Pyspark+TIDB
kettle
数据库连接测试
视图主对象树 -> 转换 ->右键新建 -> 直接快捷键Ctrl + S另存为test.ktr(自定义后缀,这里建议使用.ktr)选中DB连接,操作验证相关数据库是否能正确连接,这里以MySQL数据库为例。
Kettle作业和转换
- 转换:一般文件后缀命名为.ktr ,单表迁移数据,构建表输入(读取数据),表输出(写入数据),Linux下使用kitchen.sh脚本调用执行
- 作业:文件后缀为.kjb,可以关联多个.ktr执行,实现多表(串行/并行)迁移数据,Linux下使用pan.sh脚本调用执行
数据迁移(性能优化)
https://blog.csdn.net/JustinQin/article/details/120043364
- Kettle作业优化:作业是指对多个转换或其他任务进行调度和控制的过程,可以设置作业的并发执行、错误处理、日志记录等参数。一般来说,可以根据目标表的大小和数量,将一个大表拆分成多个小表,或者将多个小表合并成一个大表,以提高作业的执行效率。
- Kettle转换优化:转换是指对数据进行抽取、转换和加载的过程,可以设置转换的输入输出步骤、缓冲区大小、批量提交等参数。一般来说,可以根据源表和目标表的字段类型和数量,选择合适的输入输出步骤,如表输入、表输出、插入/更新等。同时,可以根据数据量的大小,调整缓冲区大小和批量提交的数量,以减少内存占用和数据库连接次数。
- Kettle连接数据库参数优化:Kettle连接数据库时,可以设置一些参数来影响数据库的性能,如连接超时、自动提交、事务隔离级别等。一般来说,可以根据数据迁移的需求和数据库的特性,选择合适的参数值,如设置较短的连接超时时间、关闭自动提交、降低事务隔离级别等。
- JVM内存大小优化:Kettle是基于Java实现的工具,运行时需要消耗JVM内存。如果JVM内存不足或过多,都会影响Kettle的性能。一般来说,可以根据数据迁移的规模和服务器的配置,调整JVM内存大小,如设置-Xms和-Xmx参数等。
- 目标表字段索引优化:目标表字段索引是指为目标表创建一些索引来提高查询效率。但是,在数据迁移过程中,索引也会影响插入效率。一般来说,在数据迁移之前,可以临时删除目标表的字段索引,在数据迁移之后再重新创建。
使用binlog数据做数据迁移
数据抽取是 ETL 流程的第一步。我们会将数据从 RDBMS 或日志服务器等外部系统抽取至数据仓库,进行清洗、转换、聚合等操作。开源项目 Apache Sqoop并不支持实时的数据抽取。MySQL **Binlog 则是一种实时的数据流,用于主从节点之间的数据复制,我们可以利用它来进行数据抽取。**借助阿里巴巴开源的 Canal 项目,我们能够非常便捷地将 MySQL 中的数据抽取到任意目标存储中。
- 配置 MySQL 主节点:开启 Binlog,binlog_format 必须设置为 ROW, 因为在 STATEMENT 或 MIXED 模式下, Binlog 只会记录和传输 SQL 语句(以减少日志大小),而不包含具体数据,我们也就无法保存了。
- 启动 Canal 服务端:指定服务端监听的端口
- 编写 Canal 客户端:从服务端消费变更消息时,我们需要创建一个 Canal 客户端,指定需要订阅的数据库和表,并开启轮询。
- 加载至数据仓库:数据可以归类成基础数据和增量数据。如昨日的 user 表是基础数据,今日变更的行是增量数据。通过 FULL OUTER JOIN,我们可以将基础和增量数据合并成一张最新的数据表,并作为明天的基础数据。
spark
UDF
Spark 提供了大量内建函数,它的灵活性让数据工程师和数据科学家可以定义自己的函数。这些函数被称为用户自定义函数(user-defined function,UDF)。UDF分为两种类型:临时函数和永久函数。临时函数只在当前会话中有效,退出后重新连接就无法使用;永久函数则会将UDF信息注册到MetaStore元数据中,可以永久使用。
永久函数
-
创建永久函数的步骤如下:
- 首先,需要使用pyspark.sql.functions模块中的udf()方法将Python函数转换为UDF对象,并指定返回类型。例如:
from pyspark.sql.functions import udf from pyspark.sql.types import StringType def upper_case(str): return str.upper() upper_case_udf = udf(upper_case, StringType())复制
- 然后,需要使用spark.udf.register()方法将UDF对象注册为永久函数,并指定函数名。例如:
spark.udf.register("upper_case", upper_case_udf)复制
- 最后,就可以在Hive或Spark SQL中调用自定义的永久函数对数据进行处理了例如:
SELECT upper_case(name) FROM student;
UDAF
首先,需要导入pyspark.sql.expressions.Aggregator模块,并继承Aggregator类来实现自定义的聚合逻辑。然后,需要使用udaf函数将Aggregator对象转换为Spark UDAF函数。最后,可以在DataFrame上使用该UDAF函数,或者在Spark SQL中注册该UDAF函数并使用它。
pyspark读取TIDB数据库
tidb可以使用pyspark来进行数据分析和处理。pyspark是Spark的Python接口,可以利用Spark的分布式计算能力来处理大规模的数据。tidb已经集成了Spark框架,可以直接使用Spark连接tidb通过写SQL操作数据。tidb也提供了一个pytispark的包,可以在pyspark中使用TiContext类来访问tidb的数据库和表。 要在tidb中使用pyspark,您需要先安装pyspark和pytispark的包。然后,您可以在pyspark中创建一个SparkSession对象,并使用TiContext类来连接tidb的数据库和表。例如,以下是一个简单的代码示例,展示了如何在pyspark中读取tidb的一个表:
# 导入pyspark和pytispark
from pyspark.sql import SparkSession
from pytispark.pytispark import TiContext
# 创建一个SparkSession对象
spark = SparkSession.builder.appName("pyspark_tidb").getOrCreate()
# 创建一个TiContext对象,连接tidb的数据库
ti = TiContext(spark)
ti.tidbMapDatabase("test")
# 读取tidb的一个表,返回一个DataFrame对象
df = spark.sql("select * from test.user")
# 显示DataFrame的内容
df.show()
DataFrame转Excel
要使用pyspark从tidb中读取数据并保存为excel文件,您可以参考以下步骤:
- 首先,您需要安装pyspark和pytispark的包,以及一个能够写入excel文件的包,例如xlsxwriter。
- 然后,您可以在pyspark中创建一个SparkSession对象,并使用TiContext类来连接tidb的数据库和表,如之前的示例所示。
- 接着,您可以使用pyspark的DataFrame API或者SQL语句来对tidb中的数据进行分析和处理。
- 最后,您可以将pyspark的DataFrame转换为pandas的DataFrame,然后使用to_excel方法来将其保存为excel文件。例如,以下是一个简单的代码示例,展示了如何将tidb中的user表保存为excel文件:
# 导入pyspark和pytispark
from pyspark.sql import SparkSession
from pytispark.pytispark import TiContext
# 创建一个SparkSession对象
spark = SparkSession.builder.appName("pyspark_tidb").getOrCreate()
# 创建一个TiContext对象,连接tidb的数据库
ti = TiContext(spark)
ti.tidbMapDatabase("test")
# 读取tidb的一个表,返回一个DataFrame对象
df = spark.sql("select * from test.user")
# 导入pandas和xlsxwriter
import pandas as pd
import xlsxwriter
# 将pyspark的DataFrame转换为pandas的DataFrame
pdf = df.toPandas()
# 将pandas的DataFrame保存为excel文件
pdf.to_excel("user.xlsx", engine="xlsxwriter")
TICONTEXT类
TiContext类是pytispark包中的一个类,它可以用来在pyspark中访问tidb的数据库和表。pytispark是一个将TiSpark与PySpark结合的包,它可以让用户在pyspark中使用TiSpark的功能,例如使用Spark SQL来操作tidb的数据。TiContext类是pytispark的核心类,它提供了以下几个方法:
tidbMapDatabase(dbName):将tidb的数据库映射到Spark SQL的catalog中,可以使用spark.sql或者spark.table来访问tidb的表。tidbMapTable(dbName, tableName):将tidb的表映射到Spark SQL的catalog中,可以使用spark.sql或者spark.table来访问tidb的表。tidbTable(dbName, tableName):返回一个DataFrame对象,表示tidb的表。sql(query):在tidb中执行SQL语句,返回一个DataFrame对象,表示查询结果。
要使用TiContext类,您需要先创建一个SparkSession对象,并传入一个TiConfiguration对象,用来配置tidb的地址和端口等信息。然后,您可以使用TiContext(spark)来创建一个TiContext对象,并调用其方法来操作tidb的数据。例如,以下是一个简单的代码示例,展示了如何在pyspark中使用TiContext类:
# 导入pyspark和pytispark
from pyspark.sql import SparkSession
from pytispark.pytispark import TiContext
# 创建一个TiConfiguration对象,配置tidb的地址和端口
from tikv_client import TiConfiguration
conf = TiConfiguration("127.0.0.1:2379")
# 创建一个SparkSession对象,并传入TiConfiguration对象
spark = SparkSession.builder.appName("pyspark_tidb").config(conf).getOrCreate()
# 创建一个TiContext对象
ti = TiContext(spark)
# 将tidb的数据库映射到Spark SQL的catalog中
ti.tidbMapDatabase("test")
# 使用spark.sql方法执行SQL语句,查询tidb的表
df = spark.sql("select * from test.user")
# 显示DataFrame的内容
df.show()
Sparksession
SparkSession对象是Spark 2.0版本引入的一个新概念,它是Spark编程的统一入口,可以用来创建和操作DataFrame,注册和查询表,缓存表,读取parquet文件等。SparkSession对象可以替代SparkContext,SQLContext和HiveContext的功能,简化了Spark编程的复杂性。要创建一个SparkSession对象,可以使用以下的构建器模式:
# 导入pyspark.sql模块
from pyspark.sql import SparkSession
# 使用builder方法创建一个SparkSession对象,并设置一些属性
spark = SparkSession.builder\
.master("local")\
.appName("Word Count")\
.config("spark.some.config.option", "some-value")\
.getOrCreate()
上面的代码会创建一个名为Word Count的SparkSession对象,并设置了运行模式和一些配置选项。然后,可以通过spark对象来进行各种操作,例如:
# 从文件中读取数据,返回一个DataFrame对象
df = spark.read.text("file:///data/word.txt")
# 注册一个临时视图,可以用SQL语句来查询
df.createOrReplaceTempView("words")
# 使用sql方法执行SQL语句,返回一个DataFrame对象
result = spark.sql("select word, count(*) as count from words group by word")
# 显示结果
result.show()
TIDB
TIDB数据库是一个开源的分布式关系型数据库,它支持在线事务处理(OLTP)和在线分析处理(OLAP)的混合场景,具有以下几个核心特点:
- 高度兼容MySQL:TIDB数据库可以无缝迁移MySQL的数据和应用,支持MySQL的语法和协议,无需修改代码。
- 水平弹性扩展:TIDB数据库可以通过简单地增加节点来实现计算和存储的水平扩展,轻松应对高并发和海量数据的挑战。
- 分布式事务支持:TIDB数据库完全支持ACID事务,保证数据的一致性和完整性。
- 真正金融级高可用:TIDB数据库采用Raft协议实现数据的多副本复制,能够自动恢复故障,提供金融级的数据安全保障。
- 一站式HTAP解决方案:TIDB数据库结合TiSpark组件,可以提供一站式的混合事务和分析处理能力,无需传统的ETL过程,实现实时的数据分析和挖掘。
- 云原生SQL数据库:TIDB数据库是为云而设计的数据库,与Kubernetes深度集成,支持公有云、私有云和混合云的部署和运维。
Raft协议与主从复制
TIDB 是一个基于 Raft 协议的分布式数据库,它使用 Raft 来实现数据的复制和容灾。Raft 是一种分布式一致性算法,它可以保证在集群中的多个节点之间同步数据,并在节点发生故障时自动选举出新的领导者(leader)来继续提供服务。Raft 有以下几个优点:
- 简单易懂:Raft 的设计和实现都非常清晰,它避免了复杂的细节和边界情况,使得开发者和用户都能够容易地理解和使用它。
- 容错性强:Raft 可以容忍集群中任意少于一半的节点同时发生故障,而不影响数据的一致性和可用性。Raft 还提供了日志压缩、成员变更、领导者转移等功能,来增强系统的稳定性和灵活性。
- 高效性能:Raft 通过减少消息的交换次数、优化日志的复制方式、利用租约(lease)机制等方法,来提高系统的吞吐量和响应时间。
TIDB 使用 Raft 协议比主从复制好,主要有以下几个原因:
- 主从复制是一种异步的复制方式,它不能保证数据在多个节点之间的强一致性,可能会导致数据丢失或不一致的问题。
- 主从复制依赖于一个单点的主节点来提供写入服务,如果主节点发生故障,需要手动切换到备节点,这会造成服务中断和延迟。
- 主从复制需要维护多个备节点来提高可用性,但是这些备节点都是被动的,不能对外提供读写服务,造成资源的浪费。
raft协议内容
Raft协议是一种分布式一致性算法,它可以保证在集群中的多个节点之间同步数据,并在节点发生故障时自动选举出新的领导者(leader)来继续提供服务。Raft协议的核心内容可以分为以下几个部分:
- 领导者选举(Leader Election):当集群中没有领导者或者领导者失效时,任意一个跟随者(follower)节点可以发起投票,请求成为新的领导者。其他节点可以根据一定的规则决定是否投票给该候选者(candidate)。当一个候选者获得了集群中大多数节点的投票时,它就成为了新的领导者,并向其他节点发送心跳消息(heartbeat)来维持自己的地位。
- 日志复制(Log Replication):当领导者接收到客户端的更新请求时,它会把该请求作为一个日志条目(log entry)追加到自己的日志中,并尝试将该日志条目复制到其他节点。当一个日志条目被集群中大多数节点接收并写入到日志中时,它就被认为是已提交(committed)的,并且可以被应用到状态机(state machine)中。Raft协议保证了所有节点的日志最终会达到一致的状态。
- 容错恢复(Fault Tolerance):当集群中发生网络分区、节点故障或者消息丢失等异常情况时,Raft协议可以通过一些机制来恢复正常的工作状态。例如,当一个旧的领导者重新加入集群时,它会接受新的领导者的日志,并且回滚自己未提交的日志条目。当一个跟随者落后于领导者太多时,领导者会通过快照(snapshot)来同步它的状态。
Greenplum
Greenplum数据库是一个基于PostgreSQL开发的开源分布式MPP(Massively Parallel Processing)数据库,支持海量数据的并行处理、分析和挖掘。Greenplum数据库采用主备模式来实现数据的冗余备份,每个Segment有一个主副本和一个备副本,不能动态调整副本数量和位置。Greenplum数据库采用PostgreSQL作为存储引擎,PostgreSQL是一个关系型数据库管理系统,支持行存储和列存储。
spark
Spark可以将Hadoop集群中的应用在内存中的运行速度提升100倍,甚至能够将应用在磁盘上的运行速度提升10倍。除了Map和Reduce操作之外,Spark还支持SQL查询,流数据,机器学习和图表数据处理。开发者可以在一个数据管道用例中单独使用某一能力或者将这些能力结合在一起使用。
spark架构图

- 我们使用spark-submit提交一个Spark作业之后,这个作业就会启动一个对应的Driver进程。根据你使用的部署模式(deploy-mode)不同,Driver进程可能在本地启动,也可能在集群中某个工作节点上启动。Driver进程本身会根据我们设置的参数,占有一定数量的内存和CPUcore。而Driver进程要做的第一件事情,就是向集群管理器(可以是Spark Standalone集群,也可以是其他的资源管理集群,美团•大众点评使用的是YARN作为资源管理集群)申请运行Spark作业需要使用的资源,这里的资源指的就是Executor进程。YARN集群管理器会根据我们为Spark作业设置的资源参数,在各个工作节点上,启动一定数量的Executor进程,每个Executor进程都占有一定数量的内存和CPU core。
- 在申请到了作业执行所需的资源之后,Driver进程就会开始调度和执行我们编写的作业代码了。Driver进程会将我们编写的Spark作业代码分拆为多个stage,每个stage执行一部分代码片段,并为每个stage创建一批task,然后将这些task分配到各个Executor进程中执行。task是最小的计算单元,负责执行一模一样的计算逻辑(也就是我们自己编写的某个代码片段),只是每个task处理的数据不同而已。一个stage的所有task都执行完毕之后,会在各个节点本地的磁盘文件中写入计算中间结果,然后Driver就会调度运行下一个stage。下一个stage的task的输入数据就是上一个stage输出的中间结果。如此循环往复,直到将我们自己编写的代码逻辑全部执行完,并且计算完所有的数据,得到我们想要的结果为止。
- Spark是根据shuffle类算子来进行stage的划分。如果我们的代码中执行了某个shuffle类算子(比如reduceByKey、join等),那么就会在该算子处,划分出一个stage界限来。可以大致理解为,shuffle算子执行之前的代码会被划分为一个stage,shuffle算子执行以及之后的代码会被划分为下一个stage。因此一个stage刚开始执行的时候,它的每个task可能都会从上一个stage的task所在的节点,去通过网络传输拉取需要自己处理的所有key,然后对拉取到的所有相同的key使用我们自己编写的算子函数执行聚合操作(比如reduceByKey()算子接收的函数)。这个过程就是shuffle。
- 当我们在代码中执行了cache/persist等持久化操作时,根据我们选择的持久化级别的不同,每个task计算出来的数据也会保存到Executor进程的内存或者所在节点的磁盘文件中。
- 因此Executor的内存主要分为三块:第一块是让task执行我们自己编写的代码时使用,默认是占Executor总内存的20%;第二块是让task通过shuffle过程拉取了上一个stage的task的输出后,进行聚合等操作时使用,默认也是占Executor总内存的20%;第三块是让RDD持久化时使用,默认占Executor总内存的60%。
- task的执行速度是跟每个Executor进程的CPU core数量有直接关系的。一个CPU core同一时间只能执行一个线程。而每个Executor进程上分配到的多个task,都是以每个task一条线程的方式,多线程并发运行的。如果CPU core数量比较充足,而且分配到的task数量比较合理,那么通常来说,可以比较快速和高效地执行完这些task线程。
如何使用Spark实现TopN的获取
聊一聊Spark实现TopN的几种方式 - 知乎 (zhihu.com)
(1)自定义分区器,按照key进行分区,使不同的key进到不同的分区
(2)对每个分区运用spark的排序算子进行排序
reduceBykey vs groupByKey
-
reduceByKey 在 shuffle 之前会对分区内相同 key 的数据进行预聚合,减少落盘的数据量,提高性能。groupByKey 直接进行 shuffle,没有预聚合的优化,可能会产生大量的中间数据,影响性能。
-
// 最终结果 ("a", 3), ("b", 7), ("c", 5) -
reduceByKey 返回的结果是 RDD [k,v],即每个 key 对应一个 value。groupByKey 返回的结果是 RDD [k, Iterable[v]],即每个 key 对应一个可迭代的 value 集合。
-
// 最终结果 ("a", Iterable(1,2)), ("b", Iterable(3,4)), ("c", Iterable(5))
SparkSQL中left outer join操作,left semi join操作
- left outer join会返回右表中与左表匹配的记录或用NULL填充,而left semi join不会返回右表中的任何列,left inner join会返回右表中与左表匹配的记录。
spark参数以及参数调优
Spark是一个分布式计算框架,它有很多参数可以用来调优性能和资源利用。根据不同的场景和需求,可以选择合适的参数来优化Spark任务的执行效率。一般来说,Spark的参数可以分为以下几类:
- 资源参数:这类参数用来控制Spark任务分配和使用的资源,包括CPU核数、内存大小、磁盘空间等。例如,
spark.executor.cores用来设置每个Executor的核数,spark.executor.memory用来设置每个Executor的内存大小,spark.default.parallelism用来设置默认的并行度等。 - Shuffle参数:这类参数用来控制Spark任务在进行Shuffle操作时的行为,包括Shuffle文件的缓存、压缩、分区等。例如,
spark.shuffle.file.buffer用来设置Shuffle文件写入磁盘时的缓冲区大小,spark.shuffle.compress用来设置是否对Shuffle文件进行压缩,spark.sql.shuffle.partitions用来设置Shuffle操作产生的分区数等。 - 数据倾斜参数:这类参数用来解决Spark任务在进行Join或GroupBy等操作时出现的数据倾斜问题,即某些分区中的数据量过大或过小,导致计算不均衡。例如,
spark.sql.adaptive.enabled用来开启自适应查询执行(AQE),它可以根据运行时的统计信息动态调整Shuffle分区数和Join策略等,spark.sql.broadcastTimeout用来设置广播Join的超时时间,spark.sql.autoBroadcastJoinThreshold用来设置广播Join的阈值等。 - 代码参数:这类参数用来优化Spark任务的代码逻辑,包括使用高效的算子、数据结构、序列化方式等。例如,使用mapPartitions代替map,使用reduceByKey代替groupByKey,使用Kryo代替Java序列化等。
spark数据倾斜
数据倾斜的原理很简单:在进行shuffle的时候,必须将各个节点上相同的key拉取到某个节点上的一个task来进行处理,比如按照key进行聚合或join等操作。此时如果某个key对应的数据量特别大的话,就会发生数据倾斜。此时第一个task的运行时间可能是另外两个task的7倍,而整个stage的运行速度也由运行最慢的那个task所决定。
可能会触发shuffle操作的算子:distinct、groupByKey、reduceByKey、aggregateByKey、join、cogroup、repartition等。出现数据倾斜时,可能就是你的代码中使用了这些算子中的某一个所导致的。
Spark Web UI上深入看一下当前这个stage各个task分配的数据量,从而进一步确定是不是task分配的数据不均匀导致了数据倾斜。
- 使用Hive ETL预处理数据 :
- 过滤少数导致倾斜的key :如果我们判断那少数几个数据量特别多的key,对作业的执行和计算结果不是特别重要的话,那么干脆就直接过滤掉那少数几个key。比如,在Spark SQL中可以使用where子句过滤掉这些key或者在Spark Core中对RDD执行filter算子过滤掉这些key。
- 提高shuffle操作的并行度 :在对RDD执行shuffle算子时,给shuffle算子传入一个参数,比如reduceByKey(1000),该参数就设置了这个shuffle算子执行时shuffle read task的数量。对于Spark SQL中的shuffle类语句,比如group by、join等,需要设置一个参数,即spark.sql.shuffle.partitions,该参数代表了shuffle read task的并行度,该值默认是200,对于很多场景来说都有点过小。
- 两阶段聚合(局部聚合+全局聚合):方案实现原理:将原本相同的key通过附加随机前缀的方式,变成多个不同的key,就可以让原本被一个task处理的数据分散到多个task上去做局部聚合,进而解决单个task处理数据量过多的问题。接着去除掉随机前缀,再次进行全局聚合,就可以得到最终的结果。仅仅适用于聚合类的shuffle操作,适用范围相对较窄。如果是join类的shuffle操作,还得用其他的解决方案。
- 将reduce join转为map join:不使用join算子进行连接操作,而使用Broadcast变量与map类算子实现join操作,进而完全规避掉shuffle类的操作,彻底避免数据倾斜的发生和出现。将较小RDD中的数据直接通过collect算子拉取到Driver端的内存中来,然后对其创建一个Broadcast变量;接着对另外一个RDD执行map类算子,在算子函数内,从Broadcast变量中获取较小RDD的全量数据,与当前RDD的每一条数据按照连接key进行比对,如果连接key相同的话,那么就将两个RDD的数据用你需要的方式连接起来。
- 采样倾斜key并分拆join操作:方案实现原理:对于join导致的数据倾斜,如果只是某几个key导致了倾斜,可以将少数几个key分拆成独立RDD,并附加随机前缀打散成n份去进行join,此时这几个key对应的数据就不会集中在少数几个task上,而是分散到多个task进行join了。
- 使用随机前缀和扩容RDD进行join:将原先一样的key通过附加随机前缀变成不一样的key,然后就可以将这些处理后的“不同key”分散到多个task中去处理,而不是让一个task处理大量的相同key。该方案与“解决方案六”的不同之处就在于,上一种方案是尽量只对少数倾斜key对应的数据进行特殊处理,由于处理过程需要扩容RDD,因此上一种方案扩容RDD后对内存的占用并不大;而这一种方案是针对有大量倾斜key的情况,没法将部分key拆分出来进行单独处理,因此只能对整个RDD进行数据扩容,对内存资源要求很高。
Spark开发调优
-
避免创建重复的RDD:之前对于某一份数据已经创建过一个RDD了,从而导致对于同一份数据,创建了多个RDD,进而增加了作业的性能开销。
-
尽可能复用同一个RDD:两个RDD的value数据是完全一样的,那么此时我们可以只使用key-value类型的那个RDD。
-
**对多次使用的RDD进行持久化:**persist(StorageLevel.MEMORY_AND_DISK_SER)
-
**避免使用shuffle类算子:**shuffle过程中,各个节点上的相同key都会先写入本地磁盘文件中,然后其他节点需要通过网络传输拉取各个节点上的磁盘文件中的相同key。而且相同key都拉取到同一个节点进行聚合操作时,还有可能会因为一个节点上处理的key过多,导致内存不够存放,进而溢写到磁盘文件中。因此在shuffle过程中,可能会发生大量的磁盘文件读写的IO操作,以及数据的网络传输操作。磁盘IO和网络数据传输也是shuffle性能较差的主要原因。
因此可以使用Broadcast与map进行join:
-
**使用map-side预聚合的shuffle操作:**ap-side预聚合之后,每个节点本地就只会有一条相同的key,因为多条相同的key都被聚合起来了。其他节点在拉取所有节点上的相同key时,就会大大减少需要拉取的数据数量,从而也就减少了磁盘IO以及网络传输开销。通常来说,在可能的情况下,建议使用reduceByKey或者aggregateByKey算子来替代掉groupByKey算子。
-
使用高性能的算子:
- 使用mapPartitions替代普通map:
- 使用foreachPartitions替代foreach:
- 使用filter之后进行coalesce操作:因为filter之后,RDD的每个partition中都会有很多数据被过滤掉,此时如果照常进行后续的计算,其实每个task处理的partition中的数据量并不是很多,有一点资源浪费,因此用coalesce减少partition数量,将RDD中的数据压缩到更少的partition之后,只要使用更少的task即可处理完所有的partition
-
**广播大变量:**在算子函数中,使用广播变量时,首先会判断当前task所在Executor内存中,是否有变量副本。 如果有则直接使用;如果没有则从Driver或者其他Executor节点上远程拉取一份放到本地Executor内存中。每个Executor内存中,就只会驻留一份广播变量副本。
-
**使用Kryo优化序列化性能:**1、在算子函数中使用到外部变量时,该变量会被序列化后进行网络传输(见“原则七:广播大变量”中的讲解)。2、将自定义的类型作为RDD的泛型类型时(比如JavaRDD,Student是自定义类型),所有自定义类型对象,都会进行序列化。因此这种情况下,也要求自定义的类必须实现Serializable接口。3、使用可序列化的持久化策略时(比如MEMORY_ONLY_SER),Spark会将RDD中的每个partition都序列化成一个大的字节数组。
Spark资源调优
- num-executors:该参数用于设置Spark作业总共要用多少个Executor进程来执行。Driver在向YARN集群管理器申请资源时,YARN集群管理器会尽可能按照你的设置来在集群的各个工作节点上,启动相应数量的Executor进程。这个参数非常之重要,如果不设置的话,默认只会给你启动少量的Executor进程,此时你的Spark作业的运行速度是非常慢的。
- executor-memory:该参数用于设置每个Executor进程的内存。Executor内存的大小,很多时候直接决定了Spark作业的性能,而且跟常见的JVM OOM异常,也有直接的关联。
- executor-cores:该参数用于设置每个Executor进程的CPU core数量。这个参数决定了每个Executor进程并行执行task线程的能力。因为每个CPU core同一时间只能执行一个task线程,因此每个Executor进程的CPU core数量越多,越能够快速地执行完分配给自己的所有task线程。
- driver-memory:该参数用于设置Driver进程的内存。
- spark.default.parallelism:该参数用于设置每个stage的默认task数量。这个参数极为重要,如果不设置可能会直接影响你的Spark作业性能。
- spark.storage.memoryFraction:该参数用于设置RDD持久化数据在Executor内存中能占的比例,默认是0.6
- spark.shuffle.memoryFraction:参数说明:该参数用于设置shuffle过程中一个task拉取到上个stage的task的输出后,进行聚合操作时能够使用的Executor内存的比例,默认是0.2。也就是说,Executor默认只有20%的内存用来进行该操作。shuffle操作在进行聚合时,如果发现使用的内存超出了这个20%的限制,那么多余的数据就会溢写到磁盘文件中去,此时就会极大地降低性能。
spark shuffle
-
未经优化的HashShuffleManager:shuffle write阶段,主要就是在一个stage结束计算之后,为了下一个stage可以执行shuffle类的算子(比如reduceByKey),而将每个task处理的数据按key进行“分类”。所谓“分类”,就是对相同的key执行hash算法,从而将相同key都写入同一个磁盘文件中,而每一个磁盘文件都只属于下游stage的一个task。在将数据写入磁盘之前,会先将数据写入内存缓冲中,当内存缓冲填满之后,才会溢写到磁盘文件中去。下一个stage的task有多少个,当前stage的每个task就要创建多少份磁盘文件。shuffle write的过程中,task给下游stage的每个task都创建了一个磁盘文件,因此shuffle read的过程中,每个task只要从上游stage的所有task所在节点上,拉取属于自己的那一个磁盘文件即可。

-
优化后的HashShuffleManager:开启consolidate机制之后,在shuffle write过程中,task就不是为下游stage的每个task创建一个磁盘文件了。此时会出现shuffleFileGroup的概念,每个shuffleFileGroup会对应一批磁盘文件,磁盘文件的数量与下游stage的task数量是相同的。一个Executor上有多少个CPU core,就可以并行执行多少个task。而第一批并行执行的每个task都会创建一个shuffleFileGroup,并将数据写入对应的磁盘文件内。**当Executor的CPU core执行完一批task,接着执行下一批task时,下一批task就会复用之前已有的shuffleFileGroup,包括其中的磁盘文件。**也就是说,此时task会将数据写入已有的磁盘文件中,而不会写入新的磁盘文件中。因此,consolidate机制允许不同的task复用同一批磁盘文件,这样就可以有效将多个task的磁盘文件进行一定程度上的合并,从而大幅度减少磁盘文件的数量,进而提升shuffle write的性能。
-
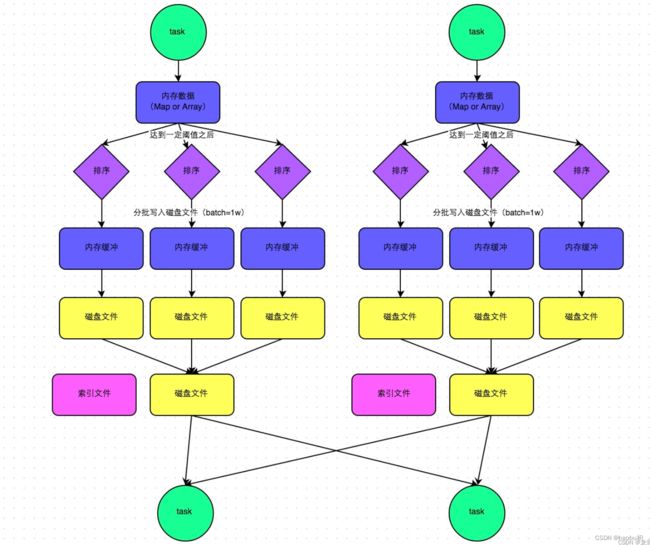
SortShuffleManager的普通运行机制:在该模式下,数据会先写入一个内存数据结构中,此时根据不同的shuffle算子,可能选用不同的数据结构。在溢写到磁盘文件之前,会先根据key对内存数据结构中已有的数据进行排序。排序过后,会分批将数据写入磁盘文件。一个task将所有数据写入内存数据结构的过程中,会发生多次磁盘溢写操作,也就会产生多个临时文件。最后会将之前所有的临时磁盘文件都进行合并,这就是merge过程,此时会将之前所有临时磁盘文件中的数据读取出来,然后依次写入最终的磁盘文件之中。此外,由于一个task就只对应一个磁盘文件,也就意味着该task为下游stage的task准备的数据都在这一个文件中,因此还会单独写一份索引文件,其中标识了下游各个task的数据在文件中的start offset与end offset。
-
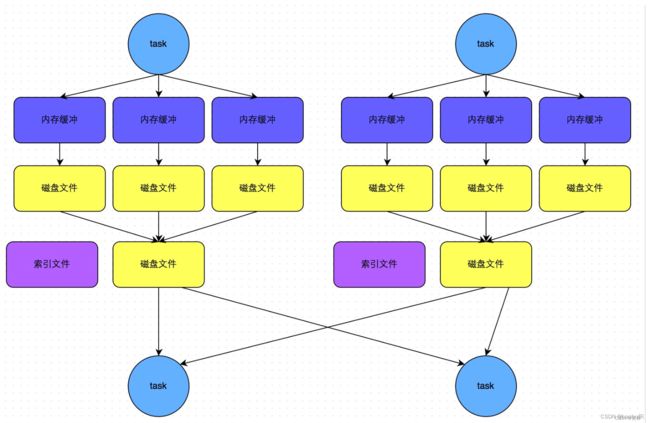
SortShuffleManager的bypass运行机制:此时task会为每个下游task都创建一个临时磁盘文件,并将数据按key进行hash然后根据key的hash值,将key写入对应的磁盘文件之中。当然,写入磁盘文件时也是先写入内存缓冲,缓冲写满之后再溢写到磁盘文件的。最后,同样会将所有临时磁盘文件都合并成一个磁盘文件,并创建一个单独的索引文件。该机制与普通SortShuffleManager运行机制的不同在于:第一,磁盘写机制不同;第二,不会进行 排序。也就是说,启用该机制的最大好处在于,shuffle write过程中,不需要进行数据的排序操作,也 就节省掉了这部分的性能开销。
spark vs mapreduce
spark 与 hadoop 最大的区别在于迭代式计算模型。基于 mapreduce 框架的 Hadoop 主要分为 map 和 reduce 两个阶段,两个阶段完了就结束了,所以在一个 job 里面能做的处理很有限;spark 计算模型是基于内存的迭代式计算模型,可以分为 n 个阶段,根据用户编写的 RDD 算子和程序,在处理完一个阶段后可以继续往下处理很多个阶段,而不只是两个阶段。所以 spark 相较于 mapreduce,计算模型更加灵活,可以提供更强大的功能。
但是 spark 也有劣势,由于 spark 基于内存进行计算,虽然开发容易,但是真正面对大数据的时候,在没有进行调优的情况下,可能会出现各种各样的问题,比如 OOM 内存溢出等情况,导致 spark 程序可能无法运行起来,而 mapreduce 虽然运行缓慢,但是至少可以慢慢运行完。
Spark 与 MapReduce 的 Shuffle 的区别
-
MapReduce的Shuffle过程
- MapReduce的Shuffle过程可以分为Map端和Reduce端两个部分。
- Map端的Shuffle过程主要包括以下几个步骤:
- Map任务对输入数据进行处理,生成键值对(key-value)作为中间结果,并将其写入环形内存缓冲区。
- 当缓冲区达到一定阈值时,启动溢写线程,将缓冲区中的数据按照key进行分区(partition)和排序(sort),并写入磁盘的临时文件(spill file)。
- 在写入磁盘前,可以选择性地进行合并(combine)操作,对相同key的数据进行局部聚合,减少数据量。
- 当所有Map任务完成后,会对磁盘中的所有临时文件进行归并(merge)操作,生成最终的输出文件。在归并过程中,会将相同分区的数据合并到一起,并对每个分区中的数据再进行一次排序(sort),生成key和对应的value-list。
- Reduce端的Shuffle过程主要包括以下几个步骤:
- Reduce任务通过RPC从JobTracker获取Map任务是否完成的信息,如果获知某个Map任务完成,就开始从其所在节点拉取对应分区的数据。
- Reduce任务将拉取到的数据保存在内存缓冲区中,当缓冲区达到一定阈值时,会将数据溢写到磁盘,并进行排序(sort)和合并(combine)操作。
- 当所有Map任务的数据都拉取完毕后,Reduce任务会对磁盘中的所有临时文件进行归并(merge)操作,生成最终的输入文件。在归并过程中,会按照key进行排序(sort),并调用用户自定义的reduce函数对每个key对应的value-list进行聚合处理。
- Reduce任务将聚合后的结果写入HDFS上。
-
spark的shuffle过程
- 在DAG阶段以shuffle为界,划分stage,上游stage做map task,每个map task将计算结果数据分成多份,每一份对应到下游stage的每个partition中,并将其临时写到磁盘,该过程叫做shuffle write;下游stage做reduce task,每个reduce task通过网络拉取上游stage中所有map task的指定分区结果数据,该过程叫做shuffle read,最后完成reduce的业务逻辑。
-
基于Sort的Shuffle在Map端输出数据时,会对每个分区中的数据进行排序(sort),并生成一个索引文件(index file),记录每个分区在输出文件中的起始位置和长度。基于Hash的Shuffle在Map端输出数据时,不会进行排序(sort),也不会生成索引文件(index file)。
-
基于Sort的Shuffle在Reduce端拉取数据时,可以根据索引文件直接定位到自己需要处理的部分数据,而不用拉取整个输出文件。基于Hash的Shuffle在Reduce端拉取数据时,需要拉取整个输出文件,并遍历其中的所有数据。
-
基于Sort的Shuffle可以减少网络传输的数据量,因为只需要拉取自己需要处理的部分数据,而不用拉取整个输出文件。基于Hash的Shuffle会增加网络传输的数据量,因为需要拉取整个输出文件。
spark 容错机制
- 调度层容错:Spark使用DAGScheduler和TaskScheduler两个调度器来管理任务的执行。当一个Stage或者一个Task失败时,调度器会尝试重新提交和执行它们,直到达到最大重试次数或者任务成功为止。
- RDD Lineage容错:Spark的RDD是基于Lineage(血统)的不可变数据结构,它记录了RDD之间的依赖关系和转换操作。当一个RDD的部分分区丢失或损坏时,Spark可以根据Lineage重新计算和恢复这些分区。根据依赖关系的不同,RDD分为窄依赖和宽依赖。窄依赖表示子RDD的每个分区最多依赖于父RDD的一个分区,这样的依赖可以在本地节点上完成计算,容错开销较低。宽依赖表示子RDD的每个分区可能依赖于父RDD的多个或全部分区,这样的依赖需要跨节点进行数据传输和计算,容错开销较高。
- Checkpoint容错:Checkpoint是一种通过将RDD的数据保存到外部存储系统(如HDFS)来断开Lineage链的方法,从而减少容错时的重算开销。Checkpoint一般适用于以下两种情况:一是当Lineage过长时,如果重算,开销太大,如PageRank等迭代算法;二是当存在宽依赖时,如果重算,会产生冗余计算,如groupByKey等聚合算法。Checkpoint需要手动调用RDD的checkpoint()方法来触发,并且需要在SparkContext中设置checkpoint目录。
spark sql过程
Spark SQL是Spark系统的核心组件,它可以将用户编写的SQL语句或者DataFrame/Dataset API转换成Spark Core的RDD操作,从而实现对结构化或者半结构化数据的高效处理。Spark SQL的执行流程主要包括以下几个步骤:
- 解析:Spark SQL使用一个叫做Catalyst的查询编译器,它可以将SQL语句或者DataFrame/Dataset API解析成一棵逻辑算子树(Logical Plan),表示用户的查询意图。
- 分析:Catalyst会对逻辑算子树进行分析,解析其中的表名、列名、数据类型等信息,生成一棵解析后的逻辑算子树(Analyzed Logical Plan)。
- 优化:Catalyst会对解析后的逻辑算子树进行优化,应用各种优化规则,如常量折叠、谓词下推、列裁剪等,生成一棵优化后的逻辑算子树(Optimized Logical Plan)。
- 物理计划:Catalyst会根据优化后的逻辑算子树,生成一个或多个物理算子树(Physical Plan),表示不同的执行策略。例如,join操作可以用SortMergeJoin或者BroadcastHashJoin来实现。Catalyst会使用一个成本模型(Cost Model)来选择最优的物理算子树(Spark Plan)。
- 代码生成:Catalyst会将最优的物理算子树转换成可执行的代码,利用Scala语言的quasiquotes功能,生成Java字节码,提高执行效率。
- 执行:Spark SQL会将生成的代码提交给Spark Core执行引擎,利用RDD的操作和调度机制,完成分布式计算。
spark vs zookeeper
- Spark可以利用Zookeeper实现高可用性。在Spark中,如果Master节点出现故障,那么整个集群就无法正常工作了。为了解决这个问题,Spark可以借助Zookeeper来实现Master节点的故障转移。具体来说,就是在集群中启动多个Master节点,并将它们注册到Zookeeper上。Zookeeper会选举出一个Leader Master,并将其地址通知给所有的Worker节点。当Leader Master出现故障时,Zookeeper会重新选举出一个新的Leader Master,并通知给所有的Worker节点。这样就可以保证集群在Master节点故障时仍然可以继续工作。
- Spark可以利用Zookeeper实现分布式协调服务。在Spark中,有些场景需要对分布式系统进行协调和同步,比如共享变量、广播变量、累加器等。为了实现这些功能,Spark可以借助Zookeeper来提供一致性和原子性的保证。具体来说,就是将这些需要协调的数据存储在Zookeeper上,并通过Zookeeper提供的API来进行读写操作。这样就可以保证数据在分布式环境中的一致性和可靠性。
3 spark中的task,stage,job之间的关系
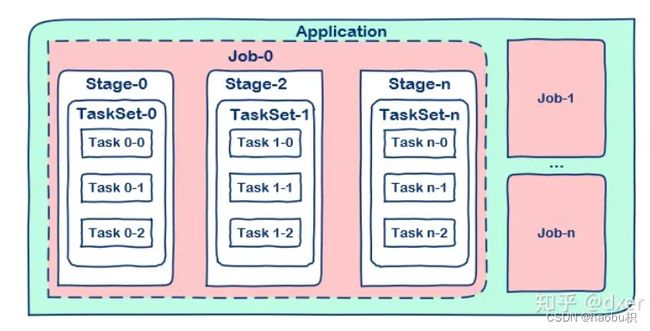
- Application:用户编写的Spark应用程序,由一个或多个Job组成。提交到Spark之后,Spark会为Application分配资源,将程序进行转换并执行。
- Job(作业):由Action算子触发生成的由一个或多个Stage组成的计算作业。
- Stage(调度阶段):每个Job会根据RDD的宽依赖被切分为多个Stage,每个Stage都包含一个TaskSet。
- TaskSet(任务集):一组关联的,但相互之间没有shuffle依赖关系的Task集合。一个TaskSet对应的调度阶段。
- Task(任务):RDD中的一个分区对应一个Task,Task是单个分区上最小的处理流程单元。
RDD
RDD 是 Spark 提供的最重要的抽象概念,它是一种有容错机制的特殊数据集合,可以分布在集群的结点上,以函数式操作集合的方式进行各种并行操作。可以将 RDD 理解为一个分布式对象集合,本质上是一个只读的分区记录集合。每个 RDD 可以分成多个分区,每个分区就是一个数据集片段。一个 RDD 的不同分区可以保存到集群中的不同结点上,从而可以在集群中的不同结点上进行并行计算。
- 即如果某个结点上的 RDD partition 因为节点故障,导致数据丢失,那么 RDD 可以通过自己的数据来源重新计算该 partition。这一切对使用者都是透明的。
- RDD 的弹性体现在于 RDD 上自动进行内存和磁盘之间权衡和切换的机制。
RDD vs Dataframe
-
RDD 是 Spark 的基础数据抽象,它可以处理各种类型的数据,包括结构化、半结构化和非结构化数据。DataFrame 是 Spark SQL 模块提供的一种高层数据抽象,它只针对结构化或半结构化数据,需要指定数据的 schema(结构信息)。
-
RDD 是分布式的 Java 对象的集合,每个对象可以是任意类型,Spark 不关心对象的内部结构。DataFrame 是分布式的 Row 对象的集合,每个 Row 对象包含多个列,每列有名称和类型,Spark 可以根据 schema 优化数据的存储和计算。
-
RDD 提供了 low-level 的转换和行动操作,可以用函数式编程的风格来操作数据,但是不支持 SQL 语言和 DSL(特定领域语言)。DataFrame 提供了 high-level 的转换和行动操作,可以用 SQL 语言和 DSL 来操作数据,比如 select, groupby 等。
-
RDD 的优点是编译时类型安全,可以在编译时发现错误,而且具有面向对象编程的风格。DataFrame 的优点是利用 schema 信息来提升执行效率、减少数据读取以及执行计划的优化,比如 filter 下推、裁剪等。
-
RDD 的缺点是构建大量的 Java 对象占用了大量的堆内存空间,导致频繁的垃圾回收(GC),影响程序执行效率。而且数据的序列化和反序列化性能开销很大。DataFrame 的缺点是编译时类型不安全,只能在运行时发现错误,而且不具有面向对象编程的风格。
RDD创建方法
-
使用程序中的集合创建RDD
如果要通过并行化集合来创建RDD,需要针对程序中的集合,调用**SparkContext的paralleize()**方法。Spark会将集合中的数据拷贝到集群上去,形成一个分布式的数据集合,也就是一个RDD。
//案例:1到10累加求和(scala) val arr = Array(1,2,3,4,5,6,7,8,9,10) val rdd = sc.parallelize(arr) val sum = rdd.reduce(_+_) -
使用本地的文件创建RDD
-
使用HDFS来创建RDD
通过调用SparkContext的textFile()方法,可以针对本地文件或HDFS文件创建RDD。
//案例:文件字数统计 val rdd = sc.textFile("data.txt") val wordcount = rdd.map(line => line.length).reduce(_+_)
Spark的RDD操作
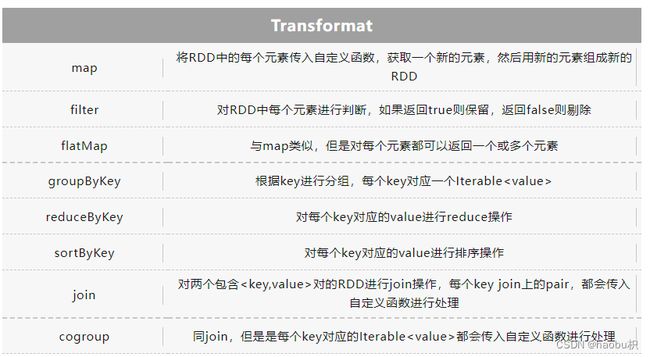
- transformat操作会针对已有的RDD创建一个新的RDD
- action则主要是对RDD进行最后的操作

RDD宽窄依赖
- 窄依赖:父 RDD 的一个分区只会被子 RDD 的一个分区依赖;
- 宽依赖:父 RDD 的一个分区会被子 RDD 的多个分区依赖(涉及到 shuffle),对于宽依赖,必须等到上一阶段计算完成才能计算下一阶段。
DAG和DAG stage
- DAGScheduler主要负责分析用户提交的应用,并根据计算任务的依赖关系建立DAG,然后将DAG划分为不同的Stage,其中每个Stage由可以并发执行的一组Task组成,这些Task的执行逻辑完全相同,只是作用于不同的数据。在DAGScheduler将这组Task划分完成之后,会将这组Task(TaskSets)提交到TaskScheduler。
- TaskScheduler负责Task级的调度,将DAGScheduler提交过来的TaskSet按照指定的调度实现,分别对接到不同的资源管理系统。TaskScheduler会将TaskSets封装成TaskSetManager,并加入到调度的队列中,TaskSetManager负责监控管理同一个Stage中的Tasks,TaskScheduler就是以TaskSetManager为单元来调度任务的。TaskScheduler通过Cluster Manager在集群中的某个Worker的Executor上启动任务。
- 宽窄依赖是指RDD之间的依赖关系,宽依赖是父RDD的一个分区会被多个子RDD的分区所依赖,窄依赖是父RDD的一个分区只被一个子RDD的分区所依赖。划分stage的依据就是宽窄依赖,遇到宽依赖就切分stage,因为宽依赖涉及到shuffle操作,需要在不同节点间传输数据,而窄依赖可以在同一个节点内完成转换。划分stage可以优化执行计划,减少数据传输和重算的开销。
RDD持久化
RDD 持久化是 Spark 的一个重要特性,它可以将 RDD 的数据保存在内存或磁盘中,避免重复计算。RDD 持久化的实现主要有以下几个步骤:
- 调用 RDD 的 cache() 或 persist() 方法,将 RDD 标记为需要持久化的状态。这两个方法的区别是 cache() 相当于 persist(StorageLevel.MEMORY_ONLY),而 persist() 可以指定不同的存储级别,如 MEMORY_AND_DISK、DISK_ONLY 等。
- 在第一次对 RDD 执行 action 操作时,触发 RDD 的计算,并将计算结果按照存储级别保存在各个节点的内存或磁盘中。同时,记录 RDD 的依赖关系和分区信息,以便在缓存丢失时重新计算。
- 在后续对 RDD 的操作中,如果发现 RDD 已经被持久化,就直接从内存或磁盘中读取数据,而不需要重新计算。如果缓存的数据丢失或不足,就根据 RDD 的依赖关系和分区信息重新计算缺失的分区。
spark streaming
Spark streaming 是 spark core API 的一种扩展,可以用于进行大规模、高吞吐量、容错的实时数据流的处理。
它支持从多种数据源读取数据,比如 Kafka、Flume、Twitter 和 TCP Socket,并且能够使用算子比如 map、reduce、join 和 window 等来处理数据,处理后的数据可以保存到文件系统、数据库等存储中。
Spark streaming 内部的基本工作原理是:接受实时输入数据流,然后将数据拆分成 batch,比如每收集一秒的数据封装成一个 batch,然后将每个 batch 交给 spark 的计算引擎进行处理,最后会生产处一个结果数据流,其中的数据也是一个一个的 batch 组成的。
Spark Streaming 整合 Kafka 的两种模式
- 基于Receiver的方式:这种方式使用Receiver来获取数据。Receiver是使用Kafka的高层次Consumer API来实现的。Receiver从Kafka中获取的数据都是存储在Spark Executor的内存中的,然后Spark Streaming启动的job会去处理那些数据。这种方式可以通过启用预写日志(Write Ahead Log,WAL)来实现零数据丢失,但是可能会造成数据重复消费的问题。
- 基于Direct的方式:这种方式没有使用Receiver,而是直接从Kafka中读取数据。这种方式使用了Kafka的低层次Consumer API,可以周期性地查询每个topic的每个partition中的最新offset,然后根据设定的每个partition的最大拉取速率(maxRatePerPartition)来处理每个batch。这种方式不需要预写日志,也不会造成数据重复消费的问题,但是需要自己管理offset的记录和更新。
Kafka
Kafka 本质上是一个 MQ(Message Queue),使用消息队列的好处?
-
解耦:允许我们独立的扩展或修改队列两边的处理过程。
-
可恢复性:即使一个处理消息的进程挂掉,加入队列中的消息仍然可以在系统恢复后被处理。
-
缓冲:有助于解决生产消息和消费消息的处理速度不一致的情况。
-
灵活性&峰值处理能力:不会因为突发的超负荷的请求而完全崩溃,消息队列能够使关键组件顶住突发的访问压力。
-
异步通信:消息队列允许用户把消息放入队列但不立即处理它。
kafka工作流程
-
生产者(Producer)向Kafka集群发送消息,消息被封装成一个ProducerRecord对象,该对象包含了要发送的主题(Topic)、分区(Partition)、键(Key)、值(Value)等信息。
-
Kafka集群根据ProducerRecord对象的信息,将消息存储到相应的主题和分区中。主题是逻辑上的消息分类单位,分区是物理上的消息存储单位,每个分区对应一个日志文件(Log),日志文件中的消息都有一个唯一的偏移量(Offset)。
-
消费者(Consumer)从Kafka集群订阅主题,并从指定的分区中拉取消息。消费者属于某个消费者组(Consumer Group),同一个消费者组内的消费者可以消费同一个主题的不同分区,同一个分区只能被同一个消费者组内的某个消费者消费,以避免重复消费。消费者会记录自己消费到了哪个分区的哪个偏移量,以便出错恢复时继续消费。
-
Kafka集群依赖于Zookeeper来保存和管理集群元数据,例如主题、分区、副本、偏移量等信息。Kafka集群中的每个节点都是一个Broker,每个Broker可以容纳多个主题和分区。每个分区都有多个副本,其中一个为主副本(Leader),负责处理读写请求,其余为从副本(Follower),负责同步主副本的数据。当主副本发生故障时,会从从副本中选举出一个新的主副本。
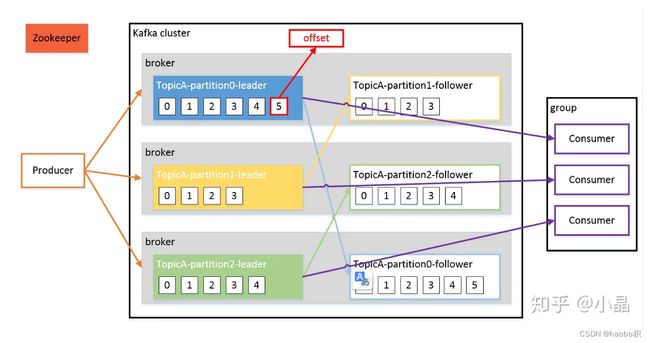
topic 是逻辑上的概念,而 partition 是物理上的概念,每个 partition 对应于一个 log 文件,该 log 文件中存储的就是 Producer 生产的数据。Producer 生产的数据会不断追加到该 log 文件末端,且每条数据都有自己的 offset。消费者组中的每个消费者,都会实时记录自己消费到了哪个 offset,以便出错恢复时,从上次的位置继续消费。