原文来源: https://tidb.net/blog/81a942af
社区里很多大佬总结了多副本丢失的灾难恢复方法,但是平时遇到最多的单节点故障快速恢复还没有人总结,本文为亲身实践后总结的问题处理过程,此过程保持集群可用无需停止其他节点服务。
背景
故事发生在炎炎夏日的某一天,通过一系列磁盘的iops的测试后,发了个工单质疑阿里云的ESSD磁盘性能不达标,阿里云的客服给我发了一份他们的测试文档,我在某个tidb集群上就开始测试,等我测试完后发现vdb的分区没了。
测试文档中提示,有可能会造成文件系统损坏。

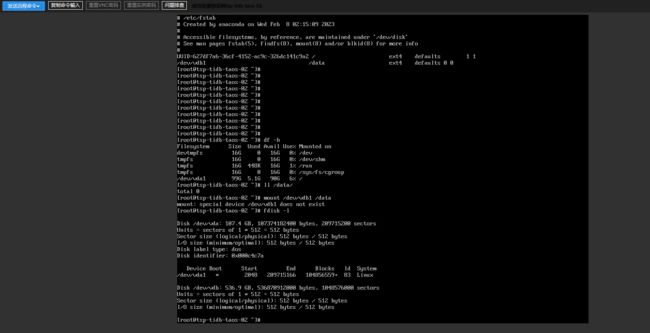
tidb、pd、tikv是混合部署在一起的,TIDB集群变成了如下状态,得益于TIDB强大可用性设计,这个时候集群还是可用状态。

修复
最快速的修复办法是直接增加一台服务器扩容down掉的节点然后缩掉有问题的节点、回收服务器,但是为了节约资源,决定在原服务器上缩容扩容节点。
首先强制缩掉三个down掉节点:
tiup cluster scale-in tsp-prod-taos-cluster --node 10.20.10.138:4000 --force
tiup cluster scale-in tsp-prod-taos-cluster --node 10.20.10.138:2379 --force
tiup cluster scale-in tsp-prod-taos-cluster --node 10.20.10.138:20160 --force


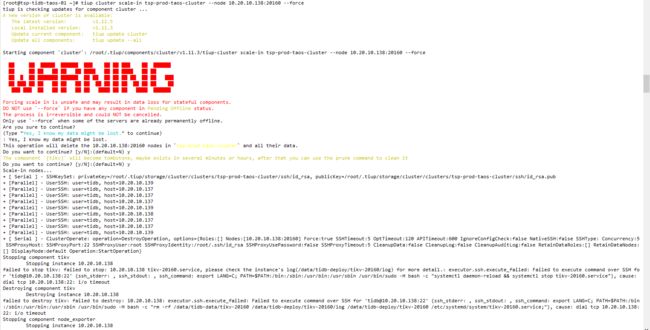
集群变成如下状态:
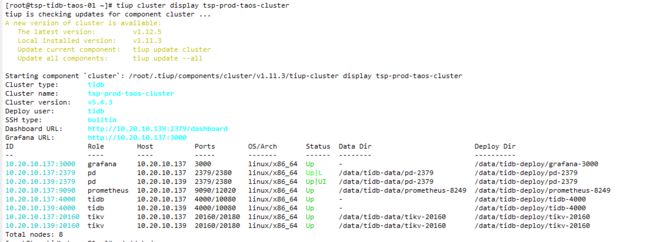
重新给138服务器格式化vdb分区
在138服务器上扩容tidb、pd、tikv节点
tiup cluster scale-out tsp-prod-taos-cluster ./topo-kv02-tidb02-pd02.yaml --user root -p
global:
user: "tidb"
ssh_port: 22
deploy_dir: "/data/tidb-deploy"
data_dir: "/data/tidb-data"
server_configs:
tikv_servers:
- host: 10.20.10.138
port: 20160
status_port: 20180
pd_servers:
- host: 10.20.10.138
tidb_servers:
- host: 10.20.10.138
tidb和pd启动成功,kv启动失败
以下是报错日志:
Error: failed to start tikv: failed to start: 10.20.10.138 tikv-20160.service, please check the instance's log(/data/tidb-deploy/tikv-20160/log) for more detail.: timed out waiting for port 20160 to be started after 2m0s
[2023/08/09 10:37:25.985 +08:00] [ERROR] [util.rs:475] ["request failed"] [err_code=KV:PD:gRPC] [err="Grpc(RpcFailure(RpcStatus { code: 2-UNKNOWN, message: \"duplicated store address: id:406981 address:\\\"10.20.10.138:2
0160\\\" version:\\\"5.4.3\\\" status_address:\\\"10.20.10.138:20180\\\" git_hash:\\\"deb149e42d97743349277ff8741f5cb9ae1c027d\\\" start_timestamp:1691548641 deploy_path:\\\"/data/tidb-deploy/tikv-20160/bin\\\" , already
registered by id:4 address:\\\"10.20.10.138:20160\\\" state:Offline version:\\\"5.4.3\\\" status_address:\\\"10.20.10.138:20180\\\" git_hash:\\\"deb149e42d97743349277ff8741f5cb9ae1c027d\\\" start_timestamp:1679983970 de
ploy_path:\\\"/data/tidb-deploy/tikv-20160/bin\\\" last_heartbeat:1689209409692065070 \", details: [] }))"]
通过pd-ctl查看store 4处于offline状态,新的kv节点无法在pd中注册。

尝试删除store 4,虽然显示成功了,实际上并没有删除。
原因是:delete 成功,触发整个store下线(offline)、开始region迁移,在正常情况下,这个store所有region迁走后会变成tombstone状态。但是实际上这个store上region没有发生迁移(有效tikv数小于replica数)。
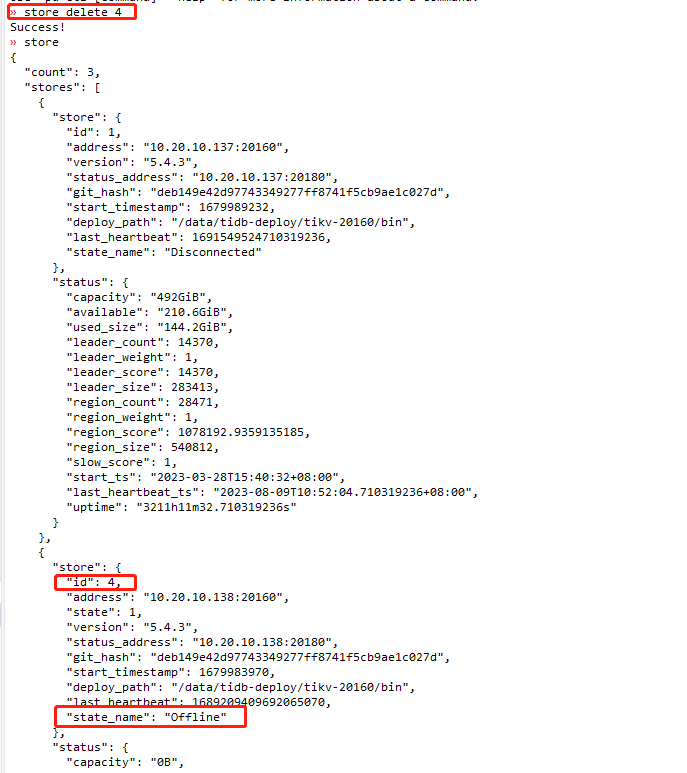
尝试设置该store状态为Tombstone,设置失败。
curl -X POST http://0.0.0.0:2379/pd/api/v1/store/4/state?state=Tombstone
![]()
原因是在 5.0 及以上版本中,该接口只支持更改 state 为 Up 或者 Offline,废弃了直接更改为 Tombstone 这个功能。这是由于直接更改为 Tombstone 总是引起操作者意料之外的结果。
把store 4的physically_destroyed设置成ture
curl -X DELETE http://0.0.0.0:2379/pd/api/v1/store/4?force=true
再看store状态

138新的kv节点也自动注册上来了
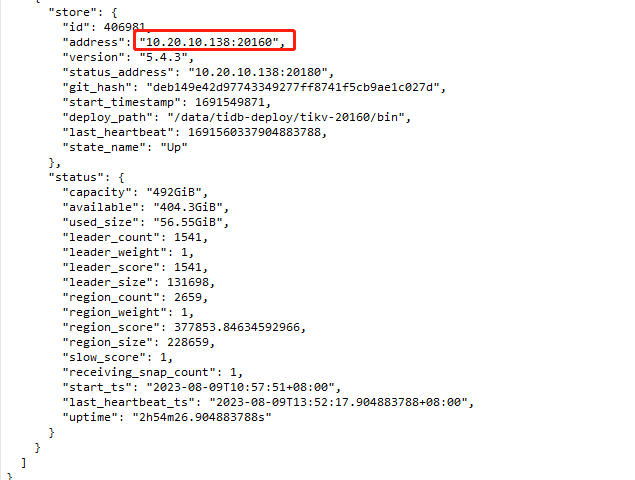
pd开始调度region到138新加入的kv中。

这个时候在pd中查看还是有4个store,由于有效tikv数>=replica数,region在迁移减少了。
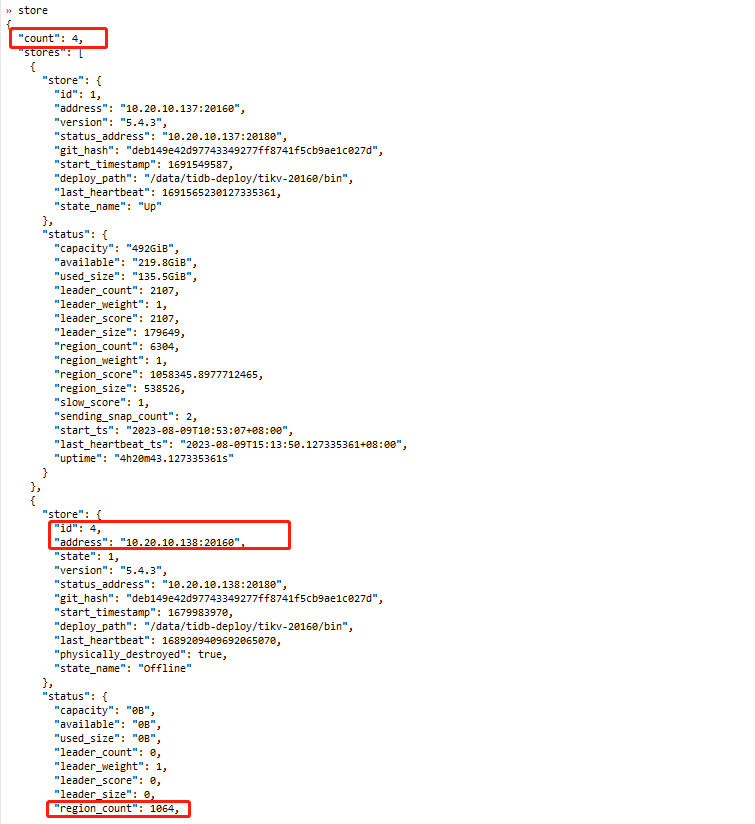
适当调大region调度速度


region迁移结束,pd中sotre4消失

至此修复全部完成!
总结:
1 本文比较基础,提供了简单的处理流程,适合帮助对tidb理解不够深入的新手。
2 没事别瞎折腾服务器,另外需要吐槽下阿里云的ESSD磁盘性能是真的不行,测试下来大概只有nvme物理盘的五分之一。
3 遇到误删文件不要慌,无论是丢失少数副本无损修复还是丢失大多数副本有损修复,TIDB社区都有成熟案例和方案供大家选择。