Map集合详解:HashMap、LinkedHashMap
1、HashMap
1.1 底层原理:
HashMap有几种常见构造方法:
//构造一个空的 HashMap ,默认初始容量(16)和默认负载系数(0.75)。
HashMap<Object, Object> hashMap = new HashMap<>();
//构造一个空的 HashMap具有指定的初始容量和默认负载因子(0.75)。
HashMap<Object, Object> hashMap1 = new HashMap<>(8);
//构造一个空的 HashMap具有指定的初始容量和负载因子。
HashMap<Object, Object> hashMap2 = new HashMap<>(8, 0.8f);
创建HashMap对象时 容量参数 和 负载系数的作用需要了解HashMap的底层数据结构及原理。
HashMap的底层数据结构为数组+链表,
插入数据时,会根据插入的key,计算其hash值,根据hash值映射到不同的数组索引,具体的映射为:
- 计算key的hash值,将该值进行无符号右移16位之后与右移前的hash值再进行异或,(主要是减少hash冲突的概率)
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
- 将处理后的hash值与数组的(长度-1)进行逻辑与操作,计算出key的索引范围在数组的下标范围之中。
- 将key对应的值插入在数组下标处,如果该处没有值,就直接插入,如果有值,判断该处的key的hash值是否和要插入的key的hash值相等,如果相等,视为同一个key,将直接覆盖旧key的值,如果不相等,再根据链表的规则在该处key的后面插入当前的key
1.2 示例:
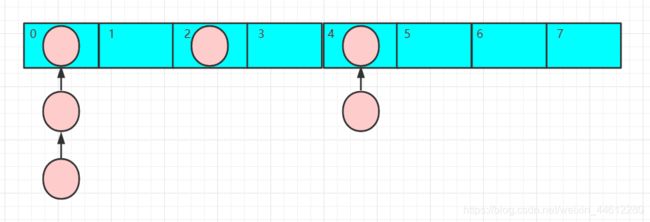
比如我创建一个容量为4的HashMap,插入的key为k1,k2,k3。对应的value值为v1,v2,v3:
- 插入k1=v1键值对:计算key的hash,并进行索引到相应数组下标:假设k1处理后的hash值234324523,将其与数组(长度-1)=3 进行逻辑与,得到的index肯定在0-3范围之内,假设为0,则将k1对的值v1放在如图所在位置

- 插入k2=v2键值对:同1,假设索引的位置为2.即

- *插入k3=v3键值对:计算key的hash,并进行索引到相应数组下标:假设k3处理后的hash值444444,将其与数组(长度-1)=3 进行逻辑与,得到的index肯定在0-3范围之内,假设也为0,插入时发现该位置已经存在v1了,不能直接插入,判断该位置的k1的hash=234324523和需要插入的k3的hash=444444进行比较,发现不相等,所以是两个不同的key,不能覆盖v1的值,往v1的后面添加,即
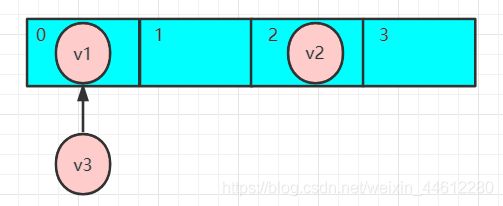
- 假如现有又有一个k4,它索引的下标也正好在0,那么怎么插入呢,同理,和上面一样,先判断它的hash是否和k1的相等,相等则覆盖,不相等,往v1后面追加,但此处v1后面已经存在v3了,其实插入时会先判断v1的后面是不是已经有连接的值,如果有,找到其连接的值v3,判断v3的k3的hash是否和插入的k4相等,相等则覆盖,不等,在往v3的后面添加,如此往复。
1.3 负载系数
负载系数其实和容量有关系,假设容量为4,系数为0.75,则到数组的下标位置有 4*0.75=3 个区域填满则开始扩容,扩容时,容量变为先前的2倍,即8。这里的容量4不是指存储的元素为4个,而是数组的长度为4,扩容是也不是指存储的元素到达3个即开始扩容,而是数组的下标位置存储的元素为3个才开始扩容。假如上图在索引0的位置一直连接了10几个元素,但数组只有索引0和2的位置存在元素,没有达到3个,所以也不会扩容。在扩容时,会进行hash的重写散列,所以HashMap的容量一般都为2的次方。负载系数一般默认的0.75,这样会保证空间的利用率和效率平衡的最大化。假如系数过大,则当数组快满时才会扩容,会导致,一个数组下标下面可能会链接了多个元素,效率较低,但空间利用率较高,如果系数过小,这数组的容量还有很多时,就开始扩容,空间会浪费,但效率较高,因为元素直接存在数组下标处。所以一般负载系数默认即可。
1.4 容量选取
容量为什么需要为2的次方,因为有很多:
- (大大降低重新索引)HashMap的数组长度一定保持2的次幂,比如16的二进制表示为 10000,那么length-1就是15,二进制为01111,同理扩容后的数组长度为32,二进制表示为100000,length-1为31,二进制表示为011111。我们也能看到这样会保证低位全为1,而扩容后只有一位差异,也就是多出了最左位的1,这样在通过 h&(length-1)的时候,只要hash对应的最左边的那一个差异位为0,就能保证得到的新的数组索引和老数组索引一致(大大减少了之前已经散列良好的老数组的数据位置重新调换),
- (使数组存储数据更加均匀)数组长度保持2的次幂,length-1的低位都为1,会使得获得的数组索引index更加均匀
- (减少hash冲突)高位是不会对结果产生影响的(hash函数采用各种位运算可能也是为了使得低位更加散列),我们只关注低位bit,如果低位全部为1,那么对于hash低位部分来说,任何一位的变化都会对结果产生影响,也就是说,要得到index=15这个存储位置,hash的低位只有这一种组合。这也是数组长度设计为必须为2的次幂的原因。
- (使所有下标都能索引到)如果不是2的次幂,也就是低位不是全为1此时,要使得index=15,hash的低位部分不再具有唯一性了,哈希冲突的几率会变的更大,同时,index对应的这个bit位无论如何不会等于1了,而对应的那些数组位置也就被白白浪费了。
2、LinkedHashMap
LinkedHashMap是继承于HashMap的,底层数据结构为数组+链表,但是与HashMap不同的是LinkedHashMap维持了一个双向链表,将里面的元素通过双向链表链接起来以实现有序。构造方法与HashMap相比,多了一个
LinkedHashMap<Object, Object> linkedHashMap4 = new LinkedHashMap<>(8,0.8f,true);
其true代表的使用插入顺序,false代表的是访问顺序。
具体插入顺序和访问顺序有什么区别,我们先看看HashMap的元素遍历过程,再来看看LinkedHashMap两种排序方式
2.1.HashMap的访问顺序:

插入的键值对的顺序为 v1 - v2 - v3 - v4 - v5 - v6,遍历访问元素时,按照上图所述的方式进行遍历,从数组索引0开始遍历,假如下标处有多个元素组成一个链表就继续遍历链表上的元素,索引0上遍历完成之后,开始遍历索引1,…一直到最后一个索引遍历完成。因此上图遍历HashMap的顺序为 v1-v3-v6-v4-v2-v5。
2.2 LinkedHashMap的排序
LinkedHashMap中的每个键值对都是一个双向链表节点.在LinkedHashMap里面每个键值对比HashMap里面都多了两个属性before和after,用来链接前一个元素和后一个元素。LinkedHashMap里面还有一个head和tail属性,表示双向链表的头节点和尾节点。
LinkedHashMap里面大部分的方法都是HashMap中的方法,HashMap中预留了方法给其子类进行重写,如在put方法中,LinkedHashMap使用的还是HashMap的put方法,只是HashMap中put方法调用了newNode方法,而LinkedHashMap重写了其newNode方法,在方法中调用LinkNodeLast方法通过双向链表将元素关联起来。


假如插入的键值对的顺序为 v1 - v2 - v3 - v4 - v5 - v6,则头节点为v1,尾节点为v6,头节点的after链接到v2,v2的before链接到v1,以此类推,
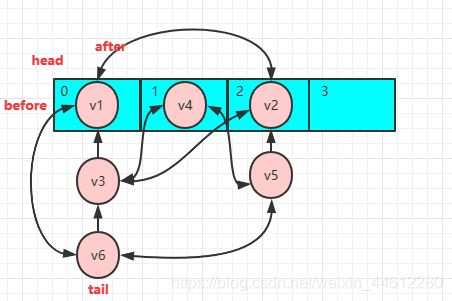
所有linkedhashmap的插入顺序就是v1 - v2 - v3 - v4 - v5 - v6,遍历时也是以此来循环的,而如果使用的是访问顺序,那么每次通过get,put等方法对元素进行操作的都会对元素之间的双向链表进行更改,如插入时的顺序是v1 - v2 - v3 - v4 - v5 - v6,而我又调用了一次get的获取了下V3的值,那么v3将跑到链表的尾部,再次访问时的顺序就变成了v1 - v2 - v4 - v5 - v6- v3,所以访问顺序是根据你对linkedHashMap的操作而时刻变化的,插入顺序不会变的,你插入是什么顺序,遍历是就是什么顺序。LinkedHashMap的访问顺序可以用来做LRU缓存,可以删掉最久一次没有使用的元素,即头元素。