HDFS高级--数据存储与管理
文章目录
-
-
- 1 HDFS数据存储与数据管理
-
- 1.1 HDFS REST HTTP API
-
- 1.1.1 WebHDFS
- 1.1.2 关于RESTful
-
- 1.1.2.1 REST
- 1.1.2.2 RESTFul API
- 1.1.3 HDFS HTTP RESTFUL API
- 1.1.4 文件系统URL和HTTP URL
- 1.1.5 webHDFS创建文件
- 1.1.6 webHDFS写入数据
- 1.2 HttpFS
-
- 1.2.1 配置Hadoop-HttpFS
- 1.2.2 WebHDFS和HttpFS之间区别
- 2 Hadoop常用文件存储格式
-
- 2.1 行式存储、列式存储
- 2.2 Hadoop的文件类型
-
- 2.2.1 Text File
- 2.2.2 Sequence File
- 2.2.3 Avro File
- 2.2.4 RCFile
- 2.2.5 ORC File
- 2.2.6 Parquet File
- 2.2.7 Apache Arrow
- 3 Hadoop文件压缩
-
- 3.1 hadoop支持的文件压缩对比
- 4 HDFS异构存储和存储策略
-
- 4.1 HDFS异构存储类型
- 4.2 块存储类型选择策略
- 4.3 HDFS内存存储策略支持
-
1 HDFS数据存储与数据管理
1.1 HDFS REST HTTP API
我们之前所学习的HDFS shell客户端和Java客户端,都客户端上安装了HDFS客户端。之前我们在windows上也配置了HDFS的windows版本客户端,否则,我们将无法操作HDFS。而且,客户端的版本如果不匹配,有可能会导致无法操作。接下来,我们将学习几种基于HTTP协议的客户端,HTTP是跨平台的,它不要求客户端上必须安装Hadoop,就可以直接操作HDFS。
1.1.1 WebHDFS
概述:WebHDFS其实是HDFS提供的HTTP RESTFul API接口,并且它是独立于Hadoop的版本的,它支持HDFS的完整FileSystem / FileContext接口。它可以让客户端发送http请求的方式来操作HDFS,而无需安装Hadoop。
在我们经常使用的HDFS Web UI,它就是基于webhdfs来操作HDFS的。
1.1.2 关于RESTful
1.1.2.1 REST
- REST(表现层状态转换,英语:Representational State Transfer)是Roy Thomas Fielding博士于2000年在博士论文中提出来的一种万维网软件架构风格,目的是便于不同软件/程序在网络(例如互联网)中互相传递信息。
- REST是基于超文本传输协议(HTTP)之上而确定的一组约束和属性,是一种设计提供万维网络服务的软件构建风格。符合或兼容于这种架构风格(简称为 REST 或 RESTful)的网络服务,允许客户端发出以统一资源标识符访问和操作网络资源的请求,而与预先定义好的无状态操作集一致化。
- 因此REST提供了在互联网络的计算系统之间,彼此资源可交互使用的协作性质(interoperability)。相对于其它种类的网络服务,例如SOAP服务,则是以本身所定义的操作集,来访问网络上的资源。
- 目前在三种主流的Web服务实现方案中,因为REST模式与复杂的SOAP和XML-RPC相比更加简洁,越来越多的Web服务开始采用REST风格设计和实现。例如,Amazon.com提供接近REST风格的Web服务运行图书查询;雅虎提供的Web服务也是REST风格的。
- 需要注意的是,REST是设计风格而不是标准。REST通常基于HTTP、URI、XML以及HTML这些现有的广泛流行的协议和标准。
- 资源是由URI来指定。
- 对资源的操作包括获取、创建、修改和删除,这些操作正好对应HTTP协议提供的GET、POST、PUT和DELETE方法。
- 通过操作资源的表现形式来操作资源。
- 资源的表现形式则是XML或者HTML,取决于读者是机器还是人、是消费Web服务的客户软件还是Web浏览器。当然也可以是任何其他的格式,例如JSON。
1.1.2.2 RESTFul API
概述:符合REST设计风格的Web API称为RESTful API。它从以下三个方面资源进行定义:
- 直观简短的资源地址:URI,比如:
http://example.com/resources - 传输的资源:Web服务接受与返回的互联网媒体类型,比如:JSON,XML,YAML等
- 对资源的操作:Web服务在该资源上所支持的一系列请求方法(比如:POST,GET,PUT或DELETE)。
| 资源 | GET | PUT | POST | DELETE |
|---|---|---|---|---|
一组资源的URI,比如 https://example.com/resources |
列出URI,以及该资源组中每个资源的详细信息。 | 使用给定的一组资源替换当前整组资源。 | 在本组资源中创建/追加一个新的资源。该操作往往返回新资源的URL。 | 删除整组资源。 |
单个资源的URI,比如https://example.com/resources/142 |
获取指定的资源的详细信息,格式可以自选一个合适的网络媒体类型(比如:XML、JSON等) | 替换/创建指定的资源。并将其追加到相应的资源组中。 | 把指定的资源当做一个资源组,并在其下创建/追加一个新的元素,使其隶属于当前资源。 | 删除指定的元素。 |
- PUT和DELETE方法是幂等方法
- GET方法是安全方法(不会对服务器端有修改,因此当然也是幂等的)
PUT请求类型和POST请求类型的区别:
- PUT和POST均可用于创建或者更新某个资源(例如:添加一个用户、添加一个文件),用哪种请求方式取决我们自己。
- 我们主要使用是否需要有幂等性来判断到底用PUT、还是POST。PUT是幂等的,也就是将一个对象进行两次PUT操作,是不会起作用的。而如果使用POST,会同时收到两个请求。
1.1.3 HDFS HTTP RESTFUL API
HDFS HTTP RESTFUL API它支持以下操作:
HTTP GET:
- OPEN (等同于FileSystem.open)
- GETFILESTATUS (等同于FileSystem.getFileStatus)
- LISTSTATUS (等同于FileSystem.listStatus)
- LISTSTATUS_BATCH (等同于FileSystem.listStatusIterator)
- GETCONTENTSUMMARY (等同于FileSystem.getContentSummary)
- GETQUOTAUSAGE (等同于FileSystem.getQuotaUsage)
- GETFILECHECKSUM (等同于FileSystem.getFileChecksum)
- GETHOMEDIRECTORY (等同于FileSystem.getHomeDirectory)
- GETDELEGATIONTOKEN (等同于FileSystem.getDelegationToken)
- GETTRASHROOT (等同于FileSystem.getTrashRoot)
- GETXATTRS (等同于FileSystem.getXAttr)
- GETXATTRS (等同于FileSystem.getXAttrs)
- GETXATTRS (等同于FileSystem.getXAttrs)
- LISTXATTRS (等同于FileSystem.listXAttrs)
- CHECKACCESS (等同于FileSystem.access)
- GETALLSTORAGEPOLICY (等同于FileSystem.getAllStoragePolicies)
- GETSTORAGEPOLICY (等同于FileSystem.getStoragePolicy)
- GETSNAPSHOTDIFF
- GETSNAPSHOTTABLEDIRECTORYLIST
- GETECPOLICY (等同于HDFSErasureCoding.getErasureCodingPolicy)
- GETFILEBLOCKLOCATIONS (等同于FileSystem.getFileBlockLocations)
HTTP PUT:
- CREATE (等同于FileSystem.create)
- MKDIRS (等同于FileSystem.mkdirs)
- CREATESYMLINK (等同于FileContext.createSymlink)
- RENAME (等同于FileSystem.rename)
- SETREPLICATION (等同于FileSystem.setReplication)
- SETOWNER (等同于FileSystem.setOwner)
- SETPERMISSION (等同于FileSystem.setPermission)
- SETTIMES (等同于FileSystem.setTimes)
- RENEWDELEGATIONTOKEN (等同于DelegationTokenAuthenticator.renewDelegationToken)
- CANCELDELEGATIONTOKEN (等同于DelegationTokenAuthenticator.cancelDelegationToken)
- CREATESNAPSHOT (等同于FileSystem.createSnapshot)
- RENAMESNAPSHOT (等同于FileSystem.renameSnapshot)
- SETXATTR (等同于FileSystem.setXAttr)
- REMOVEXATTR (等同于FileSystem.removeXAttr)
- SETSTORAGEPOLICY (等同于FileSystem.setStoragePolicy)
- ENABLEECPOLICY (等同于HDFSErasureCoding.enablePolicy)
- DISABLEECPOLICY (等同于HDFSErasureCoding.disablePolicy)
- SETECPOLICY (等同于HDFSErasureCoding.setErasureCodingPolicy)
HTTP POST:
- APPEND (等同于FileSystem.append)
- CONCAT (等同于FileSystem.concat)
- TRUNCATE (等同于FileSystem.truncate)
- UNSETSTORAGEPOLICY (等同于FileSystem.unsetStoragePolicy)
- UNSETECPOLICY (等同于HDFSErasureCoding.unsetErasureCodingPolicy)
HTTP DELETE:
- DELETE (等同于FileSystem.delete)
- DELETESNAPSHOT (等同于FileSystem.deleteSnapshot)
1.1.4 文件系统URL和HTTP URL
WebHDFS的文件系统schema是webhdfs://。WebHDFS文件系统URL具有以下格式。
webhdfs://:/
上面的WebHDFS URL对应于下面的HDFS URL。
hdfs://:/
在RESTAPI中,在路径中插入前缀“/webhdfs/v1”,并在末尾追加一个查询。因此,对应的HTTPURL具有以下格式。
http://:/webhdfs/v1/?op=...
请求URL:http://node1.itcast.cn:9870/webhdfs/v1/?op=LISTSTATUS
该操作表示要查看根目录下的所有文件以及目录,相当于 hdfs dfs -ls /
1.1.5 webHDFS创建文件
在/data/hdfs-test目录中创建一个名字为webhdfs_api.txt文件,并写入内容。
创建一个请求,设置请求方式为PUT,请求url为:
http://node1.itcast.cn:9870/webhdfs/v1/data/hdfs-test/webhdfs_api.txt?op=CREATE&overwrite=true&replication=2&noredirect=true
HTTP会响应一个用于上传数据的URL链接。
- 提交HTTP PUT请求,而不会自动跟随重定向,也不会发送文件数据。
- 通常,请求被重定向到要写入文件数据的DataNode。
- 如果不希望自动重定向,则可以设置noredirected标志。
1.1.6 webHDFS写入数据
使用Location标头中的URL提交另一个HTTP PUT请求(如果指定了noredirect,则返回返回的响应),并写入要写入的文件数据。
curl -i -X PUT -T "http://:/webhdfs/v1/?op=CREATE..."
- LOCAL_FILE 为本地文件地址
- PATH为创建文件放回的URL链接
1.2 HttpFS
概述:
- HttpHDFS本质上和WebHDFS是一样的,都是提供HTTP REST API功能,但它们的区别是HttpHDFS是HttpFS,是一个独立于HadoopNameNode的服务,它本身就是Java JettyWeb应用程序。
- 因为是可以独立部署的,所以可以对HttpHDFS设置防火墙,而避免NameNode暴露在墙外,对一些安全性要求比较高的系统,HttpHDFS会更好些。
- HttpFS是一种服务器,它提供REST HTTP网关,支持所有HDFS文件系统操作(读和写)。并且它可以与WebhdfsREST HTTPAPI
- HttpFS可用于在运行不同版本Hadoop(克服RPC版本控制问题)的集群之间传输数据,例如使用HadoopDiscreCP。
- HttpFS可用于在防火墙后面的集群上访问HDFS中的数据(HttpFS服务器充当网关,是允许跨越防火墙进入集群的唯一系统)。
- HttpFS可以使用HTTP实用程序(例如curl和wget)和来自Java以外的其他语言的HTTP库Perl来访问HDFS中的数据。
- 这个Webhdfs客户端文件系统实现可以使用Hadoop文件系统命令访问HttpFS(hdfsdfs)行工具以及使用Hadoop文件系统JavaAPI的Java应用程序。
- HttpFS内置了支持Hadoop伪身份验证和HTTP、SPNEGOKerberos和其他可插拔身份验证机制的安全性。它还提供Hadoop代理用户支持。
操作方式:
- HttpFS是一个独立于HadoopNameNode的服务。
- HttpFS本身就是Java JettyWeb应用程序。
- HttpFS HTTP Web服务API调用是HTTPREST调用,映射到HDFS文件系统操作。例如,使用curl/Unix命令:
$curl ‘http://httpfs-host:14000/webhdfs/v1/user/foo/README.txt?op=OPEN&user.name=foo’
返回HDFS的内容/user/foo/README.txt档案。
$curl ‘http://httpfs-host:14000/webhdfs/v1/user/foo?op=LISTSTATUS&user.name=foo’
返回HDFS的内容/user/foo目录中的JSON格式。
$curl ‘http://httpfs-host:14000/webhdfs/v1/user/foo?op=GETTRASHROOT&user.name=foo’
返回路径/user/foo/.trash,如果/是加密区域,则返回路径。/.Trash/Foo。看见更多细节关于加密区域中的垃圾路径。
$curl -X POST‘http://httpfs-host:14000/webhdfs/v1/user/foo/bar?op=MKDIRS&user.name=foo’
创建HDFS/user/foo/bar目录。
- HttpFS默认端口号为14000
1.2.1 配置Hadoop-HttpFS
1 编辑Hadoop的core-site.xml,并将运行HttpFS服务器的Unix用户定义为proxyuser。例如:
hadoop.proxyuser.#HTTPFSUSER#.hosts
httpfs-host.foo.com
hadoop.proxyuser.#HTTPFSUSER#.groups
*
2 重要:替换#HTTPFSUSER#使用将启动HttpFS服务器的Unix用户。
例如:
hadoop.proxyuser.root.hosts
*
hadoop.proxyuser.root.groups
*
3 重启Hadoop
4 启动HttpFS
hdfs --daemon start httpfs
5 测试HttpFS工作
http://node1.itcast.cn:14000/webhdfs/v1?user.name=root&op=LISTSTATUS
1.2.2 WebHDFS和HttpFS之间区别
webHDFS
- HDFS内置、默认开启
- 基于REST的HDFS API
- 重定向到资源所在的datanode
- 客户端会和nn、dn交互
httpFS
- 独立服务,手动开启
- 基于REST的HDFS API
- 数据先传输到该httpfs server,再由其传输到client
- 客户端不跟hdfs直接交互
2 Hadoop常用文件存储格式
概述:
-
文件格式是定义数据文件系统中存储的一种方式,可以在文件中存储各种数据结构,特别是Row、Map,数组以及字符串,数字等。
-
在Hadoop中,没有默认的文件格式,格式的选择取决于其用途。而选择一种优秀、适合的数据存储格式是非常重要的。
-
后续我们要学习的,使用HDFS的应用程序(例如MapReduce或Spark)性能中的最大问题、瓶颈是在特定位置查找数据的时间和写入到另一个位置的时间,而且管理大量数据的处理和存储也很复杂(例如:数据的格式会不断变化,原来一行有12列,后面要存储20列)。
-
Hadoop文件格式发展了好一段时间,这些文件存储格式可以解决大部分问题。我们在开发大数据中,选择合适的文件格式可能会带来一些明显的好处:
- 可以保证写入的速度
- 可以保证读取的速度
- 文件是可被切分的
- 对压缩支持友好
- 支持schema的更改
-
某些文件格式是为通用设计的(如MapReduce或Spark),而其他文件则是针对更特定的场景,有些在设计时考虑了特定的数据特征。因此,确实有很多选择。
-
每种格式都有优点和缺点,数据处理的不同阶段可以使用不同的格式才会更有效率。通过选择一种格式,最大程度地发挥该存储格式的优势,最小化劣势。
2.1 行式存储、列式存储
行式存储(Row-Based):同一行数据存储在一起。
列式存储(Column-Based):同一列数据存储在一起。
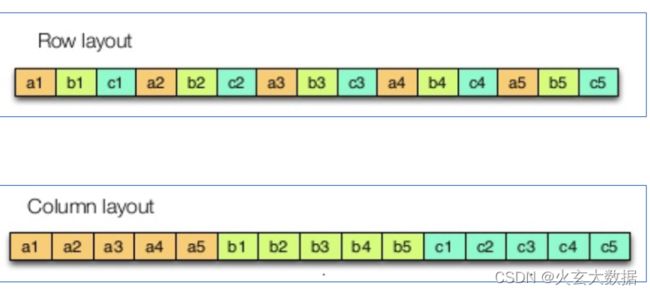
优缺点:
- 行存储的写入是一次性完成,消耗的时间比列存储少,并且能够保证数据的完整性,缺点是数据读取过程中会产生冗余数据,如果只有少量数据,此影响可以忽略;数量大可能会影响到数据的处理效率。行适合插入、不适合查询。
- 列存储在写入效率、保证数据完整性上都不如行存储,它的优势是在读取过程,不会产生冗余数据,这对数据完整性要求不高的大数据处理领域,比如互联网,犹为重要。列适合查询,不适合插入。
2.2 Hadoop的文件类型
2.2.1 Text File
- 文本格式是Hadoop生态系统内部和外部的最常见格式。通常按行存储,以回车换行符区分不同行数据。
- 最大缺点是,它不支持块级别压缩,因此在进行压缩时会带来较高的读取成本。
- 解析开销一般会比二进制格式高,尤其是XML 和JSON,它们的解析开销比Textfile还要大。
- 易读性好。
- 常见类型有:txt、xml、csv、json等
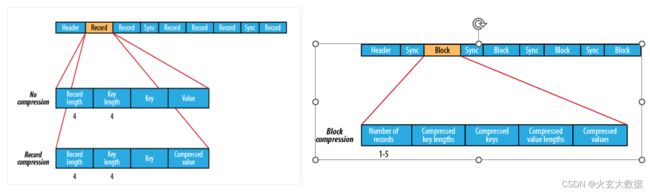
2.2.2 Sequence File
- Sequence File,每条数据记录(record)都是以key、value键值对进行序列化存储(二进制格式)。
- 序列化文件与文本文件相比更紧凑,支持record级、block块级压缩。压缩的同时支持文件切分。
- 通常把Sequence file作为中间数据存储格式。例如:将大量小文件合并放入到一个Sequence File中。
- record就是一个kv键值对。其中数据保存在value中。可以选择是否针对value进行压缩。
- block就是多个record的集合。block级别压缩性能更好。
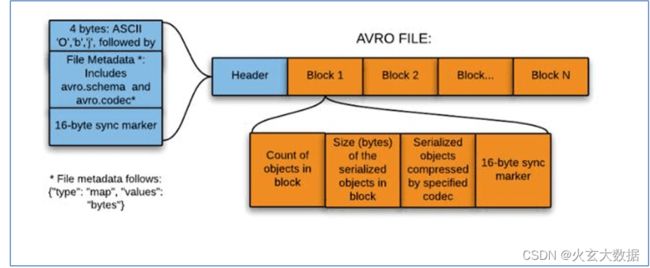
2.2.3 Avro File
- Apache Avro是与语言无关的序列化系统,由Hadoop创始人 Doug Cutting开发
- Avro是基于行的存储格式,它在每个文件中都包含JSON格式的schema定义,从而提高了互操作性并允许schema的变化(删除列、添加列)。除了支持可切分以外,还支持块压缩。
- Avro是一种自描述格式,它将数据的schema直接编码存储在文件中,可以用来存储复杂结构的数据。
- Avro直接将一行数据序列化在一个block中.
- 适合于大量频繁写入宽表数据(字段多列多)的场景,其序列化反序列化很快。
2.2.4 RCFile
- Hive Record Columnar File(记录列文件),这种类型的文件首先将数据按行划分为行组,然后在行组内部将数据存储在列中。很适合在数仓中执行分析。且支持压缩、切分
- 但不支持schema扩展,如果要添加新的列,则必须重写文件,这会降低操作效率。

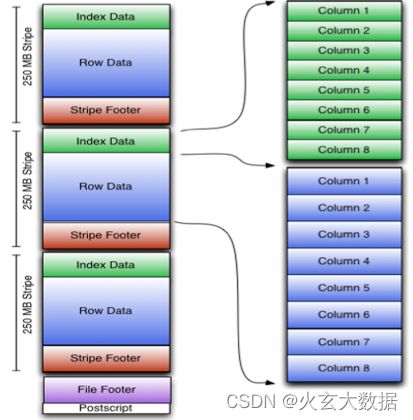
2.2.5 ORC File
- ORC File(Optimized Row Columnar)提供了比RC File更有效的文件格式。它在内部将数据划分为默认大小为250M的Stripe。每个条带均包含索引,数据和页脚。索引存储每列的最大值和最小值以及列中每一行的位置。
- 它并不是一个单纯的列式存储格式,仍然是首先根据Stripe分割整个表,在每一个Stripe内进行按列存储。
- ORC有多种文件压缩方式,并且有着很高的压缩比。文件是可切分(Split)的。
- ORC文件是以二进制方式存储的,所以是不可以直接读取。
2.2.6 Parquet File
- Parquet是面向分析型业务的列式存储格式,由Twitter和Cloudera合作开发,2015年5月从Apache的孵化器里毕业成为Apache顶级项目。
- Parquet文件是以二进制方式存储的,所以是不可以直接读取的,文件中包括该文件的数据和元数据,因此Parquet格式文件是自解析的。
- 支持块压缩。
结构:
- Parquet 的存储模型主要由行组(Row Group)、列块(Column Chuck)、页(Page)组成。
- 在水平方向上将数据划分为行组,默认行组大小与HDFS Block 块大小对齐,Parquet 保证一个行组会被一个 Mapper 处理。行组中每一列保存在一个列块中,一个列块具有相同的数据类型,不同的列块可以使用不同的压缩。Parquet 是页存储方式,每一个列块包含多个页,一个页是最小的编码的单位,同一列块的不同页可以使用不同的编码方式。
- 文件的首位都是该文件的Magic Code,用于校验它是否是一个Parquet文件。

2.2.7 Apache Arrow
概述:
-
Apache Arrow是一个跨语言平台,是一种列式内存数据结构,主要用于构建数据系统。
-
Apache Arrow在2016年2月17日作为顶级Apache项目引入。
-

-
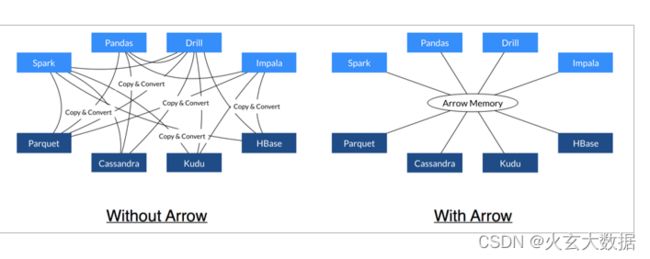
Arrow促进了许多组件之间的通信。
-
极大的缩减了通信时候序列化、反序列化所浪费的时间。
性能提高:
- 利用Arrow作为内存中数据表示的两个过程可以将数据从一种方法“重定向”到另一种方法,而无需序列化或反序列化。例如,Spark可以使用Python进程发送Arrow数据来执行用户定义的函数。
- 无需进行反序列化,可以直接从启用了Arrow的数据存储系统中接收Arrow数据。 例如,Kudu可以将Arrow数据直接发送到Impala进行分析。
- Arrow的设计针对嵌套结构化数据(例如在Impala或Spark Data框架中)的分析性能进行了优化。
3 Hadoop文件压缩
压缩算法优劣指标:
- 压缩比:原先占100份空间的东西经压缩之后变成了占20份空间,那么压缩比就是5,显然压缩比越高越好。
- 压缩/解压缩吞吐量(时间):每秒能压缩或解压缩多少MB的数据。吞吐量也是越高越好。
- 压缩算法实现是否简单、开源
- 是否为无损压缩。恢复效果要好。
- 压缩后的文件是否支持split(切分)
3.1 hadoop支持的文件压缩对比
| 压缩格式 | 工具 | 算法 | 文件扩展名 | 是否可切分 | 对应的编码解码器 |
|---|---|---|---|---|---|
| DEFLATE | 无 | DEFLATE | .deflate | 否 | org.apache.hadoop.io.compress.DefaultCodec |
| Gzip | gzip | gzip | .gz | 否 | org.apache.hadoop.io.compress.GzipCodec |
| bzip2 | bzip2 | bzip2 | .bz2 | 是 | org.apache.hadoop.io.compress.BZip2Codec |
| LZO | lzop | LZO | .lzo | 是(切分点索引) | com.hadoop.compression.lzo.LzopCodec |
| LZ4 | 无 | LZ4 | .lz4 | 否 | org.apache.hadoop.io.compress.Lz4Codec |
| Snappy | 无 | Snappy | .snappy | 否 | org.apache.hadoop.io.compress.SnappyCodec |
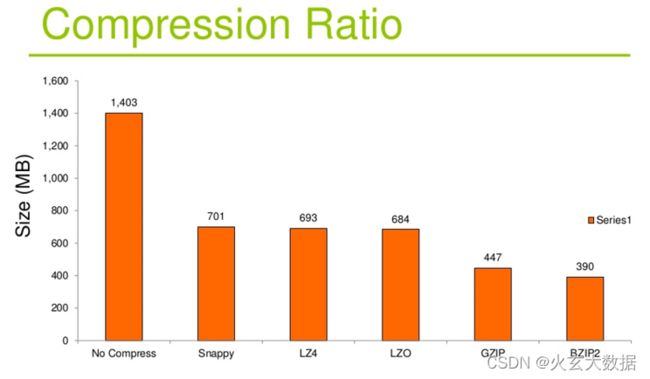
- 压缩比
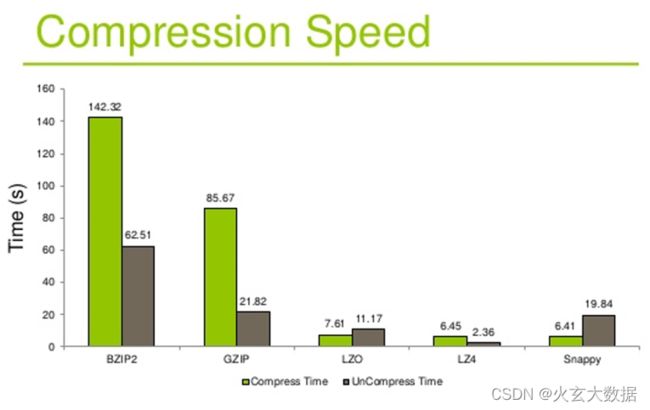
- 压缩、解压缩时间
使用原则:
- 压缩的合理使用可以提高HDFS存储效率
- 压缩解压缩意味着CPU、内存需要参与编码解码
- 选择压缩算法时不能一味追求某一指标极致。综合考虑性价比较高的。
- 文件的压缩解压需要程序或者工具的参与来对数据进行处理。大数据相关处理软件都支持直接设置。
4 HDFS异构存储和存储策略
4.1 HDFS异构存储类型
冷、热、温、冻数据
通常,公司或者组织总是有相当多的历史数据占用昂贵的存储空间。典型的数据使用模式是新传入的数据被应用程序大量使用,从而该数据被标记为"热"数据。随着时间的推移,存储的数据每周被访问几次,而不是一天几次,这时认为其是"暖"数据。在接下来的几周和几个月中,数据使用率下降得更多,成为"冷"数据。如果很少使用数据,例如每年查询一次或两次,这时甚至可以根据其年龄创建第四个数据分类,并将这组很少被查询的旧数据称为"冻结数据"。
Hadoop允许将不是热数据或者活跃数据的数据分配到比较便宜的存储上,用于归档或冷存储。可以设置存储策略,将较旧的数据从昂贵的高性能存储上转移到性价比较低(较便宜)的存储设备上。
Hadoop 2.5及以上版本都支持存储策略,在该策略下,不仅可以在默认的传统磁盘上存储HDFS数据,还可以在SSD(固态硬盘)上存储数据。
异构存储概述:
- 异构存储是Hadoop2.6.0版本出现的新特性,可以根据各个存储介质读写特性不同进行选择。
- 例如冷热数据的存储,对冷数据采取容量大,读写性能不高的存储介质如机械硬盘,对于热数据,可使用SSD硬盘存储。
- 在读写效率上性能差距大。异构特性允许我们对不同文件选择不同的存储介质进行保存,以实现机器性能的最大化。
HDFS中声明定义了4种异构存储类型:
- RAM_DISK(内存)
- SSD(固态硬盘)
- DISK(机械硬盘),默认使用。
- ARCHIVE(高密度存储介质,存储档案历史数据)
问:如何让HDFS知道集群中的数据存储目录是哪种类型存储介质?
答:配置属性时主动声明。HDFS并没有自动检测的能力。
配置参数dfs.datanode.data.dir = [SSD]file:///grid/dn/ssdO
如果目录前没有带上[SSD] [DISK] [ARCHIVE] [RAM_DISK] 这4种类型中的任何一种,则默认是DISK类型 。
4.2 块存储类型选择策略
概述:
- 块存储指的是对HDFS文件的数据块副本储存。
- 对于数据的存储介质,HDFS的BlockStoragePolicySuite类内部定义了6种策略。
- HOT(默认策略):用于存储和计算。流行且仍用于处理的数据将保留在此策略中。所有副本都存储在DISK中。
- COLD:仅适用于计算量有限的存储。不再使用的数据或需要归档的数据从热存储移动到冷存储。所有副本都存储在ARCHIVE中。
- WARM:部分热和部分冷。热时,其某些副本存储在DISK中,其余副本存储在ARCHIVE中。
- ALL_SSD:将所有副本存储在SSD中。
- ONE_SSD:用于将副本之一存储在SSD中。其余副本存储在DISK中。
- LAZY_PERSIST:用于在内存中写入具有单个副本的块。首先将副本写入RAM_DISK,然后将其延迟保存在DISK中。
- 前三种根据冷热数据区分,后三种根据磁盘性质区分。

4.3 块存储类型选择策略–命令
- 列出所有存储策略
hdfs storagepolicies -listPolicies
- 设置存储策略
hdfs storagepolicies -setStoragePolicy -path -policy
- 取消存储策略
hdfs storagepolicies -unsetStoragePolicy -path
在执行unset命令之后,将应用当前目录最近的祖先存储策略,如果没有任何祖先的策略,则将应用默认的存储策略。
- 获取存储策略
hdfs storagepolicies -getStoragePolicy -path
4.3 HDFS内存存储策略支持
LAZY PERSIST介绍:
- HDFS支持把数据写入由DataNode管理的堆外内存;
- DataNode异步地将内存中数据刷新到磁盘,从而减少代价较高的磁盘IO操作,这种写入称为 Lazy Persist写入。
- 该特性从Apache Hadoop 2.6.0开始支持。
LAZY PERSIST执行流程:
- 对目标文件目录设置 StoragePolicy 为 LAZY_PERSIST 的内存存储策略 。
- 客户端进程向 NameNode 发起创建/写文件的请求 。
- 客户端请求到具体的 DataNode 后 DataNode 会把这些数据块写入 RAM 内存中,同时启动异步线程服务将内存数据持久化写到磁盘上。
- 内存的异步持久化存储是指数据不是马上落盘,而是懒惰的、延时地进行处理。
LAZY PERSIST设置使用:
- Step1:虚拟内存盘配置
mount -t tmpfs -o size=1g tmpfs /mnt/dn-tmpfs/
将tmpfs挂载到目录/mnt/dn-tmpfs/,并且限制内存使用大小为1GB 。
- Step2:内存存储介质设置
将机器中已经完成好的虚拟内存盘配置到dfs.datanode.data.dir 中,其次还要带上 RAM_DISK 标签.

- Step3:参数设置优化
dfs.storage.policy.enabled
是否开启异构存储,默认true开启
dfs.datanode.max.locked.memory
用于在数据节点上的内存中缓存块副本的内存量(以字节为单位)。默认情况下,此参数设置为0,这将禁用 内存中缓存。内存值过小会导致内存中的总的可存储的数据块变少,但如果超过 DataNode 能承受的最大内 存大小的话,部分内存块会被直接移出 。
- Step4:在目录上设置存储策略
hdfs storagepolicies -setStoragePolicy -path -policy LAZY_PERSIST
mnt/dn-tmpfs/,并且限制内存使用大小为1GB 。
- Step2:内存存储介质设置
将机器中已经完成好的虚拟内存盘配置到dfs.datanode.data.dir 中,其次还要带上 RAM_DISK 标签.
[外链图片转存中…(img-gJq9FwH8-1668077793343)]
- Step3:参数设置优化
dfs.storage.policy.enabled
是否开启异构存储,默认true开启
dfs.datanode.max.locked.memory
用于在数据节点上的内存中缓存块副本的内存量(以字节为单位)。默认情况下,此参数设置为0,这将禁用 内存中缓存。内存值过小会导致内存中的总的可存储的数据块变少,但如果超过 DataNode 能承受的最大内 存大小的话,部分内存块会被直接移出 。
- Step4:在目录上设置存储策略
hdfs storagepolicies -setStoragePolicy -path -policy LAZY_PERSIST