Vitis高层次综合学习——FPGA
高层次综合
什么是高层次综合?就是使用高级语言(如C/C++)来编写FPGA算法程序。
在高层次综合上并不需要制定微架构决策,如创建状态机、数据路径、寄存器流水线等。这些细节可以留给 HLS 工具,通过提供输入约束(如时钟速度、性能编译指示、目标器件等)即可生成经过最优化的 RTL。
其主要优势为:
1、提高FPGA算法部署的效率
(1)使用C语言来开发和确认FPGA算法;
(2)使用C语言来仿真RTL设计。
2、算法易于移植。
Vivado 和 HLS
Vitis HLS 工具会将 C 或 C++ 函数综合到 RTL 代码中,以便在 Versal 自适应 SoC、Zynq MPSoC 或 AMD FPGA 器件的可编程逻辑 (PL) 区域内实现。Vitis HLS 与 Vivado Design Suite 紧密集成用于综合与布局布线,并与 Vitis 核开发套件紧密集成用于异构系统级别设计和应用加速。
HLS能够降顺序执行的C语言程序转为并行执行。
如下面的例子:
#include <vector>
#include <iostream>
#include <ap_int.h>
#include "hls_vector.h"
#define totalNumWords 512
unsigned char data_t;
int main(int, char**) {
// initialize input vector arrays on CPU
for (int i = 0; i < totalNumWords; i++) {
in[i] = i;
}
compute(data_t in[totalNumWords], data_t Out[totalNumWords]);
check_results();
}
void compute (data_t in[totalNumWords ], data_t Out[totalNumWords ]) {
data_t tmp1[totalNumWords], tmp2[totalNumWords];
A: for (int i = 0; i < totalNumWords ; ++i) {
tmp1[i] = in[i] * 3;
tmp2[i] = in[i] * 3;
}
B: for (int i = 0; i < totalNumWords ; ++i) {
tmp1[i] = tmp1[i] + 25;
}
C: for (int i = 0; i < totalNumWords ; ++i) {
tmp2[i] = tmp2[i] * 2;
}
D: for (int i = 0; i < totalNumWords ; ++i) {
out[i] = tmp1[i] + tmp2[i] * 2;
}
}
上面的C语言代码在CPU中按顺序执行,当然也可以在FPGA中顺序执行,但是这样就没有发挥FPGA的优势。compute() 函数需重构,以实现基于 FPGA 的加速。
加速有以下方向:
1、compute 函数可先启动,随后再将所有数据传递给它;
2、多个 compute 函数能以重叠方式运行,例如,“for”循环能够在上一次迭代完成前启动下一次迭代;
3、“for”循环内的各项操作都能在多个码字上并发运行,无需逐字执行。
compute() 函数循环 A 将输入值乘以 3,并创建两条独立路径,分别是 B 和 C。循环 B 和 C 执行操作并将数据馈送给 D。这是一种现实状况的简单表示法,您需在其中逐一执行多项任务,这些任务彼此相连形成如下所示网络。
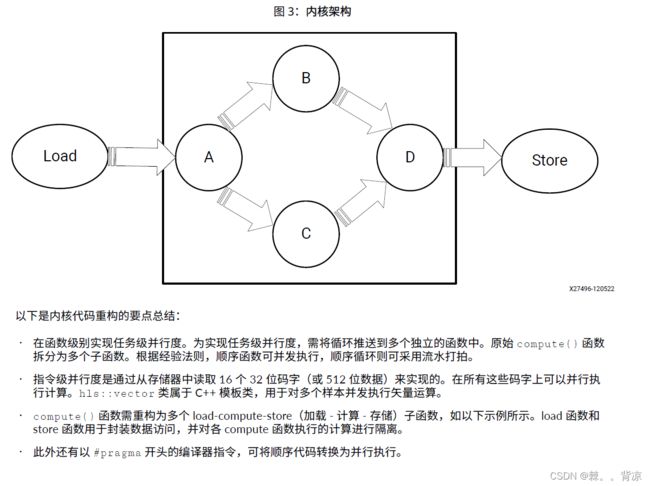
#include "diamond.h"
#define NUM_WORDS 16
extern "C" {
void diamond(vecOf16Words* vecIn, vecOf16Words* vecOut, int size)
{
hls::stream<vecOf16Words> c0, c1, c2, c3, c4, c5;
assert(size % 16 == 0);
#pragma HLS dataflow
load(vecIn, c0, size);
compute_A(c0, c1, c2, size);
compute_B(c1, c3, size);
compute_C(c2, c4, size);
compute_D(c3, c4,c5, size);
store(c5, vecOut, size);
}}
void load(vecOf16Words *in, hls::stream<vecOf16Words >& out, int size)
{
Loop0:
for (int i = 0; i < size; i++)
{
#pragma HLS PERFORMANCE target_ti=32
#pragma HLS LOOP_TRIPCOUNT max=32
out.write(in[i]);
}
}
void compute_A(hls::stream<vecOf16Words >& in, hls::stream<vecOf16Words >&
out1, hls::stream<vecOf16Words >& out2, int size)
{
Loop0:
for (int i = 0; i < size; i++)
{
#pragma HLS PERFORMANCE target_ti=32
#pragma HLS LOOP_TRIPCOUNT max=32
vecOf16Words t = in.read();
out1.write(t * 3);
out2.write(t * 3);
}
}
void compute_B(hls::stream<vecOf16Words >& in, hls::stream<vecOf16Words >&
out, int size)
{
Loop0:
for (int i = 0; i < size; i++)
{
#pragma HLS PERFORMANCE target_ti=32
#pragma HLS LOOP_TRIPCOUNT max=32
out.write(in.read() + 25);
}
}
void compute_C(hls::stream<vecOf16Words >& in, hls::stream<vecOf16Words >&
out, int size)
{
Loop0:
for (data_t i = 0; i < size; i++)
{
#pragma HLS PERFORMANCE target_ti=32
#pragma HLS LOOP_TRIPCOUNT max=32
out.write(in.read() * 2);
}
}
void compute_D(hls::stream<vecOf16Words >& in1, hls::stream<vecOf16Words >&
in2, hls::stream<vecOf16Words >& out, int size)
{
Loop0:
for (data_t i = 0; i < size; i++)
{
#pragma HLS PERFORMANCE target_ti=32
#pragma HLS LOOP_TRIPCOUNT max=32
out.write(in1.read() + in2.read());
}
}
void store(hls::stream<vecOf16Words >& in, vecOf16Words *out, int size)
{
Loop0:
for (int i = 0; i < size; i++)
{
#pragma HLS PERFORMANCE target_ti=32
#pragma HLS LOOP_TRIPCOUNT max=32
out[i] = in.read();
}
}