4.2 Serializable Concept(2)
4.Class Serialization Traits
4.1 Version
此头文件包括以下代码:
namespace boost {
namespace serialization {
template<class T>
struct version
{
BOOST_STATIC_CONSTANT(unsigned int, value = 0);
};
} // namespace serialization
} // namespace boost
对于任何类T,boost::serialization::version::value的默认定义是0。如果我们想要为类my_class分配版本2作为版本号,我们可以专门化版本模板:
namespace boost {
namespace serialization {
struct version<my_class>
{
BOOST_STATIC_CONSTANT(unsigned int, value = 2);
};
} // namespace serialization
} // namespace boost
现在,每当需要类my_class的版本号时,将返回值2,而不是默认值0。
为了减少键入并增强可读性,定义了一个宏,以便我们可以写成:
BOOST_CLASS_VERSION(my_class, 2)
4.2 Implementation Level
与上面的方法类似,可以指定序列化的实现级别。头文件level.hpp定义了以下内容:
// 每个级别的名称
enum level_type
{
// 不要序列化这种类型。尝试这样做应该会触发编译时断言。
not_serializable = 0,
// 直接将此类型写入/从归档中读取。在这种情况下,不会调用序列化代码。
// 这是基本类型的默认情况。它假定归档类中有一个可以处理此类型的成员函数或模板。
// 读取/写入此级别的实例时没有与之相关的运行时开销
primitive_type = 1,
// 使用对象的 "serialize" 函数或模板序列化此类型的对象。这允许值被写入/从归档中读取,
// 但不包括类或版本信息。
object_serializable = 2,
///
// 一旦在上述级别之一对对象进行了序列化,如果更改了归档对象的实现级别,
// 则无法读取相应的归档。
///
// 向归档添加类信息。类信息包括实现级别、类版本和类名称(如果有的话)。
object_class_info = 3,
};
使用level.hpp中定义的宏,我们可以指定要序列化的my_class以及其版本号:
BOOST_CLASS_IMPLEMENTATION(my_class, boost::serialization::object_class_info)
如果未显式分配实现级别,则系统将根据以下规则使用默认值:
- 如果数据类型是volatile,则分配not_serializable。
- 否则,如果它是枚举或基本类型,则分配primitive_type。
- 否则,分配object_class_info。
换句话说,对于大多数用户定义的类型,对象将与类版本信息一起序列化。这将允许在包含先前版本的归档中保持向后兼容性。但是,这种能力会带来一些运行时成本。对于其定义“永远不会更改”的类型,可以通过指定object_serializable来覆盖object_class_info的默认设置以提高效率。例如,这已经用于binary_object包装器。
4.3 对象跟踪(Object Tracking)
根据类型的使用方式,可能需要或方便跟踪保存和加载的对象的地址。例如,在通过指针序列化对象时,通常需要跟踪对象的地址,以确保在加载归档时不会创建多个相同的对象。这种“跟踪行为”由头文件tracking.hpp中定义的类型特征控制,该文件定义了以下内容:
// 每个跟踪级别的名称
enum tracking_type
{
// 从不跟踪此类型
track_never = 0,
// 仅在通过指针序列化对象时跟踪该类型的对象。
track_selectively = 1,
// 总是跟踪此类型
track_always = 2
};
还定义了相应的宏,以便我们可以使用:
BOOST_CLASS_TRACKING(my_class, boost::serialization::track_never)
默认的跟踪特性如下:
- 对于基本类型,track_never。
- 对于指针,track_never。也就是说,默认情况下不跟踪地址的地址。
- 所有当前的序列化包装器,如boost::serialization::nvp,track_never。
- 对于所有其他类型,track_selectively。也就是说,只有在以下情况之一为真时,才跟踪序列化对象的地址:
- 该类型的对象在程序的任何地方通过指针进行序列化。
- 类显式地“导出” - 请参阅下文。
- 类在存档中显式“注册”。
默认行为几乎总是最方便的。然而,有一些情况下,覆盖默认行为会更有利。一个案例是虚基类。在具有虚基类的钻石继承结构中,对象跟踪将阻止冗余的保存/加载调用。因此,在这种情况下,覆盖默认跟踪特性可能很方便。 (注意:在将来的版本中,将重新实现默认行为以自动跟踪用作虚基类的类)。这种情况可以通过包含在库中的test_diamond.cpp演示。
4.4 抽象类(Abstract)
当通过指向其基类的指针序列化对象时,库需要确定基类是否为抽象类(即是否具有至少一个虚函数)。库使用类型特征宏 BOOST_IS_ABSTRACT(T) 来执行此操作。并非所有编译器都支持此类型特征和相应的宏。为解决此问题,已实现宏BOOST_SERIALIZATION_ASSUME_ABSTRACT(T),允许显式指示指定的类型实际上是抽象的。这将确保BOOST_IS_ABSTRACT将对所有编译器返回正确的值。
4.5 类型信息实现(Type Information Implementation)
这个特性与通过基类指针序列化对象也有关。实现此功能需要能够在运行时确定基类指针指向的对象的真实类型。不同的序列化系统以不同的方式实现这一点。在我们的系统中,默认方法是使用在支持RTTI(运行时类型信息)的系统中可用的函数typeid(…)。这在几乎所有情况下都是令人满意的,大多数使用此库的用户将不会在跳过本手册的本节中失去任何东西。
但是,有一些情况下,默认的类型确定系统不方便。某些平台可能不支持RTTI,或者它可能已被禁用以加速执行或出于某种其他原因。某些应用程序,例如运行时链接的插件模块,不能依赖于C++ RTTI来确定真实的派生类。RTTI仅对多态类(至少有一个虚函数的类)返回正确的类型。如果出现这些情况中的任何一种,可以替换自己的extended_type_info的实现。
所需以实现序列化的设施的接口在extended_type_info.hpp中定义。这些设施的默认实现是基于typeid(…)的,该实现在extended_type_info_typeid.hpp中定义。基于导出类标识符的替代实现在extended_type_info_no_rtti.hpp中定义。
通过调用宏:
BOOST_CLASS_TYPE_INFO(
my_class,
extended_type_info_no_rtti<my_class>
)
我们可以根据情况为每个类分配类型信息实现。并没有要求程序中的所有类都使用相同的 extended_type_info实现。这支持了每个类的序列化在一个可以在任何项目中包含而不进行更改的头文件中被指定的“一劳永逸”的概念。
test_no_rtti.cpp测试程序示例了这一点。其他实现是可能的,并且在某些特殊情况下可能是必要的。
4.6 包装器(Wrappers)
存档需要以不同于其他类型的方式处理包装器,因为例如,它们通常是非const对象,而输出存档要求任何序列化的对象(除包装器外)都必须是const。这个头文件wrapper.hpp包含以下代码:
namespace boost {
namespace serialization {
template<class T>
struct is_wrapper
: public mpl::false_
{};
} // namespace serialization
} // namespace boost
对于任何类T,boost::serialization::is_wrapper::value的默认定义是false。如果我们想声明一个类my_class是一个包装器,我们可以专门化version模板:
namespace boost {
namespace serialization {
struct is_wrapper<my_class>
: mpl::true_
{};
} // namespace serialization
} // namespace boost
为了减少输入并提高可读性,定义了一个宏,以便我们可以写成:
BOOST_CLASS_IS_WRAPPER(my_class)
这会扩展到上述代码。
4.7 位级序列化(Bitwise Serialization)
一些简单的类可以通过直接复制类的所有位来进行序列化。这尤其适用于不包含指针成员、不进行版本控制或跟踪的POD数据类型。一些归档格式,例如非可移植二进制归档,可以利用这些信息来大幅加速序列化过程。为了指示可以进行位级序列化,可以使用位于header文件is_bitwise_serializable.hpp中定义的类型特性:
namespace boost { namespace serialization {
template<class T>
struct is_bitwise_serializable
: public is_arithmetic<T>
{};
} }
可以用于其他类的专门化,而相应的宏可简化专门化的过程:
BOOST_IS_BITWISE_SERIALIZABLE(my_class)
4.8模板序列化特性(Template Serialization Traits)
在某些情况下,一次性为一组类分配序列化特性可能会很方便。考虑到name-value pair包装器:
template<class T>
struct nvp : public std::pair<const char *, T *>
{
...
};
它用于XML归档,将名称与类型为T的数据变量关联起来。这些数据类型从不被跟踪,也不进行版本控制。因此,您可能希望指定:
BOOST_CLASS_IMPLEMENTATION(nvp<T>, boost::serialization::level_type::object_serializable)
BOOST_CLASS_TRACKING(nvp<T>, boost::serialization::track_never)
检查这些宏的定义会发现,在使用模板参数时,它们不会展开为合理的代码。因此,与其使用便捷宏,不如使用原始定义:
template<class T>
struct implementation_level<nvp<T> >
{
typedef mpl::integral_c_tag tag;
typedef mpl::int_<object_serializable> type;
BOOST_STATIC_CONSTANT(
int,
value = implementation_level::type::value
);
};
// nvp对象通常在堆栈上创建,不进行跟踪
template<class T>
struct tracking_level<nvp<T> >
{
typedef mpl::integral_c_tag tag;
typedef mpl::int_<track_never> type;
BOOST_STATIC_CONSTANT(
int,
value = tracking_level::type::value
);
};
以将序列化特性分配给由模板nvp生成的所有类。请注意,只有在使用正确支持部分模板特化的编译器时,才能使用上述方法为模板分配特性。一种可能的方法是:
#ifndef BOOST_NO_TEMPLATE_PARTIAL_SPECIALIZATION
template<class T>
struct implementation_level<nvp<T> >
{
... // see above
};
// nvp对象通常在堆栈上创建,不进行跟踪
template<class T>
struct tracking_level<nvp<T> >
{
... // see above
};
#endif
当希望使代码和归档在其他平台上可移植时,这可能会引发问题。这意味着对象将根据所使用的平台进行不同方式的序列化。这意味着从一个平台保存的对象在另一个平台上无法正确加载。换句话说,归档不具备可移植性。
通过创建一种将序列化特性分配给用户类的方法来解决这个问题。这一点可以通过名值对的序列化来说明。
具体来说,这涉及从特殊类boost::serialization::traits中派生模板,该特殊类专门为特定组合的序列化特性进行了专门化。在查找序列化特性时,库首先检查是否已将此类用作基类。如果是这样,就使用相应的特性。否则,使用标准默认值。通过从序列化特性类中派生,而不是依赖于部分模板特化,可以将序列化特性应用于模板,并且这些特性将在所有已知平台上保持一致。
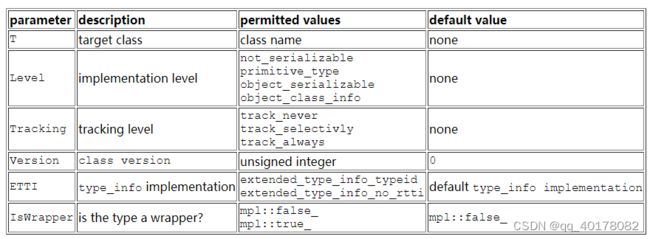
特性模板的签名如下:
template<
class T,
int Level,
int Tracking,
unsigned int Version = 0,
class ETII = BOOST_SERIALIZATION_DEFAULT_TYPE_INFO(T),
class IsWrapper = mpl::false_
>
struct traits
应根据以下表格为模板参数分配模板参数: