Bitmap回收,也会把transform时用到的中间Bitmap加以复用及回收)
Glide库图片池
4.4以前是Bitmap复用必须长宽相等才可以复用
4.4及以后是Size>=所需就可以复用,只不过需要调用reconfigure来调整尺寸
Glide用AttributeStrategy和SizeStrategy来实现两种策略
图片池在收到传来的Bitmap之后,通过长宽或者Size来从KeyPool中获取Key(对象复用到了极致,连Key都用到了Pool),然后再每个Key对应一个双向链表结构来存储。每个Key下可能有很多个待用Bitmap
取出后要减少图片池中记录的当前Size等,并对Bitmap进行eraseColor(Color.TRANSPAENT)操作确保可用
Glide加载发起流程
Glide.with(context)创建RequestManager
RequestManager负责管理当前context的所有Request
Context 可以传Fragment、Activity或者其他Context,当传Fragment、Activity时,当前页面对应的Activity的生命周 期可以被RequestManager监控到,从而可以控制Request的pause、resume、clear。这其中采用的监控方法就是在当前 activity中添加一个没有view的fragment,这样在activity发生onStart onStop onDestroy的时候,会触发此fragment的onStart onStop onDestroy。
RequestManager用来跟踪众多当前页面的Request的是RequestTracker类,用弱引用来保存运行中的Request,用强引用来保存暂停需要恢复的Request。
Glide.with(context).load(url)创建需要的Request
通常是DrawableTypeRequest,后面可以添加transform、fitCenter、animate、placeholder、error、override、skipMemoryCache、signature等等
如果需要进行Resource的转化比如转化为Byte数组等需要,可以加asBitmap来更改为BitmapTypeRequest
Request是Glide加载图片的执行单位
Glide.with(context).load(url).into(imageview)
在Request的into方法中会调用Request的begin方法开始执行
在 正式生成EngineJob放入Engine中执行之前,如果并没有事先调用override(width, height)来指定所需要宽高,Glide则会尝试去获取imageview的宽和高,如果当前imageview并没有初始化完毕取不到高 宽,Glide会通过view的ViewTreeObserver来等View初始化完毕之后再获取宽高再进行下一步
Glide加载资源
GlideBuilder在初始化Glide时,会生成一个执行机Engine
Engine中包含LruCache缓存及一个当前正在使用的active资源Cache(弱引用)
activeCache辅助LruCache,当Resource从LruCache中取出使用时,会从LruCache中remove并进入acticeCache当中
Cache优先级LruCache>activeCache
Engine在初始化时要传入两个ExecutorService,即会有两个线程池,一个用来从DiskCache获取resource,另一个用来从Source中获取(通常是下载)
线程的封装单位是EngineJob,有两个顺序状态,先是CacheState,在此状态先进入DiskCacheService中执行获取,如果没找到则进入SourceState,进到SourceService中执行下载
LruCache
LruCache 内部使用的是LinckedHashMap,基于 Lru算法实现的一种缓存机制;
Lru算法链表实现原理:每次put和get,都会将该元素移动到链表头部,而链表的尾部则为Least Recently Used,当达到最大缓存时,移出链表最后一个元素;
使用LruCache:
继承LruCache,并复写protected int sizeOf(K key, V value)方法,用于返回每个item的大小,单位与构造方法中参数(最大容量)相同;
复写protected V create(K key) 方法返回当item丢失时,返回对应key的值;
复写protected void entryRemoved(boolean evicted, K key, V oldValue, V newValue) 方法,该方法当value被回收释放存储空间时被remove调用,或者替换item值时put调用,evicted 的值为true—表示释放空间被删除,false—表示put或remove导致;
LruCache 没有真正的释放内存,只是从 Map中移除掉数据,真正释放内存还是要复写上述方法进行释放。