2021秋招面试整理
以下为2021秋招,Java后端面试的文档记录。
图片是用自带的画图工具,可以点击放大可以看清晰。
因为在忙毕业论文,10月底才开始准备秋招。由于在杭州某大厂暑期实习体验感实在不好,又想留在上海拿户口,就发生了菜鸟拒大厂的事。(因为自己真的很菜,属于玩里挤时间学一丢丢的那种,所以当时感觉可能这是唯一的大厂机会了)
惊喜的是,没想到10月底才开始的菜鸟,后面拿了6个offer!
而且其中的5个都比暑期转正的那个开的高。(一个末流211本,末流985硕的垫底小透明的offer)
这里想说一下,朋友们,拒绝焦虑拒绝焦虑啊!!!最近几年,每每看到一堆人发文搞紧张气氛都暴躁啊,如果说是5、6月劝人早做准备的,OK,我觉得没问题。但是时间都已经在10月了,你说别找了,找不到了,现在竞争太大了!真想一巴掌糊上去。你找到工作了,你就去旅游,或者去入职,好好干活。你还没找到的,就赶紧刷题准备。为什么要写一堆帖子制造焦虑,找工作最好的时间是提前一个月,如果错过了,那就是现在!
人生处处都是路,选一条路走下去,就是我们要做的!那些自己焦虑还想让别人都焦虑的人,趁早毁灭吧!
1. 线程
现在感觉要去理解,才能游刃有余的面对面试官的问题。
第一,线程是什么?(弄清楚线程的定义,线程是什么?这里常会遇到的问题就是进程、线程、协程区别)
第二,他有什么作用?(什么情况下用线程?用了线程会导致怎样的好处或者坏处?可不可以不用?)
第三,线程的生命周期。(生命周期就是从创建到销毁中间完整的可能会经历到的过程。线程的生命周期包括,创建、就绪、运行、阻塞、死亡。生命周期中的每一个状态都要理解,比如如何创建,是什么时候创建,创建的线程类型。如何才能导致产生每一个状态,状态如何更新,发生什么会导致阻塞态,就绪可以转回创建态么,怎么使得运行中的线程超时死亡。)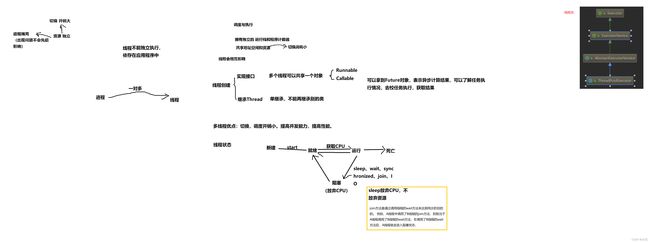
线程的内存
在秋招的时候,线程的内存也被广泛问道。因为当时时间紧,我没有系统的学一遍OS,所以内存这一块总是不太理解。到现在也不太理解。但是毫无疑问,内存的存取分配这一块是个面试的重点,时间允许的话还是要好好看看理解一下。
下图中有,JVM中的线程内存和OS中的线程内存映射关系。
内存这一块涉及到一个关键词,volatile,他是一个保护线程安全的关键词。这是一个很重要的关键词,需要对内存模型理解后,才能明白这个关键词的作用。
现在感觉内存这一块的学习路线,应该是先把操作系统中的存储相关知识学会,明白主存、内存、RAM、ROM,OS中线程的运行等。
JAVA基础
java基础当时看的一本教程,名字忘掉了,面试官当时给推荐了一本书JAVA编程思想(Thinking in java,宝典级java教材)。秋招结束了,这本书才到,还没看。不过一直相信黑皮书,经典中的经典。(这里说一下,对大部头黑皮书为什么这么认可!之前看过一本C语言的黑皮书[Brian W.Kernighan C程序设计语言],语言简单易懂,不仅很细致的解释了怎么做,还会用很容易听懂的话解释为什么这么做。超级薄的一本书,比我看两三本大部头的C语言书看完,理解的,学习到的多太多了,在学C语言的小伙伴快去看!)
这一部分问的比较多的,接口、继承、哈希、ArrayList、Set、哈希表,Vector,StringBuilder,StringBuffer等,java中包含的数据结构基本上都会问,数据结构是重中之重,数据结构的扩容、线程安全、不同版本的区别。还有反射、装箱拆箱等。
多看书吧,内容太多了,下图是我当时不太熟悉的知识点整理的图。
Hashmap
100%问的东西,整理的东西都在下图了,点击看吧。
摩根Morgan面试时准备的资料,都是一些对于自己不太熟悉的内容,摩根的全英文面,一轮电话面,半小时,7-8个问题,问题比较基础,全英的。二轮是,疫情线上了,一下午,三场全英的。先写两道算法,一道简单一道难。第一场就是讨论算法题,第二场问项目,技术,第三场hr,主要是一些遇到困难怎么处理的。
why morgan stanley need these tech?
make financial transactions more precise and efficiency.
i prefer to trading system. Because the trading system is related to finance that i have always wanted to know. And I think I can learn about different industries here.
Memory leak
Out of memory means that the program does not have enough memory space for its use when applying for memory, and out of memory occurs; For example, if you apply for an integer, but save it with a long to save the number, that is, memory overflow.
Memory leak refers to that the program cannot release the applied memory space after applying for memory. The harm of a memory leak can be ignored, but the consequences of memory leak accumulation are very serious. No matter how much memory is, it will be occupied sooner or later.
Memory leak will eventually lead to out of memory!
min heap && max heap
Index
Index is like a catalog of dictionary. Users can query words more fast by catalog. In database,index is spacial files that contains reference pointers to all data in database. Usually, index is implemented by B+ tree. B+ tree is an improved version of B tree. It puts all data on leaf nodes and add sequential pointers .
Because of the sequential pointers, querying by range becomes more easily. It just needs to query first data and last data,then traverse between them.
Since non-leaf nodes just contain keywords in B+ tree. So once IO operation can load more keywords into memory. This can reduce IO operation times.
Mysql B+树的优点:非叶子节点仅存关键字,非叶子节点间有双向链表,每一个page有前一页的编号和后一页的编号。page中存储的记录之间用单链表串联,因为page会一次性读入内存,同一个page中按顺序查找。(B+树的根节点页常驻内存)
(1)Mysql常用InnoDB引擎。页是固定的,如果不存储数据,只存储键值,相应的树的阶数(每个节点的子节点树)会更大,树就会更矮胖。这样查找数据时,磁盘IO次数就会减少。每一次IO,从磁盘中读取16K的块,InnoDB引擎为页面编码留有32位,所以InnoDB上限是64TB(2^30 × 16KB)。若一页均是非叶子节点,key为64位整数,8个字节,一页可以装1000可key,1000个key意味着B+树有1000个分叉。
(2)因为B+索引数据均存在叶子结点,且数据时有序的。所以范围查询、前缀匹配模糊查询(可以转换为范围查询)、排序(叶子结点天然排序好的)和分页。B树数据时分散在各个节点的,故不容易。
缺点:在mysql 分页中,通常会写limite 1000,10,从offset=1000的位置取10条,此时需要把前1000个数据都遍历一遍才能知道。这种情况下吧offset=1000修改为min_id,改为where id>min_id
为什么建议自增主键?
为了避免页面分割的问题。由于B+树中是有序的,如果新加入的值需要在一个已经满的page中的话,就需要新建page,把插入数据之后的数据拷贝到新page中,并且要调整page前后的双向链表的指针,这会影响插入速度。如果是顺序插入,只需要把最后一个page指向新的page即可。对于硬删除操作,会引起页面合并问题。
在mysql中非主键索引记录的不是数据的指针,而是主键的值,在查找时,需要先查找到非主键索引的B+树上定位主键,再用主键去索引的b+树找到最终记录。由于非主键索引,一个主键可能对应多个数据记录,故非主键索引的结构和主键索引的结构不一样。
MyISAM?
MyISAM中B+树索引中的叶子结点并不存储数据,存储文件地址。
聚集索引和非聚集索引?
以主键作为B+树索引的键值构建的B+树索引,称之为聚集索引。
以主键之外的列值构建索引称为非聚集索引。非聚集的叶子结点存储列对应的主键,通过主键再找,称为回表。
应用层、FTP、SMTP、http、DNS
传输层、
网络层、IP、ICMP(ping)、OSPF(全局泛洪)
数据链路层、ARP地址解析协议 ip—>mac
物理层
TCP的可靠连接:连接三次握手、四次挥手;报文校验、ACK应答、超时重传、失序数据重传、丢弃重复数据、流量控制和拥塞控制。
TCP和UDP区别:
1,面向连接
2,顺序,TCP超时重传保证可靠
3,TCP占资源多
4,TCP有流量和拥塞控制
5,TCP面向字节流,UDP面向报文
6,TCP是一对一的,UDP支持一对一,一对多,多对多
滑动窗口:接收段使用的窗口大小,用来告知发送端 接收端的缓存大小,以此控制发送端发送数据的大小,从而流量控制。滑动窗口的值越大,说明网络的吞吐量越高。
**滑动窗口控制流量的基本原理:**假设当前窗口m,x个发送已确认的数据,共发送n个数据,则发送端还可以发送y=m-(n-x)。当接收方陆续确认后,滑动窗口就向右移动。当接收端确认数据并释放TCP的接收缓存时,窗口右边向右移动。
接收缓存满了,则发送端接收到接收端的窗口大小为0,则停止发数据。这时,发送端超时重传,发送窗口探测包,仅包含一个字节获取窗口大小。
流量控制:端对端通信时,控制发送端的发送速率,以便接收端来得及接收。
拥塞控制(拥塞窗口):防止过多的数据注入网络,使得网络中的路由器或链路不能过载。一个RTT内可以最多发送的数据包数。
慢开始 发送窗口1->指数增长,增长到门限,用拥塞避免,
网络延时时门限减半开始慢算法;或者快恢复(收到三个重复的确认,门限减半开始拥塞避免,窗口线性增大)
收到3个重复确认:ACK表示期望接收到的下一个字节的序号n,如果接收方收到n,回复n+1,如果接收方下一个收到n+2,则不会回复n+2,而是继续回复n+1,故n+1如果一直没有收到,ack就会一直发送n+1的ack。
快重传(尽快发送未收到的报文段确认)、快恢复
三次握手
|----------------SYN=1,seq=j--------------------->| 一种典型的DDOS攻击:
|<-----ACK=1,SYN=1,ack= j+1,seq= m-------| Server发送SYN_ACK后,
|-------------ACK=1,ack = m+1----------------->| 收到ACK前,称为半连接状态。SYN攻击就是Client 在短时间伪造大量不存在IP,并向Server端发送 SYN包,服务器向伪造的IP回复确认包,等等确认。由于是伪造的,不存在ip,故服务器需要不断重发知道超时,伪造的SYN包长时间占用未连接队列,导致正常的SYN请求因为队列满了被抛弃,引起网络堵塞或者瘫痪。
当server上有大量半连接状态且源IP地址是随机的,可以判定遭到攻击。
为什么不是2次握手?
防止已失效的连接请求突然传到B。A第一个连接没有丢失,又传到了B,这是一个早已失效的报文段,但是B收到会误以为A又发出连接请求,于是发出确认报文段。如果不采用3次握手的话,B确认了,就建立了新连接,一直等待A发送,浪费资源。
为什么不是4次握手?
因为服务端收到建立连接请求后,把ACK和SYN一起发送给客户端了,第二次握手既是发起握手也是响应握手。而在关闭的时候,服务端收到FIN包后,仅仅表示客户端不再发送数据了,还可以接收数据。那么服务端可以选择关闭或者继续发送数据,再发送FIN包给客户端确认关闭。因此,在断开连接时,ACK和FIN包分别发送。
4次挥手最后等待2MSL?
1,为了保证最后一个ACK报文段可以达到B。最后的ACK报文段丢失的话,B会超时重传FIN报文段,A就可以在2MSL内收到这重传的ACK+FIN报文段,A再重传一次。
2,防止已失效的报文段重新出现。A发送ACK报文段后,经过2MSL,可以使本连接持续的时间内所产生的的报文段都从网络中消失。
关闭时CLOSE_WAIT和TIME_WAIT区别?
- CLOSE_WAIT 是被动关闭形成的;当对方发送 FIN 报文过来时,回应 ACK 之后进入 CLOSE_WAIT 状态。随后检查是否存在未传输数据,如果没有则发起第三次挥手,发送 FIN 报文给对方,进入 LAST_ACK 状态并等待对方 ACK 报文到来
- TIME_WAIT 是主动关闭连接方式形成的;处于 FIN_WAIT_2 状态时,收到对方 FIN 报文后进入 TIME_WAIT 状态;之后再等待两个 MSL(Maximum Segment Lifetime: 报文最大生存时间)
适用场景
UDP(用户数据包协议):多播的信息, 传输信息简短(大的话会在传输过程中分片,影响效率),实时性高于完整和安全(流媒体)
QQ聊天:登陆采用TCP协议和HTTP协议,你和好友之间发送消息,主要采用UDP协议,内网传文件采用了P2P技术。
1.登陆过程,客户端client 采用TCP协议向服务器server发送信息,HTTP协议下载信息。登陆之后,会有一个TCP连接来保持在线状态。
2.和好友发消息,客户端client采用UDP协议,但是需要通过服务器转发。腾讯为了确保传输消息的可靠,采用上层协议来保证可靠传输。如果消息发送失败,客户端会提示消息发送失败,并可重新发送。
3.如果是在内网里面的两个客户端传文件,QQ采用的是P2P技术,不需要服务器中转。
粘包和拆包:
程序需要发送的数据大小和TCP报文段能发送的最大报文长度是不一样的。大于最大报文长度了,需要拆分成多个TCP报文段,称为拆包,小于则会合并,粘包。
在IP协议层、链路层、物理层都存在粘包,拆包现象。
解决方法:数据尾部增加特殊字符分割 2,数据固定大小 3,数据分为两部分:头部和内容,头部固定大小,声明内容体大小。
一次http请求,经历几个步骤?
1)解析域名 -> 2)发起 TCP 三次握手,建立连接 -> 3)基于 TCP 发起 HTTP 请求 -> 4)服务器响应 HTTP 请求,并返回数据 -> 5)客户端解析返回数据
http响应码
- 200:表示成功正常请求
- 302
- 206
- 400:语义有误,一般是请求格式不对
- 401:需求用户验证权限,一般是证书 token 没通过认证
- 403:拒绝提供服务
- 404:资源不存在
- 500:服务器错误
- 503:服务器临时维护,过载;可恢复
session 和 cookie 有什么区别,都是会话状态跟踪技术
- 1)存储位置不同,cookie 是保存在客户端的数据(可以通过max_age,大于0,则保存硬盘,等于0,则关闭会话就消失);session 的数据存放在服务器上。都是由服务器生成的。
- 2)存储容量不同,单个 cookie 保存的数据小,一个站点最多保存 20 个 Cookie;对于 session 来说并没有上限
- 3)存储方式不同,cookie 中只能保管 ASCII 字符串;session 中能够存储任何类型的数据
- 4)隐私策略不同,cookie 对客户端是可见的;session 存储在服务器上,对客户端是透明的
- 5)有效期上不同,cookie 可以长期有效存在;session 依赖于名为 JSESSIONID 的 cookie,过期时间默认为 - 1,只需关闭窗口该 session 就会失效
- 6)跨域支持上不同,cookie 支持跨域名访问;session 不支持跨域名访问
域属性范围:保证功能的情况下,优先使用小范围的。不仅节省内存,而且保证数据安全。
ServletContext 应用范围,跨会话
HTTPSession 会话范围,跨请求 request.getSession(true),写用true(无则建) 获取false的话,session.setAttribute()
HTTPServletRequest 请求范围,跨Servlet共享数据,多个同一次请求中的Servlet。request.setAttribute()
Session原理:
1,服务器中的Session以Map存储,key为32位长度的随机串,value为Session对象的引用。
当用户第一次请求提交时,生成JSessionID,Session引用,作为mapEntry,加入到map中。
2,把JSessionID包装为cookie返回给客户端,cookie存在浏览器缓存,在下一次请求时候,请求头会携带该cookie。
根据cookie中的JSessionID查找对应的Session引用。
3,由于cookie是会话结束时消失,所以Session也是会话结束时失效。
HTTPS 和 HTTP 的区别
- 1)http 协议的连接是无状态的,明文传输
- 2)HTTPS 则是由 SSL/TLS(TLS是SSL的升级版,现在在1.2版本)+HTTP 协议构建的有加密传输、身份认证的网络协议
HTTPs
客户端 服务端
HTTP HTTP
SSL加密 SSL解密
TCP/IP---------------->TCP/IP
SSL握手的过程中还是明文,握手后才是安全的?SSL握手的重点在于怎么在不安全的网络中安全的进行密钥交换?
在握手过程中,采用非对称加密(RSA)。握手后,采用对称加密(对称加密,效率高)
SSL握手:
客户端----------------SSL协议版本号(TLS1.2)+ 随机数1 + 客户端支持的加密算法---------------->服务端
客户端<--------------------------------------------数字证书+随机数2-----------------------------------------------服务端(确认加密方法)
客户端(确认数字证书有效,取出公钥)-----------数字证书中的公钥加密随机数3---------------------->服务端(私钥获取随机数)
客户端<---------------约定的加密方法将随机数123生成对话密钥用于整个对话加密------------------->服务端
客户端和服务端都拥有3个随机数,网络中仅传输随机数1、2,和加密后的随机数3
DH算法(密钥交换)
AES
它首先会通过安全层进行 ca 证书认证,正确获取服务端的公钥。接着客户端会通过公钥和服务端确认一种加密算法,后面的数据则可以使用该加密算法对数据进行加密。
http中,怎么判断请求体中的数据读取完成?(请求头的每行结尾都是有\r\n的)
- http分块(先看transfer-encoding)
- 请求头中有content-length
HTTP分块(http响应头中transfer-encoding中值为chunk):
当发送的数据量很大的时候,分块编码。
7\r\n
chenjie\r\n
2\r\n 向下一行读2个字符
is\r\n
0\r\n 读到0表示响应体结束了
Hash index
This method is to have hash code of keywords as index. It is applied for accuracy query. It’s index file store index column and pointers to data. The key of this method is to find a hash function that can minimize hash collisions.
- why morgen
Ebay面试
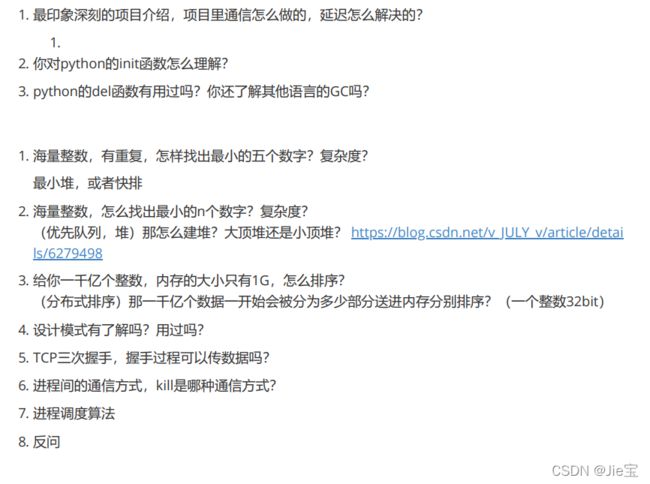
线程连着面三轮,第一轮是个老头,问一些简单的算法,和技术问题,聊的很开心,像是师生在交流。第二轮应该是个主管吧,先让写智力题,5分钟左右做出来了,没怎么问技术好像,问的一些无关紧要的,家乡是哪里的这种问题。这场面试体验不太好,面试官一直在忙自己手头上的事,感觉有点敷衍不尊重人,第三轮的hr面,小姐姐很温柔,当时手上有大厂的offer,因为准备拒了,就没说,但是感觉可能说了会让自己有竞争力一点。