Go高质量编程
Go高质量编程
- 简介——编程原则
- 编码规范——如何编写高质量的Go代码
-
- 代码格式
- 注释
-
- 解释代码作用
- 解释代码如何做的
- 解释代码实现的原因
- 解释代码什么情况会出错
- 公共符号始终要注释
- 命名规范
-
- 变量variable
- 函数function
- 包package
- 控制流程
-
- 避免嵌套,保持正常流程清晰
- 尽量保持正常代码路径为最小缩进
- 小结
- 错误和异常处理
-
- 简单错误
- 错误的 Wrap 和 Unwrap
- 错误判定
- panic
- recover
- 小结
- 性能优化建议
-
- Benchmark
- Slice
- Map
- 字符串处理
- 空结构体
- atomic包
- 性能优化建议
在工作中,编程是团队合作的工程,简洁清晰的代码让其他人更容易在你的基础上开发,同时出问题的概率更低,大家更乐于与你合作,也让团队更高效。在面试的时候,也有编码环节,利用代码清晰地表达出思路,还能让面试官额外加分。每种语言都有自己的特性,对 Go 编程来说,也有一些性能优化的手段以及趁手的工具。本文主要介绍在实际工作中,如何分析性能问题并进行优化,基本原则和流程是怎么样的。
高质量:编写的代码能够达到正确可靠、简洁清晰的目标可称之为高质量代码。
- 正确性:各种边界条件是否考虑完备,错误的调用是否能够处理。
- 可靠性:异常情况或者错误的处理策略是否明确,依赖的服务出现异常是否能够处理。
- 简洁:逻辑是否简单,后续调整功能或新增功能是否能够快速支持。
- 清晰:其他人在阅读理解代码的时候是否能够清楚明白,重构或者修改功能是否不会担心出现无法预料的问题。
\newline
简介——编程原则
实际应用场景千变万化,各种语言的特性和语法各不相同,但是高质量编程遵循的原则是相通的。
- 简单性:消除”多余的复杂性”,以简单清晰的逻辑编写代码。在实际工程项目中,复杂的程序逻辑会让人害怕重构和优化,因为无法明确预知调整造成的影响范围。难以理解的逻辑,排查问题时也难以定位,不知道如何修复。
- 可读性:可读性很重要,因为代码是写给人看的,而不是机器。在项目不断迭代的过程中,大部分工作是对已有功能的完善或扩展,很少会完全下线某个功能,对应的功能代码实际会生存很长时间。已上线的代码在其生命周期内会被不同的人阅读几十上百次。听课时老师经常说的在课堂上不遵守纪律影响全班同学的时间,难以理解的代码会占用后续每一个程序员的时间。
- 生产力:编程在当前更多是团队合作,因此团队整体的工作效率是非常重要的一方面。为了降低新成员上手项目代码的成本,Go 语言甚至通过工具强制统一所有代码格式。编码是整个项目开发链路中的一个节点,遵循规范,避免常见缺陷的代码,能够降低后续联调、测试、验证、上线等各个节点的出现问题的概率,就算出现问题也能快速排查定位。
\newline
编码规范——如何编写高质量的Go代码
Google 官方和大规模采用 Go 的公司,比如 Uber 都有开源的编码规范文档,这里从中选择比较重要的公共约定部分进行介绍。
\newline
代码格式
推荐使用 gofmt 自动格式化代码,保证所有的 Go 代码与官方推荐格式保持一致,常见IDE都可以很方便地进行配置,像 Goland 内置了相关功能,直接开启即可在保存文件的时候自动格式化。

还可以考虑 goimports,也是 Go 语言官方提供的工具,会对依赖包进行管理,自动增删依赖的包引用,按
字母序排序分类,具体可以根据团队实际情况配置使用。

之所以将格式化放在第一条,因为这是后续规范的基础,团队合作 review 其他人的代码时就能体会到这条规范的作用了。
\newline
注释
注释应该做的:
- 注释应该解释代码作用
- 注释应该解释代码如何做的
- 注释应该解释代码实现的原因
- 注释应该解释代码什么情况会出错
\newline
解释代码作用
适合注释公共符号,比如对外提供的函数注释描述它的功能和用途,只有在函数的功能简单而明显时才能省略这些注释(例如,简单的取值和设置函数)。
// Open opens the named file for reading. If successful, methods on
// the returned file can be used for reading; the associated file
// descriptor has mode O_RDONLY.
// If there is an error, it will be of type *PathError.
func Open(name string) (*File, error) {
return OpenFile(name, O_RDONLY, 0)
}
另外注释要避免啰嗦,不要对显而易见的内容进行说明。下面的代码中注释就没有必要加上,通过名称可以很容易的知道作用。
// Returns true if the table cannot hold any more entries
func IsTableFull() bool
\newline
解释代码如何做的
适合注释实现过程,对代码中复杂的,并不明显的逻辑进行说明。
下面这段代码是给新 url 加上最近的 referer 信息,并不是特别明显,所以注释说明了一下。
// Add the Referer header from the most recent
// request URL to the new one, if it's not https->http:
if ref := refererForURL(reqs[len(reqs)-1].URL, req.URL); ref != "" {
req.Header.Set("Referer", ref)
}
下面的是一个反例,虽然是对过程注释,但是描述的是显而易见的流程,注意不要用自然语言直接翻译。代码作为注释,信息冗余还好,有时候表述不一定和代码一致。
// Process every element in the list
for e := range elements {
process(e)
}
\newline
解释代码实现的原因
适合解释代码的外部因素,这些因素脱离上下文后通常很难理解。以下示例中有一行 shouldRedirect = false 的语句,如果没有注释,无法清楚地明白为什么会设置 false。所以注释里提到了这么做的原因,给出了上下文说明。
switch resp.StatusCode {
// ...
case 307, 308:
redirectMethod = reqMethod
shouldRedirect = true
includeBody = true
if ireq.GetBody == nil && ireq.outgoingLength() != 0 {
// We had a request body, and 307/308 require
// re-sending it, but GetBody is not defined. So just
// return this response to the user instead of an
// error, like we did in Go 1.7 and earlier.
shouldRedirect = false
}
}
\newline
解释代码什么情况会出错
适合解释代码的限制条件,注释应该提醒使用者一些潜在的限制条件或者会无法处理的情况。例如函数的注释中可以说明是否存在性能隐患,输入的限制条件,可能存在哪些错误情况,让使用者无需了解实现细节。示例介绍了解析时区字符串的流程,同时对可能遇到的不规范字符串处理进行了说明。
// parseTimeZone parses a time zone string and returns its length. Time zones
// are human-generated and unpredictable. We can't do precise error checking.
// On the other hand, for a correct parse there must be a time zone at the
// beginning of the string, so it's almost always true that there's one
// there. We look at the beginning of the string for a run of upper-case letters.
// If there are more than 5, it's an error.
// If there are 4 or 5 and the last is a T, it's a time zone.
// If there are 3, it's a time zone.
// Otherwise, other than special cases, it's not a time zone.
// GMT is special because it can have an hour offset.
func parseTimeZone(value string) (length int, ok bool)
\newline
公共符号始终要注释
包中声明的每个公共的符号:变量、常量、函数以及结构都需要添加注释。
Google Style 指南中有两条规则:任何既不明显也不简短的公共功能必须予以注释;无论长度或复杂程度如何,对库中的任何函数都必须进行注释。
下方的示例是一个公共函数的注释说明,结合之前提到的规范,注释表述了函数的功能和如何工作的。
// ReadAll reads from r until an error or EOF and returns the data it read.
// A successful call returns err == nil, not err == EOF. Because ReadAll is
// defined to read from src until EOF, it does not treat an EOF from Read
// as an error to be reported.
func ReadAll(r Reader) ([]byte, error)
有一个例外,不需要注释实现接口的方法,具体不要像下图这样做,图里的注释没有提供有用的信息,它没有告诉你这个方法做了什么,更糟糕是它告诉你去看其他地方的文档。在这种情况下,建议完全删除该注释。
// Read implements the io.Reader interface
func (r *FileReader) Read(buf []byte) (int, error)
以下是 go 仓库中相对完整的代码块,图中 LimitReader 的功能有注释说明,然后是 LimitedReader 结构体的说明,就在使用它的函数之前,LimitedReader.Read 的声明遵循 LimitedReader 本身的声明,里面已经有详细说明,所以没有注释。
// LimitReader returns a Reader that reads from r
// but stops with EOF after n bytes.
// The underlying implementation is a *LimitedReader.
func LimitReader(r Reader, n int64) Reader { return &LimitedReader{r, n} }
// A LimitedReader reads from R but limits the amount of
// data returned to just N bytes. Each call to Read
// updates N to reflect the new amount remaining.
// Read returns EOF when N <= 0 or when the underlying R returns EOF.
type LimitedReader struct {
R Reader // underlying reader
N int64 // max bytes remaining
}
func (l *LimitedReader) Read(p []byte) (n int, err error) {
if l.N <= 0 {
return 0, EOF
}
if int64(len(p)) > l.N {
p = p[0:l.N]
}
n, err = l.R.Read(p)
l.N -= int64(n)
return
}
\newline
命名规范
变量variable
- 简洁胜于冗长
- 缩略词全大写,但当其位于变量开头且不需要导出时,使用全小写。例如使用 ServeHTTP 而不是 ServeHttp
;使用 XMLHTTPRequest 或者 xmlHTTPRequest - 变量距离其被使用的地方越远,则需要携带越多的上下文信息。全局变量在其名字中需要更多的上下文信息,使得在不同地方可以轻易辨认出其含义。
以下这个循环的代码示例,在 i 和 index 作用域仅在 for 循环内部时,变量名 index 没有增加对程序的理解,基本是一样的,所以用更简单的 i 是好的。如果索引的作用域扩展,在循环外也会用到的时候,可以考虑更符合需求的名称。
// LimitReader returns a Reader that reads from r
// but stops with EOF after n bytes.
// The underlying implementation is a *LimitedReader.
func LimitReader(r Reader, n int64) Reader { return &LimitedReader{r, n} }
// A LimitedReader reads from R but limits the amount of
// data returned to just N bytes. Each call to Read
// updates N to reflect the new amount remaining.
// Read returns EOF when N <= 0 or when the underlying R returns EOF.
type LimitedReader struct {
R Reader // underlying reader
N int64 // max bytes remaining
}
func (l *LimitedReader) Read(p []byte) (n int, err error) {
if l.N <= 0 {
return 0, EOF
}
if int64(len(p)) > l.N {
p = p[0:l.N]
}
n, err = l.R.Read(p)
l.N -= int64(n)
return
}
以下例子是函数参数的名称示例,为了简短,将时间参数 deadline 改成了 t,t 常代指任意时间,deadline 指截止时间,有特定的含义。函数提供给外部调用时,签名的信息很重要,要将自己的功能准确表现出来,自动提示一般也会提示函数的方法签名,通过参数名更好的理解功能很有必要,节省时间。
// Good
func(c *Client) send(req *Request, deadline time.Time)
// Bad
func(c *Client) send(req *Request, t time.Time)
函数function
- 函数名不携带包名的上下文信息,因为包名和函数名总是成对出现的
- 函数名尽量简短
- 当名为 foo 的包某个函数返回类型 Foo 时,可以省略类型信息而不导致歧义
- 当名为 foo 的包某个函数返回类型 T 时(T 并不是 Foo) ,可以在函数名中加入类型信息
http 包中创建服务的函数如何命名更好?
func Serve(l net.Listener, handler Handler) error
func ServeHTTP(l net.Listener, handler Handlen) error
第一种更好,实际情况中,在调用 http 包的 Server 方法时,代码是 http.Server,携带有 http 包名,所以函数名中无需添加包信息。
\newline
包package
比函数更高一层的就是包,如何对包进行更好的命名也有一些经验:
- 只由小写字母组成。不包含大写字母和下划线等字符。
- 简短并包含一定的上下文信息。例如 schema、task 等。
- 不要与标准库同名。例如不要使用 sync 或者 strings。
以下规则尽量满足,以标准库包名为例:
- 不使用常用变量名作为包名。例如使用 bufio 而不是 buf
- 使用单数而不是复数。例如使用 encoding 而不是 encodings
- 逼慎地使用缩写。例如使用 fmt 在不破坏上下文的情况下比 format 更加简短
标准库有很多地方在使用,同时使用时需要指定别名,比较麻烦。需要用多个单词表达上下文的命名可以使用缩写,例如使用 strconv 而不是 stringconversion。包名也涉及到项目代码结构的划分和层次安排,具体名称不同项目会有细微差异,实际保持项目内风格统一。
总体来说,命名的核心目标是降低阅读理解代码的成本,重点考虑上下文信息,设计简洁清晰的名称。人们在阅读理解代码的时候会尝试模拟计算机运行程序,好的命名能让人把关注点留在主流程上,清晰地理解程序的功能,避免频繁切换到分支细节,增加理解成本。
\newline
控制流程
避免嵌套,保持正常流程清晰
从最简单的一个 if else 条件开始,如果两个分支都包含 return 语句,则可以去除冗余的 else,方便后续维护。else 一般是正常流程,不过如果需要在正常流程新增判断逻辑,避免分支嵌套。
// Bad
if foo {
return x
} else {
return nil
}
// Good
if foo {
return x
}
return nil
\newline
尽量保持正常代码路径为最小缩进
- 优先处理错误情况/特殊情况,尽早返回或继续循环来减少嵌套
- 最常见的正常流程的路径被嵌套在两个 if 条件内
- 成功的退出条件是 return nil,必须仔细匹配大括号来发现
- 函数最后一行返回一个错误,需要追溯到匹配的左括号,才能了解何时会触发错误
- 如果后续正常流程需要增加一步提作,调用新的函数,则又会增加一层嵌套
以下为多层嵌套情况的代码:
// Bad
func OneFunc() error {
err := doSomething()
if err == nil {
err := doAnotherThing()
if err == nil {
return nil // normal case
}
return err
}
return err
}
调整后的代码如下,调整后的代码从上到下就是正常流程的执行过程。初步阅读代码时可以先忽略每一步的 err 情况,对整体流程有更清晰的了解,如果后续想排查问题可以针对具体某一步的错误详细分析。如果后续正常流程新增操作,可以放心地在函数中添加新的代码。
// Good
func OneFunc() error {
err := doSomething(); err != nil {
return err
}
if err := doAnotherThing(); err != nil {
return err
}
return nil // normal case
}
下面是go仓库中的代码示例,也是优先处理err情况,保持正常流程的统一。
func (b *Reader) UnreadByte() error {
if b.lastByte < 0 || b.r == 0 && b.w > 0 {
return ErrInvalidUnreadByte
}
// b.r > 0 || b.w == 0
if b.r > 0 {
b.r--
} else {
// b.r == 0 && b.w == 0
b.w = 1
}
b.buf[b.r] = byte(b.lastByte)
b.lastByte = -1
b.lastRuneSize = -1
return nil
}
\newline
小结
- 线性原理,处理逻辑尽量走直线,避免复杂的嵌套分支
- 正常流程代码沿着屏幕向下移动
- 提升代码可维护性和可读性
- 故障问题大多出现在复杂的条件语句和循环语句中
Go 语言代码不是成功的路径越来越深地嵌套到右边,而是随着函数的执行,正常流程代码会沿着屏幕向下移动。一个功能如果可以通过多个功能的线性结合来实现,那它的结构就会非常简单。反过来,用条件分支控制代码、毫无章法地增加状态数等行为会让代码变得难以理解。需要避免这些行为,提高代码的可读性。如果能让正常流程自上而下、简单清晰地进行处理,代码的可读性就会大幅提高,与此同时,可维护性也将提高,添加功能等改良工作将变得更加容易。故障问题大多出现在复杂的条件语句和循环语句中,在维护这种逻辑时,添加功能会变成高风险的操作,很容易遗漏部分条件导致问题。
\newline
错误和异常处理
简单错误
- 简单的错误指的是仅出现一次的错误,且在其他地方不需要捕获该错误
- 优先使用 errors.New 来创建匿名变量来直接表示简单错误
- 如果有格式化的需求,使用 fmt.Errorf
示例是 go 仓库中的一段代码,定义了简单错误,描述失败原因:
func defaultCheckRedirect(req *Request, via []*Request) error {
if len(via) >= 10 {
return errors.New("stopped after 10 redirects")
}
return nil
}
\newline
错误的 Wrap 和 Unwrap
- 错误的 Wrap 实际上是提供了一个 error 嵌套另一个 error 的能力,从而生成一个 error 的跟踪链,同时结合错误的判定方法来确认调用链中是否有关注的错误出现。这个能力的好处是每一层调用方可以补充自己对应的上下文,方便跟踪排查问题,确定问题的根本原因在哪里。
- 在 fmt.Errorf 中使用: %w 关键字来将一个错误关联至错误链中。
list, _, err := c.GetBytes(cache.Subkey(a.actionID, "srcfiles"))
if err != nil {
return fmt.Errorf("reading srcfiles list: %w", err)
}
Go1.13 在 errors 中新增了三个新 API 和一个新的 format 关键字,分别是 errors.Is errors.As,errors.Unwrap 以及 fmt.Errorf 的%w。如果项目运行在小于 Go1.13 的版本中,导入 golang.org/x/xerrors 来使用。
\newline
错误判定
- 判定一个错误是否为特定错误,使用 errors.Is
- 不同于使用 ==,使用该方法可以判定错误链上的所有错误是否含有特定的错误
data, err = lockedfile.Read(targ)
if errors.Is(err, fs.ErrNotExist) {
// Treat non-existent as empty, to bootstrap the "latest" file
// the first time we connect to a given database.
return []byte{}, nil
}
return data, err
- 在错误链上获取特定种类的错误,使用 errors.As。它和 is 的区别在于 as 会提取出调用链中指定类型的错误,并将错误赋值给定义好的变量,方便后续处理,示例中是把问题的path打印出来了。
if _, err := os.Open("non-existing"); err != nil {
var pathError *fs.PathError
if errors.As(err, &pathError) {
fmt.Println("Failed at path:", pathError.Path)
} else {
fmt.Println(err)
}
}
\newline
panic
在 Go 中,比错误更严重的就是 panic,它的出现表示程序无法正常工作了,在使用时应该注意:
- 不建议在业务代码中使用 panic,因为 panic 发生后,会向上传播至调用栈顶,如果当前 goroutine 中所有 deferred 函数都不包含 recover 就会造成整个程序崩溃
- 若问题可以被屏蔽或解决,建议使用 error 代替 panic
- 当程序启动阶段发生不可逆转的错误时,可以在 init 或 main 函数中使用 panic,因为在这种情况下,服务启动起来也不会有意义。
以下示例是启动消息队列监听器的逻辑,在创建消费组失败的时候会 Panic,实际打印日志,然后抛出panic。
func main() {
// ...
ctx, cancel := context.WithCancel(context.Background())
client, err := sarama.NewConsumerGroup(strings.Split(brokers, ","), group, config)
if err != nil {
log.Panicf("Error creating consumer group client: %v", err)
}
// ...
}
// Panicf is equivalent to Printf() followed by a call to panic().
func Panicf(format string, v ...interface()){
s := fmt.Sprintf(format, v...)
std.Output(2, s)
panic(s)
}
\newline
recover
- recover 只能在被 defer 的函数中使用
- 嵌套无法生效
- 只在当前 goroutine 生效
- defer 的语句是后进先出
func (s *ss) Token(skipSpace bool, f func(rune) bool) (tok []byte, err error) {
defer func() {
if e := recover(); e != nil {
if se, ok := e.(scanError); ok {
err = se.err
} else {
panic(e)
}
}
}()
// ...
}
- 如果需要更多的上下文信息,可以 recover 后在 log 中记录当前的调用栈,出现问题时能够方便分析定位。示例中的 debug.Stack() 包含的调用堆栈信息,方便定位具体问题代码。
func (t *treeFS) Open(name string) (f fs.File, err error) {
defer func() {
if e := recover(); e != nil {
f = nil
err = fmt.Errorf("gitfs panic: %v\n%s", e, debug.Stack())
}
}()
// ...
}
\newline
小结
- error 尽可能提供简明的上下文信息链,方便定位问题
- panic 用于真正异常的情况
- recover 生效范围,在当前 goroutine 的被 defer 的函数中生效
因为错误和异常是不正常的情况,除了希望程序能兼容这些场景外,重要的也有记录问题的上下文信息,方便后续定位问题。在明确panic,recover这些功能的作用范围的情况下,编写更可靠的程序。
以下例子中,Now 和 NowTime 中哪个方法名更好?

实际调用时,Now 和 NowTime 返回的是 time.Time 类型,使用时没有必要写成 time.NowTime 来额外表示时间信息,使用 Now 更简洁。

另外一个例子中,Parse 和 ParseDuration 哪个方法名更好?

实际调用时,使用 time.Parse 很容易让人误以为是在解析 time 类型的字符串,使用 time.ParseDuration 返回的是 time.Duration 类型,这种情况在函数命名中体现是不冗余的,用 ParseDuration 更好。

以下例子,程序的输出是什么?

最终输出:31
- defer 语句会在函数返回前调用
- 多个 defer 语句是后进先出
\newline
性能优化建议
高质量的代码能够完成功能,但是在大规模程序部署的场景,仅仅支持正常功能还不够,我们还要尽能的提升性能,节省资源成本。
- 性能优化的前提是满足正确可靠、简洁清晰等质量因素
- 性能优化是综合评估,有时候时间效率和空间效率可能对立
- 针对 Go 语言特性,介绍 Go 相关的性能优化建议
Go 语言常见性能优化建议的对比测试 代码地址 ,以下代码案例均来自于这个网址。
\newline
Benchmark
如何使用:
- 性能表现需要实际数据衡呈
- Go 语言提供了支持基准性能测试的 benchmark 工具
性能表现要用数据来验证,Go自带了性能评估工具。
以计算斐波拉契数列的函数为例,分两个文件,fib.go 编写函数代码,fib test.go 编写 benchmark 的逻辑。

通过命令运行 benchmark 可以得到测试结果,-benchmem 表示也统计内存信息。
go test -bench=. -benchmem
结果说明:

BenchmarkFib10 是测试函数名,-8 表示 GOMAXPROCS 的值为8,1855870表示一共执行1855870次,即 b.N 的值,602.5 ns/op 表示每次执行花费602.5ns,0 allocs/op 表示每次执行申请的内存为0,后续就通过这种 benchmark 结果来对比分析不同代码的性能表现。
\newline
Slice
slice 是 go 中最常用的结构,也很方便,在使用过程中应注意:
- 预分配内存,尽可能在使用 make() 初始化切片时提供容量信息,特别是在追加切片时。对比以下两种情况的性能表现,第一个是没有提供初始化容量信息,第二个是设置了容量大小。


结果中可以看出执行时间相差很多,预分配只有一次内存分配。

slice的结果:
- 切片本质是一个数组片段的描述包括:数组指针,片段的长度,片段的容量(不改变内存分配情况下的最大长度)
- 切片操作并不复制切片指向的元素
- 创建一个新的切片会复用原来切片的底层数组

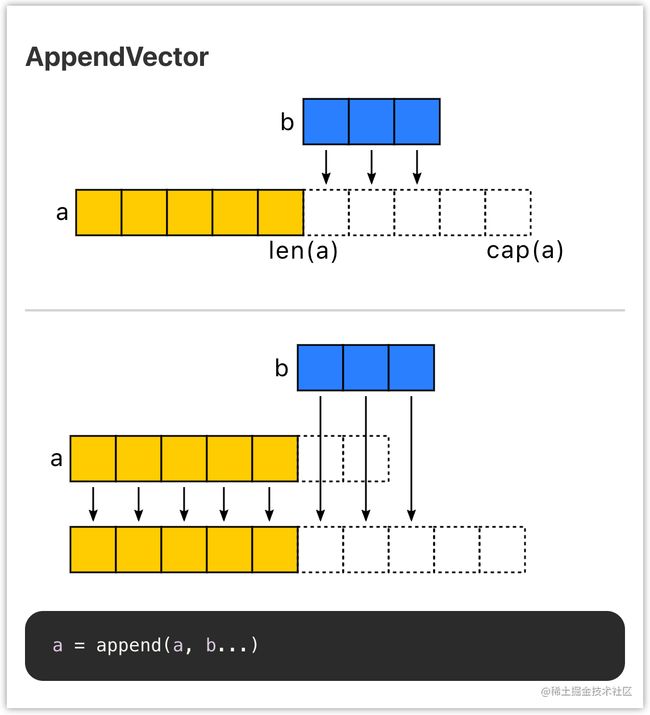
以切片的 append 为例,append 时有两种场景: - 当 append 之后的长度小于等于 cap,将会直接利用原底层数组剩余的空间。
- 当 append 后的长度大于 cap 时,则会分配一块更大的区域来容纳新的底层数组。
因此,为了避免内存发生拷贝,如果能够知道最终的切片的大小,预先设置 cap 的值能够避免额外的内存分配,获得更好的性能。
另一个陷阱:大内存未释放
- 在已有切片基础上创建切片,不会创建新的底层数组
- 场景:原切片较大,代码在原切片基础上新建小切片;原底层数组在内存中有引用,得不到释放
- 可使用 copy 替代 re-slice
如下两部分代码,使用了不同的逻辑取 slice 的最后两位数创建新数组,同时统计输出了内存占用信息。


go test -run=. -v
结果差异非常明显,lastBySlice 耗费了 100.14 MB 内存,也就是说,申请的 100 个 1 MB 大小的内存没有被回收。切片虽然只使用了最后 2 个元素,但是与原来 1M 的切片引用了相同的底层数组,底层数组得不到释放,因此,最终 100 MB 的内存始终得不到释放,而 lastByCopy 仅消耗了 3.14MB 的内存。这是因为,通过 copy,指向了一个新的底层数组,当 origin 不再被引用后,内存会被垃圾回收。

\newline
Map
map 也有预分配的性能优化点。如下两部分代码,一个预分配了内存,一个没有。


结果差异非常明显,对于 Map,预分配内存也可以优化性能。这是因为不断向 map 中添加元素的操作会触发 map 的扩容,如果提前分配好空间,可以减少内存持贝和 Renash 的消耗,因此建议根据实际需求提前预估好需要的空间。
![]()
\newline
字符串处理
编程过程中除了slice 和 map,平时很多编码功能都和字符串处理相关的,字符串处理也是高频操作,使用strings.Builder。
以下是三种常见的字符串拼接方式:



结果如下:可以看到使用 + 拼接性能最差,strings.Builder,bytes.Buffer 相近,strings.Builder 更快。这是因为字符串在 Go 语言中是不可变类型,占用内存大小是固定的,使用 + 每次都会更新分配内存。当使用 + 拼接 2 个字符串时,生成一个新的字符串,那么就需要开辟一段新的空间,新空间的大小是原来两个字符串的大小之和。拼接第三个字符串时,再开辟一段新空间,新空间大小是三个字符串大小之和,以此类推。
strings.Builder,bytes.Bufer 底层都是 []byte 数组,内存扩容策略使得不需要每次拼接重新分配内存。

为什么 strings.Builder 会比 bytes.Buffer 更快一些,可以看看实际的代码。bytes.Buffer 转化为字符串时重新申请了一块空间,而strings.Builder 直接将底层的Dbyte 转换成了字符串类型返回。


除了使用 strings.Builder 外,字符串拼接和 slice 一样,同样支持预分配,在预知字符串长度的情况下,可以进一步提升拼接性能。如下:


结果如下:这里能确认 stringbuiler 只有一次内存分配,bytebuffer 有两次。

\newline
空结构体
性能优化有时是时间和空间的平衡,之前提到的都是提高时间效率的点,对于空间上也有优化的手段。
空结构体是节省内存空间的一个手段。空结构体 struct{} 实例不占据任何的内存空间,可作为各种场景下的占位符使用,能够节省资源,空结构体本身具备很强的语义,即这里不需要任何值,仅作为占位符。

结果如下:空结构体占用内存更少些,在元素更多的情况下会更明显。实现 Set,可以考虑用 map 来代替;对于这个场景,只需要用到 map 的键,而不需要值,即使是将 map 的值设置为 bool 类型,也会多占据 1 个字节空间。
![]()
一个开源实现:https://github.com/deckarep/golang-set/blob/main/threadunsafe.go
\newline
atomic包
在工作中会遇到多线程编程的场景,比如实现一个多线程共用的计数器,如何保证计数准确,线程安全,有不同的方式。以下实例展示了如何使用atomic包:


结果如下,可以看到使用 atomic 包性能会好一点。
![]()
- 锁的实现是通过操作系统来实现,属于系统调用
- atomic 操作是通过硬件实现,效率比锁高
- sync.Mutex 应该用来保护一段逻辑,不仅仅用于保护一个变量
- 对于非数值操作,可以使用 atomic.Value,能承载一个 interface{}
\newline
性能优化建议
- 避免常见的性能陷阱可以保证大部分程序的性能
- 普通应用代码,不要一味地追求程序的性能
- 越高级的性能优化手段越容易出现问题
- 在满足正确可靠、简洁清晰的质量要求的前提下提高程序性能